
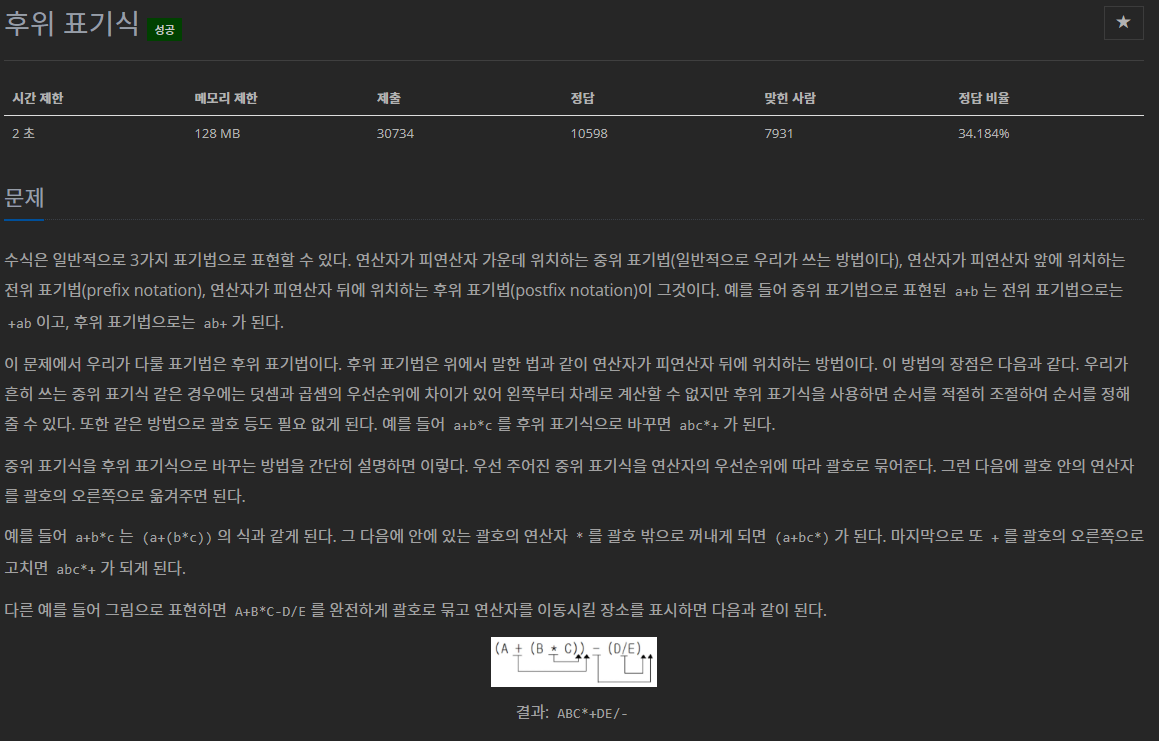
일반적인 사칙연산기호 및 괄호로 이루어진 식을 후위 표기식 형태로 변환하는 문제이다.
주어진 문자열의 각 문자를 탐색하며 조건에 따라 적절한 처리법을 떠올리고 분기 처리하는 것이 중요하다.
골드 상위권 문제라 역시 쉽지 않았다... 반례를 보며 겨우 풀었다.
num = []
oper = []
s = input().rstrip()
for a in s:
if "A" <= a <= "Z":
num.append(a)
if oper and (oper[-1] == "*" or oper[-1] == "/"):
temp = num.pop()
num.append(num.pop() + temp + oper.pop()) # 즉시 한 번 연산
elif a == "+" or a == "-":
while oper and len(num) >= 2:
if oper[-1] == "(":
break
temp = num.pop()
num.append(num.pop() + temp + oper.pop()) # '('을 만날 때까지 계속 연산
oper.append(a)
elif a == ")":
while oper and len(num) >= 2:
if oper[-1] == "(":
oper.pop()
break
temp = num.pop()
num.append(num.pop() + temp + oper.pop()) # '('을 만날 때까지 계속 연산
if oper[-1] == "*" or oper[-1] == "/": # 괄호를 처리했을 때 '*', '/' 연산자가 앞에 남아있다면
temp = num.pop()
num.append(num.pop() + temp + oper.pop()) # 추가로 한 번 더 연산
else:
oper.append(a)
while oper and len(num) >= 2:
temp = num.pop()
num.append(num.pop() + temp + oper.pop())
print(num.pop())내 코드의 경우엔 피연산자 스택(num)과 연산자 스택(oper)을 따로 두고, 이번 문자가 피연산자일 때와 연산자일 때 각각 연산 수행 분기가 있다. 연산 수행 후엔 결과값을 다시 피연산자 스택에 넣는다. 그래서 괜히 더 복잡해진 느낌이다.
그래서 구글링을 하다가 다른 분의 블로그에서 더 명확한 코드를 발견했다.
strn = list(input())
stack = []
res = ""
for s in strn:
if s.isalpha():
res += s
else:
if s == "(":
stack.append(s)
elif s == "*" or s == "/":
while stack and (stack[-1] == "*" or stack[-1] == "/"):
res += stack.pop()
stack.append(s)
elif s == "+" or s == "-":
while stack and stack[-1] != "(":
res += stack.pop()
stack.append(s)
elif s == ")":
while stack and stack[-1] != "(":
res += stack.pop()
stack.pop()
while stack:
res += stack.pop()
print(res)연산자 스택 하나만 사용하고, 이번 문자가 피연산자일 경우 바로 결과 문자열에 추가한다. 현재 문자가 연산자라면 스택에 있는 자신보다 우선순위가 낮거나 같은 연산자들을 모두 꺼낸다. ')'일 경우 마지막에 '('도 날려준다.
내가 이렇게 코드를 짜지 못한 이유는 후위 표기식을 제대로 이해하지 못했기 때문이다.
후위 표기식은 중위 표기식과 달리 연산자가 연속으로 배치될 수 있으므로 피연산자 스택을 따로 둘 필요가 없었다. (우선순위에 따라 연산자를 계속 뿌려준다)

공부용 블로그