11장. Sytem
시스템에서는 시스템 수준에서 높은 추상화 수준을 유지하는 방법에 대해서 소개한다.
클린 코드에서는 시스템 제작과 시스템 사용의 분리가 중요하다고 언급한다. 소프트웨어 시스템은 애플리케이션 객체를 제작하고 의존성을 서로 연결하는 준비과정과, 준비과정 이후에 이어지는 런타임로직을 분리해야 한다. 모든 어플리케이션에서는 시작단계라는 관심사를 분리하는 것이 가장 중요한 설계기법 중 하나이다. 하지만 대다수의 애플리케이션은 관심사를 분리하지 않고 런타임 로직과 준비과정코드를 섞기도 한다.
class HomeService {
...
fun getService(): Service {
if(service == null) service = MyServiceImpl(...)
return service
}
}이 예시가 관심사를 분리하지 못한 코드 중 하나이다. 초기화 지연기법 중 하나인데 실제로 우리가 객체를 필요로 하기 전까지 객체생성을 하지 않기 때문에 불필요한 부하가 걸리지 않고, 어떤 경우에도 null을 반환하지 않을 수 있다는 장점을 가지고 있다.
하지만 이 경우, 해당 클래스가 MyServiceImpl 클래스에 의존성을 가지게 되기 때문에 MyServiceImpl 객체를 실제로 사용하지 않더라도 의존성을 해결하지 않는다면 컴파일이 되지 않는다. 이것은 테스트코드를 작성할 때도 문제가 되는데, MyServiceImpl가 무거운 객체라면 적절한 mock 객체를 만들어 필드에 할당해야한다.
또한 일반 런타임에 객체 생성 로직을 넣어놨기 때문에 모든 실행경로 (예시로 service가 null일 때와, null이 아닌 경우)에 대한 테스트 코드도 작성해야하는데, 이것은 단일 책임 원칙에 위배하는 로직이 된다. 또한 MyServiceImpl 객체 유형이 클래스 내부의 모든 케이스에 대해 적합해야 하는데 항상 적합할 수 있는지에 대한 의구심이 들 수 있다.
이런 지연 초기화 방법은 가끔씩만 사용한다면 괜찮겠지만 자주 사용하게 된다면 모듈성이 저조하고 중복이 심해질 것이다.
탄탄한 시스템을 만들고 싶다면 모듈성을 절대로 깨트리면 안된다. 일반 실행 논리와 설정 논리를 분리해야 모듈성이 높아진다.
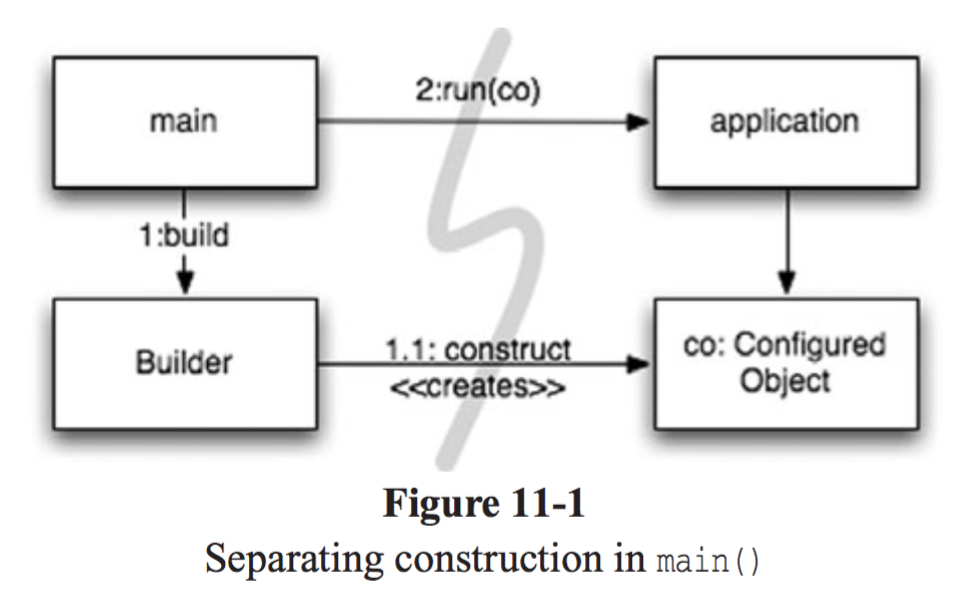
[11-1] 은 제어의 흐름을 따라가기가 쉽다. main 함수에서 시스템에 필요한 객체를 생성해서 애플리케이션에 넘기고, 애플리케이션에서는 넘겨온 객체를 직접적으로 사용하고 있다. 애플리케이션은 main 을 모르고 있는 상태이기 때문에, 모든 객체가 잘 생성되었다고 가정할 수 밖에 없다.
또한 의존성 방향도 한 쪽으로만 흐르고 있기 때문에 강하게 연결되어있어, 객체를 분리하여 컴포넌트로 사용할 수도 없게 된다. (이 때 컴포넌트란 다른 곳에서도 재사용이 가능하다는 것을 의미한다.)
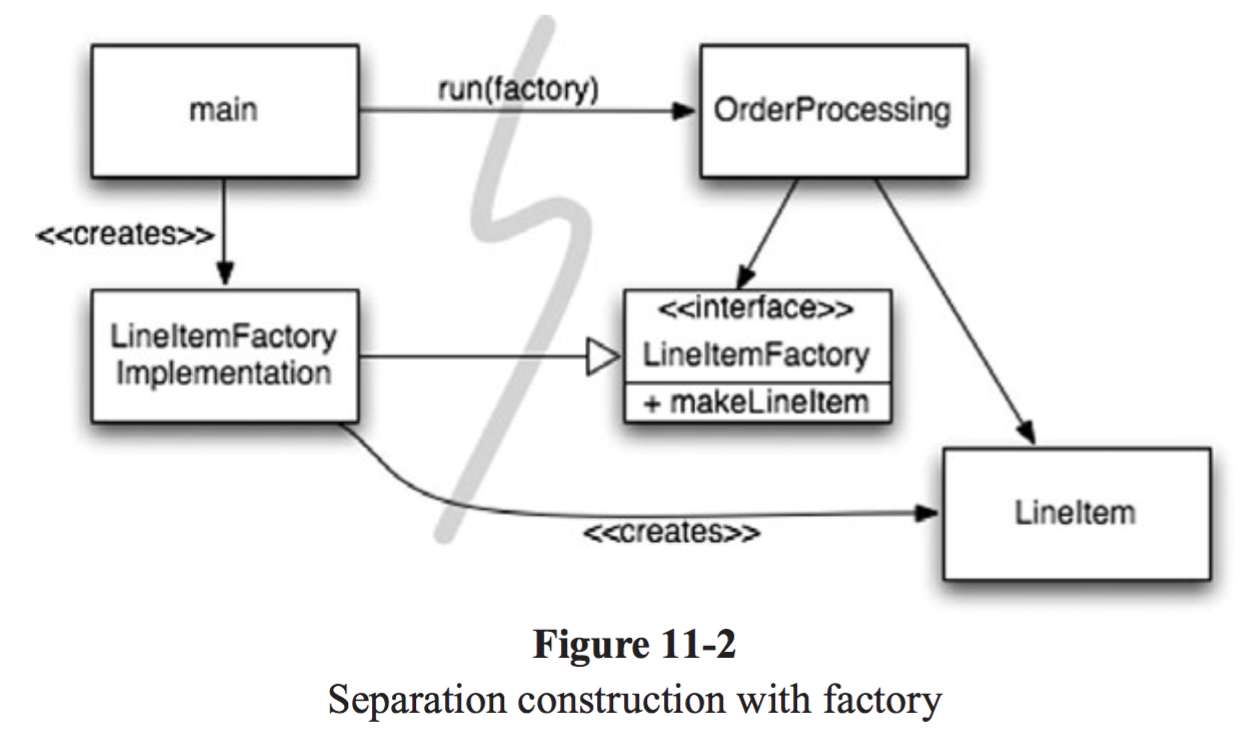
[11-1] 의 의존성 관계를 개선하기 위해, 추상팩토리 패턴을 사용한 [11-2] 예시이다. (주문 처리 시스템에서 ListItem 객체를 생성해 Order 에 추가하는 로직)
아까와는 달리 OrderProcessing이 직접적으로 객체에 접근하지 않고, interface 로 접근하게 되어 어떻게 LineItem이 생성되는지 알 수 없게된다. 추상적인 클래스에 의존할 수 있도록 변경하여 의존성 주입을 다른 곳으로 위임함으로써 1. 추후에 변경이 쉬워지고 2. 관심사 분리가 가능해지며 3. 재사용이 가능해진다. 는 장점을 가질 수 있게 되었다.
[11-2] 의 방식이 대표적인 의존성 주입의 방식이다. 의존성 관리 맥락에서는 객체는 의존성 자체를 인스턴스로 만드는 책임을 지지 않고, 다른 전담 메커니즘에 넘겨 제어를 역전한다. 그래서 책임질 메커니즘으로 DI 컨테이너를 사용하게 된다.
대게 의존성을 주입하려는 방법으로 setter 혹은 생성자 파라미터를 제공한다. 그래서 객체 생성 요청이 들어올 때마다 DI 컨테이너에서 필요한 객체를 생성한 후 setter 혹은 생성자 파라미터를 통해 의존성을 설정하게 된다. 대다수의 DI 컨테이너는 필요할 때까지 객체를 생성하지 않고, 대부분 지연초기화 기법을 제공하고 있다.
군락은 마을로, 마을은 도시로 성장한다. 처음에는 전력, 상수도, 인터넷과 같은 서비스가 없었지만 인구가 늘어나면서 서비스도 생겨나게 된다. 하지만, 이런 성장에는 고통이 따르게된다. 늘어난 인구를 위해 도로 확장 공사 시행하게 될 때 "왜 처음부터 넓게 만들지 않았지?" 라고 자문한 적이 얼마나 많은가? 하지만 마을이 성장하기 전, 처음부터 도로를 넓게 만든다면 넓게 만들기 위한 비용을 정당화 할 수 있을까? 그 전에 조그마한 마을이 넓은 도로를 좋아할까?
처음부터 올바르게 시스템을 만들 수 있다는 것은 미신이다. 대신 오늘은 오늘에 주어진 시스템을 구현하고, 내일은 시스템을 조정하고 더욱 확장시키면 된다.
하지만 시스템 수준에서는 조금 다르다. 시스템 아키텍처는 사전 계획이 필요하며, 단순한 아키텍처는 복잡한 아키텍처로 키울 수는 없다. 시작 시점부터 관심사를 적절히 분리한다면 소프트웨어 아키텍처를 점진적으로 발전할 수 있다. 시스템 수명은 짧다는 본질로 인해 아키텍처는 점진적인 발전이 가능하다.
Cross-cutting concern (횡단 관심사)
영속성(persistence)과 같은 관심사는 객체 경계를 넘나드는 경향이 있다.
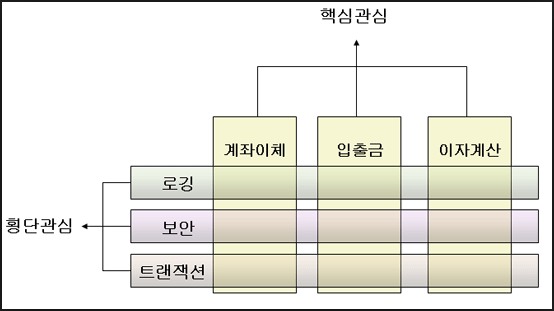
핵심 관심사인 계좌이체, 입출금, 이자계산 로직들은 공통적으로 로깅 - 보안 - 트랜젝션 과정을 거쳐야 한다. 이렇게 핵심 관심사에 공통적으로 들어가는 로직을 횡단 관심사라고 부르게 된다. 동일한 로직을 객체별로 처리하기 때문에 나타나게 된 형태인데, 중복되는 코드가 많이 생길 수 있다는 것을 알 수 있다. 중복되는 코드는 제거하는 것이 클린코드로 나아가는 방법 중 하나이기 때문에, 핵심 관심에서 중복으로 나타나고 있는 횡단관심을 모듈로 분리하고자 AOP(관심 지향 프로그래밍)이 등장하게 되었다.
AOP에서는 관점(Aspect) 이라는 모듈 구성은 "특정 관심사를 지원하려면 시스템에서 특정 지점들이 동작하는 방식을 일관성있게 바꾸어야한다"고 명시한다. 일관성있게 바꾸어야 핵심 관심 속에 존재하는 특정 관심사를 공통의 모듈로 묶을 수 있고, 핵심 로직에 더욱 집중할 수 있기 때문이다.
코드 수준에서 아키텍처 관심사를 분리할 수 있다면(DI를 통해 의존성 주입을 외부 프레임워크에게 맡기고, AOP를 이용해 핵심 로직만을 집중) 우리는 불필요한 내용을 알 필요가 없게 되고, 진정한 테스트 주도 아키텍처 구축이 가능해진다.
그때그때 새로운 기술을 채택해 단순한 아키텍처를 복잡한 아키텍처로 키워갈 수 있다. 많은 노력으로 탄생한 초기 아키텍처라면 이를 버리지 않으려는 심리적 갈등이 있기 때문에 변경을 쉽게 수용할 수 없게 되는데, 이런 방식보다는 단순하게 짜여진 아키텍처 위해 결과물을 도출해낸 후, 추후에 기반을 다지고 확장해나가는 것이 좋다.
Reference
