시작!
이전에 PLG를 도입했었는데 욕심이 조금 더 생겼다.
어차피 Grafana가 올라가 있으니 다른 모니터링을 추가해서 볼 수 있으면 했다.
생각했던 후보로는 서비스에서 주로 모니터링이 필요했던
- WAS
- Oracle DB
- 네트워크(스위치)
정도가 되었다.
WAS는 PLG를 사용하면서 정확하게는 현재는 Log를 관찰하고 있고
네트워크(스위치)는 모니터링이 자체적으로 구축되어있어서 내가 또 만들 필요는 따로 없었다.
Oracle DB는 생각보다 문제가 있는 경우가 간혹 있었고 모니터링 자체가 없었기 때문에 Oracle DB를 모니터링하기로 결정했다.
과정
최종 목표
- PLG(WAS Log 모니터링)
- Oracle 상태 모니터링
- 특정 기준 부합 시 Alert Message 시스템
사전 파악
우선은 필요했던 기술은 Oracle Exporter가 필요했다.
Oracle Exporter는 DB로 쿼리를 날려 매트릭 값들을 가져오는 것이다.
쿼리를 지속적으로 날리면 리소스는 얼마나 잡아먹지..?
다행히 생각보다는 잡아먹지 않았다.
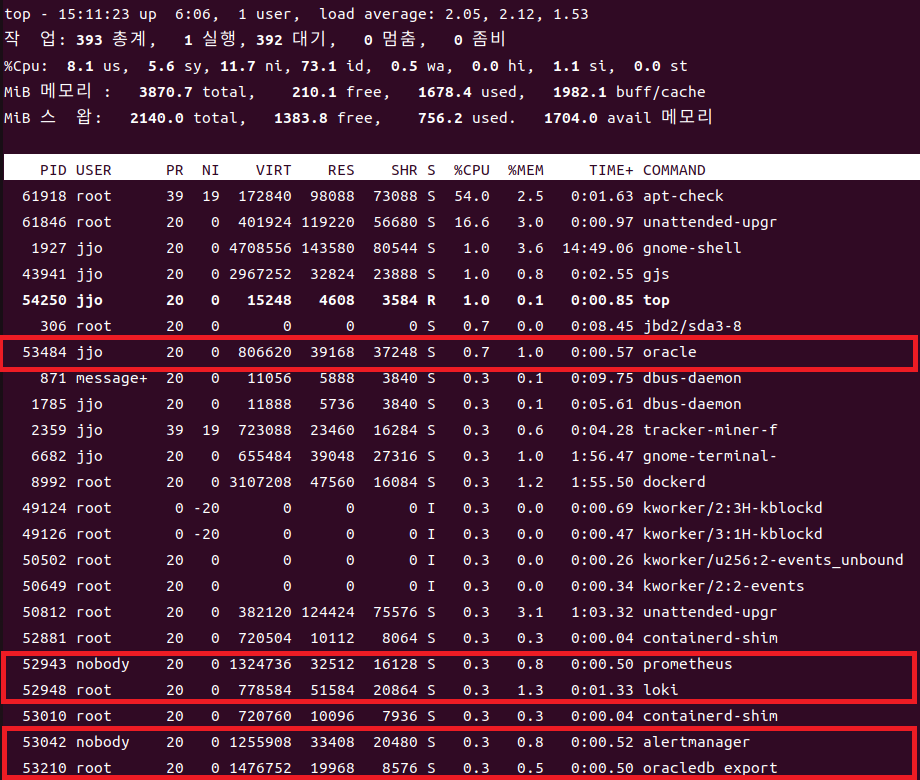
서버에서 리소스는 크지 않고 Oracle에서의 부하도 크지 않았다.
생각보다 중요했던 포인트인게, 내가 욕심에 하는 일인데 서비스에 지장이간다면 주제넘는 행동이 되기엔 시간문제이기 때문이다.
설계
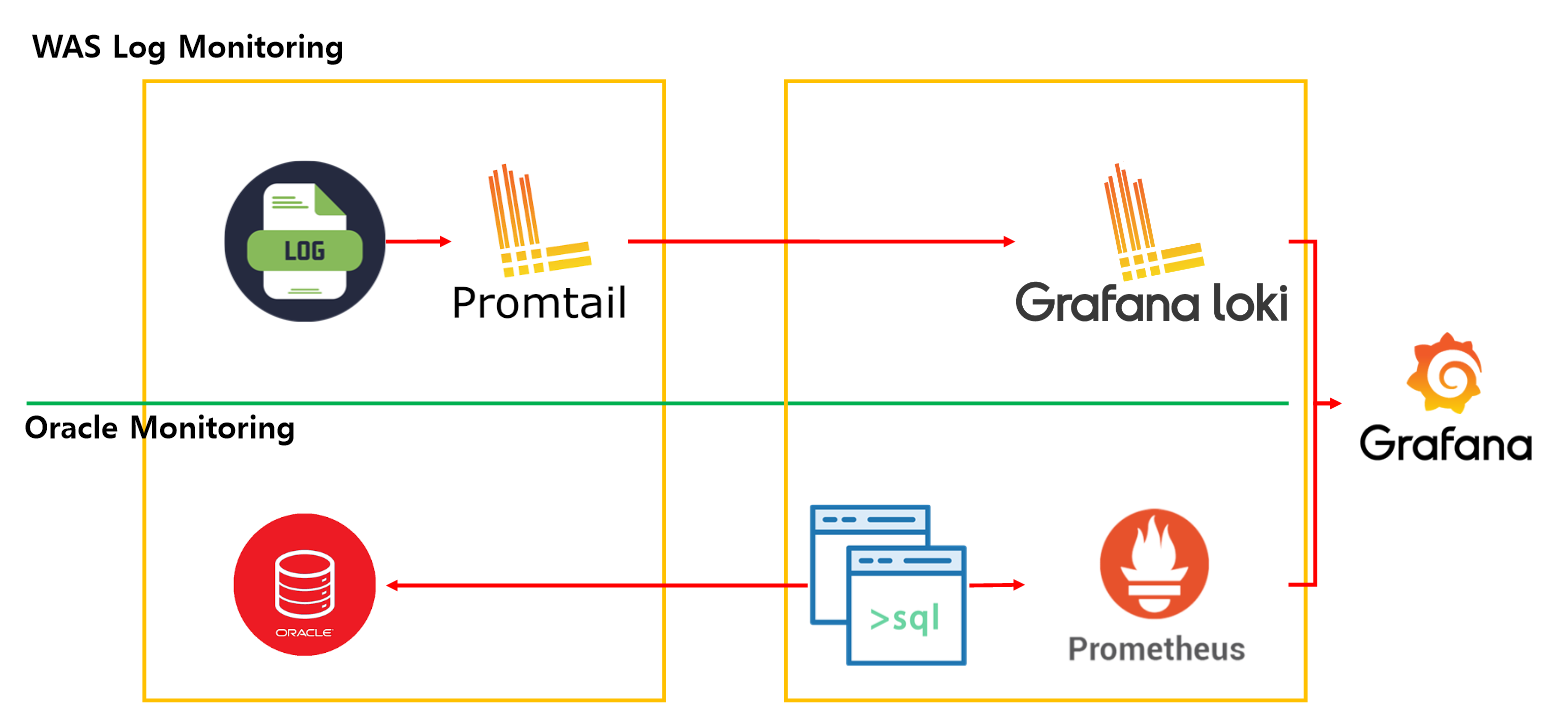
기존에 있던 PLG에 Prometheus와 Oracle Exporter를 띄우면 된다.
서버에 올릴 서비스는 총 5개로
- Grafana
- Loki
- Prometheus
- Oracle Exporter
- Alert Manager
Prometheus에서 특정 기준을 넘기면 Alert 메시지를 보내는 기능까지 포함이다.
구현
- docker-compose.yml
version: '3.8'
services:
oracle:
image: oracleinanutshell/oracle-xe-11g
container_name: db-cms-oracle
hostname: oracle
restart: on-failure
ports:
- "1522:1522"
- "8080:8080" # Oracle Enterprise Manager HTTP port
environment:
ORACLE_SID: XE
ORACLE_PWD: oracle
ORACLE_USERNAME: system
ORACLE_ALLOW_REMOTE: true
volumes:
- oradata:/oradata/orcl
networks:
- monitoring-network
deploy:
restart_policy:
condition: on-failure
delay: 10s
max_attempts: 10
window: 120s
loki:
image: grafana/loki:2.9.1
container_name: db-cms-loki
ports:
- "3100:3100"
volumes:
- ./config/loki-config.yml:/etc/loki/local-config.yaml
- /docker/data/loki/index:/loki/index
- /docker/data/loki/chunks:/loki/chunks
command: -config.file=/etc/loki/local-config.yaml
networks:
- monitoring-network
user: "0"
prometheus:
image: prom/prometheus:latest
container_name: db-cms-prometheus
restart: on-failure
ports:
- "9090:9090"
volumes:
- ./config/prometheus-config.yml:/etc/prometheus/prometheus.yml
networks:
- monitoring-network
deploy:
restart_policy:
condition: on-failure
delay: 10s
max_attempts: 10
window: 120s
alertmanager:
image: prom/alertmanager:latest
container_name: db-cms-alertmanager
networks:
- monitoring-network
ports:
- "9093:9093"
volumes:
- ./config/alertmanager-config.yml:/etc/alertmanager/alertmanager.yml
oracledb_exporter:
image: iamseth/oracledb_exporter
container_name: db-cms-oracledb_exporter
restart: on-failure
ports:
- "9161:9161"
environment:
- DATA_SOURCE_NAME=system/oracle@oracle:1522/XE
networks:
- monitoring-network
depends_on:
- oracle
deploy:
restart_policy:
condition: on-failure
delay: 10s
max_attempts: 10
window: 120s
grafana:
image: grafana/grafana:10.2.0
container_name: db-cms-grafana
ports:
- "3000:3000"
volumes:
- /docker/data/grafana:/var/lib/grafana
#- C:/Users/User/AppData/Local/Docker/wsl/data/grafana:/var/lib/grafana
networks:
- monitoring-network
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin
depends_on:
- loki
- prometheus
- alertmanager
volumes:
oradata:
networks:
monitoring-network:
driver: bridge
2. loki-config.yml
auth_enabled: false
server:
http_listen_port: 3100
grpc_listen_port: 9095
ingester:
wal:
enabled: true
dir: /loki/wal
lifecycler:
ring:
kvstore:
store: inmemory
replication_factor: 1
chunk_idle_period: 5m
chunk_retain_period: 30s
max_transfer_retries: 0
schema_config:
configs:
- from: 2020-10-24
store: boltdb
object_store: filesystem
schema: v11
index:
prefix: index_
period: 24h
storage_config:
boltdb:
directory: /loki/index
filesystem:
directory: /loki/chunks
limits_config:
enforce_metric_name: false
reject_old_samples: true
reject_old_samples_max_age: 168h
chunk_store_config:
max_look_back_period: 0s
table_manager:
retention_deletes_enabled: false
retention_period: 0s
3. prometheus-config.yml
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'oracledb_exporter'
static_configs:
- targets: ['oracledb_exporter:9161']
alerting:
alertmanagers:
- static_configs:
- targets: ['alertmanager:9093']
rule_files:
- '/etc/prometheus/alerts.yml'4. alertmanager-config.yml
global:
resolve_timeout: 5m
route:
receiver: 'slack-receiver'
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receivers:
- name: 'slack-receiver'
slack_configs:
- api_url: '${{ secrets.SLACK_WEBHOOK }}' # 복사한 Webhook URL
channel: '#monitoring' # 알림을 보낼 Slack 채널
send_resolved: true
title: '{{ .CommonAnnotations.summary }}'
text: >-
{{ range .Alerts }}
*Alert:* {{ .Annotations.summary }}
*Description:* {{ .Annotations.description }}
*Severity:* {{ .Labels.severity }}
*Source:* {{ .GeneratorURL }}
{{ end }}
5. alerts.yml
groups:
- name: example_alerts
rules:
# CPU 사용량이 높은 경우 알람 (기준: 80%)
- alert: HighCpuUsage
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 80
for: 1m
labels:
severity: critical
team: ops
annotations:
summary: "Instance {{ $labels.instance }} has high CPU usage"
description: "CPU usage on instance {{ $labels.instance }} is above 80% for more than 1 minute. Current value: {{ $value }}%"
# 메모리 사용량이 높은 경우 알람 (기준: 80%)
- alert: HighMemoryUsage
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes > 0.8
for: 2m
labels:
severity: warning
team: ops
annotations:
summary: "Instance {{ $labels.instance }} has high memory usage"
description: "Memory usage on instance {{ $labels.instance }} is above 80% for more than 2 minutes. Current value: {{ $value }}%"
# 인스턴스 다운 시 알람
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: critical
team: infra
annotations:
summary: "Instance {{ $labels.instance }} is down"
description: "Instance {{ $labels.instance }} has been down for more than 1 minutes."
- name: performance_alerts
rules:
# 응답 시간이 1초를 초과하면 알람 발생
- alert: HighResponseTime
expr: (rate(http_request_duration_seconds_sum{job="oracledb_exporter"}[5m]) / rate(http_request_duration_seconds_count{job="oracledb_exporter"}[5m])) > 1
for: 1m
labels:
severity: warning
annotations:
summary: "High response time detected"
description: "The average response time has exceeded 1 second for the past 1 minute."
# 캐시 사용량이 80%를 초과하면 알람 발생
- alert: HighCacheUsage
expr: (redis_memory_used_bytes{job="oracledb_exporter"} / redis_memory_max_bytes{job="oracledb_exporter"}) > 0.8
for: 2m
labels:
severity: critical
annotations:
summary: "High cache usage detected"
description: "The cache usage has exceeded 80% for the past 2 minutes."
# # 예를 들어, 쿼리 수가 특정 기준을 초과하면 알람 발생
# - alert: HighQueryCount
# expr: oracledb_exporter_sql_queries_total{job="oracledb_exporter"} > 1000
# for: 1m
# labels:
# severity: critical
# annotations:
# summary: "High query count detected"
# description: "The number of SQL queries has exceeded 1000 in the past 1 minute."
# # 또는, 데이터베이스 연결 수가 특정 기준을 초과하면 알람 발생
# - alert: HighDbConnections
# expr: oracledb_exporter_db_connections{job="oracledb_exporter"} > 500
# for: 2m
# labels:
# severity: warning
# annotations:
# summary: "High number of database connections detected"
# description: "The number of database connections has exceeded 500 in the past 2 minutes."특이점으로는 alerts.yml 이 기준이 되어 Prometheus에서 알림을 보내게 된다.
결과
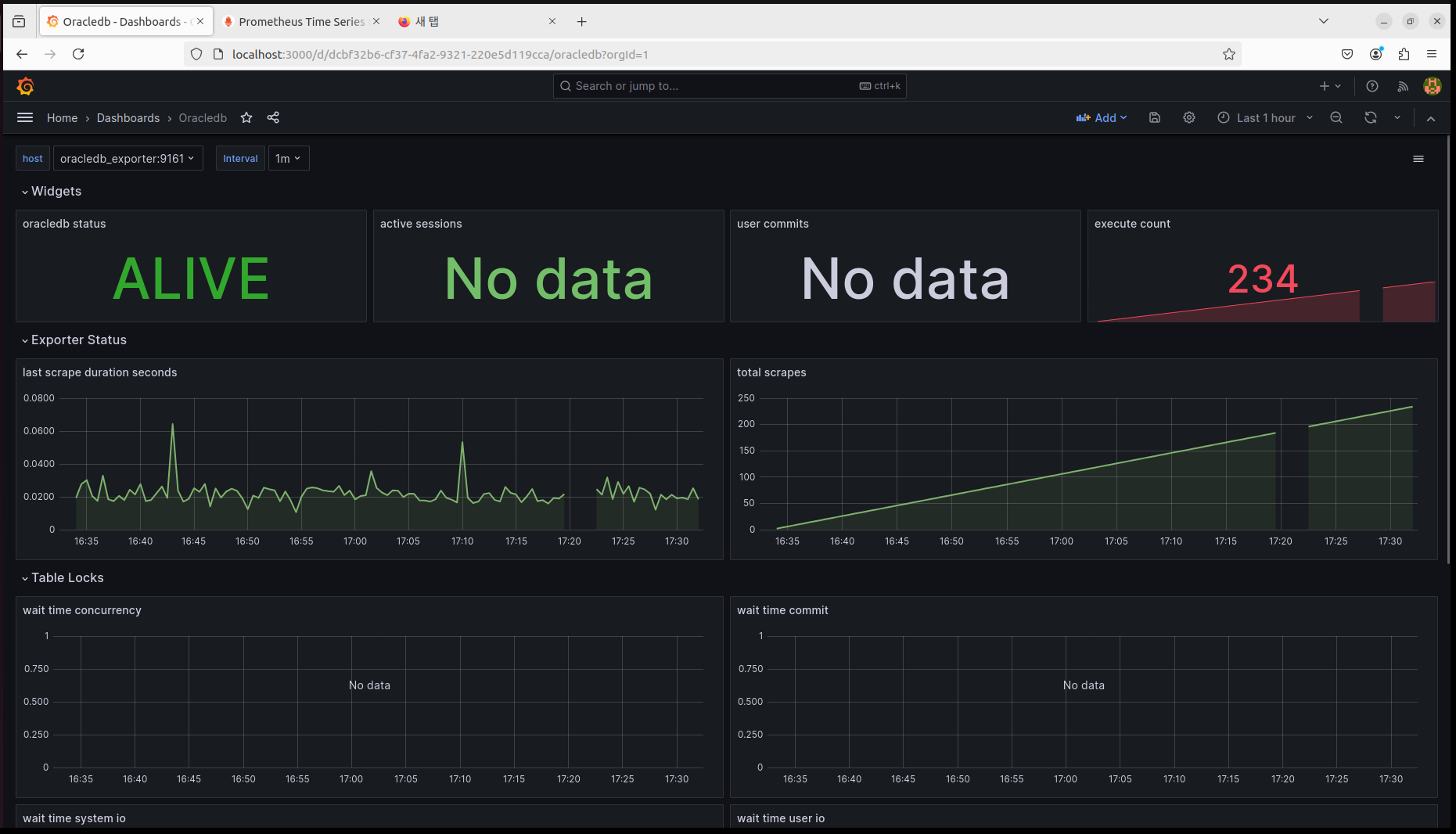
1. PLG
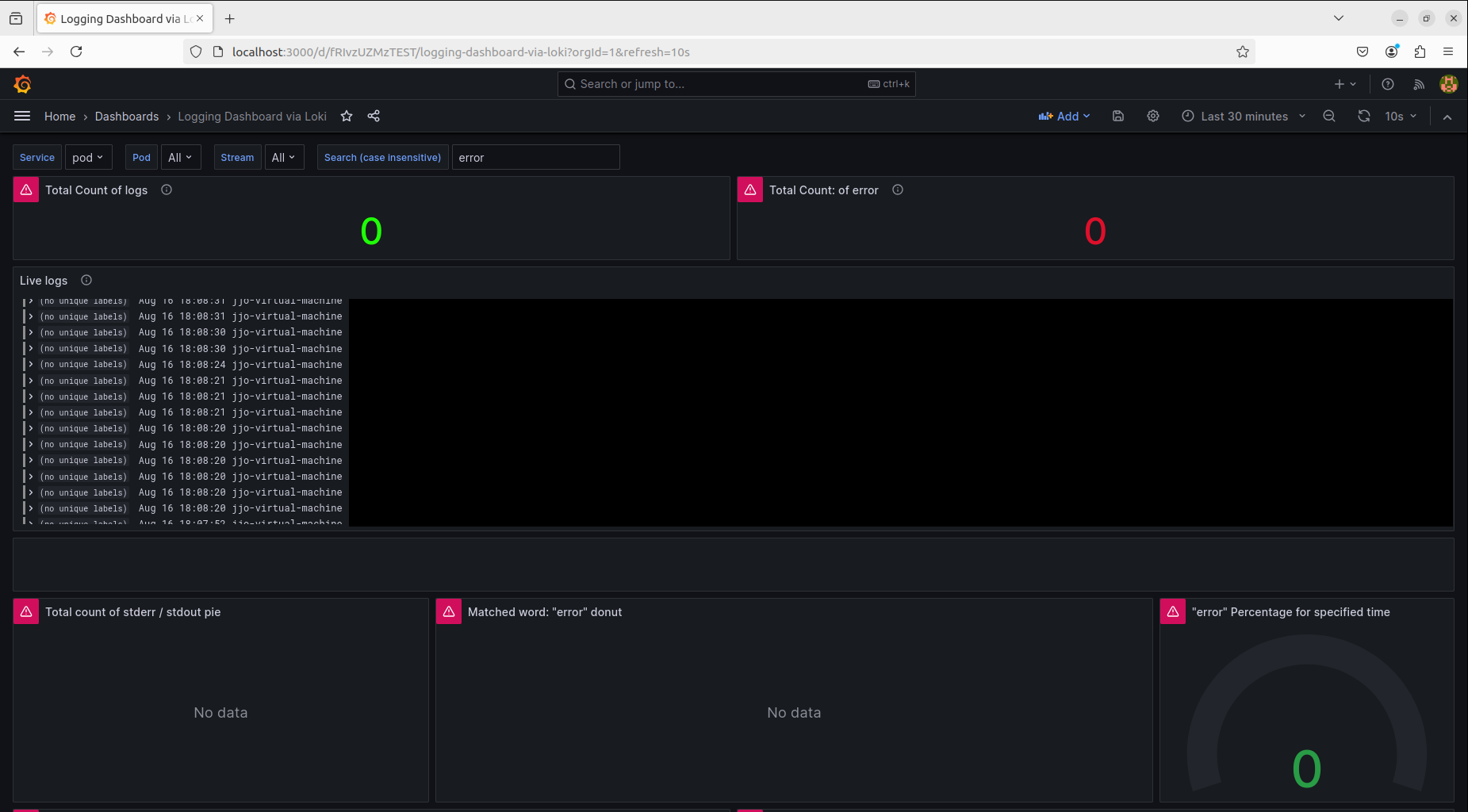
2. Oracle
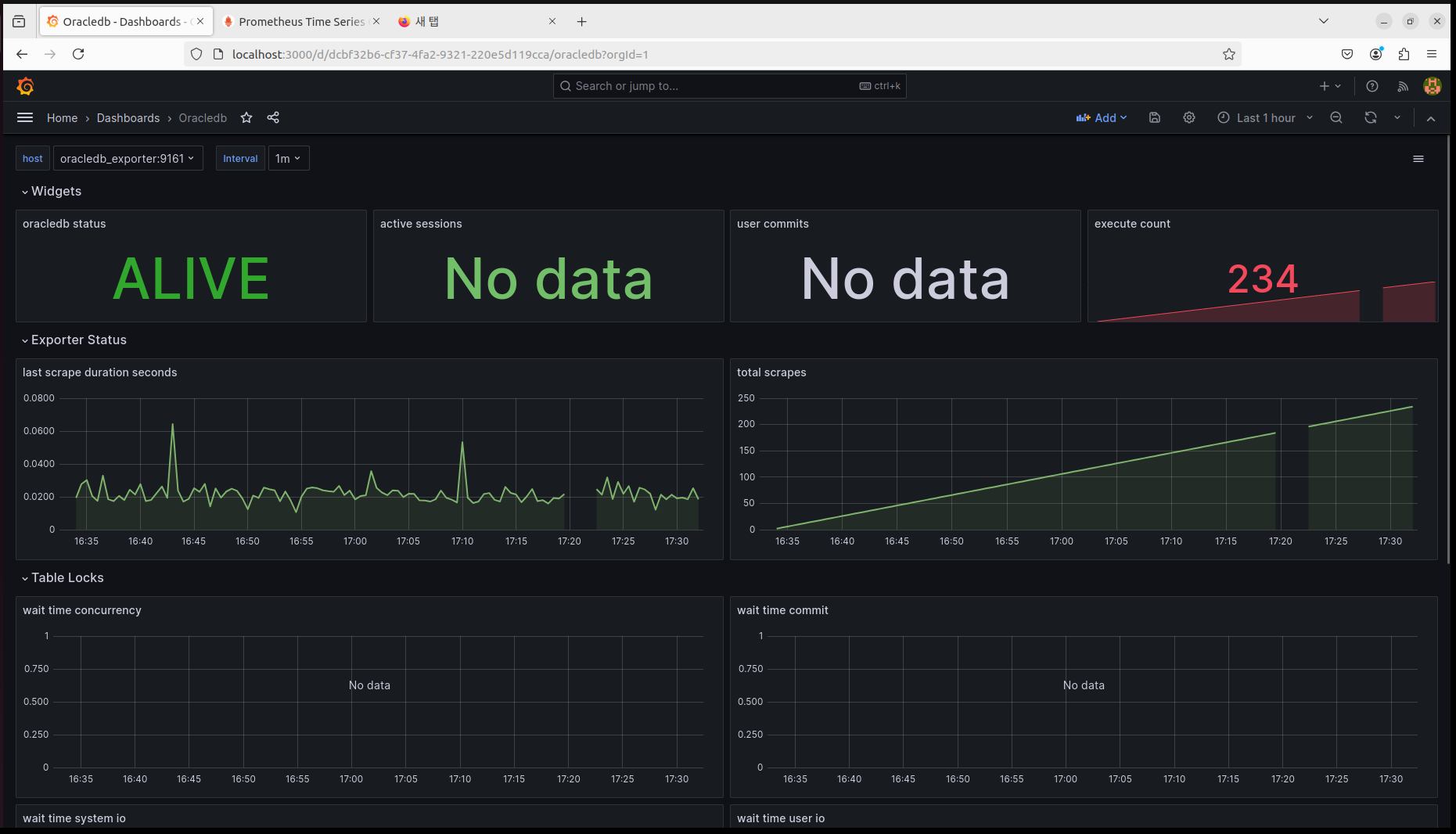
구축 후 확인할 수 있는 화면은 총 2개가 만들어졌다.
추가로 Alertmanager를 테스트해보자
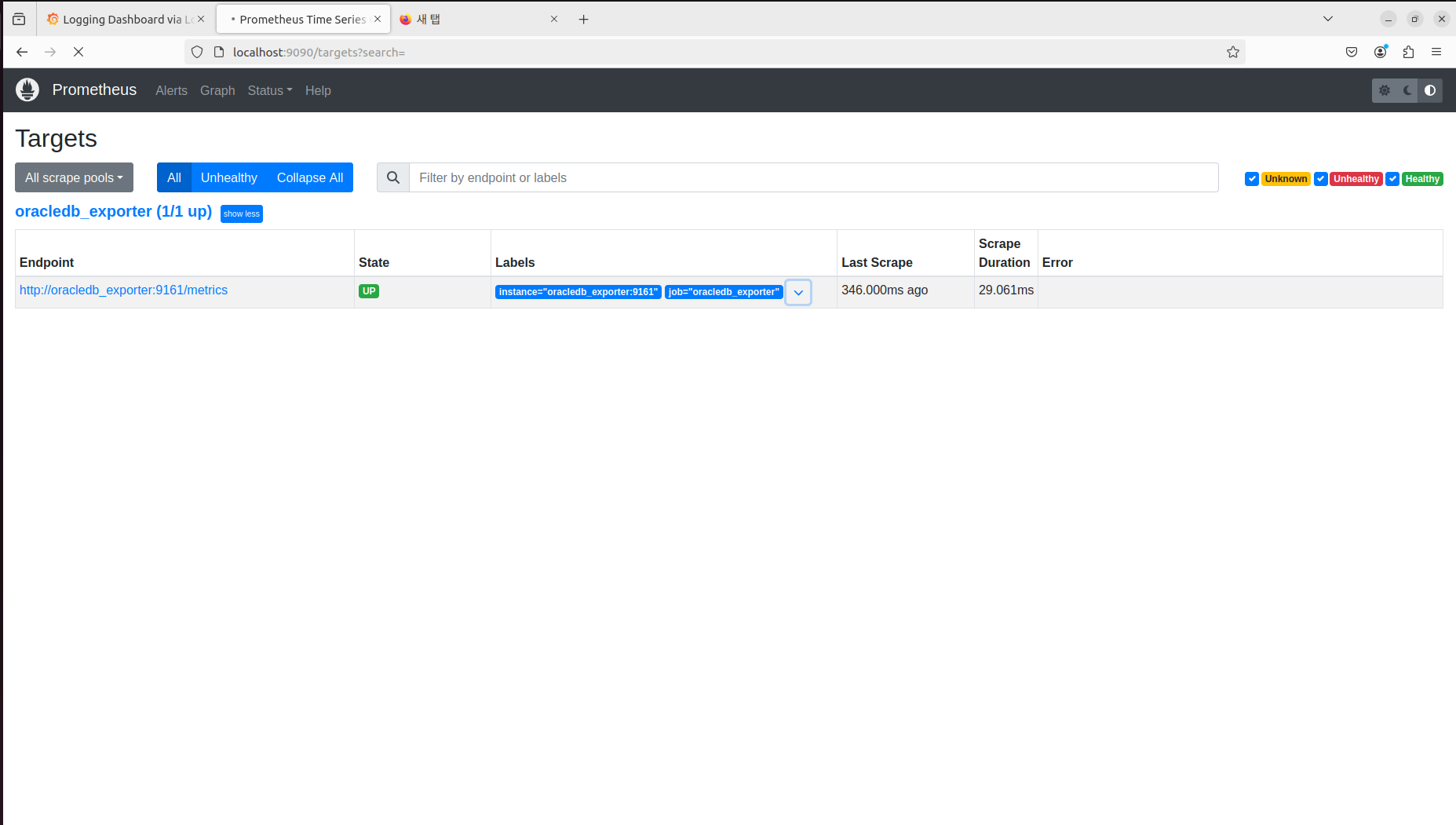
Prometheus로 들어가서
Status -> Targets를 들어가면
Oracle Exporter가 올라와 있는 걸 확인할 수 있고
Oracle을 먼저 내려보겠다.
docker stop oracle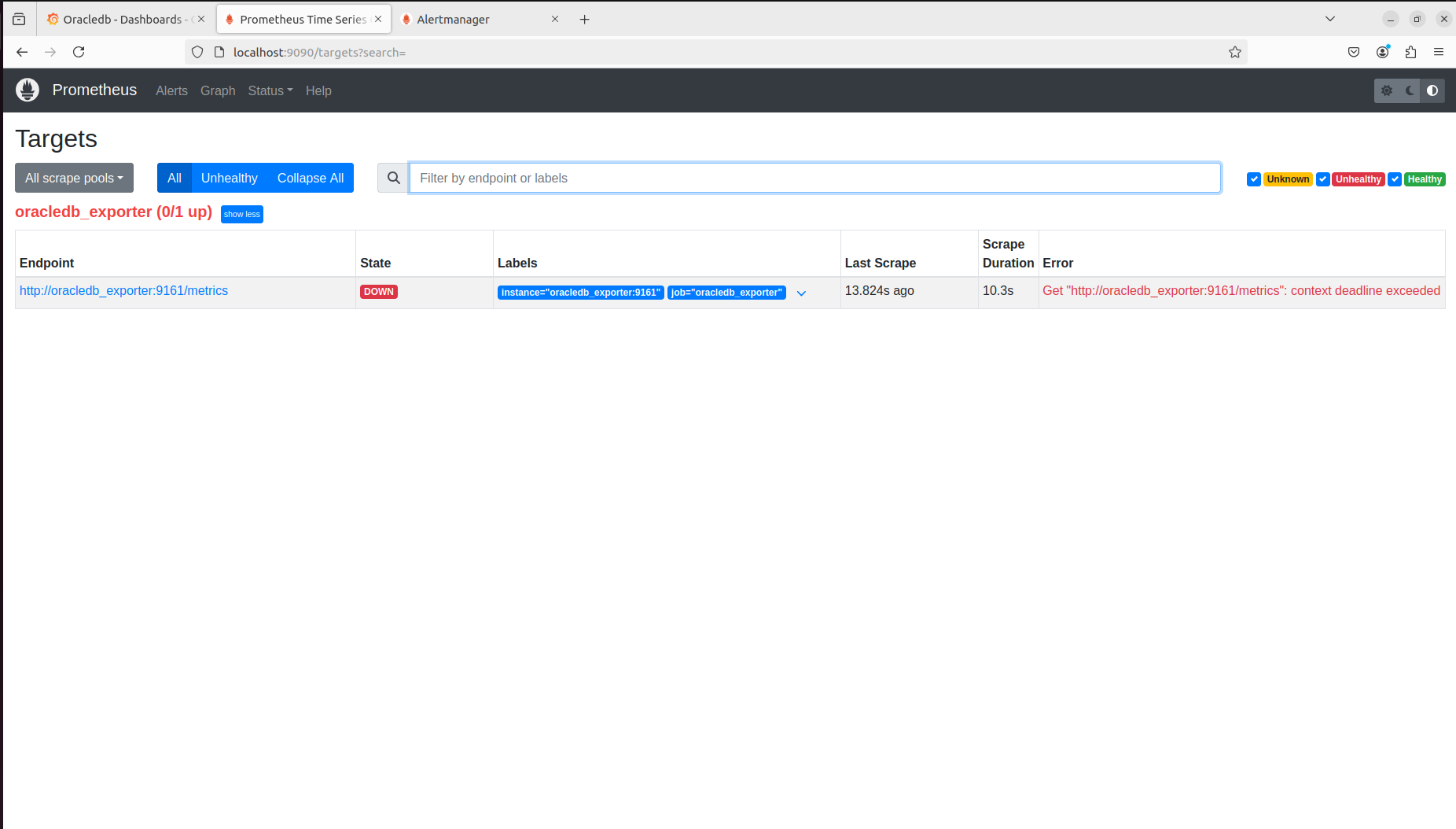
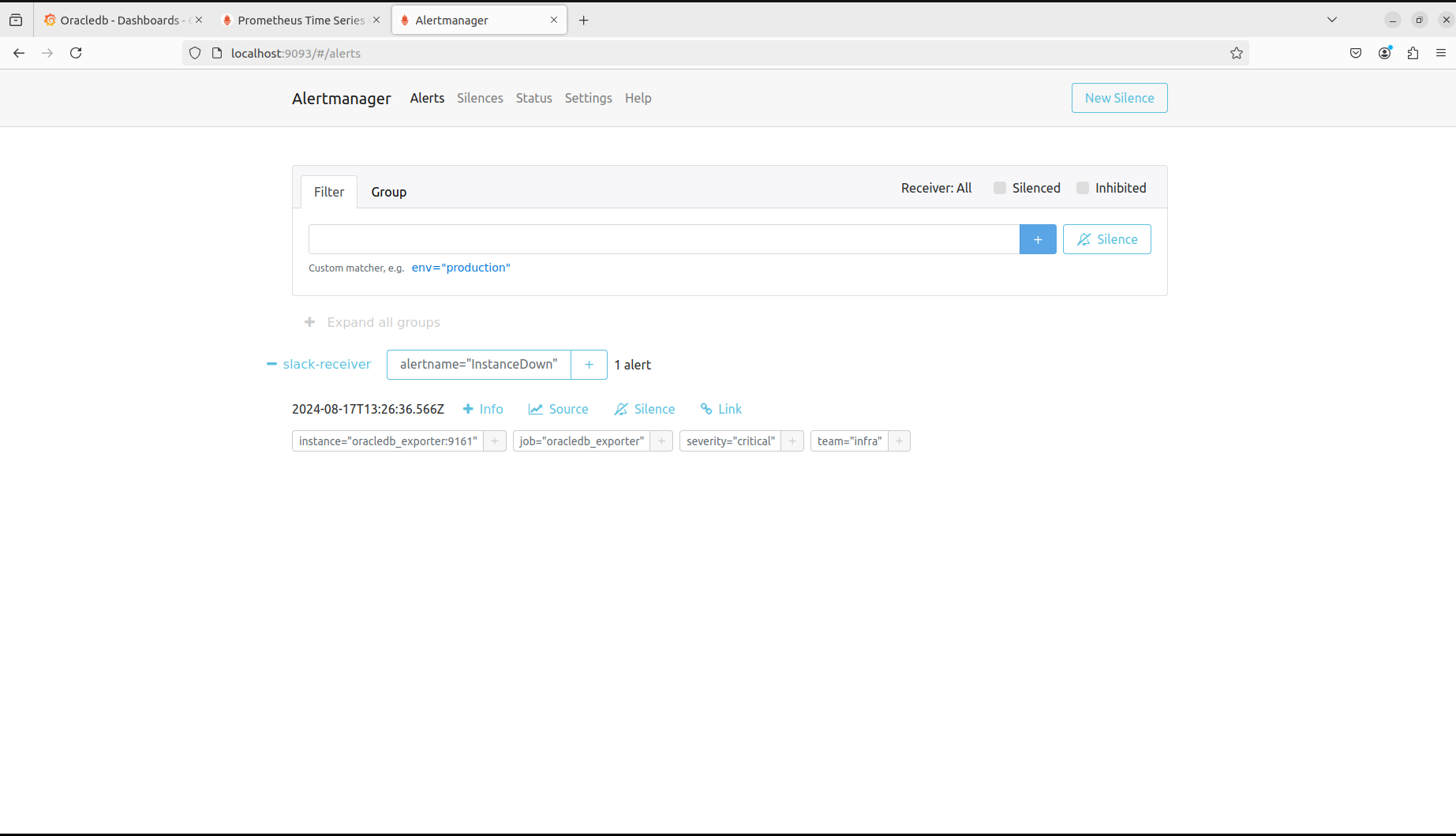
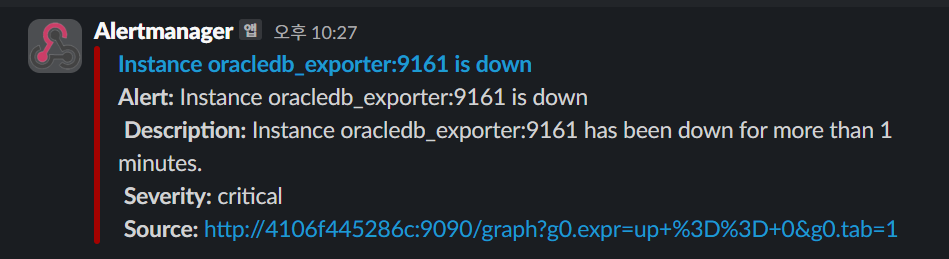
잘 내려갔고, alertmanager로 들어가면 기준들을 넘었기 때문에 Alert가 발생한 것을 확인할 수 있다.
Slack에서도 메세지를 확인할 수 있고 메세지는 너무 알아보기 힘들어서 변경할 필요가 있어 보인다.
결론
PLG + Oracle 까지 모니터링하는 시스템을 구현했고
다음으로는 실제로 테스트DB 환경에 적용해본 뒤 WAS도 상태를 모니터링하는 걸 추가로 봤으면 한다.
