생활코딩 - Tensorflow 102 강의를 듣고 요약, 필기한 내용입니다.
'차원'이란?
맥락에 따라 서로 다른 두 가지 뜻으로 쓰임.
- 데이터 공간의 관점: 데이터에서 변수의 개수가 곧 공간의 차원수가 됨. 관측치는 N차원 공간에서의 한 점으로 취급.
- 모든 경우의 수들 중 어느 하나를 구별 가능한 형태로 표현하기 위하여?
- 데이터 형태의 관점: 데이터를 표현하는 배열의 깊이가 곧 차원수가 됨. 예를 들어 표는 2차원 데이터임.
- tensor: 여러 차원 형태로 구성된 데이터
이미지 데이터
컴퓨터 입장에서 흑백 이미지는 각 픽셀마다 숫자(명도) 값을 가진 2차원 형태의 데이터임. (가로 N, 세로 M)
이때 이미지 하나는 각 픽셀을 변수로 취급하여 (N × M)차원 공간의 한 점으로 취급됨.
- 이미지 하나는 단일 관측치이고, 단일 관측치 기준으로 변수 하나 당 숫자(값) 하나가 대응됨을 떠올리기.
변수 개수 = 숫자 개수 = 차원수
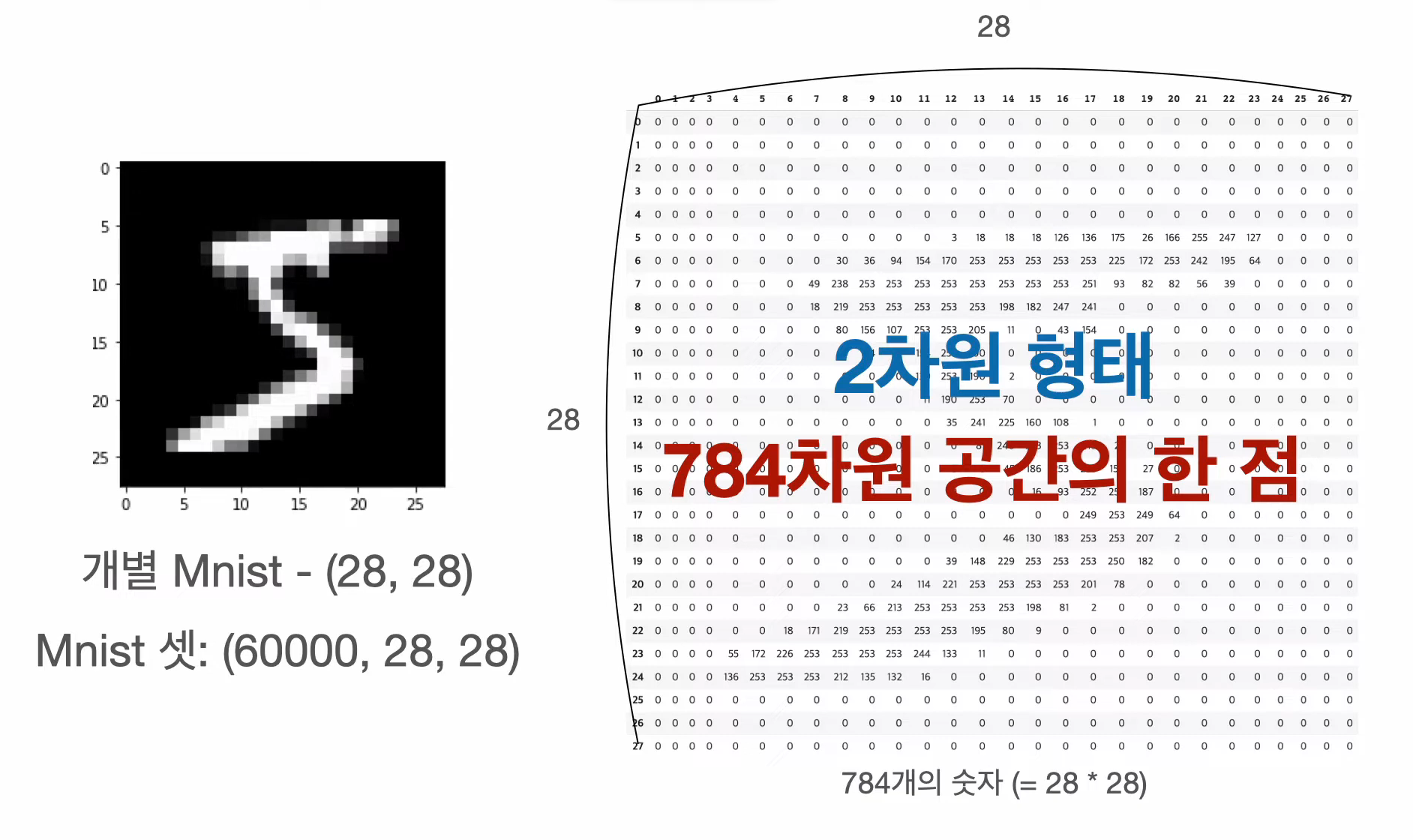
컬러 이미지의 경우 각 픽셀마다 R/G/B 3개의 값을 추가로 가짐. 즉, 차원이 하나 더 늘어난 3차원 형태의 데이터이며, 이미지 하나는 (N × M × 3)차원 공간의 한 점으로 취급됨.

- ex. 가로 32픽셀, 세로 32픽셀의 컬러 이미지 1000장으로 구성된 데이터는 (1000, 32, 32, 3)으로 표현되는 4차원 형태의 데이터가 됨.
이미지 출력
matplotlib 라이브러리를 활용하여 이미지를 코드를 통해 화면 상에 출력할 수 있다.
import tensorflow as tf
(mnist_x, mnist_y), _ = tf.keras.datasets.mnist.load_data()
print(mnist_x.shape, mnist_y.shape)
# (60000, 28, 28) (60000,)
import matplotlib.pyplot as plt
# 흑백 이미지 출력을 위해 cmap 옵션 추가
plt.imshow(mnist_x[0], cmap='gray')
# mnist_x[0] 이미지에 대응되는 카테고리 출력
print(mnist_y[0])- MNIST: 손글씨 숫자 이미지들로 이루어진 대형 데이터셋.
- CIFAR-10/CIFAR-100: 라벨이 붙은 작은 이미지들로 이루어진 데이터셋. (링크)
데이터 형태 확인
데이터의 차원 확인은 numpy 라이브러리의 array()을 사용하자.
import numpy as np
d1 = np.array([1, 2, 3, 4, 5])
print(d1.shape) # (5,) / 1차원 데이터
d2 = np.array([d1, d1, d1, d1])
print(d2.shape) # (4, 5) / 2차원 데이터
d3 = np.array([d2, d2, d2])
print(d3.shape) # (3, 4, 5) / 3차원 데이터- CIFAR 데이터셋의 종속변수
cifar_y의 형태를 출력해 보면(50000, 1), 즉 2차원으로 나오는데, 이는[[1], [2], [3], ...]과 같이 원소가 하나인 배열을 여러 개 갖고 있는 구조이다.(1, 50000)과 혼동하지 않도록 유의
Flatten
reshape() 함수를 통해 크기 28 × 28의 이미지를 픽셀 784개로 이루어진 1차원 배열로 변환할 수 있다.
print(독립.shape) # (60000, 28, 28)
독립.reshape(60000, 784)
print(독립.shape) # (60000, 784)=> 이미지 데이터를 기존의 표 데이터와 동일하게 다룰 수 있음!
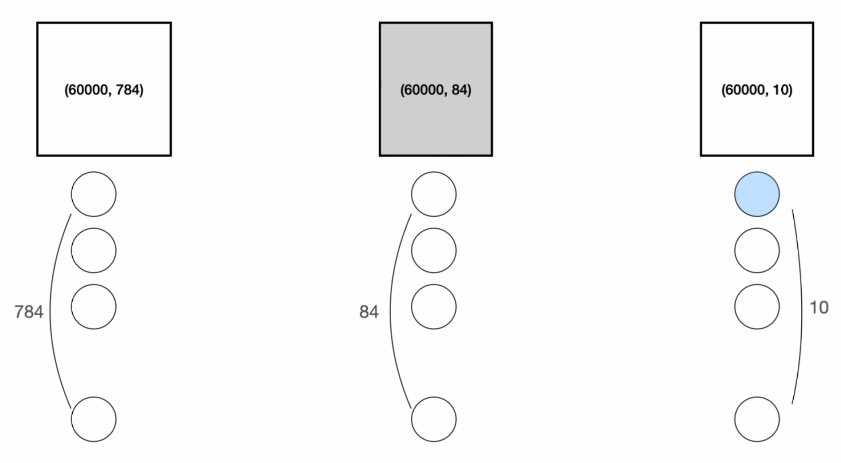
- 칼럼 = 변수 = 특징
- 가중치가 높게 부여된 변수 = 판단에 있어 중요도가 높은 변수
- n개의 노드로 이루어진 히든 레이어 추가 = 중간 결과로 판단을 위한 특징 n개를 찾아달라!
- 인공 신경망 = '특징 자동 추출기'
reshape()와 동일한 동작을 Flatten()을 통해 모델 내에서 수행할 수도 있음.
print(독립.shape) # (60000, 28, 28)
# 데이터가 2차원 형태이므로 shape 값도 달라짐
X = tf.keras.layers.Input(shape=[28, 28])
# 평탄화 수행
H = tf.keras.layers.Flatten()(X)
H = tf.keras.layers.Dense(84, activation='swish')(H)
H = tf.keras.layers.Dense(10, activation='softmax')(H)컨볼루션
컨볼루션(Convolution): 이미지에서 어떠한 패턴의 특징이 어느 위치에서 나타나는지를 확인하는 도구.
ex. 숫자 '9'는 원이 위쪽에서, '6'은 원이 아래쪽에서, '8'은 원이 위-아래 양쪽에서 나타남.
특징맵(Feature map): 원본 이미지와 컨볼루션 필터 간의 연산 결과. 2차원 형태의 숫자 집합이므로 이미지로 표현 가능.
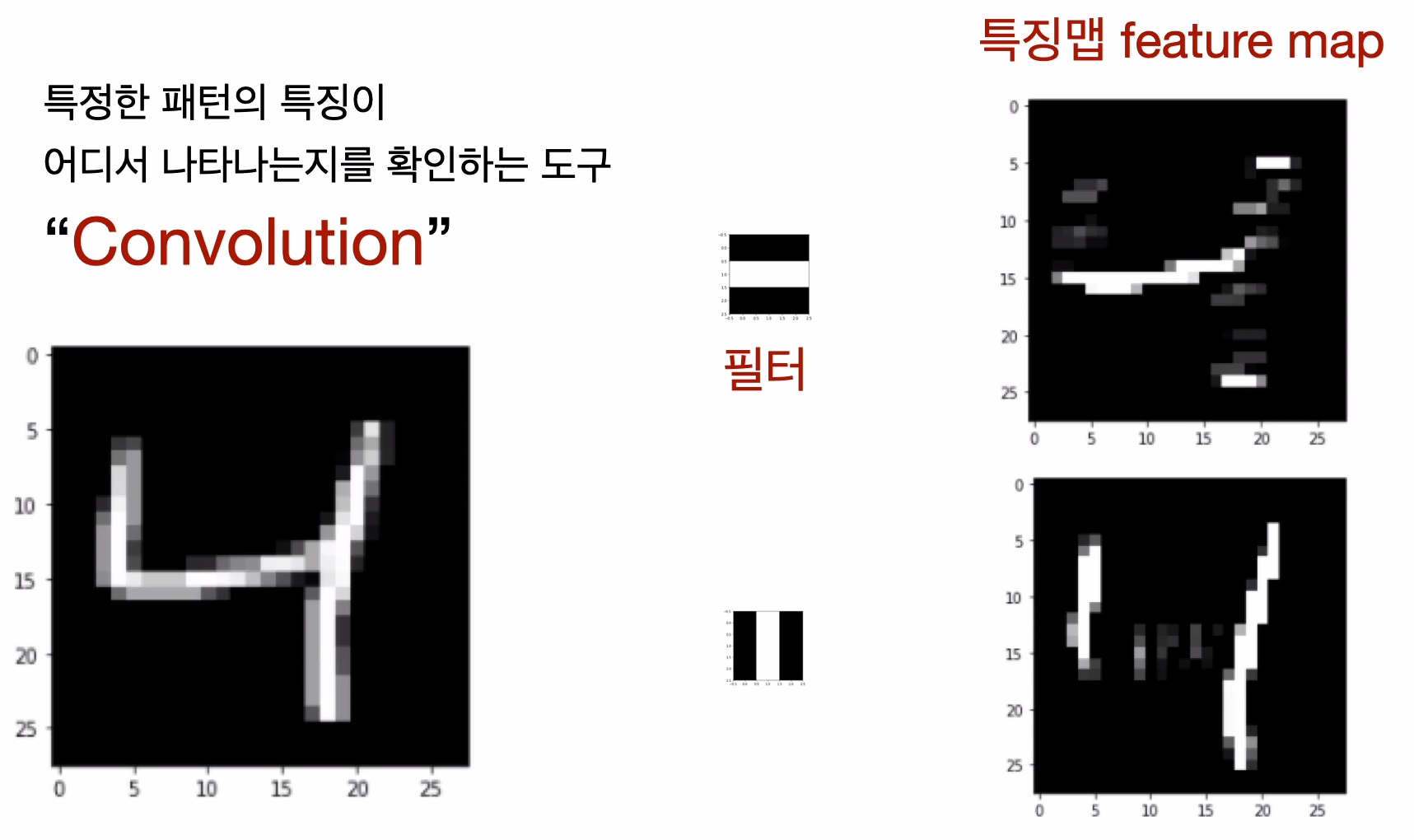
컨볼루션 레이어에서는 필터를 몇 개 사용할지, 사이즈를 얼마로 할 것인지를 결정해야 함.
- '필터 하나 당 이미지 하나를 만든다.'
- 필터 3개는 3개의 특징맵(= 3채널의 특징맵)을 만듦.
컨볼루션 연산은 3차원 형태의 관측치를 입력으로 받도록 정해짐. => 흑백 이미지도 3차원 형태로 reshape 필요.
필터의 이해
- 개별 필터는 3차원 형태로 된 가중치의 모음임.
(가로, 세로, 채널 수 = 이전 특징맵의 채널 수)
- 필터는 앞선 레이어의 결과인 특징맵 전체를 봄.
- 신경망에서 각 노드 하나 당 이전 층의 노드 전체를 학습에 사용하는 것과 동일!
- 따라서 항상 필터 개수만큼의 특징맵이 만들어지며, 그 다음 필터들은 각각 이전 특징맵만큼의 채널을 가짐
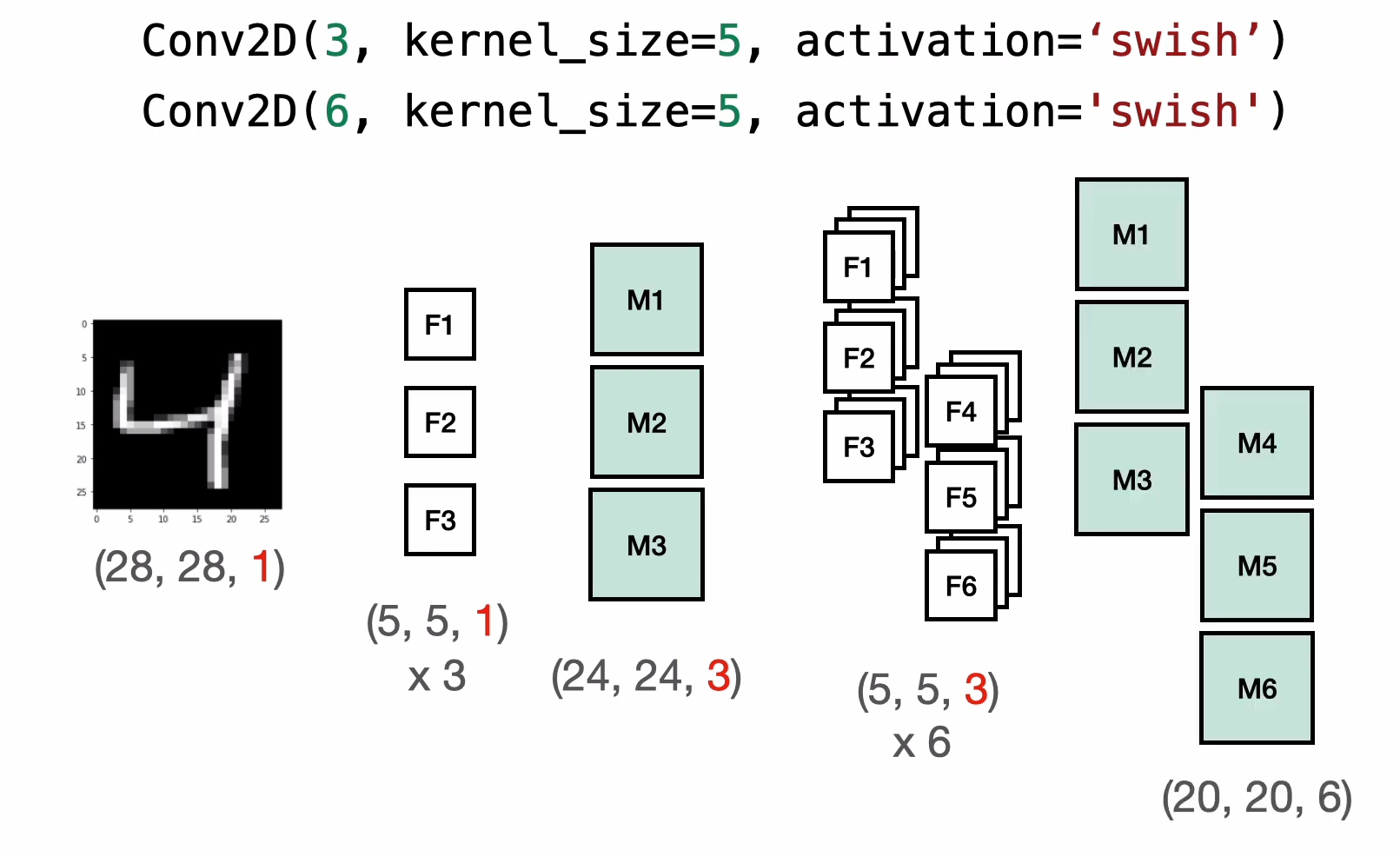
필터를 6개 추가하는 것 = 컴퓨터에게 이미지 판단을 위한 가장 좋은 특징맵 6개를 찾아달라 하는 것! => '특징 자동 추출기'
연산의 이해
컨볼루션 연산: 원본 이미지와 필터를 겹쳐놓은 후, 서로 대응되는 픽셀끼리 곱한 것들의 총합을 가장 좌측 상단의 결과로 함.
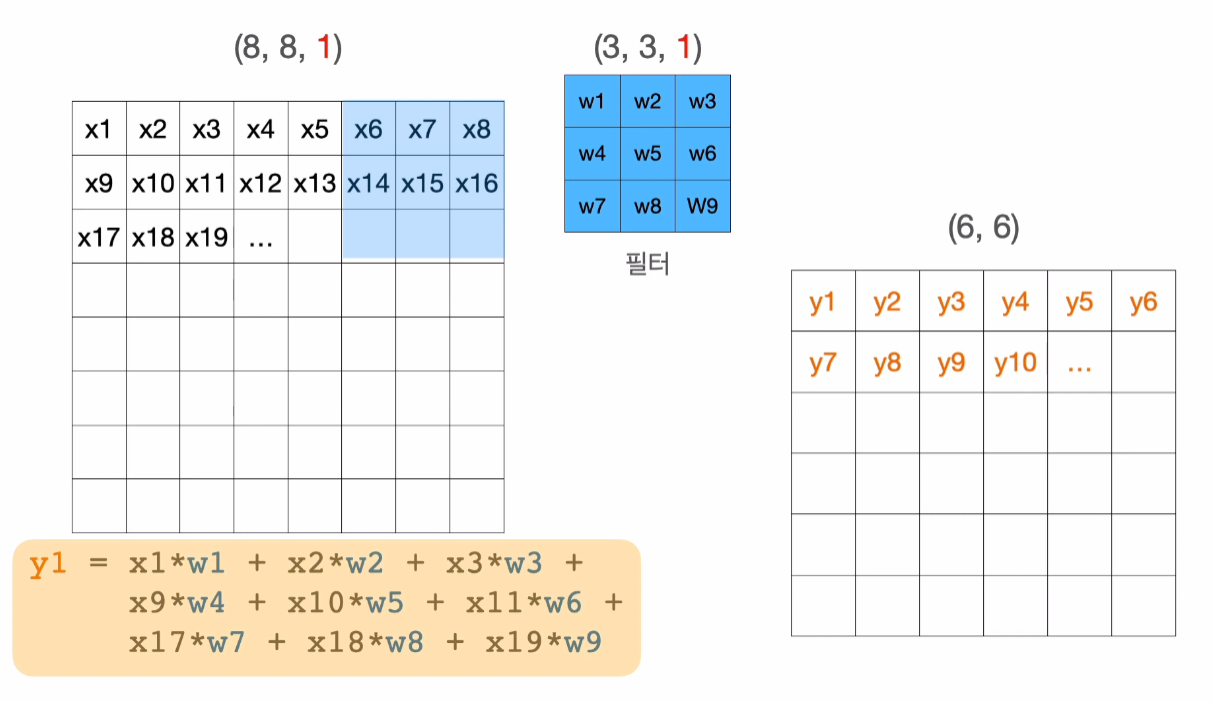
- 결과 특징맵의 크기는
이전 특징맵 크기 - (필터 크기 - 1)으로 줄어듦. - 만들어진 수식
y1 = x1 * w1 + ...는 기존 퍼셉트론의 수식과 동일한 형태! 조합만 살짝 달리 한 것.
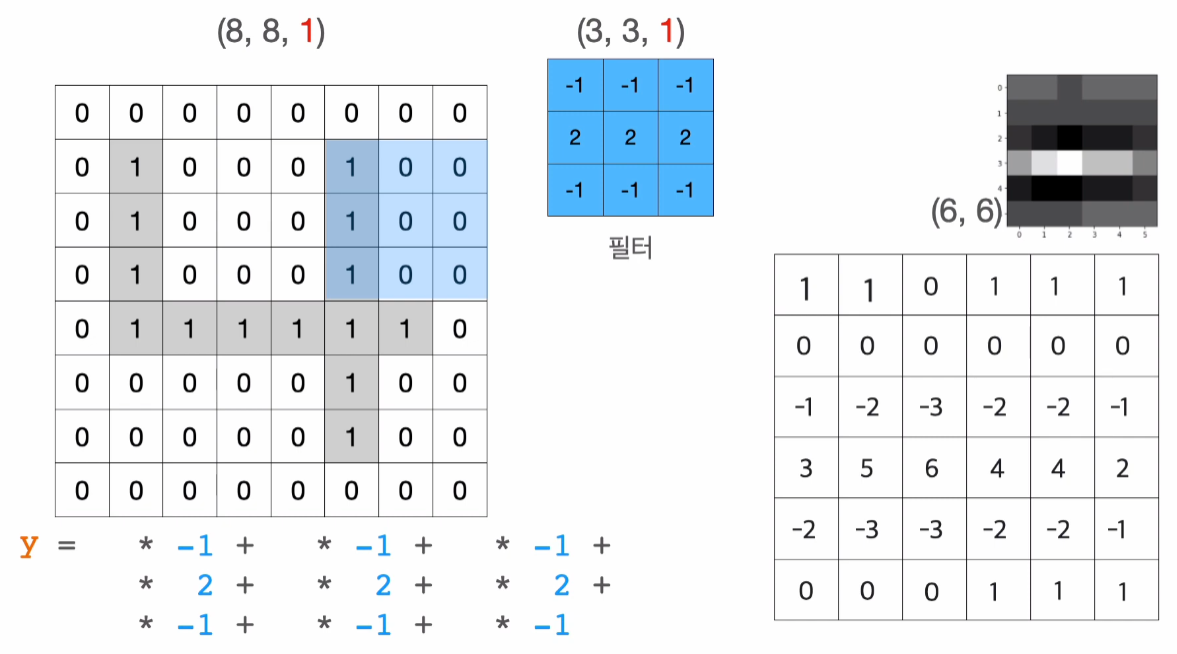
"실제로는 컨볼루션 모델을 통해서 딥러닝 모델을 만들면, 컴퓨터가 적절한 필터를 자동으로 찾아준다.
컴퓨터가 찾은 필터가 어떤 특징을 찾은 것인지 사람은 해석하지 못한다.
다만 그 필터가 찾아낸 특징맵이 최적의 결과를 만들어내는 특징맵이라는 것만 알 수 있을 뿐이다."
기존 퍼셉트론 수식에서 가중치 w를 사람이 직접 찾지 않고 학습을 통해 컴퓨터가 찾아나가는 것과 동일한 이유인 것 같다. (필터는 3차원 형태의 가중치들의 모음이라고 했으니까)
우리는 가중치 데이터의 형태(가로 몇, 세로 몇)만 정해주고 정확한 값은 컴퓨터가 계산하도록 두는 것이다.
Conv2D 코드
- 데이터를 준비한다.
import tensorflow as tf
import pandas as pd
(독립, 종속), _ = tf.keras.datasets.mnist.load_data()
# 흑백 이미지를 3차원 형태의 데이터로 변환
독립 = 독립.reshape(60000, 28, 28, 1)
# 범주형 값이므로 원핫-인코딩 수행
종속 = pd.get_dummies(종속)
print(독립.shape, 종속.shape)
# (60000, 28, 28, 1) (60000, 10)- 모델을 생성한다.
# 이미지의 데이터 형태에 맞춰 shape 작성
X = tf.keras.layers.Input(shape=[28, 28, 1])
# 두 개의 필터 레이어를 추가하고
H = tf.keras.layers.Conv2D(3, kernel_size=5, activation='swish')(X)
H = tf.keras.layers.Conv2D(6, kernel_size=5, activation='swish')(H)
# 표 형태로 다룰 수 있도록 평탄화
H = tf.keras.layers.Flatten()(H)
H = tf.keras.layers.Dense(84, activation='swish')(H)
Y = tf.keras.layers.Dense(10, activation='softmax')(H)
model = tf.keras.models.Model(X, Y)
model.compile(loss='categorical_crossentropy', metrics='accuracy')- 모델을 데이터로 학습시킨 후, 이용한다.
model.fit(독립, 종속, epochs=10)
pred = model.predict(독립[0:5])
pd.DataFrame(pred).round(2)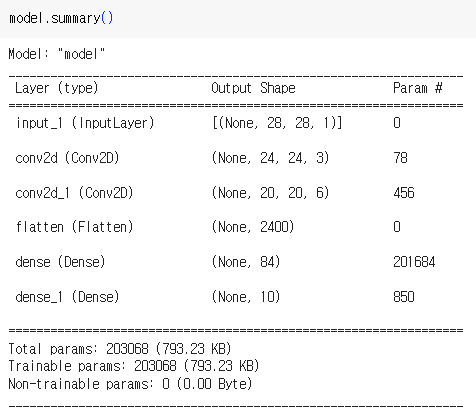
- 필터 레이어를 거치며 크기가 줄어드는 이미지(특징맵)
- 학습하게 되는 파라미터의 개수가 매우 많아짐.
- 입력: Flatten 직후의 변수 2400개 (+ 바이어스 1개)
- 출력: Dense 레이어의 변수 84개
- 즉, 해당 레이어의 가중치 개수는 (2400 + 1) × 84 = 201,684개
Pooling
Flatten 레이어 이후에 사용되는 가중치 개수를 적게 유지하기 위해, 입력으로 사용할 칼럼 수를 조정하는 것.
MaxPooling: 입력 데이터를 2×2 단위로 분할하고, 각 영역마다 가장 큰 수를 하나의 결과 단위로 삼는 방식.
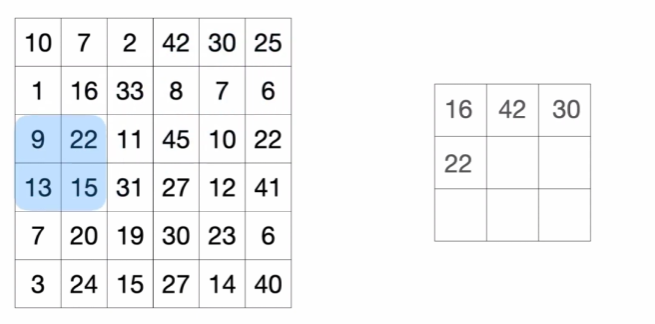
- 이때 입력 데이터는 특징맵이므로, 값이 크다는 것은 필터로 찾으려는 특징이 많이 나타난 부분이라는 뜻이다.
- 즉, MaxPooling을 통해 유의미한 정보를 남기면서 크기를 줄이는 것이 가능함!
# 2번의 풀링 절차 추가
H = tf.keras.layers.Conv2D(3, kernel_size=5, activation='swish')(X)
H = tf.keras.layers.MaxPool2D()(H)
H = tf.keras.layers.Conv2D(6, kernel_size=5, activation='swish')(H)
H = tf.keras.layers.MaxPool2D()(H)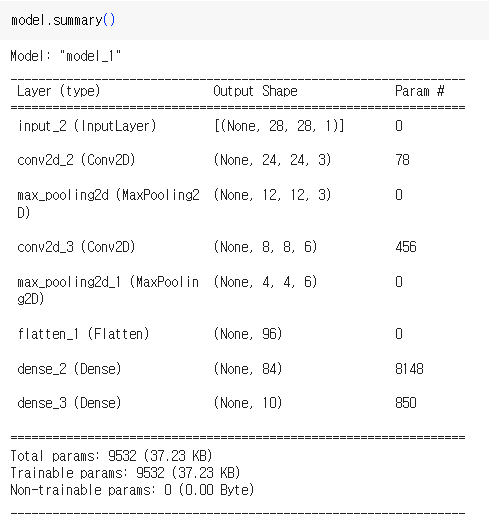
- Pooling을 거칠 때마다 크기가 절반씩 떨어지는 것을 확인 가능.
- 기존 모델에 비해 정확도도 크게 떨어지지 않음!
- 여기까지가 가장 기본적인 CNN 모델.
LeNet
LeNet-5: 1998년 제안된 최초의 컨볼루션 신경망(Convolutional Neural Networks, CNN) 구조.
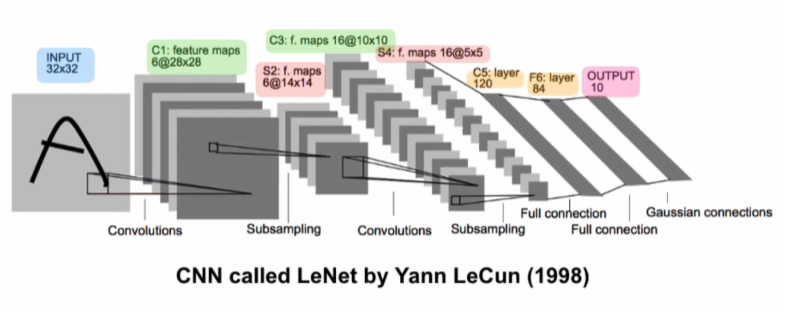
- 컨볼루션 레이어에
padding='same'옵션을 주면 컨볼루션의 결과인 특징맵의 크기가 입력 이미지와 동일한 크기로 출력됨. - 원핫-인코딩을 위한
pd.get_dummies()함수는 1차원 데이터를 대상으로 동작한다. 2차원 데이터라면reshape()메서드를 통해 직접 변환해 줘야 함.
로컬 이미지 사용하기
import glob
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 이미지 파일들을 전부 불러와서
paths = glob.glob('./my_images/*/*.png')
# 랜덤으로 섞음
paths = np.random.permutation(paths)
# 모든 이미지를 순차적으로 읽어서 독립변수로 설정
독립 = np.array([plt.imread(paths[i]) for i in range(len(paths))])
# 각 이미지가 포함된 폴더명을 종속변수(정답)로 설정
종속 = np.array([paths[i].split('/')[2] for i in range(len(paths))])
# 이후 적절히 reshape 및 원핫-인코딩 수행느낀 점
표가 아닌 이미지 데이터를 기계가 어떻게 다루고 학습하는지 알게 해준 유익한 강의였다. 물론 처음 OT에서 소개했던 대로, 강의를 들을수록 오히려 궁금한 점이 더 많아지는 기분이 들기도 했다.
CNN의 기본적인 원리와 가장 간단한 모델을 직접 만들어 보면서 넓고 얕은 이해를 쌓았다. 이제 궁금한 부분을 하나씩 깊게 파고들면서 공부해 보자.
