https://arxiv.org/pdf/2407.09025v1
Abstract
주요 기여 및 방법론
- Vanila Serialization
- 셀 주소, 값 서식을 포함하는 기본적인 직렬화 방식을 도입
- but, 토큰 제한으로 인해 실제 적용에 어려움이 있음
- SHEETCOMPRESSOR
- LLM을 위한 스프레드시트 압축을 위해 개발된 인코딩 프레임워크
- 구성
- Structural-anchor-based compression (구조적 앵커 기반 압축)
- Inverse index translation (역 인덱스 변환)
- Data-format-aware aggregation (데이터 형식 인식 집계)
- 스프레드시트 테이블 감지 작업에서 기본 방식보다 GPT4의 인컨텍스트 학습 설정에서 25.6% 향상된 성능을 보임
- SHEETCOMPRESSOR를 상요한 fine-tuned된 LLM은 25배 압축되고, 기존의 최고 모델보다 12.3% 높은 78.9%의 F1 score을 가진다.
- Chain of Spreadsheet
- 스프레드시트 이해와 관련된 downstream 작업을 위해 Chain of Spreadsheet를 제안
- 스프레드시트의 고유한 레이아웃과 구조 체계적으로 활용함으로써, SPREADSHEETLLM의 효과 검증
Introduction
1. LLM이 스프레드시트에서 겪는 주요 문제점
- 확장성 문제
- 스프레드시트의 크기로 인해, LLM의 토큰 한도를 초과하는 경우가 많음
- 기존 LLM은 순차적(linear) 입력을 기반으로 동작하지만, 스프레드시트는 2D 구졸르 가지므로 적절하지 않음
- 특수한 요소 처리 문제
- 셀 주소(cell address)나 서식(format)과 같은 스프레드시트의 고유한 특징을 제대로 해석하지 못함.
- 데이터를 효과적으로 분석하고 활용하는데 어려움을 겪음
이를 해결하기 위해 SPREADSHEETLLM이라는 새로운 프레임워크를 제안
2. SPREADSHEETLLM 및 SHEETCOMPRESSOR 소개
기존 문제 해결을 위한 SHEETCOMPRESSOR 기법
스프레드시트가 LLM의 토큰 한도를 초과하면 성능 저하되는 문제 발생(Liu et al., 2024).
이를 해결하기 위해 SHEETCOMPRESSOR라는 새로운 인코딩 프레임워클르 도입
핵심 모듈
1. Structural Ancho(구조적 앵커)를 활용한 레이어 분석
- 큰 스프레드시트에는 반복적인 행과 열이 많으며, 이는 레이아웃 이해에 기여하지 않음.
- 테이블 경계를 정의하는 heterogeneous(이질적인) 행과 열을 구조적 앵커로 식별하여 주요 레이아웃을 유지하면서, 불필요한 반복 행/열을 제거 압축된
skeleton버전 생성
- Inverted-Index Translation (역index 변환)으로 토큰 절약
- 기존의 행/열 단위 직렬화 방식은 빈 셀과 반복적인 값이 맣아 토큰 소비가 많음
- 이를 개선하기 위해, JSON 기반의 Inverted-Index Translation(역색인 변환) 사용
- 비어 있지 않은 셀의 내용을 딕셔너리(dictionary) 형태로 저장.
- 동일한 내용을 가진 셀 주소를 병합하여 불필요한 토큰 낭비 방지.
- 데이터의 무결성(data integrity)을 유지하면서 토큰 효율성 극대화.
- Data Format Aggregation for Numerical
Cells
- 인접한 숫자 셀들은 종종 동일한 형식을 공유함.
- 정확한 숫자 값보다 숫자 데이터의 형식 정보가 더 중요한 경우가 많음.
같은 형식의 숫자 셀을 클러스터링하여 숫자 데이터의 분포를 더 쉽게 이해할 수 있도록 함.
밑의 그림처럼 사각형 영역을 균일한 형식 문자열 및 데이터 유형으로 표현하여 숫자 데이터 분포를 쉽게 이해할 수 있도록 하면서도 불필요한 토큰 소비를 방지

실험 결과
- SHEETCOMPRESSOR는 스프레드시트 인코딩을 위한 토큰 사용량을 96% 절감
- SPREADSHEETLLM는 스프레드시트 테이블 감지에서 SOTA 방법보다 12.3% 높은 성능을 보임
- 스프레드시트 추론을 테이블 감지-매핑-추론 파이프라인 Chain of Spreadsheet(CoS) 방법론 제안
연쇄 추론 (Chain of Though, CoT)방법론과 유사
기존 SOTA 방법(Herzig et al., 2020; Cheng et al., 2022)을 능가하는 성능을 보임
2. Related Work
Spreadsheet Representation
다양한 표현 방식
Mask R-CNN을 활용하여 스프레드시트의 공간 및 시각 정보를 활용하는 연구 (Dong et al., 2019a,b)LLM을 활용하여 이미지 테이블을 평가하는 연구- 스프레드시트 이미지를 VLM(Visual Language Models)의 입력으로 사용할 때 성능이 저하되는 문제 있음.
- 행과 열에서 순차적 의미를 포착하기 위해,
LSTM이 추가적으로 적용 (Nishida et al., 2017; Gol et al., 2019) Pre-trained LMs(사전 학습된 언어 모델)을 활용 (Dong et al., 2022; Wang et al., 2021)markdown및HTML을 사용한 테이블 표현 방식이 탐구 (Zhang et al., 2023; Li et al., 2023b; Sui et al., 2023)
이러한 방식은 단일 테이블 입력만을 처리할 수 있어서 스프레드시트 표현에 적합하지 않음
Spreadsheet Understanding
대부분의 테이블 LLM은 단일 테이블 환경으로 제한.
스프레드시트는 여러 개의 테이블을 포함하고 있고, 이는 토큰 한계를 초과하는 경우가 많음.
또한, 다중 테이블 레이아웃과 구조의 다양성이 문제를 더욱 복잡하게 만듦
< 목표 >
스프레드시트 테이블 탐지: 주어진 시트에 모든 테이블을 식별하고 해당 범위를 결정하는 작업 (Dong et al., 2019b; Christodoulakis et al., 2020; Doush and Pontelli, 2010; Vitagliano et al., 2022)
Spreadsheet Downstream Tasks
스프레드시트 이해는 다양한 작업 가능
- 테이블 질의응답(Table Question Answering, QA) 분석 (He et al., 2024; Cheng et al., 2021b, 2022; Jiang et al., 2022; Herzig et al., 2020)
- 테이블 추출(Table Extraction) (Chen and Cafarella, 2013, 2014; Li et al., 2024)
- 수식 및 코드 생성(Formula or Code Generation) (Chen et al., 2021; Cheng et al., 2021a; Joshi et al., 2024; Chen et al., 2024; Li et al., 2023a)
- 오류 탐지(Error Detection) (Wang and He, 2019; Dou et al., 2016)
LLM의 토큰 효율성 (LLMs’ Token Efficiency)
긴 context에서 LLM의 성능이 크게 저하됨.
따라서, 성능을 향상시키고 비용을 절감하기 위한 압축 기술의 개발
- 정보 이론적 메트릭을 활용하여 중복 정보 필터링 (Li, 2023; Jiang et al., 2023a)
- 프롬프트 압축을 최적화하는 모델 제시 (Pan et al., 2024)
이러한 전략들은 주로 자연어 기반의 prompt에 초점을 맞추고 있으며, 테이블 데이터에는 적합하지 않아 구조 및 데이터 정보 손실 초래
DBCopilot (Wang et al., 2023)
- 스키마 라우팅을 통해 대규모 데이터베이스에서 text-SQL 변환을 가능하게 함
- LLM의 다중 테이블 레이아웃 및 복잡한 테이블 구조 이해 능력 부족으로 스키마 라우팅은 비실용적
3. Method (방법론)
본 논문에서는 텍스트 기반의 Markdown 스타일의 새로운 스프레드시트 인코딩 프레임워크를 제안.
보다 간결하고 효율적인 표현을 달성하기 위해, 구조적 앵커 기반 추출, 역색인 변환, 데이터 형식 인식 집계 -> 독립적이면서 조합 가능한 모듈 도입
효율적인 데이터 압축 가능, 다운스트림 작업에서 성능 향상
3.1 셀 값, 주소 및 형식을 포함한 기본 스프레드시트 인코딩 (Vanilla Spreadsheet Encoding with Cell Value, Address, and Format)
LLM을 위한 스프레드시트 인코딩의 표준화된 방식이 없기 때문에, 먼저 기존의 스프레드시트 인코딩 방식 탐색
(부록 B에서는 HTML, XML, Markdown을 포함한 여러 주류 테이블 데이터 인코딩 방법을 비교)
여기서,
- : 스프레드시트 데이터
- : 텍스트 기반의 인코딩된 셀
- : 행 및 열의 인덱스와 범위
추가적으로, 셀의 배경색, 굵은 글씨, 테두리 등 형식 정보를 포함하는 실험도 진행했으나, 밑의 이유 등으로 모델 성능이 저하됨을 확인
- 빠른 토큰 제한 초과
- LLM이 형식 정보를 효과적으로 처리하지 못함
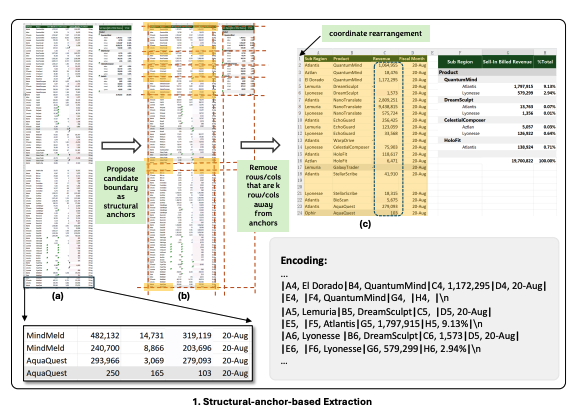
3.2 Structural-anchor-based Extraction (구조적 앵커 기반 추출)
대형 스프레드시트는 동질정인 행과 열이 많아 테이블의 레이아웃과 구조를 이해하는데 기여하는 바가 적음
여기서 볼 수 있듯이, 불필요한 데이터를 효율적으로 압축하면서도 레이아웃 및 구조 정보를 보존하기 위해 휴리스틱 기반 방법을 제안
여기서,
-
: 특정 행의 셀 집합
-
: 특정 열의 셀 집합
이 방법은 테이블 경계를 결정하는 이질적인(heterogeneous) 행과 열을 찾아냄으로써,
( k ) 단위 이상 떨어진 행과 열을 삭제하여 데이터를 압축함
이를 통해
- 전체 데이터의 75%를 필터링
- 97%의 테이블 경계 행과 열을 보존
추출된 데이터는 좌표 재매핑(coordinate re-mapping)을 수행하여, 데이터 관계의 연속성을 유지
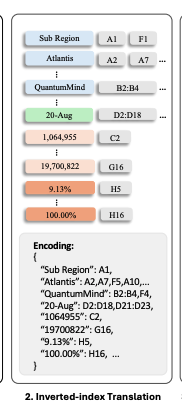
3.3 Inverted-index Translation (역색인 변환)
스프레드시트에는 빈 행, 빈 열, 분산된 셀이 많아, 기존의 행렬 방식은 불필요한 공간을 차지함
이를 해결하기 위해, Inverted-index-based Traslation 제안
- 기존의 행렬 방식 딕셔너리(dictionary) 형식으로 변환
- 같은 값을 가진 셀들을 병합(Merging)하고, 빈 셀을 삭제
이 방법은 모든 스프레드시트 이해 작업에서 적용 가능한 손실 없는 압축 방법으로, SHEETCOMPRESSOR의 압축 비율을 4.41에서 14.91로 향상시킴
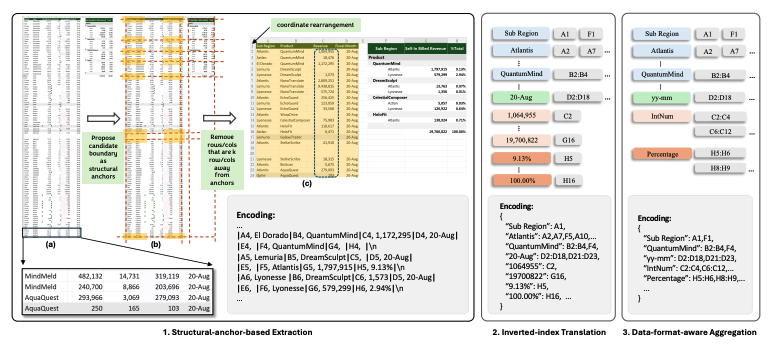
3.4 Data-format-aware Aggregation (데이터 형식 인식 집계)
스프레드시트에서는 인접한 셀들이 동이한 데이터 형식을 공유하는 경우가 많음.
예를 들어, C열이 제품의 매출 데이터를 포함하고 있다면, 개별 숫자의 차이는 중요하지 않지만, 해당 열이 매출 이라는 정보는 중요함.
이를 반영하여,data type 을 기준으로 데이터 집계를 수행하는 방법을 도입함
1) NFS (Number Format String) 기반 데이터 분류
- NFS는 스프레드시트의 내장 속성으로, 셀 데이터의 형식을 문자열로 표현함
- 예를들어,
2024.2.14→yyyy-mm-dd
모든 스프레드시트가 NFS를 명시적으로 포함하는 것은 아니므로,
Rule-based 데이터 타입 인식기를 추가로 적용
데이터 타입 인식할 수 있게 설정한 방법
- 연도(Year), 정수(Integer), 실수(Float), 퍼센트(Percentage), 과학적 표기법(Scientific Notation), 날짜(Date), 시간(Time), 통화(Currency), 이메일(Email)
2) Aggregation (데이터 집계)

Algorithm 1을 통해 데이터 집계 수행
이 방법을 적용한 결과, 압축 비율이 14.91에서 24.79로 증가
3.5 Chain of Spreadsheet, CoS (스프레드시트 체인)
SPREADSHEETLLM의 활용성을 확장하기 위해 CoS(Chain of Spreadsheet) 프레임워크를 도입
1) Table Identification and Boundary Detection (테이블 식별 및 경계 감지)
- LLM이 압축된 스프레드시트와 Query를 입력으로 받아, 관련 테이블과 경계를 탐지
- 불필요한 데이터 처리를 방지하여 효율성 최적화
2) Response Generation (응답 생성)
- 탐지된 테이블과 질의를 기반으로 LLM이 응답 생성
적용한 결과, SPREADSHEETLLM이 복잡한 스프레드시트를 보다 효과적으로 처리 할 수 있었음.
4. Experiments (실험)
4.1 스프레드시트 표 탐지 (Spreadsheet Table Detection)
4.1.1 데이터셋
본 연구에서는 Dong et al. (2019b)에서 제안한 실제 스프레드시트 데이터셋을 사용하여 표 탐지 성능을 평가
- 데이터셋은 표 경계(annotation)가 포함된 벤치마크 데이터셋으로, 데이터셋의 품질을 높이기 위해 전문가 5명이 추가 검토
최종적으로 188개의 스프레드시트, 311개의 표로 구성된 데이터셋 구축.
- 표의 크기에 따라 Small(64), Medium(32), Large(70), Huge(22) 네 개의 그룹으로 분류
표를 탐지하기 위해 Error-of-Boundary 0 (EoB-0) 지표를 활용. (표의 상/하/좌/우 경계를 정확히 예측해야 하는 평가 방식)
4.1.2 실험 설정 (Experiment Setup)
(1) Baseline & Evaluation Metrics (비교대상)
- Baseline model: TableSense-CNN (Dong et al., 2019b)
평가 지표:
- F1 Score: 정밀도(Precision)와 재현율(Recall)을 고려한 종합 평가
- EoB-0 (Error-of-Boundary 0): 표 경계의 정확한 예측 여부
(2) Model Selection (모델 선정)
폐쇄형 모델: OpenAI GPT-4, GPT-3.5
오픈소스 모델: Llama2, Llama3, Phi3, Mistral-v2
4.2 스프레드시트 질의응답 (Spreadsheet QA)
4.2.1 Dataset (데이터 셋)
기존의 Table QA 데이터셋은 대부분 single table 환경을 대상으로 하므로 multi table을 평가하기에는 한계가 있음.
새로운 Spreadsheet QA 데이터셋 구축
- 64개의 스프레드시트에서 각 4~6개의 질문 생성 (총, 307개의 QA 항목 포함)
- 질문 유형: Search, Comparison, Arithmetic(기본 연산) 중심
- 각 질문(Q)에 대한 정답(A)과 관련된 표(S)를 제공
- 정답은 셀 주소(cell address) 또는 셀 포함한 수식으로 명확히 정의하여 평가의 객관성 확보
4.2.2 Experiment Setup (실험 설정)
(1) Baseline & Evaluation Metrics (비교 대상)
스프레드시트 QA는 기존에 LLM 기반으로 체계적인 연구가 이뤄지지 않아, 비교 모델로 Table QA에서 검증된 두 가지 기법 채택
-
Baseline 모델
- TAPEX (Herzig et al., 2020)
- Binder (Cheng et al., 2022)
-
평가지표
- 셀 주소(cell address)와 계산식의 정확도를 기준으로 정답 여부 판단
(TAPEX, Binder는 single table 환경을 위주로 설계되어 있기문에, Multi table 환경에서도 적용할 수 있도록 사전 처리 단계 추가)
(2) Model Selection
- QA 실험은 GPT-4 사용
4.2.3 Experiment Procedure (실험 절차)
- 스프레드시트 표 탐지 실험 절차
- 스프레드시트 데이터를 입력하여 표 탐지 모델 적용
- 모델이 예측한 표의 경계와 정답(Ground Truth) 경계 비교
- EoB-0 및 F1 Score 기반 평가 수행
- 스프레드시트 QA 실험 절차
- 표 탐지 모델을 활용하여 질문과 관련된 표 영역을 식별
- 표 데이터를 정리하여 QA 모델 입력 형식으로 변환
- 입력 길이가 제한을 초과할 경우, 압축 기법(Compression Techniques) 적용
- 압축이 어려운 경우 표 분할(Table Spliting Algorithm) 적용
- 표의 Header를 분석하여 의미를 유지한 상태에서 적절히 문할
- 표를 병합(Concatenation)하여 맥락(Context)을 최대한 보존
- QA 모델에 입력 후 정답 예측
- 예측된 정답과 실제 정답을 비교하여 성능 평가
4.3 Compression Performance (데이터 압축 실험)
4.3.1 Compression Results (압축 기법 적용 결과)
QA 실험에서는 모델의 입력 길이를 초과하는 경우가 많아, 다양한 압축 기법을 활용하여 토큰 수를 줄이는 실험을 진행
| 모듈 조합 | 전체 토큰 수 | 압축 비율 |
|---|---|---|
| No Modules | 1,548,577 | 1.00 (Baseline) |
| Module 1 | 350,946 | 4.41 |
| Module 2 | 580,912 | 2.67 |
| Module 3 | 213,890 | 7.24 |
| Module 1 & 2 | 103,880 | 14.91 |
| Module 1 & 3 | 96,365 | 16.07 |
| Module 2 & 3 | 211,445 | 7.32 |
| Module 1 & 2 & 3 | 62,469 | 24.79 |
4.3.2 Analysis & Conclusion (분석 및 결론)
- 압축 모듈을 조합할수록 토큰 수를 효과적으로 줄일 수 있었음
- Module 1 & 2 & 3을 함께 적용한 경우 24.79배 압축이 가능했음
- 데이터가 압축됨에 따라 모델의 처리 효율이 증가
- 입력 길이 제한으로 인해 발생하는 문제를 최소한 할 수 있었음
5. Results (결과)
5.1 Compresison Ratio

- 인코딩 방법은 25배 압축 비율을 달성하여 대형 스프레드시트 데이터 처리의 컴퓨팅 부하를 크게 감소시킴
- 다양한 모듈 조합의 압축 성능 확인 가능
- 다양한 스프레드시트 구조에서도 높은 적응성과 견고성을 보여줌
5.2 Spreadsheet Table Detection
5.2.1 Main Results
1. Enhanced Performance with Various LLMs
- Fine-tuned GPT-4 모델: F1 score 약 76%
- 압축 기법 적용시: F1 score 약 79% → SOTA 달성
- 기존 모델 대비 성능 향상:
- Fine-tuned 원본 모델 대비 27% 개선
- TableSense-CNN 대비 13% 개선
- 다른 LLM에서도 성능 향상
- Llama3: 25% 개선
- Phi3: 36% 개선
- Llama2: 38% 개선
- Mistral-v2: 18% 개선
- Benefits for Larger Spreadsheets
- 대형 스프레드시트에서 성능 향상이 더욱 두드러짐
- GPT-4 대비 75% 향상 (Huge)
- TableSense-CNN 대비 19% 향상
- Large(45%, 17%), Mediun(13%, 5%), Small(8%)에서도 성능 개선 확인.
- Improvements in In-Context Learning (ICL)
- GPT-4의 전체 데이터 성능이 26% 향상됨.
- 압축 인코딩 덕분에 ICL에서도 효과적인 성능 향상 가능.
- Significant Cost Reduction
- 토큰 수 절감으로 인해 최대 96% 비용 절감 가능.
5.2.2 Ablation Experiment Results
Extraction모듈 제거 시 F1 score 감소 → 핵심 구조 정보 유지에 필수적.Aggregation모듈 제거 시 F1 score 약간 증가 → NFS 방식이 LLM의 해석에 영향을 줄 가능성 있음.Translation모듈 제거 시에도 성능 감소 → 정보 변환 과정이 중요한 역할 수행.
5.3 Spreadsheet QA
- Effectiveness of the CoS Method
- CoS(Compression & Selection) 기법 적용 시 GPT-4 대비 22% 성능 향상
- 대형 스프레드시트의 토큰 제한 문제를 해결하여 LLM의 QA 성능 극대화
- Generalization Capability of the FIne-tuned Model
- Fine-tuning된 모델이 QA 성능에서 뛰어난 일반화 성능을 보임
- TAPEX 대비 37% 개선
- Binder 대비 12% 개선
- Impact of the Split Algorithm
- split 알고리즘 적용 시 정확도 추가 개선
- ICL: 3% 향상
- Fine-tuning: 5% 향상
- 토큰 제한으로 처리 불가능했던 테이블까지 처리 가능하게 하여 QA 성능을 향상.
6. Conclusion
본 논문에서는 SPREADSHEETLLM이라는 새로운 프레임워크를 제안하여 LLM을 활용한 스프레드시트 데이터 처리 및 이해의 발전을 이루었음
- SHEETCOMPRESSOR라는 새로운 인코딩 방식을 통해 스프레드시트의 크기, 다양성, 복잡성으로 인한 문제를 효과적으로 해결.
- 토큰 사용량과 연산 비용을 크게 절감하여 대규모 데이터셋에서도 실용적인 활용 가능
- 최신 LLM을 Fine-tuning하여 스프레드시트 이해 성능을 더욱 향상
- Chain of Spreadsheet(CoS) 확정을 통해 다양한 스프레드시트 관련 다운스트림 작업에서도 높은 적용성과 잠재력을 입증
이를 통해 스프레드시트 데이터 관리 및 분석 방식을 혁신하고, 더욱 지능적이고 효율적인 사용자 인터페이스 가능성을 제시
Limitations (한계)
SPREADSHEETLLM이 LLM의 스프레드시트 해석 및 활용 방식을 개선했지만, 여전히 추가 연구가 필요한 몇 가지 한계점이 있음
1. 스프레드시트의 시각적 요소 미반영
- 현재 프래임워크는 배경색, 테두리 등의 형식을 고려하지 않음 (토큰 비용 문제)
- but, 이러한 요소는 맥락적, 시각적 정보 제공 측면에서 중요한 역할을 할 수 있음
- 자연어 데이터의 의미 기반 압축 부족
- SHEETCOMPRESSOR는 데이터 영역을 효과적으로 압축하지만, 셀 내 자연어 데이터를 의미적으로 압축하는 기법이 부족
- 예)
"China","America","France"등을"Country"로 분류하면
압축률 향상뿐만 아니라 의미적 이해도 증가 가능. - 향후 연구에서 이러한 의미 기반 압축 기법을 탐색할 예정
