
Graph Mining
Graph Basics
-
Graph는 기본적으로 node(V)와 edge(E)로 이루어져 있다.
-
보통 node는 동그라미로, edge는 화살표나 라인으로 그려지며, 화살표/라인에 따라 directed/undirected graph로 나뉜다.
-
Example
- Social Networks : 각 개인이 node, 그들의 relationship은 edge가 되겠다.
- Communication networks : 전자 기기들이 node, 각종 통신망이 link들이 될 것이다.
Graph Mining이란?
-
이러한 graph로 부터 important하거나 interesting한 성질들이나 패턴을 mining해내는 것이다.
-
단순히 connected component의 개수나 그것을 구성하는 node의 개수들뿐만 아니라, Network의 Diameter 같이 쉽게 구하기 어려운 것들을 mining해보고자 한다.
-
Community Detection (Clustering)과 같은 것을 하기도 하며 in-degree나 out-degree를 이용하기도 한다.
Properties of Social Networks
- few connected components : 대부분 다 이어져 있어서 connected component의 개수가 몇 개 되지 않는다.
- Small diameter : 생각보다 작은 diameter, 얼마 안넘어가도 다 이어져 있다고 한다
- hight degree of clustering
- heavy-tailed degree distribution : power law form으로 in-degree와 out-dgree의 분포가 log scale로 보면 linear한 그런 모습으로 되어있다.
Scale-Free Networks - WWW, Citaiton
요즘 나오는 network들은 node의 개수가 고정되어있지 않은데, 실시간으로 계속해서 늘어나며, uniform하게 연결되는 것이 아니라, 이미 많은 link(edge)를 가진 node들에 더 연결될 가능성이 높은 - 어찌보면 당연한 - 성질을 보이고 있다.
Graph algorithms & functions
- BFS / DFS/ Min Spaning tree / Shortest path / etc ...
Object Ranking
Object Ranking에서의 질문은 어떤 Node가 important 그리고 높은 authority를 가졌는지를 묻는 것이다.
Simple Baseline
- In-degree : reasonable하나 너무 simple하고 Out-degree를 고려하지 않는다.
- Out-degree : 좋은데, out-degree가 높은 spam에게 vulnerable하다.
- Center of a specific community : reasonable하지만 cost가 너무 높다.
따라서 HITS와 PageRank를 공부해보도록 하자.
HITS
Importance of Nodes (HITS)
- Good Hub > point many good authorities
- Good Authority > be pointed by many good hubs.
- 엥 그러면 둘이 완전 상호의존적인 관계, mutual reinforcement relationship.
HITS Algorithm
각 Page(Node)는 2개의 score을 갖고있는데
1. Hub score : 해당 Node가 point하고 있는 Node들의 authority score의 합
2. Authority score : 해당 Node를 point하고 있는 Node(Hub)들의 Hub score의 합
둘을 계산하는 방법은 "Hub score를 계산하고 Authority score을 계산한 뒤에 제곱합을 1로 맞추는 Normalization을 진행하는 과정"을 반복하는 것이다. 언제까지? 수렴할 때까지
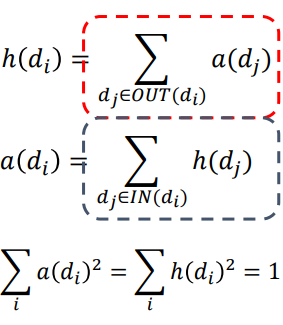
Point는 방금 계산한 Hub score을 바로 다음 A score 계산에 사용하는 것
PageRank
Importance of Nodes (PageRank)
- 많은 Incoming Edge가 곧 important를 의미
- 엥 그러면 너무 Simple하지 않나요? Incoming Edge가 적더라도 Important Node로부터 point되면 걔도 important한 걸로!
PageRank : Simple Version
- Initialization : same score(1) to every page
- For each page : transfer its score to its neighbors (1/n)
- Iterate : until converge
위 방식을 단순히 기존 PageRank Matrix(R)에 Transition Matrix(S)를 곱하는 것으로 봐도 무방하다. 이때 Transition Matrix는 adjacency matrix에서 각 row의 합을 1로 바꿔준 것일 뿐이다.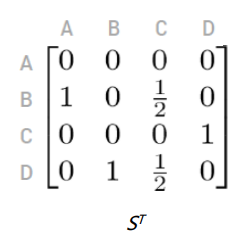
Problems of Simple Version
- Dangling Node : overall한 rank의 sumation이 지속적으로 decrease하는 문제가 있다.
- Ranksink (Cyclic citation) : loop가 rank를 모으고 안에서 돌기만 하는 현상이 발생한다.
PageRank : Random Surfer Model
말그대로 랜덤한 인터넷 surfer의 행동을 따온 모델이다.
- Random walk : 막다른 dangling Node에 도달했을 때, 자신을 포함한 모든 Node로 uniform하게 이동하는 것을 의미한다.
- Restart : 말그대로 모든 Node에서 이동하는 순간에, 어느 페이지에서 restart할지 모르는 surfer의 행동을 고려해 그 확률을 집어넣는다.
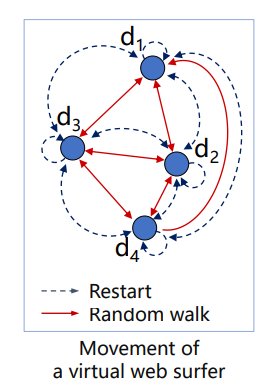
여기서 는 dangling node 여부를 나타내는 벡터 는 uniform한 확률을 가진 벡터이다.
따라서 앞쪽 소괄호 2개는 Random Walk를, 뒤쪽 는 Restart를 의미하는 것이다.
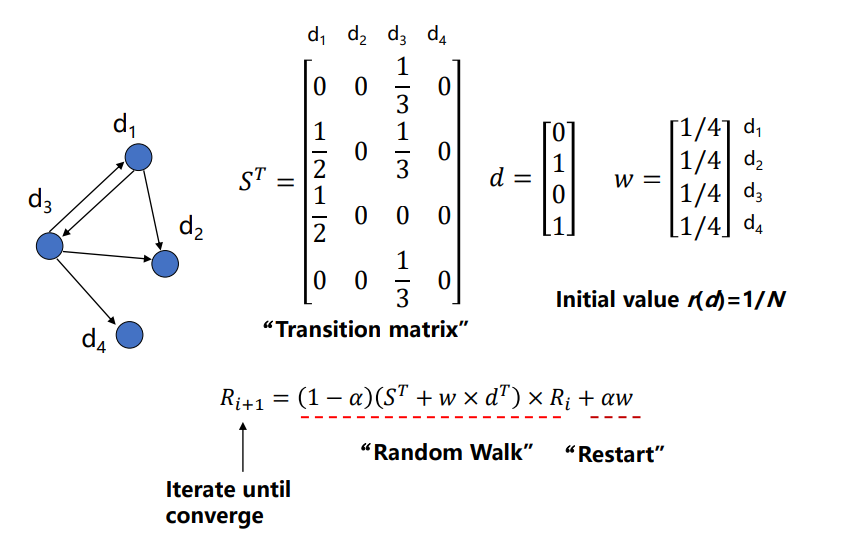
Special Case of PageRank
그런데, 실제 인터넷 surfer들이 완전히 uniform하게 random한 사이트에서 restart하지 않는다는 사실은 우리 모두가 알고 있다. 따라서, 벡터 가 uniform하지 않고 하나의 값만 1이고 나머지는 0으로 두어 오직 특정 Node에서만 Restart하게 설정한다면, 해당 사용자들을 위한 PageRank가 만들어질 것이다.
어? 이게 바로 개인화 personalizaed Ranking이라고 볼 수 있겠다.
따라서 이전의 uniform한 restart가 적용된 것이 "Gloabl" Rank, 방금 소개한 것이 "Local" Rank라고도 할 수 있다.
