MySQL 실행 계획 : 개요
DBMS의 쿼리 실행은 같은 결과를 만들어 내는 데 한 가지 방법만 있는 것은 아니다. 아주 많은 방법이 있지만 그중에서 어떤 방법이 최적이고 최소의 비용이 소모될지 결정해야 한다. DBMS에서는 쿼리를 최적으로 실행하기 위해 각 테이블의 데이터가 어떤 분포로 저장돼 있는지 통계 정보를 참조하며, 그러한 기본 데이터를 비교해 최적의 실행 계획을 수립하는 작업이 필요하다. DBMS에서는 옵티마이저가 이러한 기능을 담당한다.
MySQL에서는 EXPLAIN이라는 명령으로 쿼리의 실행 계획을 확인할 수 있는데, 여기에는 많은 정보가 출력된다. 여기서는 실행 계획에 표시되는 내용이 무엇을 의미하고 MySQL 서버가 내부적으로 어떤 작업을 하는지 자세히 살펴보자. 그리고 어떤 실행 계획이 좋고 나쁜지도 간단히 살펴보자.
어떤 DBMS든지 쿼리의 실행 계획을 수립하는 옵티마이저는 가장 복잡한 부분으로 알려져 있으며, 옵티마이저가 만들어 내는 실행 계획을 이해하는 것 또한 상당히 어려운 부분이다. 하지만 그 실행 계획을 이해할 수 있어야만 실행 계획의 불합리한 부분을 찾아내고, 더욱 최적화된 방법으로 실행 계획을 수립하도록 유도할 수 있다. 실행 계획을 살펴보기 전에, 먼저 알고 있어야 할 몇 가지 부분을 살펴보자.
1. 쿼리 실행 절차
MySQL 서버에서 쿼리가 실행되는 과정은 크게 3가지로 나눌 수 있다.
- 사용자로부터 요청된 SQL 문장을 잘게 쪼개서 MySQL 서버가 이해할 수 있는 수준으로 분리한다.
- SQL의 파싱 정보(파스 트리)를 확인하면서 어떤 테이블로부터 읽고 어떤 인덱스를 이용해 테이블을 읽을지 선택한다.
- 두 번째 단계에서 결정된 테이블의 읽기 순서나 선택된 인덱스를 이용해 스토리지 엔진으로부터 데이터를 가져온다.
첫 번째 단계를 "SQL 파싱(Parsing)"이라고 하며, MySQL 서버의 "SQL 파서"라는 모듈로 처리한다. 만약 SQL 문장이 문법적으로 잘못됐다면 이 단계에서 걸러진다. 또한 이 단계에서 "SQL 파스 트리"가 만들어진다. MySQL 서버는 SQL 문장 그 자체가 아니라 SQL 파스 트리를 이용해 쿼리를 실행한다.
두 번째 단계는 첫 번째 단계에서 만들어진 SQL 파스 트리를 참조하면서, 다음과 같은 내용을 처리한다.
- 불필요한 조건의 제거 및 복잡한 연산의 단순화
- 여러 테이블의 조인이 있는 경우 어떤 순서로 테이블을 읽을지 결정
- 각 테이블에 사용된 조건과 인덱스 통계 정보를 이용해 사용할 인덱스 결정
- 가져온 레코드들을 임시 테이블에 넣고 다시 한번 가공해야 하는지 결정
물론 이 밖에도 수많은 처리를 하지만, 대표적으로 이런 작업을 들 수 있다. 두 번째 단계는 "최적화 및 실행 계획 수립" 단계이며, MySQL 서버의 "옵티마이저"에서 처리한다. 또한 두 번째 단계가 완료되면 쿼리의 "실행 계획"이 만들어진다.
세 번째 단계는 수립된 실행 계획대로 스토리지 엔진에 레코드를 읽어오도록 요청하고, MySQL 엔진에서는 스토리지 엔진으로부터 받은 레코드를 조인하거나 정렬하는 작업을 수행한다.
첫 번째 단계와 두 번째 단계는 거의 MySQL 엔진에서 처리하며, 세 번째 단계는 MySQL 엔진과 스토리지 엔진이 동시에 참여해서 처리한다. 아래 그림은 "SQL 파서"와 "옵티마이저"가 MySQL 전체적인 아키텍처에서 어느 위치에 있는지 보여준다.
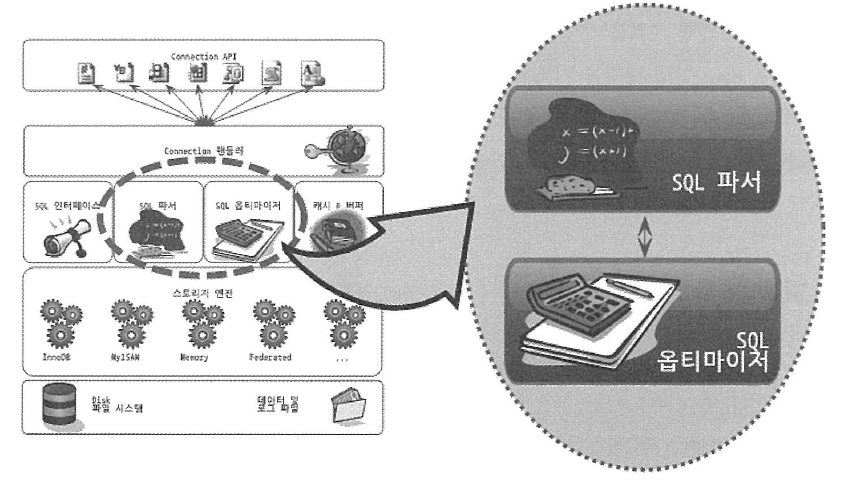
2. 옵티마이저의 종류
옵티마이저는 데이터베이스 서버에서 두뇌와 같은 역할을 담당하고 있다. 옵티마이저는 현재 대부분의 DBMS가 선택하고 있는 비용 기반 최적화(Cost-based optimizer. CBO) 방법과 예전 오라클에서 많이 사용됐던 규칙 기반 최적화 방법(Rule-based optimizer, RBO)으로 크게 나눠 볼 수 있다.
-
규칙 기반 최적화는 기본적으로 대상 테이블의 레코드 건수나 선택도 등을 고려하지 않고 옵티마이저에 내장된 우선순위에 따라 실행 계획을 수립하는 방식을 의미한다. 이 방식에서는 통계 정보(테이블의 레코드 건수나 칼럼 값의 분포도)를 조사하지 않고 실행 계획이 수립되기 때문에 같은 쿼리에 대해서는 거의 항상 같은 실행 방법을 만들어 낸다. 하지만 규칙 기반의 최적화는 이미 오래 전부터 많은 DBMS에서 거의 지원되지 않거나 업데이트되지 않은 상태로 그대로 남아 있는 것이 현실이다.
-
비용 기반 최적화는 쿼리를 처리하기 위한 여러 가지 가능한 방법을 만들고, 각 단위 작업의 비용(부하) 정보와 대상 테이블의 예측된 통계 정보를 이용해 각 실행 계획별 비용을 산출한다. 이렇게 산출된 각 실행 방법별로 최소 비용이 소요되는 처리 방식을 선택해 최종 쿼리를 실행한다.
규칙 기반 최적화는 각 테이블이나 인덱스의 통계 정보가 거의 없고, 상대적으로 느린 CPU 연산 탓에 비용 계산 과정이 부담스러웠기 때문에 사용되던 최적화 방법이다. 현재는 거의 대부분의 RDBMS가 비용 기반의 옵티마이저를 채택하고 있으며, MySQL 역시 마찬가지다.
3. 통계 정보
비용 기반 최적화에서 가장 중요한 것은 통계 정보다. 통계 정보가 정확하지 않다면 전혀 엉뚱한 방향으로 쿼리를 실행해 버릴 수 있기 때문이다. 예를 들어 1억 건의 레코드가 저장된 테이블의 통계 정보가 갱신되지 않아서 레코드가 10건 미만인 것처럼 돼 있다면 옵티마이저는 실제 쿼리 실행 시에 인덱스 레인지 스캔이 아니라 테이블을 처음부터 끝까지 읽는 방식(풀 테이블 스캔)으로 실행해 버릴 수 있다. 부정확한 통계 정보 탓에 0.1초에 끝날 쿼리가 1시간이 소요될 수 있다.
MySQL 또한 다른 DBMS와 같이 비용 기반의 최적화를 사용하지만 다른 DBMS보다 통계 정보는 그리 다양하지 않다. 기본적으로 MySQL에서 관리되는 통계 정보는 대략의 레코드 건수와 인덱스의 유니크한 값의 개수 정도가 전부다. 오라클과 같은 DBMS에서는 통계 정보가 상당히 정적이고 수집에 많은 시간이 소요되기 때문에 통계 정보만 따로 백업하기도 한다. 하지만 MySQL에서 통계 정보는 사용자가 알아채지 못하는 순간순간 자동으로 변경되기 때문에 상당히 동적인 편이다. 하지만 레코드 건수가 많지 않으면 통계 정보가 상당히 부정확한 경우가 많으므로 "ANALYZE" 명령을 이용해 강제적으로 통계 정보를 갱신해야 할 때도 있다. 특히 이런 현상은 레코드 건수가 얼마 되지 않는 개발용 MySQL 서버에서 자주 발생한다.
MEMORY 테이블은 별도로 통계 정보가 없으며, MyISAM과 InnoDB의 테이블과 인덱스 통계 정보는 다음과 같이 확인할 수 있다. ANALYZE 명령은 인덱스 키값의 분포도(선택도)만 업데이트하며, 전체 테이블의 건수는 테이블의 전체 페이지 수를 이용해 예측한다.
SHOW TABLE STATUS LIKE 'tb_test'\G
SHOW INDEX FROM tb_test;통계 정보를 갱신하려면 다음과 같이 ANALYZE를 실행하면 된다.
-- // 파티션을 사용하지 않는 일반 테이블의 통계 정보 수집
ANALYZE TABLE tb_test;
-- // 파티션을 사용하는 테이블에서 특정 파티션의 통계 정보 수집
ALTER TABLE tb_test ANALYZE PARTITION p3;ANALYZE를 실행하는 동안 MyISAM 테이블은 읽기는 가능하지만 쓰기는 안 된다. 하지만 InnoDB 테이블은 읽기와 쓰기 모두 불가능하므로 서비스 도중에는 ANALYZE을 실행하지 않는 것이 좋다. MyISAM 테이블의 ANALZYE는 정확한 키값 분포도를 위해 인덱스 전체를 스캔하므로 많은 시간이 소요된다. 이와는 달리 InnoDB 테이블은 인덱스 페이지 중에서 8개 정도만 랜덤하게 선택해서 분석하고 그 결과를 인덱스의 통계 정보로 갱신한다.
MySQL 5.1.38 미만 버전에서는 항상 랜덤하게 인덱스 페이지 8개만 읽어서 통계 정보를 수집하지만 MySQL 5.1.38 이상의 InnoDB 플러그인 버전에서는 분석할 인덱스 페이지의 개수를 "Innodb_status_sample_pages" 파라미터로 지정할 수 있다. 분석할 페이지 개수를 늘릴수록 더 정확한 통계 정보를 수집할 수 있겠지만 InnoDB의 통계 정보는 다른 DBMS보다 훨씬 자주 수집되며 서비스 도중에도 통계 정보가 수집될 수 있다. InnoDB의 통계 수집을 위한 인덱스 페이지 개수는 기본값 8개에서 2~3배 이상을 벗어나지 않도록 설정하는 것이 좋다.
참고
- Real MySQL
