크롤링 / Python / MongoDB
[목표]
- 크롤링하여 정보 가져오기.
- python의 기본 문법 익히기
- MongoDB를 사용하여 NoSQL 알아보기 & 직접 코딩에 사용해보기
[일주일 공부 후 느낀 것]
- 재학생 때, 크롤링을 배운 적이 있다. 그 땐, HTML에 대해서 공부를 안 하고 크롤링을 배웠던 터라 정말 어려웠는데, HTML의 태그를 알고 하나하나 비교하고 보니, 정보들이 눈에 들어왔다.
크롤링에 대한 문법을 조금 더 심화적으로 배우고 싶다. - Python은 잘 알고 있는 언어 중 하나다. 일단 배우기가 쉽고, 문법도 간단해서 코딩테스트를 준비하기 위해 정말 강의를 여러번 들었고, 코딩테스트를 여러번 풀어봤기에 사용하기 쉬웠다.
- 예전에 프로젝트를 했을 땐 Firebase만을 사용해 봤는데, NoSQL에 대한 개념은 지금 처음 알았다. DB를 직접 써보니까 그리 어려운 과정은 아니기 때문에 현재 진행중인 프로젝트에서 사용할 수 있었다.
[미리 알고 있었던 것]
- 역시 Python이다. 문법은 잘 알고 있었다.
- 크롤링에 대해서는 알고 있었지만 사실 제대로 익혀본 적은 없어서 많이 긴장했다. 강사님께서 쉽게 가르쳐주셔서 빨리 익힐 수 있었다.
[새로 알게된 것]
- beatifulSoup4 에 대해서 알 수 있었다. 크롤링을 사용하기 위해 미리 제작된 Package인데, 직접 사용해보니 크롤링이 그리 어려운 것이 아니었다.
- NoSQL = 데이터베이스는 크게 관겨형 DB인 SQL과 이것이 아닌 NoSQL 두개로 나뉜다.
(1) SQL에는 MySQL, ORACLE등이 있다. 이는 엑셀과 비슷한데 이미 칸이 만들어져 있다. 따라서 만약 해당하는 정보가 없다면 빈 칸으로 유지되어 공간의 낭비가 있다는 단점이 있다. 또 중간에 바꾸기가 불편하다. 웬만해선 정보가 유지되기 때문에 최적화하기엔 적합하다.
(2) 반면에 NoSQL은 MongoDB가 속하게 되는데, Dictionary형태로 되어있다. Data가 가지고 있는 정보가 다 다르며, 공란으로 굳이 빈 곳을 채울 필요가 없기 때문에 데이터의 변경이 유연하다는 장점이 있다.
크롤링
(1)크롤링 기본 세팅
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
# 이제 코딩을 통해 필요한 부분을 추출하면 된다.
soup = BeautifulSoup(data.text, 'html.parser')
beautifulsoup라이브러리를 사용한다.
url을 통해 HTML을 get해오고 soup을 통해 데이터를 받아온다.
movies = soup.select('#old_content > table > tbody > tr')이런식으로 사용하면 HTML의 구조 안에 있는 정보를 받아와 사용할 수 있게된다.
select를 하는 방식은 다양하다.
(2)Select 하는 방식
# 선택자를 사용하는 방법 (copy selector)
soup.select('태그명')
soup.select('.클래스명')
soup.select('#아이디명')
soup.select('상위태그명 > 하위태그명 > 하위태그명')
soup.select('상위태그명.클래스명 > 하위태그명.클래스명')
# 태그와 속성값으로 찾는 방법
soup.select('태그명[속성="값"]')
# 한 개만 가져오고 싶은 경우
soup.select_one('위와 동일')-
태그명은 말 그대로 태그다. a / div / img등의 태그를 입력하면 된다.
-
클래스 명은 설정해둔 클래스의 이름이다. class="name"이라고 해놓으면 .name이라고 입력하면 된다.
-
아이디명은 설정한 아이디이다. id="name"이라고 하면 #name을 넣는다. 중복 안된다.
-
상위 태그와 하위태그는 간단하다. 위에 올려놓은 예제처럼
<div id="old_content">상위 컴포넌트
<table>
<tbody>
<tr></tr>
</tbody>
</table>
</div>이런식으로 이루어있자면 바깥쪽이 있을 수록 상위 컴포넌트 안쪽으로 갈 수록 하위컴포넌트라고 말한다.
(3)실습
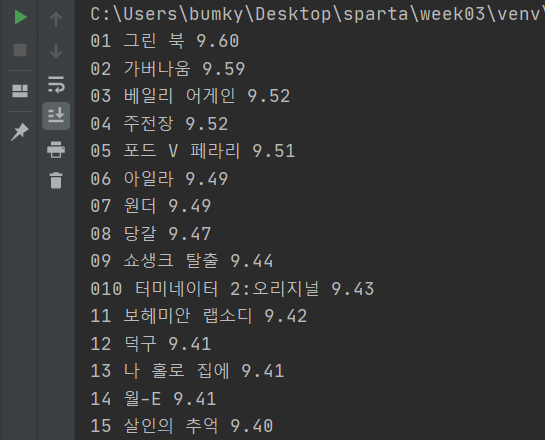
이렇게 영화 평점 사이트에서 번호와 영화이름 평점을 가져와봤다.
여기서 잠깐. 이번에 새로 안 python 함수가 있다.
바로 strip()인데, 크롤링을 하다보면 원치않게 띄어쓰기를 마주할 때가 있다. 그럼 이렇게 말끔하게 정리되지 않고 가독성이 떨어지게 된다. 이 때, strip()을 쓰게 되면 이 띄어쓰기를 없앨 수 있다.
짜란.
MongoDB
(1) pymongo 코드요약
from pymongo import MongoClient # pymongo를 임포트 하기(패키지 인스톨 먼저 해야겠죠?)
client = MongoClient('localhost', 27017) # mongoDB는 27017 포트로 돌아갑니다.
db = client.dbsparta # 'dbsparta'라는 이름의 db를 만듭니다.
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
same_ages = list(db.users.find({'age':21},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})이렇게 네 개만 알아두면 일단 DB는 쉽게 사용 가능하다.
설명을 해보자면
db.users.insert_one(doc)
users는 내가 설정한 db의 이름이다.
(2) pymongo 실습 & 3주차 숙제
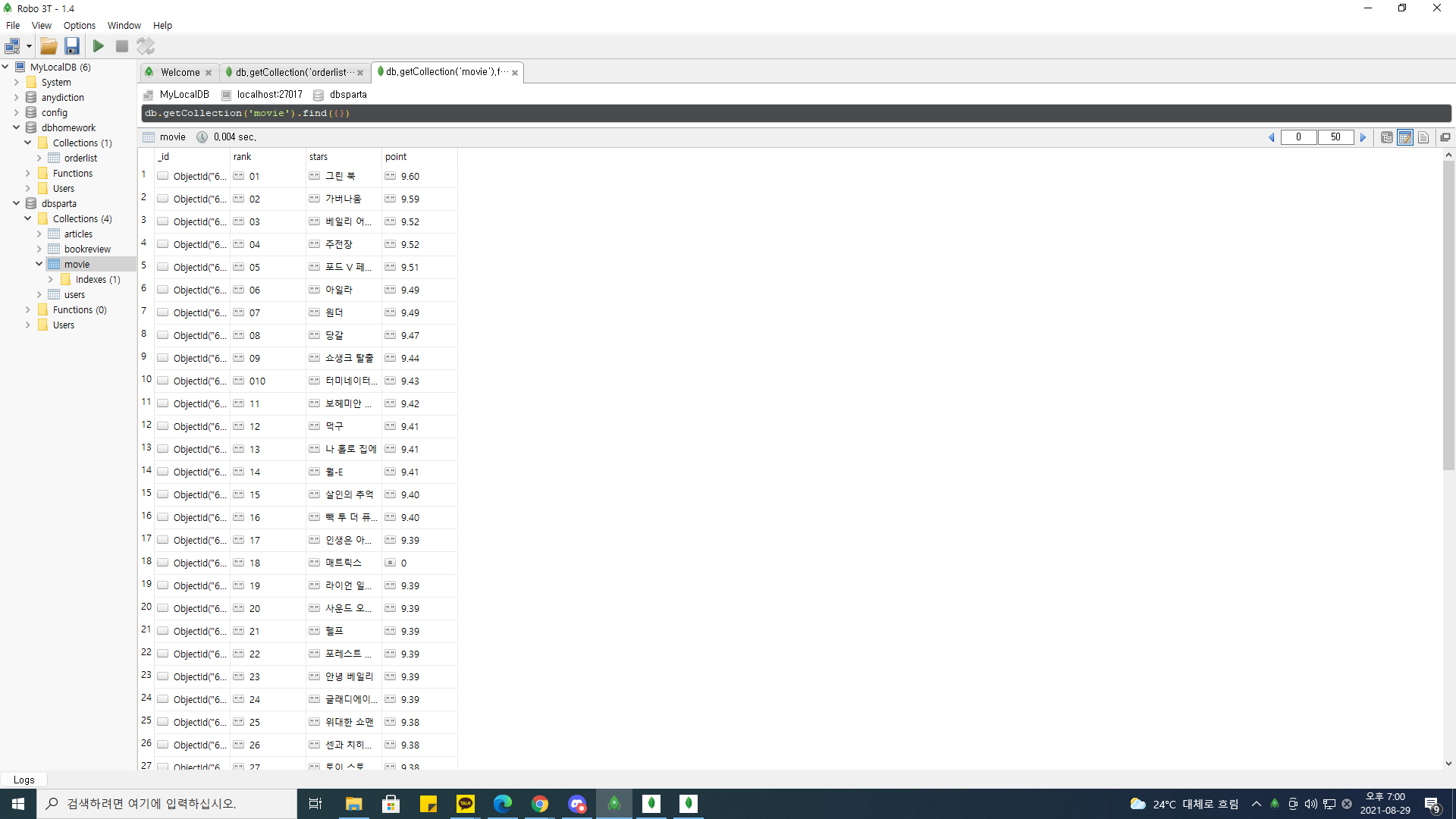
위에서 실행한 크롤링의 실습을 통해 DB에 저장해보았다.
잘 뜨는 것을 확인할 수 있다.

전문 프로그래머가 되고 싶은 소소한 개