시작하며,
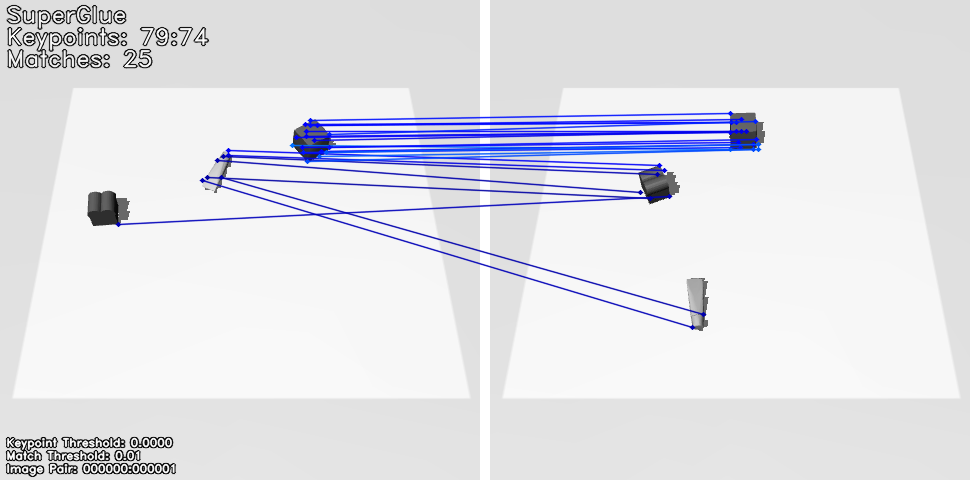
최근에 저는 강화학습 기반 물체 재배열 알고리즘 개발을 졸업 프로젝트로 진행하고 있습니다. 기존에 진행했던 연구의 한계를 찾아 개선하는 방향으로 전개했습니다. 구체적으로, object matching module이 naive하게 구현되어 있어서 이 module의 accuracy를 높이는 쪽으로 연구하고 있습니다. 그러던 중, 조교님의 추천으로 SuperGlue라는 deep matcher를 알게 되었습니다! 아래 그림은 MUJOCO로 생성한 observation과 goal image를 SuperGlue의 input으로 통과시킨 후 얻은 결과를 나타냅니다. 같은 물체의 keypoints끼리 matching 되는 것이 신기하지 않나요? (물론, matching의 outliers도 조금 보이네요.)
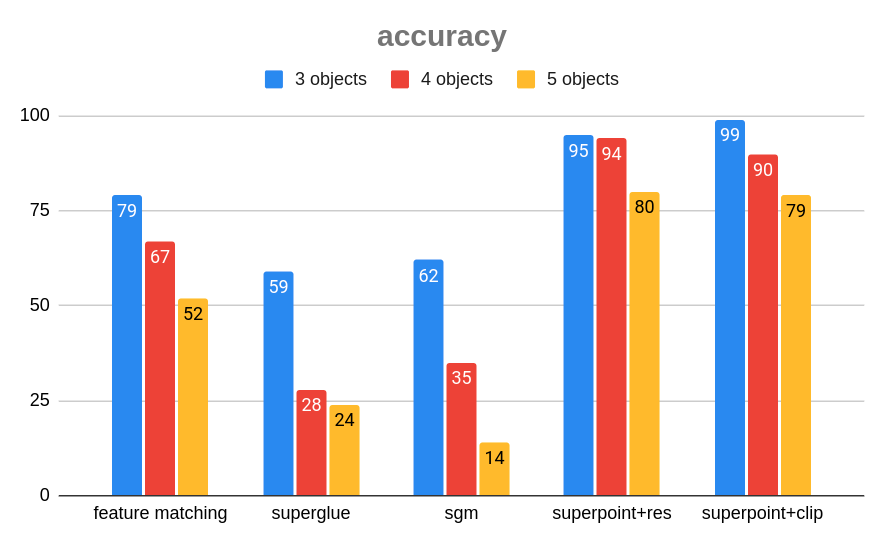
결론적으로는 SuperGlue 자체가 object matching의 accuracy를 높이지는 않았지만 Front-end로 자주 사용되는 SuperPoint의 keypoints와 descriptors를 참조하여 linear sum assignment를 적용한 matching의 결과, 아래의 그래프에서 보시다시피 accuracy 측면에서 유의미한 향상이 있었습니다.
그리하여! 이번 글에서는 며칠간 탐구했던 end-to-end 기반의 deep matcher network인 SuperGlue (https://arxiv.org/pdf/1911.11763.pdf) 에 대해서 리뷰합니다~!
SuperGlue: Learning Feature Matching with Graph Neural Networks
0. Abstract
SuperGlue는 두 개의 local feature sets가 주어졌을 때, correspondences를 찾고 non-matchable points를 검열하여 matches를 찾아내는 neural network입니다. matches를 구하기 위해 differentiable optimal transport problem의 solver를 활용합니다. 이때의 cost는 graph neural network (GNN)의 출력값을 feeding 합니다. 유연한 context aggregation을 위해 attention 기법이 적용되었다고 하네요.
1. Introduction
이미지 내의 점 간 Correspondences는 3D 구조를 예측하거나 camera poses(geometric computer vision tasks)에서 필수적입니다. Simultaneous Localization and Mapping (SLAM)과 Structure-from-Motion (SfM) 가 대표적인 예시입니다. 이와 같은 correspondences는 주로 local features를 기준으로 matching 할 수 있습니다.
SLAM의 맥락에서 front-end와 back-end는 아래와 같이 구분됩니다.
Front-end: visual feature 추출(ex. keypoints, descriptors)
Back-end: bundle adjustment, pose estimation
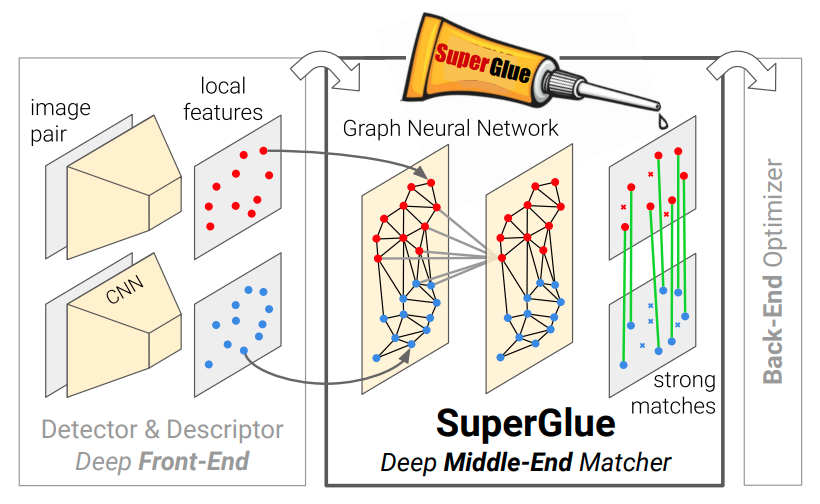
이 논문에서 제시하는 SuperGlue는 front-end와 back-end의 중간에 위치하는 middle-end network(learnable)입니다. 아래의 figure로 보면 더욱 직관적인 이해가 가능하더라고요.
이 연구에선 feature matching을 학습하는 것을 두 local features sets 간 partial assignment로 봤다고 하네요. linear assignment problem, optimal transport problem, Graph Neural Network (GNN), Transformer가 주요 키워드입니다. 특히, Transformer를 활용한 self, cross attention은 spatial, visual 정보를 전부 feeding 하여 complex priors를 학습할 수 있다는 점에서 인상 깊네요. SuperGlue는 indoor and outdoor pose estimation tasks에서 state-of-the-art이며 end-to-end deep SLAM을 위한 초석을 마련했다는 점에서 의미가 있습니다. 아래의 그림은 Superglue를 활용해 matches를 찾아낸 그림입니다.

2. Related work
Local feature matching
SIFT와 RANSAC을 활용한 classical local feature matching pipeline은 아래와 같은 순서로 이뤄집니다.
1) interest points를 찾습니다.
2) 1)에 찾은 interest points의 visual descriptors를 계산합니다.
3) Nearest Neighbor (NN) search를 활용해서 match 합니다.
4) incorrect matches를 검열합니다.
5) a geometric transformation 추론합니다.
근래의 방향은 CNN을 활용해 local descriptors를 더 잘 표현하는 것에 있습니다. regional feature 혹은 log-polar patches를 사용하는 것도 더욱 넓은 context를 살펴보기 위함에 있습니다. 그 외에도 inliers과 outliers의 classification과 3D point clouds의 dense matching하는 방식도 등장했습니다. 한편, 이 논문에서 제시하는 학습 가능한 middle-end는 end-to-end 기반으로 context aggregation, matching, 그리고 filtering (검열)을 한 번에 진행합니다.
Graph matching
Graph matching 문제는 quadratic assignment problems로 재구성할 수 있습니다. 이는 NP-hard 문제로 알려져 있으므로 computationally heavy 하다는 특징을 가지고 있습니다. 이를 위해 heuristics와 approximations가 개발되었으며 그 중 approximate solution인 Sinkhorn algorithm을 활용하였다고 합니다.
Deep learning for sets
self-attention을 완전 그래프에 대한 Message Passing Graph Neural Network로 볼 수 있으며 모든 간선에 대해 attention을 적용함으로써 두 local features 집합에 대한 복잡한 추론을 할 수 있습니다.
3. The SuperGlue Architecture
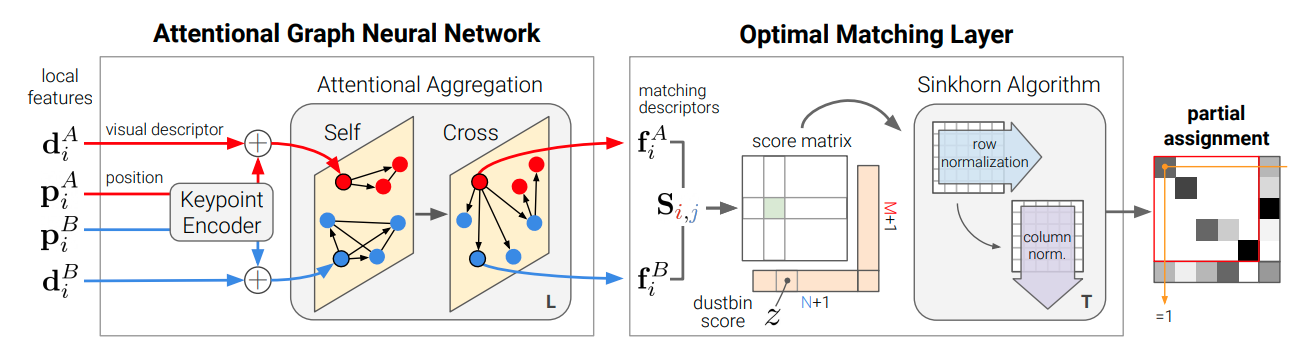
Motivation
images간 correspondences는 아래의 조건을 반드시 만족해야 합니다.
1) keypoint는 다른 이미지에서 최대 하나의 correspondence를 가질 수 있습니다.
2) 어떤 keypoint는 occlusion 혹은 detector의 failure로 인해 unmatch 될 수 있습니다.
SuperGlue는 deep neural network를 통과해서 나온 cost matrix를 optimization problem의 입력으로 받아들입니다.
Formulation
두 개의 image를 각각 와 라고 합니다. 각 image에서 추출한 keypoint positions를 , 그에 해당하는 visual descriptors를 라고 합니다. 를 묶어 local features라고 합니다. keypoint position은 으로 위치 정보와 함께 detection confidence 도 포함합니다. 는 SuperPoint 혹은 SIFT를 활용해 추출할 수 있습니다. 와 는 각각 와 개의 local features를 가지며 인덱스 집합을 로 나타냅니다.
Partial Assignment
우리의 목표는 local features로 구성된 두 집합에 대해 Partial (soft) assignment 를 추론하는 neural network를 디자인하는 것입니다.
3.1. Attentional Graph Neural Network
local features와 더불어 다른 문맥적 힌트를 추가하여 더 특수한 정보를 얻을 수 있습니다. 두 이미지에서 추출한 keypoints끼리의 비교를 통해서 photometric 혹은 geometric transformation을 잘 추론할 수 있고 이는 곧 ambiguities를 해소합니다. 사람이 직접 match task를 실행할 때, ambiguous keypoint를 이리저리 살펴보며 걸러내는 (sift through) 작업을 필요로 합니다. 여기서 착안해서 attention 기반의 iterative process의 힌트를 얻을 수 있었습니다. 첫 번째 주요 block은 위의 그림에서 볼 수 있듯 Attentional Graph Neural Network입니다. initial local features가 주어졌을 때, matching descriptors 를 계산합니다. robust matching을 위해서 이미지간(within) 그리고 이미지끼리(across)의 long-range feature aggregation이 필수입니다.
Keypoint Encoder
The initial representation 는 위치 정보와 시각 정보를 결합합니다. keypoint position은 Multilayer Perceptron (MLP) 를 활용해 high dimensional vector로 임베딩합니다. language processing에서는 “positional encoder”라고 불리는 것과 흡사합니다.
Multiplex Graph Neural Network
두 개의 images의 keypoints에 대한 complete graph를 생각합니다. 그리고 아래와 같은 두 종류의 edges를 생각합니다.
: Intra-image edges
: Inter-image edges
{, }
두 종류의 edges에 대해 message passing formulation을 활용해 정보를 전파합니다. 결과적인 multiplex는 각 고차원의 상태정보를 가진 노드들로 시작해서 messages를 취합하며 표현을 update 해나갑니다.
: layer 에서 image A에 대한 번째 intermediate representation
: { : }의 aggregation한 결과
따라서, image A에서 residual message passing은 아래의 방식으로 update 됩니다.
Attentional Aggregation
attention mechanism은 aggregation을 해나가며 message 계산을 수행합니다.
는 representation을 base로 합니다. 위의 수식에서 q (query)는 target image의 linear projection이며 k (key), v (value)는 source image의 linear projection입니다. 궁극적인 matching descriptor (A 기준)는 아래의 linear projection으로 나타낼 수 있습니다.
3.2. Optimal matchin g layer
위의 그\space 림에서 볼 수 있듯 두 번째 주요 block은 partial assignment matrix를 생산하는 optimal matching layer입니다. 는 score matrix 를 활용한 아래의 최적화 과정으로 구할 수 있습니다.
maximize such that
Score Prediction
score는 matching features의 similarity입니다. normalize 하기 전의 상태입니다.
Occlusion and Visibility
unmatched keypoints가 명시적으로 나타날 수 있도록 dustbin을 추가합니다. 그렇게 에서 로 augmented matrix를 얻을 때 point-to-bin과 bin-to-bin에 해당하는 행과 열을 추가합니다. dubstin에 관련된 element를 single learnable parameter로 설정하고 최대한 match가 많이 발생하도록 아래와 같이 constraint를 강제합니다.
Sinkhorn Algorithm
를 입력으로 Sinkhorn Algorithm을 활용한 T번의 iteration 거쳐 를 얻습니다. 그 뒤, dustin이 포함된 row와 column을 제거해 를 얻습니다.
3.3. Loss
transformation(poses and depth maps or homographies을 활용한)으로 생성된 ground truth label을 dataset으로 supervised learning을 수행합니다. label에는 unmatched keypoints도 존재합니다. labels가 주어졌을 때, 아래의 에 대한 NLL을 최소화합니다.
는 각각 matched keypoints, A에서의 unmatched keypoints, B에서의 unmatched keypoints의 index set입니다.
위 loss는 matching의 precision과 recall을 동시에 최대화하는데 목표를 두고 있습니다.
3.4. Comparisons to related work
SuperGlue vs. Instance Normalization:
SuperGlue의 attention이 모든 keypoints를 동등하게 취급한다는 점에서 instance normalization보다 훨씬 유연하고 강력합니다.
SuperGlue vs. ContextDesc:
Superglue는 appearance와 position을 동시에 추론할 수 있지만, ContextDesc는 그 둘을 분리하여 추론합니다. 게다가, ContextDesc는 더 cost가 큰 regional extractor와 loss가 필요하지만, Superglue는 local features만을 필요로 합니다.
SuperGlue vs. Transformer:
SuperGlue는 transformer의 self-attention의 개념 빌려 GNN의 embeddings를 계산하는 데 활용합니다. 또, cross attention도 추가로 활용해 feature를 재사용할 수 있는 단순한 architecture를 구상했습니다.
4. Implementation details
SuperGlue는 임의의 local feature detector와 descriptor를 front-end로 활용할 수 있지만 SuperPoint와 결합하였을 때 가장 성능이 좋았습니다. SuperPoint는 sparse keypoints를 추출해 효율성 높은 matching을 가능케 했습니다. Visual descriptor는 feature map에서 bilinearly sampling 했습니다. 다른 matcher와의 공평한 비교를 위해, SuperGlue를 학습시킬 때 front-end를 얼려두었습니다.
Architecture details
key, query value, descriptors는 전부 SuperPoint descriptors와 같은 D = 256의 차원을 갖도록 설정했습니다. 4 heads의 multi-head layer로 구현했고 L = 9 layers는 self- and cross-attention을 한 번씩 번갈아 적용했습니다. T = 100번의 Sinkhorn 알고리듬을 반복했습니다. 모델은 PyTorch로 구현했으며, 12M의 parameters를 사용했습니다. NVIDIA GTX 1080 GPU 위에서 real-time으로 forward pass를 수행할 수 있습니다. 속도는 indoor image pair 당 평균 69 ms (15 FPS)로 측정했습니다.
Training details
robustness를 위해 batch에 random keypoints의 추가하는 방식의 data augmentation을 하였습니다.
5. Experiments
5.1. Homography estimation
실제 이미지를 활용해 견고한 (RANSAC) 그리고 견고하지 않은 (DLT) estimator로 large-scale homography estimation 실험을 했습니다.
Dataset
random homographies와 random photometric distortions를 적용해 image pairs를 생성했습니다. Oxford and Paris dataset의 images를 기반으로 생성했고 training, validation, and test sets로 나눴습니다.
Baselines
SuperGlue와 다양한 matchers를 비교했습니다. front-end로 모두 SuperPoint의 local features를 활용했습니다. matchers의 종류로는 NN matcher, NN constraint, PointCN, Order-aware Network (OANet)이 있습니다. 모든 learning method는 즉석에서 생성된 ground truth correspondences를 data로 활용했으며 image pairs는 두 번 사용되지 않습니다.
Metrics
ground truth correspondences를 기준으로 match의 precision (P)과 recall (R) 을 계산했습니다. 명시적인 least squares solution이 존재하는 RANSAC과 the Direct Linear Transformation에 대한 Homography estimation을 수행하였습니다. 이미지의 4개의 코너에 대해 mean reprojection error를 계산하고 10 픽셀까지의 cumulative error curve의 넓이 (AUC)를 측정했습니다.
Results
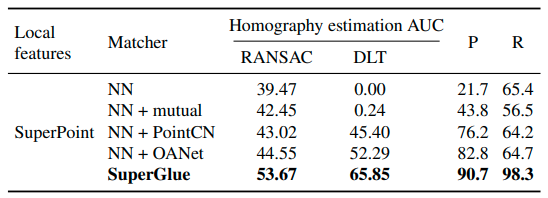
robust estimator가 필요하지 않은 task이므로 SuperGlue의 correspondences가 높은 성능으로 측정되었습니다. (DLT에서 RANSAC보다 더 좋은 결과가 나오는 때도 있었습니다.) PointCN와 OANet 같이 Outlier rejection methods는 NN matcher보다 정확성이 낮았는데 이는 initial descriptors에 과도하게 의존하고 있기 때문입니다.
5.2. Indoor pose estimation
Indoor image matching은 질감의 부재, 자기 유사성, 복잡한 3D 그리고 viewpoint의 극심한 변화 때문에 매우 어려운 과제입니다. SuperGlue는 이러한 문제를 극복하기 위해 효과적으로 priors를 배워나갈 수 있습니다.
Dataset
large-scale indoor dataset인 ScanNet을 활용했습니다. 선행 연구들은 시간차이나 동시 가시성(SIFT를 활용한)을 기준으로 training과 evaluation pairs를 선택했습니다. 우리는 이것이 pairs의 난이도에 한계가 있다고 주장합니다. 그래서 가능한 모든 image pairs에 대해 overlap score를 계산한 것을 기준으로 pairs를 선택했습니다. 결과적으로 이 방식은 더욱 넓은 범위의 pairs를 생성했습니다.
Metrics
선행연구를 참조하여, 5◦, 10◦, 20◦의 threshold에서 pose error의 AUC를 측정했습니다. pose error는 회전과 평행이동에 대한 angular errors의 최댓값입니다. 상대적 poses는 RANSAC를 활용한 essential matrix로부터 구할 수 있었습니다. 또한, 우리는 match precision과 matching score를 구했습니다. match는 epipolar distance를 기준으로 correctness를 판단했습니다.
Baselines
root-normalized SIFT와 SuperPoint를 front-end로 하여 SuperGlue와 다양한 baseline 모델의 평가를 진행했습니다. 모든 baseline은 NN matcher와 잠재적인 outlier rejection 방법에 기초를 두고 있습니다. 아래와 같이 카테고리를 분류했습니다.
Handcrafted method: 상호 체크, 비 판정, descriptor의 거리 판정, 복합적 GMS
Learned method: PointCN, OANet, NG-RANSAC
앞서 논문에서 정의한 loss로 ScanNet에서 PointCN과 OANet을 재학습시켰습니다. SuperPoint 와 SIFT 모두에 대해 진행했습니다. NG-RANSAC는 기존의 학습된 모델을 사용했습니다. graph matching methods는 속도의 문제로 사용하지 않았습니다.
Results
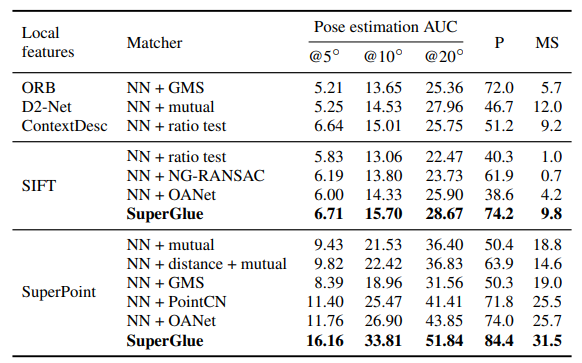
SuperGlue는 handcrafted와 learned matchers 모두에 대해 더 높은 pose accuracy를 보였습니다. 게다가, SIFT와 SuperPoint 모두와 잘 작동하였습니다. 다른 learned matchers에 비해 높은 precision을 확인할 수 있었고 이는 곧 표현력의 강력함을 나타냅니다. SuperPoint + SuperGlue는 indoor pose estimation에서 최고의 성능을 보였습니다.
5.3. Outdoor pose estimation
outdoor image는 조도의 변화와 폐색(occlusion)의 난관을 겪습니다. Indoor pose estimation에서와 같은 metrics와 baseline을 사용했습니다.
Dataset
PhotoTourism dataset의 일부를 활용했습니다. Indoor pose estimation에서와 같이 data augmentation을 진행했습니다.
Results
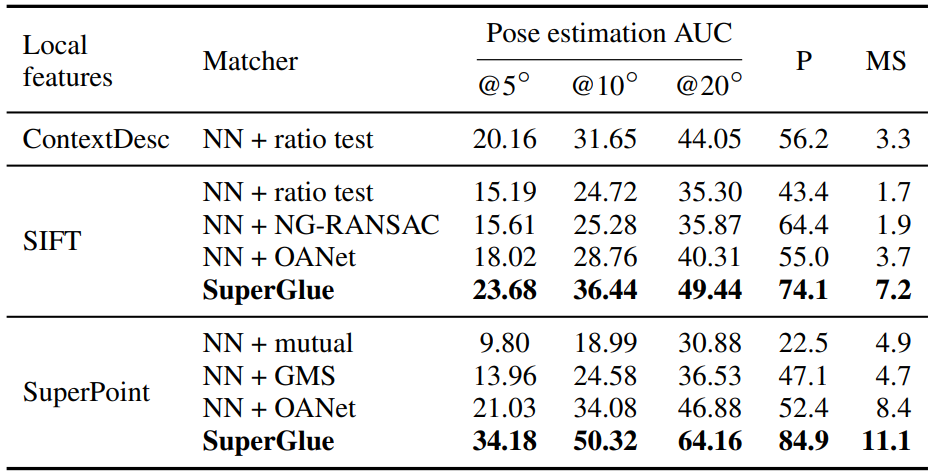
5.4. Understanding SuperGlue
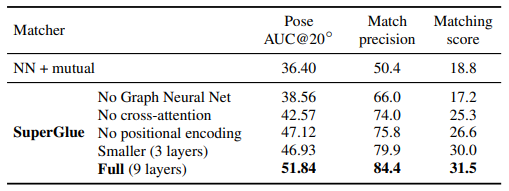
Ablation study
indoor experiments를 진행하며 ablation study를 진행한 결과는 아래와 같습니다.
Visualizing Attention
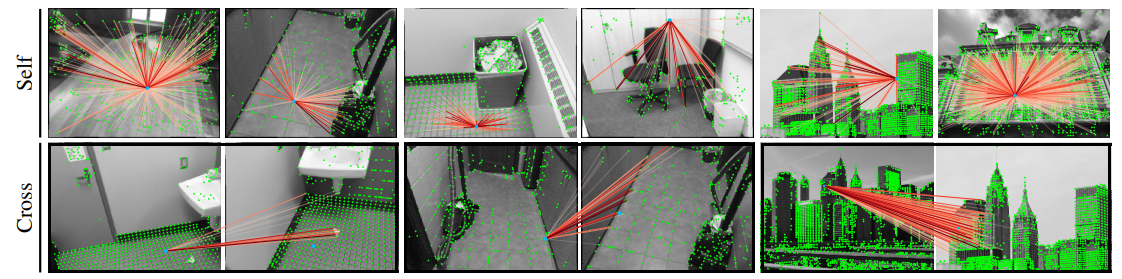
self-와 cross-attention에 대해 의 크기를 시각화한 결과입니다. Attention은 global 또는 local context, self-similarities, distinctive features, 혹은 match candidates에 집중할 수 있습니다.
6. Conclusion
이 논문은 attention을 기반 GNN의 local feature matching의 강력함에 대해 증명했습니다. SuperGlue의 구조는 두 종류의 attention을 활용합니다.
(1) self-attention: local descriptor의 수용 영역을 확장합니다.
(2) cross-attention: 다른 이미지간 정보의 주고받음을 가능케 합니다.
우리의 방법은 optimal transport solver를 활용해 partial assignments와 occluded points를 우아하게 다룹니다. 우리의 실험은 SuperGlue가 현존하는 다른 접근들에 비해 우수하다는 것을 보여줬습니다. (특히, pose estimation과 extreme wide-baseline indoor and outdoor image pairs에 대해) 게다가, SuperGlue는 real-time이며 classical 혹은 learned features에 대해 모두 정상적으로 작동합니다.
요약하자면, handcrafted heuristics를 learnable한 SuperGlue가 대체하였습니다. SuperGlue는 context aggregation, matching과 filtering을 한 번에 수행한다는 장점이 있습니다. SuperGlue가 end-to-end deep SLAM의 마일스톤이 되었습니다.
마치며,
handcraft 방식에서 벗어난 end-to-end 기반의 deep matcher가 존재한다는 게 새로웠습니다. 마치, 예전에 detector에 관해서 연구할 때, NMS와 같은 handcraft 방식을 후처리로 필요로 하는 YOLO만 보다가 DETR을 보게 된 느낌이랄까요? 그때 잠시 살펴봤던 linear sum assignment가 다채롭게 활용되더군요. 역시 뭐든 알아두면 피가 되고 살이 되는 느낌입니다. 하지만 superglue 역시 transformer의 한계인 많은 계산량을 처리해야 된다는 단점을 가지고 있습니다. 이를 해소하기 위해서 SGM이라는 network가 있는데 다음번에 간단하게 리뷰해보도록 하겠습니다. 또, optimal transport problem을 전체적으로 살펴보는 시간도 가지면 좋겠네요! 1~2주에 한 번씩은 글을 완성해서 올리는 것이 목표입니다.
ps) 이제 vision을 연구했던 곳은 떠나게 되었습니다. 출입증 반납을 하는데 왠지 모를 씁쓸함이 밀려오더군요. 그래도 이곳에서 팀원들과 공부도 하고 논문도 많이 읽고 GPU로 실습 코드도 원 없이 돌려볼 수 있어서 너무 감사했습니다.

