인덱스는 데이터베이스 쿼리의 성능을 언급하면서 빼놓을 수 없는 부분이다. 각 인덱스의 특성과 차이는 상당이 중요하며, 물리 수준의 모델링을 할 때도 중요한 요소가 될 것이다. 다른 RDBMS에서 제공하는 모든 기능을 제공하지는 않지만, MySQL에서는 인덱싱이나 검색 방식에 따라 스토리지 엔진을 선택해야 할 수도 있기 때문에 여전히 인덱스에 대한 기본 지식은 중요하며, 쿼리 튜닝의 기본이 될 것이다.
디스크 읽기 방식
컴퓨터의 CPU나 메모리와 같은 전기적 특성을 띤 장치의 성능은 짧은 시간 동안 매우 빠른 속도로 발전했지만 디스크와 같은 기계식 장치의 성능은 상당히 제한적으로 발전했다. 데이터베이스나 쿼리 튜닝에 어느 정도 지식을 갖춘 사용자가 많이 절감하고 있듯이, 데이터베이스의 성능 튜닝은 어떻게 디스크 I/O를 줄이느냐가 관련인 것들이 상당히 많다.
1. 저장 매체
디스크의 읽기 방식을 살펴보기 전에 간단히 데이터를 저장할 수 있는 매체(Media)에 대해 살펴보자. 일반적으로 서버에 사용되는 저장 매체는 크게 3가지로 나뉜다.
- 내장 디스크(Internal Disk)
- DAS(Direct Attached Storage)
- NAS(Network Attached Storage)
- SAN(Storage Area Network)
내장 디스크는 개인용 PC의 본체 내에 장착된 디스크와 같은 매체다. 물론 서버용으로 사용되는 디스크는 개인 PC에 장착되는 것보다는 빠르고 안정적인 것들이다. 그리고 개인 PC와는 달리 데이터베이스 서버용으로 사용되는 장비는 일반적으로 4~6개 정도의 내장 디스크를 장착한다. 하지만 컴퓨터의 본체 내부 공간은 제한적이어서 장착할 수 있는 디스크의 개수가 적고 용량도 부족할 때가 많다.
내장 디스크의 용량 문제를 해결하기 위해 주로 사용하는 것이 DAS인데, DAS는 컴퓨터의 본체와는 달리 디스크만 있는 것이 특징이다. DAS 장치는 독자적으로 사용할 수 없으며, 컴퓨터 본체에 연결해서만 사용할 수 있다. DAS나 내장 디스크는 모두 SATA나 SAS와 같은 케이블로 연결되기 때문에 실제 사용자에게는 거의 같은 방식으로 사용되며, 성능 또한 내장 디스크와 거의 비슷하다. 최근의 DAS는 디스크를 최대 200개까지 장착할 수 있는 것들도 있기 때문에 대용량의 디스크가 필요한 경우에는 DAS가 적합하다. 하지만 DAS는 반드시 하나의 컴퓨터 본체에만 연결해서 사용할 수 있기 때문에 디스크의 정보를 여러 컴퓨터가 동시에 공유하는 것이 불가능하다.
내장 디스크와 DAS의 문제점을 동시에 해결하기 위해 주로 NAS와 SAN을 사용한다. DAS와 NAS의 가장 큰 차이는 여러 컴퓨터에서 동시에 사용할 수 있는지와 컴퓨터 본체와 연결되는 방식이다. 위에서도 살펴봤지만 DAS는 내장 디스크와 같이 컴퓨터 본체와 SATA나 SAS 또는 SCSI 케이블로 연결되지만, NAS는 TCP/IP를 통해 연결된다. NAS는 동시에 여러 컴퓨터에서 공유해서 사용할 수 있는 저장 매체이지만 SATA나 SAS 방식의 직접 연결보다는 속도가 매우 느리다.
SAN은 DAS로는 구축할 수 없는 아주 대용량의 스토리지 공간을 제공하는 장치다. SAN은 여러 컴퓨터에서 동시에 사용할 수 있을뿐더러 컴퓨터 본체와 광케이블로 연결되기 때문에 상당히 빠르고 안정적인 데이터 처리(읽고 쓰기)를 보장해준다. 하지만 그만큼 고가의 구축 비용이 들기 때문에 각 기업에서는 중요 데이터를 보관할 경우에만 일반적으로 사용한다.
NAS는 TCP/IP로 데이터가 전송되기 때문에 빈번한 데이터 읽고 쓰기가 필요한 데이터베이스 서버용으로는 거의 사용되지 않는다. 내장 디스크 -> DAS -> SAN 순으로, 뒤로 갈수록 고사양 고성능이며, 구축 비용도 올라간다. 각 장치가 얼마나 많은 디스크 드라이브를 장착할 수 있는지, 그리고 어떤 방식으로 컴퓨터 본체에 연결되는지에 따른 구분일 뿐, 여기에 언급된 모든 저장 매체는 내부적으로 1개 이상의 디스크 드라이브를 장착하고 있다는 점은 같다. 대부분의 저장 매체는 디스크 드라이브의 플래터(Platter, 디스크 드라이브 내부의 데이터 저장용 원판)를 회전시켜서 데이터를 읽고 쓰는 기계적인 방식을 사용한다.
2. 디스크 드라이브나 솔리드 스테이트 드라이브
컴퓨터에서 CPU나 메모리와 같은 주요 장치는 대부분 전자식 장치지만 디스크 드라이브는 기계식 장치다. 그래서 데이터베이스 서버에서는 항상 디스크 장치가 병목 지점이 된다. 이러한 기계식 디스크 드라이브를 대체하기 위해서 전자식 저장 매체인 SSD(Solid State Drive)가 많이 출시되고 있다. SSD도 기존 디스크 드라이브와 같은 인터페이스(SATA나 SAS)를 지원하므로 내장 디스크나 DAS 또는 SAN에 그대로 사용할 수 있다.

SSD는 기존의 디스크 드라이브에서 데이터 저장용 플래터(원판)를 제거하고 대신 플래시 메모리를 장착하고 있다. 그래서 디스크 원판을 기계적으로 회전시킬 필요가 없으므로 아주 빨리 데이터를 읽고 쓸 수 있다. 플래시 메모리는 전원이 공급되지 않아도 데이터가 삭제되지 않는다. 그리고 컴퓨터의 메모리(D-Ram)보다는 느리지만 기계식 디스크 드라이브보다는 훨씬 빠르다.
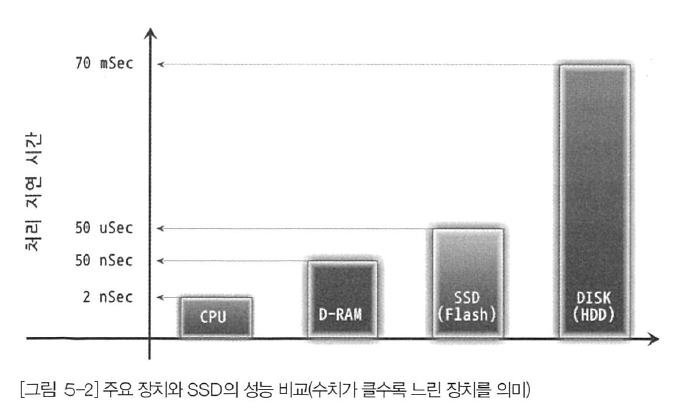
위의 그림은 컴퓨터이 주요 부품별 처리 속도를 보여준다. Y축의 "처리 지연 시간"이란 요청된 작업을 처리하는데 소요되는 시간을 의미하므로 이 값이 클수록 처리 속도가 느리다는 것을 의미한다. 위의 그림에서 보는 것과 같이 메모리와 디스크의 처리 속도는 10만 배 이상의 차이를 보인다. 그에 비해 플래시 메모리를 사용하는 SSD는 1000배 가량의 차이를 보인다. 아직 시중에 판매되는 SSD는 대부분 기존 디스크보다는 용량이 적으며, 가격도 상당히 비싼 것이 흠이지만 조만간 SSD가 어느 정도는 디스크를 대체할 것으로 생각한다.
디스크의 헤더를 움직이지 않고 한번에 많은 데이터를 읽는 순차 I/O에서는 SSD가 디스크 드라이브보다 조금 빠르거나 거의 비슷한 성능을 보이기도 한다. 하지만 SSD의 장점은 기존의 디스크 드라이브보다 랜덤 I/O가 훨씬 빠르다는 것이다. 데이터베이스 서버에서 순차 I/O 작업은 그다지 비중이 크지 않고 랜덤 I/O를 통해 작은 데이터를 읽고 쓰는 작업이 대부분이므로 SSD의 장점은 DBMS용 스토리지에 최적이라고 볼 수 있다. 아래 그림은 SSD와 디스크 드라이브에서 랜덤 I/O의 성능을 벤치마크해 본 것이다.
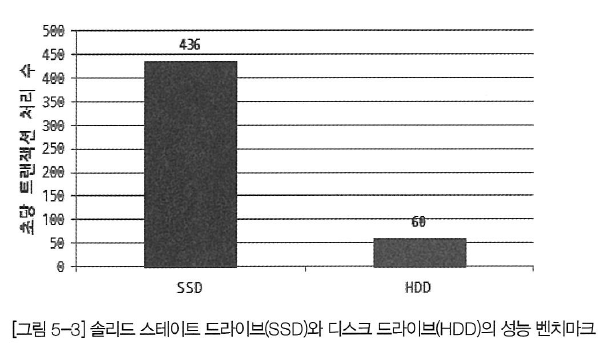
위의 그림의 벤치마크 결과를 살펴보면 SSD는 초당 436개의 트랜잭션을 처리했지만 디스크 드라이브는 초당 60개의 트랜잭션밖에 처리하지 못했다. 일반적인 웹 서비스(OLTP) 환경의 데이터베이스에서는 SSD가 디스크 드라이브보다는 훨씬 빠르다.
3. 랜덤 I/O와 순차 I/O
랜덤 I/O라는 표현은 디스크 드라이브의 플래터(원판)을 돌려서 읽어야 할 데이터가 저장된 위치로 디스크 헤더를 이동시킨 다음 데이터를 읽는 것을 의미하는데, 사실 순차 I/O 또한 이 작업은 같다. 그렇다면 랜덤 I/O와 순차 I/O는 어떤 차이가 있을까? 아래 그림을 살펴보자.
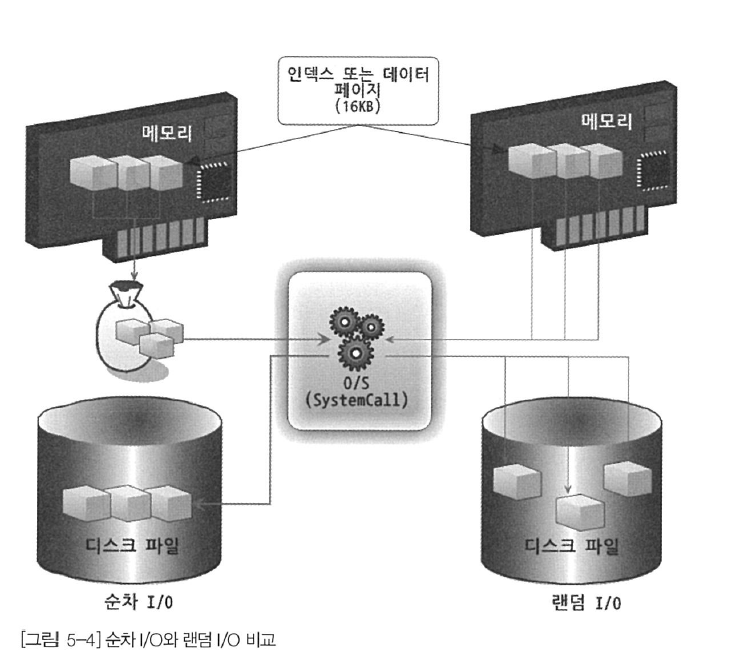
순차 I/O는 3개의 페이지(16 * 3KB)를 디스크에 기록하기 위해 1번 시스템 콜을 요청했지만 랜덤 I/O는 3개의 페이지를 디스크에 기록하기 위해 3번 시스템 콜을 요청했다. 즉, 디스크에 기록해야 할 위치를 찾기 위해 순차 I/O는 디스크의 헤드를 1번 움직였고, 랜덤 I/O는 디스크 헤드를 3번 움직인 것이다. 디스크에 데이터를 쓰고 읽는데 걸리는 시간은 디스크 헤더를 움직여서 읽고 쓸 위치로 옮기는 단계에서 결정된다. 즉 위의 그림의 경우 순차 I/O는 랜덤 I/O보다 거의 3배 정도 빠르다고 볼 수 있다. 즉, 디스크의 성능은 디스크 헤더의 위치 이동 없이 얼마나 많은 데이터를 한 번에 기록하느냐에 의해 결정된다고 볼 수 있다. 그래서 여러 번 쓰기 또는 읽기를 요청하는 랜덤 I/O 작업이 훨씬 작업의 부하가 커지는 것이다. 데이터베이스 대부분의 작업은 이러한 작은 데이터를 빈번히 읽고 쓰기 때문에 MySQL 서버에는 그룹 커밋이나 바이너리 로그 버퍼 또는 InnoDB 로그 버퍼 등의 기능이 내장된 것이다.
랜덤 I/O가 순차 I/O 모두 파일에 쓰기를 실행하면, 반드시 동기화(sync 또는 flush 작업)가 필요하다. 그런데 순차 I/O인 경우에도 이런 파일 동기화 작업이 빈번히 발생한다면 랜덤 I/O와 같이 비효율적인 형태로 처리될 때가 많다. 기업용으로 사용하는 데이터베이스 서버에는 캐시 메모리가 장착된 RAID 컨트롤러가 일반적으로 사용되는데, RAID 컨트롤러의 캐시 메모리는 아주 빈번한 파일 동기화 작업이 호출되는 순차 I/O를 효율적으로 처리될 수 있게 변환하는 역할을 하게 된다.
사실 쿼리를 튜닝해서 랜덤 I/O를 순차 I/O로 바꿔서 실행할 방법은 그다지 많지 않다. 일반적으로 쿼리를 튜닝하는 것은 랜덤 I/O 자체를 줄여주는 것이 목적이라고 할 수 있다. 여기서 랜덤 I/O를 줄인다는 것은 쿼리를 처리하는 데 꼭 필요한 데이터만 읽도록 쿼리를 개선하는 것을 의미한다.
인덱스 레인지 스캔은 데이터를 읽기 위해 주로 랜덤 I/O를 사용하며, 풀 테이블 스캔은 순차 I/O를 사용한다. 그래서 큰 테이블의 레코드 대부분을 읽는 작업에서는 인덱스를 사용하지 않고 풀 테이블 스캔을 사용하도록 유도할 때도 있다. 이는 순차 I/O가 랜덤 I/O보다 훨씬 빨리 많은 레코드를 읽어올 수 있기 때문인데, 이런 형태는 OLTP 성격의 웹 서비스보다는 데이터 웨어하우스나 통계 작업에서 주로 사용된다.
참고
- Real MySQL
