밑바닥부터 시작하는 딥러닝을 읽고 필기, 요약한 글입니다.
1. 파이썬
numpy
파이썬에서 배열과 행렬 계산 시 유용한 메서드를 제공하는 라이브러리.
ndarray: N-dimensional array(N차원 배열), 연산의 기본이 되는 클래스.np.array(array_like)함수를 통해 쉽게 만들 수 있음.- 배열을 인덱스로 지정해 한 번에 여러 개의 원소에 접근할 수 있음.
넘파이 배열을 이용한 연산 방식에는 크게 두 가지가 있다.
- 원소 수가 같은 두 배열 간의 산술연산: 각 원소에 대하여 연산 수행, 같은 크기의 결과 배열 반환
- 배열과 스칼라값 간의 산술연산: 스칼라값과의 계산이 각 원소별로 한 번씩 수행됨 (= 브로드캐스트)
- 예를 들어, 부등호와의 연산 결과는 bool 변수로 이루어진 배열이 됨.
ex.np.array([1, 2, 3]) > 2 == [False False True]
- 예를 들어, 부등호와의 연산 결과는 bool 변수로 이루어진 배열이 됨.
matplotlib
그래프 그리기와 데이터 시각화를 위한 라이브러리.
matplotlib.pyplot모듈 이용plt.plot(x, y)로 그리고plt.show()로 출력!- 이미지 또한 읽고 출력할 수 있음. (
imread() & imshow())
2. 퍼셉트론
다수의 입력을 받아서 정해진 규칙에 따라 하나의 신호를 출력하는 알고리즘.
입력 신호의 합이 정해진 한계를 넘을 때만 1을 출력하며, 그렇지 않으면 0을 출력함.
- 하나의 입력 또는 출력을 노드 또는 뉴런이라고 부름.
- 가중치: 입력 신호가 다음 뉴런으로 보내지기 전에 곱해지는 값. 해당 신호가 '얼마나 중요한지'를 나타냄.
- 임계값: 1을 출력하기 위해 필요한 입력 신호의 기준치.
- 임계값을 0으로 두고 입력 신호에 '편향'을 추가하는 식으로도 표현할 수 있음.
- 편향: '뉴런이 얼마나 쉽게 활성화되는지'를 나타냄.
두 개의 입력과 하나의 출력을 가진 퍼셉트론만으로도 AND, OR, NAND 게이트를 만들 수 있다. 구현된 3개의 게이트 간 차이는 오직 매개변수(가중치 & 편향) 뿐이다.
- ex. 기본 수식인 에서, 이고 이면 , 가 모두 1일 때에만 가 1이 되는 AND 게이트가 됨.
XOR Problem
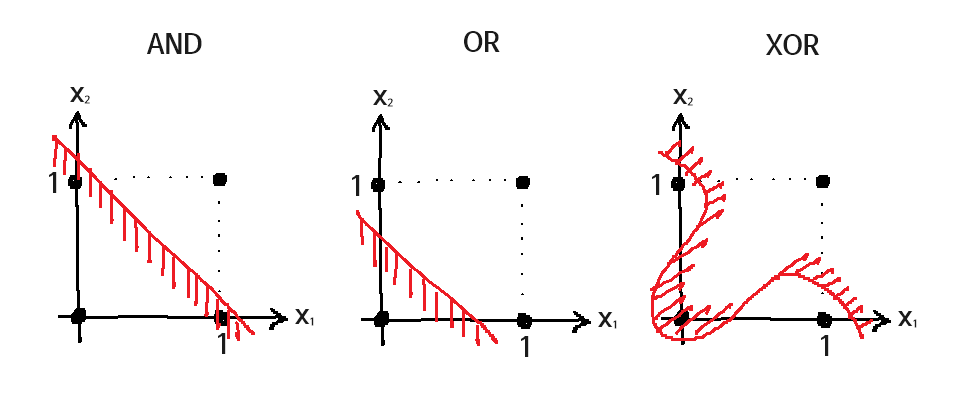
위 그래프에서 빨간 선을 기준으로 빗금이 있는 부분은 False, 없는 부분은 True를 의미한다. 단일 퍼셉트론만으로는 선형 분리가 가능한 문제만 해결할 수 있으므로, XOR 게이트처럼 직선 하나로 True/False를 구분할 수 없는 문제의 경우 구현이 불가능하다.
하지만 실제 XOR 게이트를 AND, OR, NAND 3개의 게이트의 조합으로 만드는 것처럼, 여러 층으로 구성된 다층 퍼셉트론을 이용한다면 구현이 가능해진다!
3. 신경망
신경망에서는 입력층과 출력층 사이에 여러 개의 '은닉층'이 추가로 존재할 수 있다.
은닉층은 입력층/출력층과 달리 직접적으로 보이지 않으며, 이 층이 많아질수록 더 복잡한 일을 수행할 수 있다.
활성화 함수
입력 신호의 총합을 출력 신호로 변환하는 일종의 래퍼 함수. 입력 신호의 총합이 활성화를 일으킬지를 결정함.
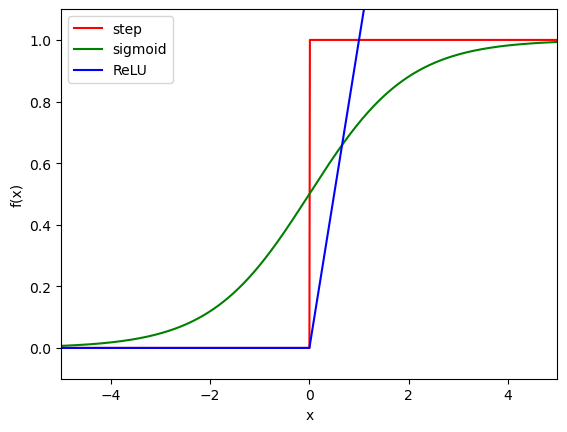
- 계단 함수: 입력이 0을 넘으면 1을 출력하고, 그렇지 않으면 0을 출력하는 함수. 기존 퍼셉트론에서 이용.
- 시그모이드 함수: , S자 형태의 곡선을 나타내며, 신경망에서 자주 이용됨.
- 공통점: 출력의 크기가 입력의 크기에 비례함. 출력은 0에서 1 사이의 값을 가짐. 비선형 함수임.
- 차이점: 시그모이드는 계단보다 '매끄러움', 즉 입력에 따라 출력이 연속적으로 변화함. (0과 1뿐 아니라 실수 포함)
- ReLU 함수: 입력이 0을 넘으면 그대로 출력하고, 그렇지 않으면 0을 출력하는 함수. 최근 신경망 분야에서 자주 이용됨.
선형 함수: 출력이 입력의 상수배만큼 변하는 함수. 꼴을 가짐.
- 신경망에서는 활성화 함수로 반드시 비선형 함수를 사용해야 함. 선형 함수를 사용하면 은닉층을 아무리 늘리더라도 '은닉층이 없는 네트워크'로도 똑같이 표현 가능하기 때문.
- ex. 를 활성화 함수로 사용한 3층 네트워크의 수식은 인데, 이는 을 활성화 함수로 사용한 단층 네트워크와 똑같음.
다차원 배열 계산
np.shape(배열): 배열의 차원 수를 반환함.ndarray.shape: 배열의 형상(각 차원의 원소 수)을 튜플로 반환함.np.dot(행렬A, 행렬B): 두 행렬의 내적(곱)을 반환함.- A의 1번째 차원의 원소 수(= 열 수)와 B의 0번째 차원의 원소 수 (= 행 수)가 같아야 함.
- 계산 결과는 A의 행 수와 B의 열 수를 가지는 행렬이 됨.
신경망 각 층마다 이루어지는 연산 과정은 행렬의 곱을 통해 표현할 수 있다. ()
X = np.array([1.0, 0.5])
W1 = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
B1 = np.array([0.1, 0.2, 0.3])
A1 = np.dot(X, W1) + B1 # 1층에서의 입력과 가중치 간 연산 결과
Z1 = sigmoid(A1)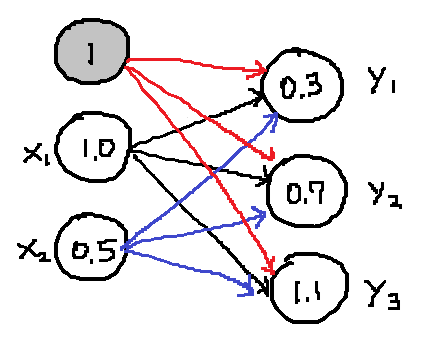
가중치 행렬의 형태는 입력 노드와 출력 노드의 개수에 따라 결정된다. 입력 노드가 N개이고 출력 노드가 M개라면, 가중치 행렬은 행렬 곱의 조건에 따라 N × M의 크기를 갖는다.
위 그림에서 검은색, 파란색 화살표들이 가중치 값이다. 입력 노드 하나 당 다음 층의 전체 노드를 가리키며, 입력 노드가 2개, 출력 노드가 3개이므로 총 가중치 행렬은 2 × 3의 크기가 될 것이다.
- 편향은 입력 노드와 가중치 간 곱셈이 먼저 수행된 후 더해지는 값이므로 출력 노드와 같은 개수를 갖는다.
출력층 설계
출력층에서의 활성화 함수는 풀고자 하는 문제의 성질에 맞게 정해야 한다.
- 항등 함수: 입력을 그대로 출력한다. 회귀 문제에서 사용한다.
- 소프트맥스 함수: (은 출력층의 뉴런 수, 는 그 중 k번째 출력이라는 뜻)
- 분류 문제에서 사용한다.
- 프로그래밍 시 오버플로를 막기 위해 분자, 분모의 e의 지수에서 입력 신호 중 가장 큰 값을 빼주기도 함.
- 각 출력은 0에서 1.0 사이의 실수이며, 출력의 총합은 1이 됨. => '확률'로 해석 가능!
- 각 원소의 대소 관계는 변하지 않음. (는 단조 함수이므로)
출력층의 뉴런 수 역시 풀려는 문제에 맞게 적절히 정해야 한다. 분류 문제에서는 분류하려는 클래스 수로 설정하는 것이 일반적이다.
- ex. 입력 이미지를 숫자 0부터 9 중 하나로 분류하는 문제 => 출력층 뉴런 10개 필요
실제 데이터 분류하기
기계학습의 문제 풀이는 모델에 대한 학습과 미지의 데이터에 대한 추론 두 단계를 거쳐 이루어짐.
신경망 역시 훈련 데이터를 통해 가중치 매개변수를 학습하고, 추론 단계에서 이를 이용하여 입력 데이터를 분류함.
이때, 추론 과정을 신경망의 순전파(forward propagation)라고도 함.
- 원-핫 인코딩: 정답을 뜻하는 원소만 1이고(= one-hot), 나머지는 0인 배열 형태로 변환하는 것.
- 전처리: 입력 데이터를 처리하기 전에 특정 변환을 가하는 것. (ex. 정규화)
- 정규화: 데이터를 특정 범위로 변환하는 처리. (ex. 0~255 범위인 각 픽셀의 값을 0.0~1.0 범위로 normalize)
입력 데이터와 신경망 각 층 가중치 매개변수의 형상은 연달아서 곱해질 수 있도록 대응되는 차원의 원소 수가 일치해야 한다.
- ex.
또한, 여러 개의 입력 데이터들을 하나의 묶음(배치)으로 만들어 처리할 수도 있다.
컴퓨터에서는 큰 배열을 한꺼번에 계산하는 것이 분할된 작은 배열을 여러 번 계산하는 것보다 빠름! (CPU/GPU 연산 시간 ≪ I/O 수행 시간)
np.argmax(array_like, axis?): 주어진 배열에서,axis번째 차원을 구성하는 각 원소에서 최댓값의 인덱스를 찾는다.- ex.
(4, 3)형태의 2차원 배열이 주어졌을 때,axis=0이면 3개의 열에서 각각,axis=1이면 4개의 행에서 각각 최댓값을 찾아서 배열로 반환함.
- ex.
4. 신경망 학습
신경망(딥러닝)은 데이터를 보고 가중치 매개변수의 값, 즉 '특징'을 자동으로 찾아낼 수 있음. => 인간의 개입이 필요하지 않음, 스스로 처음부터 끝까지 학습한다!
- 기계학습 문제는 데이터를 훈련 데이터와 시험 데이터로 나눠 학습과 실험을 수행함.
- 범용 능력: 훈련 데이터에 포함되지 않는 '아직 보지 못한 데이터'로도 올바르게 문제를 풀어내는 능력.
- 오버피팅: 특정 데이터셋에만 지나치게 최적화된 상태. 범용 능력을 해친다.
손실 함수
신경망 학습에서 현재 상태를 표현하기 위해 쓰는 대표적인 '지표'.
학습의 목적은 이 지표를 가장 좋게 만들어주는(= 손실 함수의 값을 최소화하는) 가중치 매개변수의 값을 찾는 것.
- 평균 제곱 오차: (는 신경망의 출력, 는 정답 레이블)
- 교차 엔트로피 오차:
- 이때 는 원-핫 인코딩된 값으로, 정답일 때만 1이고 나머지는 0이므로 실제로는 정답일 때의 출력(추정값)이 전체 값을 정하게 됨. (= '정답을 얼마나 확신했니?')
- 실제 프로그래밍 시에는 로그값이
-inf가 되는 걸 막기 위해 에 아주 작은 값을 더해서 씀.
학습해야 할 데이터셋이 매우 큰 경우, 그 중 일부만 골라 학습을 수행할 수도 있음. (= 미니배치 학습)
np.random.choice(n, r): 0부터n미만의 수 중r개의 수를 무작위로 골라 배열로 반환함.
왜 손실 함수를 쓸까?
학습의 지표로 손실 함수가 아닌 정확도, 즉 'k개의 실험 데이터 중 몇 개를 맞추었는지'를 사용하는 게 더 간단하지 않을까? 어차피 궁극적인 목적은 최대한 많이 정답을 맞추는 거니까...
결론은 안 된다.
-
신경망 학습에서는 매개변수 값을 아주 조금 변화시킨 후, 손실 함수의 값이 줄었는지 늘었는지를 보고 매개변수를 어느 쪽으로 바꿔야 할지를 판단한다. (= 손실 함수의 미분, 기울기)
-
그러나 정확도는 값이 이산적이므로 대부분의 구간에서 미분값이 0이다. 즉, 매개변수 값의 미세한 변화가 정확도를 변화시킬 확률이 매우 적고, 값이 변하더라도 불연속적으로 일어나게 된다. (활성화 함수에서 계단 함수 대신 부드러운 형태의 시그모이드 함수를 사용하는 것과 같은 이유!)
수치 미분
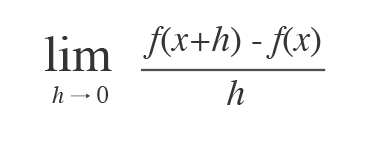
미분 = 기울기 = 순간변화율
- 차분: 임의의 두 점에서의 함수 값들의 차이.
- 수치 미분: 아주 작은 차분으로 미분을 구하는 것. 프로그래밍 시 와 같은 값을 사용함.
- 전방 차분:
- 중심/중앙 차분: , 수치 미분의 오차를 줄이기 위해 사용 (분모는 )
- 해석적 미분: 실제 수식을 전개하여 미분을 구하는 것. 오차를 포함하지 않는 '진정한 미분' 값.
- 편미분: 변수가 여럿인 함수에 대한 미분. 미분 시 어느 변수에 대한 미분인지를 구별해야 함.
- 관심이 있는 변수만 변수로 두고, 나머지 변수들은 값을 고정하여 새로운 함수를 정의하자.
- 기울기: 모든 변수에 대한 편미분을 벡터로 정리한 것. 수식으로 와 같이 표현함.
np.zeros_like(array_like): 주어진 매개변수와 형상이 같고 모든 원소가 0인 배열을 반환함.
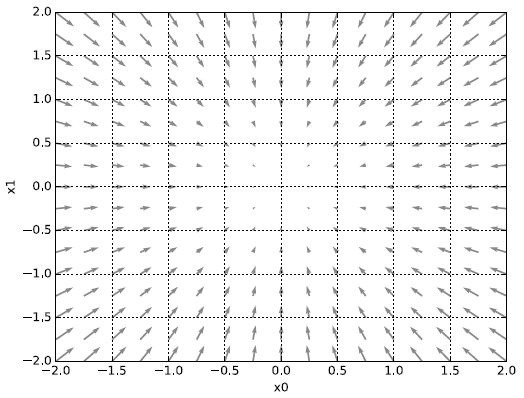
위 그림은 의 기울기를 그림으로 표현한 것이다. 각 점의 벡터(화살표)가 함수의 '가장 낮은 곳'을 가리키고 있으며, 가장 낮은 곳에서 멀어질 수록 벡터의 크기가 커지는 것을 볼 수 있다.
"기울기가 가리키는 쪽은 각 위치에서 함수의 출력값을 가장 크게 줄이는 방향이다."
최적의 매개변수는 손실 함수의 값을 최소로 만드는 매개변수이므로,
기울기를 이용해서 손실 함수의 값이 낮아지는 방향을 찾을 수 있지 않을까?
- 경사하강법: 매 위치에서 기울어진 방향으로 일정 거리만큼 이동하는 것을 반복하며 함수의 값을 점차 줄이는 기법. 기계학습의 최적화 문제, 특히 신경망 학습에서 자주 사용됨.
- 물론 기울기가 0이 되는 곳이 항상 최솟값인 건 아님. (ex. 극솟값, 안장점, 고원)
- 수식으로 나타내면 , (는 학습률)
- 학습률: 한 번의 학습으로 얼마만큼 학습해야 할지, 즉 매개변수 값을 얼마나 변화시킬 것인지를 결정함.
- 학습률이 너무 크면 큰 값으로 발산하고, 너무 작으면 그만큼 더 많은 횟수의 학습이 필요함.
- 하이퍼 파라미터: 자동으로 획득되는 가중치나 편향과 달리 사람이 직접 설정해야 하는 매개변수. 여러 후보 값들 중 시험을 통해 가장 학습에 용이한 값을 찾는 과정을 거쳐야 함.

신경망 학습에서는 가중치 매개변수에 대한 손실 함수의 기울기를 구해야 한다.
이때 손실 함수의 편미분 값의 형상은 가중치 매개변수의 형상과 같으며, 이 값을 보고 각각의 가중치 값들을 '어떤 방향으로 변화시켜야 좋을지'를 판단할 수 있다.
학습 알고리즘 구현하기
- 신경망 학습 절차: 미니배치 → 기울기 산출 → 매개변수 갱신 → (반복)
- 확률적 경사 하강법(SGD): 미니배치를 통해 '확률적으로 무작위로 골라낸 데이터'에 대하여 수행하는 경사 하강법.
학습을 반복할 수록 손실 함수의 값은 점차 내려가지만, 이는 '훈련 데이터의 미니배치에 대한 손실 함수'이므로 다른 데이터셋에서도 비슷한 실력을 보일지는 확실하지 않음.
따라서 훈련 데이터 외의 데이터를 올바르게 인식하는지(즉, 오버피팅을 일으키지 않는지) 확인해야 함.
=> 1에폭마다 훈련 데이터와 시험 데이터에 대한 정확도를 각각 기록하여 서로 비교해 보자!
- 에폭(epoch): 학습에서 훈련 데이터를 모두 소진했을 때의 횟수에 해당하는 단위.
- ex. 10,000개의 훈련 데이터를 100개의 미니배치로 학습 시, 확률적 경사 하강법 100회 = 1에폭
- 조기 종료(ealry stopping): 시험 데이터에 대한 정확도가 훈련 데이터에 대한 정확도보다 떨어지기 시작하는 시점(즉, 오버피팅이 일어나기 시작하는 시점)에서 학습을 중단하는 것.
정리
강의를 듣기 전까지 거의 비슷한 용어로 느껴졌던 퍼셉트론과 신경망의 차이를 명확히 알게 되었다.
퍼셉트론은 단일 신경망의 가장 기본적인 종류라 할 수 있고, 은닉층 없이 입력층과 출력층으로만 구성되며, 활성화 함수는 계단 함수를 사용하여 0 또는 1의 출력값만을 가진다. (반면, 신경망에서는 반드시 활성화 함수로 시그모이드와 같은 함수를 사용해야 함)
또한 손실 함수의 값을 최소화하기 위한 수단으로 미분, 기울기를 사용한다는 말의 의미를 더 직접적으로 이해할 수 있었다. 각 층마다 입력, 가중치, 편향 간의 연산을 전부 행렬 연산으로 표현할 수 있다는 것도 알게 되었다.
