AutoEncoder란?
오토인코더란 인력이 들어왔을 때, 해당 입력 데이터를 최대한 압축 시킨 후, 압축한 데이터를 다시 본래의 입력 형태로 복원 시키는 신경망입니다.
이때, 데이터를 압축하는 부분을 Encoder, 복원하는 부분을 Decoder라고 부릅니다.
압축 과정에서 추출한 의미 있는 데이터 Z를 보통 latent vector라고 부릅니다.
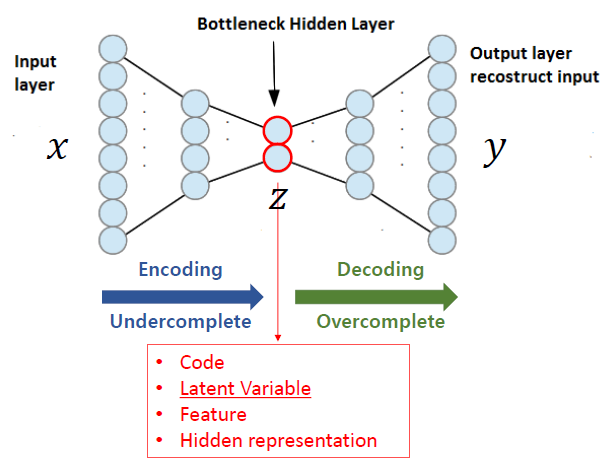
AutoEncoder의 관점
Auto Encoder는 입력 데이터를 일종의 label(정답)로 삼아 학습하므로 Self-Supervised Learning이라고도 부르지만 y값이 존재하지 않으며 이용하지 않는다는 점에서 Unsupervised Learning으로 분류되는 모델입니다.
AutoEncoder vs PCA
AutoEncoder의 경우 Encoder 부분을 입력 데이터를 압축하는 과정에서 데이터의 차원을 축소시킵니다. 차원의 축소 관점에서 Encoder 부분은 주성분 분석인 PCA(Principal Component Analysis)와 유사한 점이 있습니다.
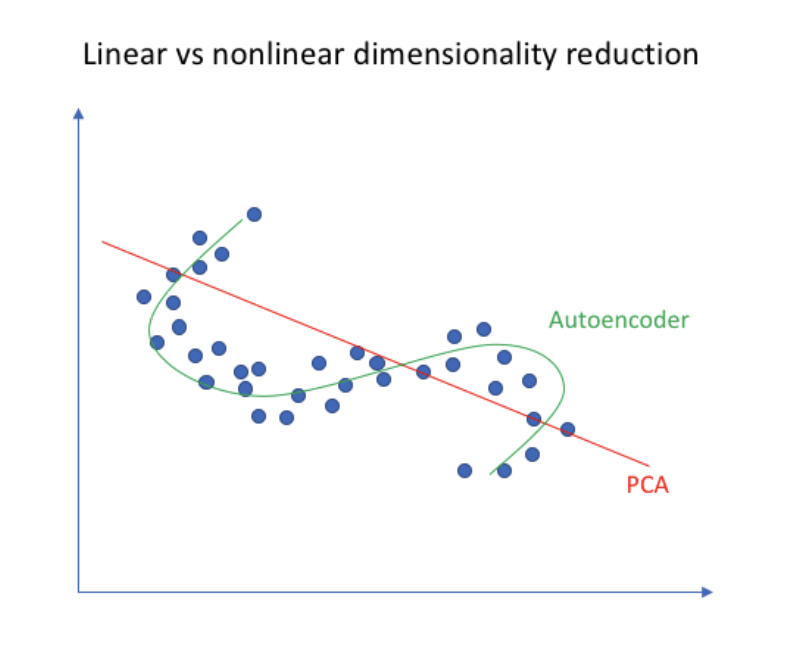
기본적으로 PCA는 선형적으로 데이터 차원을 감소시켜줍니다. 위 그림에서 보듯이 빨간색 실선이 PCA를 뜻하고 데이터가 주어졌을 때 위와 같이 선형적으로 데이터의 차원을 축소시키게 됩니다. 반면에 초록색 실선인 AutoEncoder의 Encoder는 비선형적으로 데이터의 차원을 줄여줄 수 있습니다.
PCA는 kernel을 통해서 비선형적으로 데이터를 축소할 수 있지만 보통 선형적으로 데이터 차원을 축소하고 비선형적으로 데이터를 축소하기 위해서 AutoEncoder를 사용합니다.
DAE (Denoising Auto Encoder)
Input Data에 'random noise'를 추가로 더해주어 학습함로써 작은 변화에도 강건한 모델입니다.
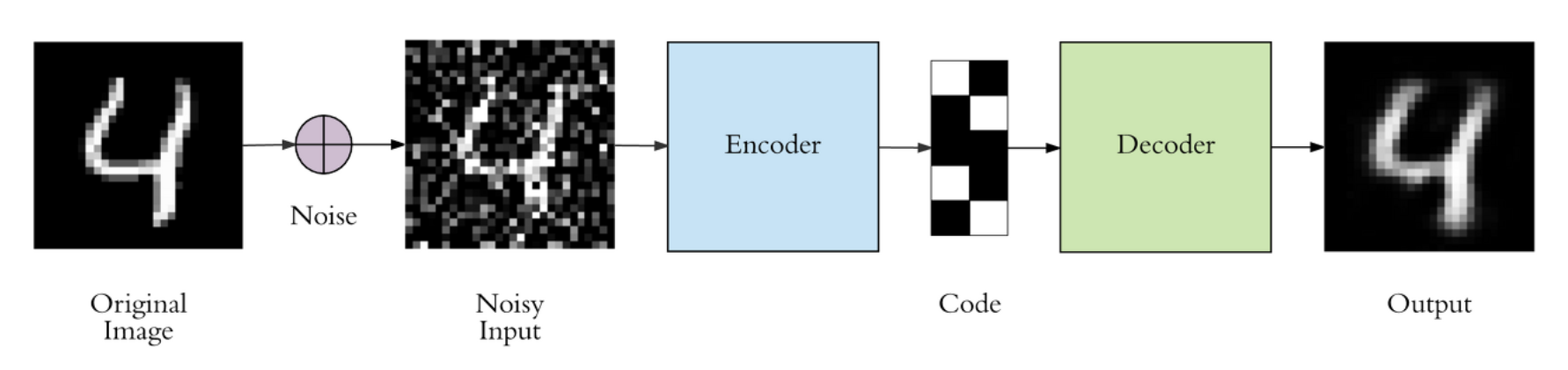
-> 하는 이유 : 학습 데이터는 깨끗한 이미지겠지만 실제 낯선 환경의 실제 Test 데이터는 노이즈가 첨가되어 있는 지저분한 데이터일 수 있기 때문입니다.
만약 깨끗한 이미지로 데이터로만 모델이 학습되었다면 노이즈가 첨가된 데이터가 들어왔을시 원본 이미지를 제대로 복구시키지 못하는 overfitting 문제를 야기할 수 있습니다. 하지만 노이즈가 첨가된 데이터가 들어왔을 경우를 대비해서 모델이 스스로 잘 복구시키도록 일부로 원본 이미지에 노이즈를 첨가한 후 모델을 학습시키는 것입니다.
VAE (Variational Auto Encoder)
DAE는 노이즈를 제거하는 기능을 주로했다면 VAE는 노이즈를 첨가하는 기능을 주로 해줍니다.
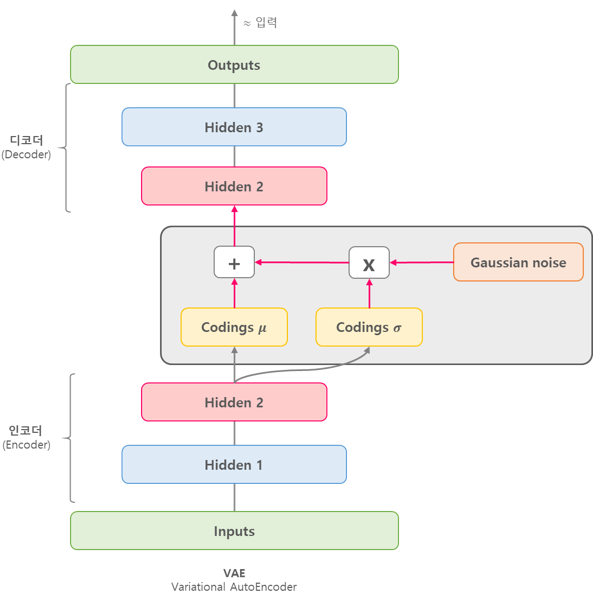
VAE는 랜덤 노이즈로 부터 원하는 영상을 얻을 수 없는 지에 대한 의문에서 시작됩니다.
VAE는 Input image X를 Encoder에 통과시켜 Latent vector z를 구하고, Latent vector z를 다시 Decoder에 통과시켜 기존 input image X와 비슷하지만 새로운 이미지 X를 찾아내는 구조입니다.
VAE vs AE
VAE와 AE는 구조가 비슷하지만 다른 모델입니다.
AutoEncoder의 목적은 Encoder에 있습니다. AE는 Encoder 학습을 위해 Decoder를 붙인 것입니다.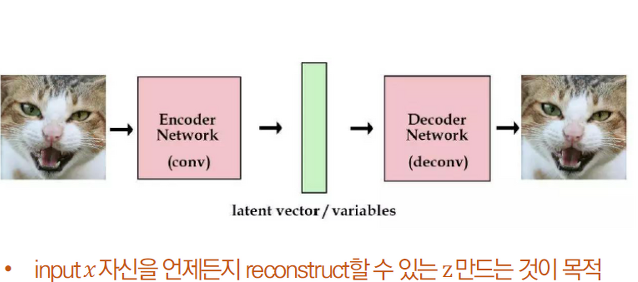
반면에 VAE의 목적은 Decoder에 있습니다. Decoder 학습을 위해 Encoder를 붙인 것입니다.
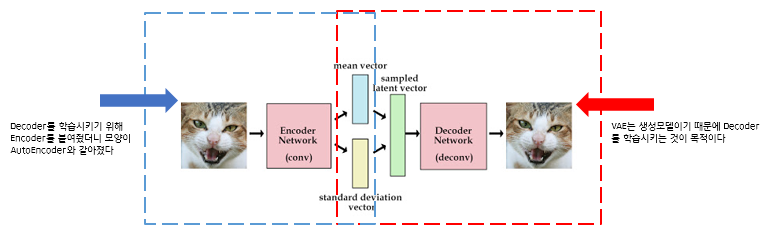
즉, AE는 데이터 압축이, VAE는 데이터 생성이 목적입니다.
|  |
|---|
- AE에 경우 latent vector z 특정 값을 만들어내고 잘 찾자.
- VAE에 경우 더 나아가 latent vector z가 특정한 값이 아니라 다루기 쉬운 분포(정규분포 등.)의 형태를 띄게 만들자.
- latent vector z는 각 feature의 평균과 분산값을 나타냄
- 확률 분포를 잘 찾아내고, 확률값이 높은 부분을 이용하여 실제 있을법한 이미지를 새롭게 생성
Reference
