MySQL 실행 계획 : 실행 계획 분석(4)
10. Extra
칼럼의 이름과는 달리, 쿼리의 실행 계획에서 성능에 관련된 중요한 내용이 Extra 칼럼에 자주 표시된다. Extra 칼럼에는 고정된 몇 개의 문장이 표시되는데, 일반적으로 2~3개씩 같이 표시된다. MySQL 5.0에서 MySQL 5.1로 업그레이드된 이후 추가된 키워드는 조금 있지만 MySQL 5.5는 MySQL 5.1과 거의 같다. 그럼 Extra 칼럼에 표시될 수 있는 문장을 하나씩 자세히 살펴보자. 여기서 설명하는 순서는 성능과는 무관하므로 각 문장의 순서 자체는 의미가 없다.
const row not found (MySQL 5.1부터)
쿼리의 실행 계획에서 const 접근 방식으로 테이블을 읽었지만 실제로 해당 테이블에 레코드가 1건도 존재하지 않으면 Extra 칼럼에 이 내용이 표시된다. Extra 칼럼에 이런 메시지가 표시되는 경우에 테이블에 적절히 테스트용 데이터를 저장하고 실행 계획을 확인해보는 것이 좋다.
Distinct
Extra 칼럼에 Distinct 키워드가 표시되는 다음 예제 쿼리를 한번 살펴보자.
EXPLAIN
SELECT DISTINCT d.dept_no
FROM departments d, dept_emp de WHERE de.dept_no=de.dept_no;| id | select_type | table | type | key | key_len | ref | rows | Extra |
| 1 | SIMPLE | d | index | ux_ deptname |
123 | NULL | 9 | Using index; Using temporary |
| 1 | SIMPLE | de | ref | PRIMARY | 12 | employees.d .dept_no |
18603 | Using index; Distinct |
위 쿼리에서 실제 조회하려는 값은 dept_no인데, departments 테이블과 dept_emp 테이블에 모두 존재하는 dept_no만 중복 없이 유니크하게 가져오기 위한 쿼리다. 그래서 두 테이블을 조인해서 그 결과에 다시 DISTINCT 처리를 넣은 것이다.
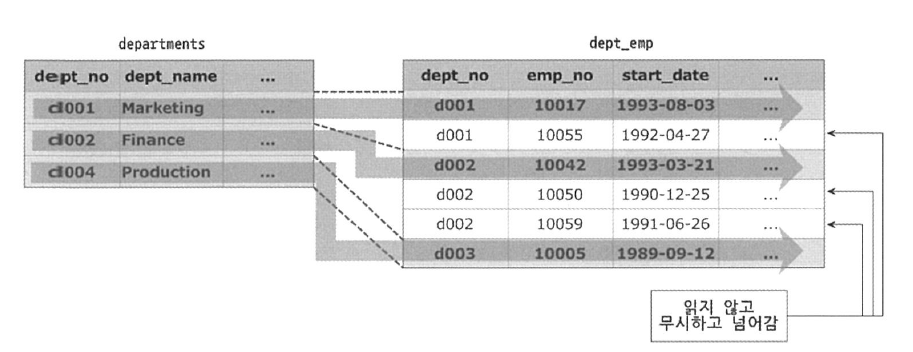
위의 그림은 실행 계획의 Extra 칼럼에 Distinct가 표시되는 경우, 어떻게 처리되는지 보여준다. 쿼리의 DISTINCT를 처리하기 위해 조인하지 않아도 되는 항목은 모두 무시하고 꼭 필요한 것만 조인했으며, dept_emp 테이블에서는 꼭 필요한 레코드만 읽었다는 것을 표현하고 있다.
Full scan on NULL key
이 처리는 'col1 IN (SELECT col2 FROM ...)"과 조건이 포함된 쿼리에서 자주 발견할 수 있는데, 만약 col1의 값이 NULL이 된다면 결과적으로 조건은 "NULL IN (SELECT col2 FROM ...)"과 같이 바뀐다. SQL 표준에서는 NULL을 "알 수 없는 값"으로 정의하고 있으며, NULL에 대한 연산의 규칙까지 정의하고 있다. 그 정의대로 연산을 수행하기 위해 이 조건은 다음과 같이 비교돼야 한다.
- 서브 쿼리가 1건이라도 결과 레코드를 가진다면 최종 비교 결과는 NULL
- 서브 쿼리가 1건도 결과 레코드를 가지지 않는다면 최종 비교 결과는 FALSE
이 비교 과정에서 col1이 NULL이면 풀 테이블 스캔(Full scan)을 해야만 결과를 알아낼 수 있다. Extra 칼럼의 "Full scan on NULL key"는 MySQL이 쿼리를 실행하는 중 col1이 NULL을 만나면 예비책으로 풀 테이블 스캔을 사용할 것이라는 사실을 알려주는 키워드다. 만약 "col1 IN (SELECT col2 FROM ...)" 조건에서 col1이 NOT NULL로 정의된 칼럼이라면 이러한 예비책은 사용되지 않고 Extra 칼럼에도 표시되지 않을 것이다.
Extra 칼럼에 "Full scan on NULL key"를 표시하는 실행 계획을 한번 살펴보자.
EXPLAIN
SELECT d.dept_no, NULL IN (SELECT id.dept_name FROM departments id)
FROM departments d;| id | select_type | table | type | key | key_len | ref | rows | Extra |
| 1 | PRIMARY | d | index | ux_ deptname |
123 | NULL | 9 | Using index |
| 2 | DEPENDENT SUBQUERY |
id | index _subquery |
ux_ deptname |
123 | const | 2 | Using index; Full scan on NULL key |
만약 칼럼이 NOT NULL로 정의되지는 않았지만 이러한 NULL 비교 규칙을 무시해도 된다면 col1이 절대 NULL은 될 수 없다는 것을 MySQL 옵티마이저에게 알려주었다. 가장 대표적인 방법으로는 이 쿼리의 조건에 "col1 IS NOT NULL"이라는 조건을 지정하는 것이다. 그러면 col1이 NULL이면 "col1 IS NOT NULL" 조건이 FALSE"가 되기 때문에 "col1 IN (SELECT col2 FROM tb_test2)" 조건은 실행하지 않는다.
SELECT *
FROM tb_test1
WHERE col1 IS NOT NULL
AND col1 IN (SELECT col2 FROM tb_test2);"Full scan on NULL key" 코멘트가 실행 계획의 Extra 칼럼에 표시됐다고 하더라도, 만약 IN이나 NOT IN 연산자의 왼쪽에 있는 값이 실제로 NULL이 없다면 풀 테이블 스캔은 발생하지 않으므로 걱정하지 않아도 된다. 하지만 IN이나 NOT IN 연산자의 왼쪽 값이 NULL인 레코드가 있고, 서브 쿼리에 개별적으로 WHERE 조건이 지정돼 있다면 상당한 성능 문제가 발생할 수도 있다.
Impossible HAVING (MySQL 5.1부터)
쿼리에 사용된 HAVING 절의 조건을 만족하는 레코드가 없을 때 실행 계획의 Extra 칼럼에는 "Impossible HAVING" 키워드가 표시된다.
EXPLAIN
SELECT e.emp_no, COUNT(*) AS cnt
FROM employees e
WHERE e.emp_no=10001
GROUP BY e.emp_no
HAVING e.emp_no IS NULL;위의 예제에서 HAVING 조건에 "e.emp_no IS NULL"이라는 조건이 추가됐지만, 사실 employees 테이블의 e.emp_no 칼럼은 프라이머리 키이면서 NOT NULL 타입의 칼럼이다. 그러므로 결코 e.emp_no IS NOT NULL 조건을 만족할 가능성이 없으므로 Extra 칼럼에서 "Impossible HAVING"이라는 키워드를 표시한다. 여기서 보여준 예제에서는 이처럼 명확한 예제(실제 테이블 구조상으로 불가능한 조건)를 사용했지만 실제로 SQL을 개발하다 보면 이렇게 테이블 구조상으로 불가능한 조건뿐 아니라 실제 데이터 때문에 이런 현상이 발생하기도 하므로 주의해야 한다.
| id | select_type | table | type | possible_ keys |
key | key_len | ref | rows | Extra |
| 1 | SIMPLE | Impossible HAVING |
애플리케이션의 쿼리 중에서 실행 계획의 Extra 칼럼에 "Impossible HAVING" 메시지가 출력된다면 쿼리가 제대로 작성되지 못한 경우가 대부분이므로 쿼리의 내용을 다시 점검하는 것이 좋다.
Impossible WHERE (MySQL 5.1부터)
"Impossible HAVING"과 비슷하며, WHERE 조건이 항상 FALSE가 될 수밖에 없는 경우 "Impossible WHERE"가 표시된다.
EXPLAIN
SELECT * FROM employees WHERE emp_no IS NULL;위의 쿼리에서 WHERE 조건절에 사용된 emp_no 칼럼은 NOT NULL이므로 emp_no IS NULL 조건은 항상 FALSE가 된다. 이럴 때 쿼리의 실행 계획에는 다음과 같이 "불가능한 WHERE 조건"으로 Extra 칼럼이 출력된다.
| id | select_type | table | type | possible_ keys |
key | key_len | ref | rows | Extra |
| 1 | SIMPLE | Impossible WHERE |
Impossible WHERE noticed after reading const tables
위의 "Impossible WHERE"의 경우에는 실제 데이터를 읽어보지 않고도 바로 테이블의 구조상으로 불가능한 조건이라고 판단할 수 있었지만 다음 예제 쿼리는 어떤 메시지가 표시될까?
EXPLAIN
SELECT * FROM employees WHERE emp_no=0;| id | select_type | table | type | key | key_len | ref | rows | Extra |
| 1 | SIMPLE | Impossible WHERE noticed after reading const tables |
이 쿼리는 실제로 실행되지 않으면 emp_no=0인 레코드가 있는지 없는지 판단할 수 없다. 그런데 이 쿼리의 실행 계획만 확인했을 뿐인데, 옵티마이저는 사번이 0인 사원이 없다는 것까지 확인한 것이다.
이를 토대로 MySQL이 실행 계획을 만드는 과정에서 쿼리의 일부분을 실행해 본다는 사실을 알 수 있다. 또한 이 쿼리는 employees 테이블의 프라이머리 키를 동등 조건으로 비교하고 있다. 이럴 때는 const 접근 방식을 사용한다는 것을 이미 살펴봤다. 쿼리에서 const 접근 방식이 필요한 부분은 실행 계획 수립 단계에서 옵티마이저가 직접 쿼리의 일부를 실행하고, 실행된 결과 값을 원본 쿼리의 상수로 대체한다.
SELECT *
FROM employees eo
WHERE oe.first_name=(
SELECT ie.first_name
FROM employees ie
WHERE ie.emp_no=10001
);No matching min/max row (MySQL 5.1부터)
쿼리의 WHERE 조건절을 만족하는 레코드가 한 건도 없는 경우 일반적으로 "Impossible WHERE ..." 문장이 Extra 칼럼에 표시된다. 만약 MIN()이나 MAX()와 같은 집합 함수가 있는 쿼리의 조건절에 일치하는 레코드가 한 건도 없을 때는 Extra 칼럼에 "No matching min/max row"라는 메시지가 출력된다. 그리고 MIN()이나 MAX()의 결과로 NULL이 반환된다.
EXPLAIN
SELECT MIN(dept_no), MAX(dept_no)
FROM dept_empp WHERE dept_no='';위의 쿼리는 dept_emp 테이블에서 dept_no 칼럼이 빈 문자열인 레코드를 검색하고 있지만 dept_no 칼럼은 NOT NULL이므로 일치하는 레코드는 한 건도 없을 것이다. 그래서 위 쿼리의 실행 계획의 Extra 칼럼에는 "No matching min/max row" 코멘트가 표시된다.
| id | select_type | table | type | possible_ keys |
key | key_len | ref | rows | Extra |
| 1 | SIMPLE | No matching min/ max row |
Extra 칼럼에 출력되는 내용 중에서 "No matching ..."이나 "Impossible WHERE ..." 등의 메시지는 잘못 생각하면 쿼리 자체가 오류인 것처럼 오해하기 쉽다. 하지만 Extra 칼럼에 출력되는 내용은 단지 쿼리의 실행 계획을 산출하기 위한 기초 자료가 없음을 표현하는 것뿐이다. Extra 칼럼에 이러한 메시지가 표시된다고 해서 실제 쿼리 오류가 발생하는 것은 아니다.
no matching row in const table (MySQL 5.1부터)
다음 쿼리와 같이 조인에 사용된 테이블에서 const 방식으로 접근할 때, 일치하는 레코드가 없다면 "no matching row in const table"이라는 메시지를 표시한다.
EXPLAIN
SELECT *
FROM dept_emp de,
(SELECT emp_no FROM employees WHERE emp_no=0) tb1
WHERE tb1.emp_no=de.emp_no AND de.dept_no='d005'이 메시지 또한 "Impossible WHERE ..."와 같은 종류로, 실행 계획을 만들기 위한 기초 자료가 없음을 의미한다.
| id | select_type | table | type | key | key_len | ref | rows | Extra |
| 1 | PRIMARY | Impossible WHERE noticed after reading const tables |
||||||
| 2 | DERIVED | no matching row in const table |
No tables used (MySQL 5.0의 "No tables"에서 키워드 변경됨)
FROM 절이 없는 쿼리 문장이나 "FROM DUAL" 형태의 쿼리 실행 계획에서는 Extra 칼럼에 "No table used"라는 메시지가 출력된다. 다른 DBMS와는 달리 MySQL은 FROM 절이 없는 쿼리도 허용된다. 이처럼 FROM 절 자체가 없거나, FROM 절에 상수 테이블을 의미하는 DUAL(칼럼과 레코드를 각각 1개씩만 가지는 가상의 상수 테이블)이 사용될 때는 Extra 칼럼에 "No table used"라는 메시지가 표시된다.
EXPLAIN SELECT 1;
EXPLAIN SELECT 1 FROM dual;| id | select_type | table | type | possible_ keys |
key | key_len | ref | rows | Extra |
| 1 | SIMPLD | No tables used |
MySQL에서는 FRM 절이 없는 쿼리도 오류 없이 실행된다. 하지만 오라클에서는 쿼리에 반드시 참조하는 테이블이 있어야 하므로 FROM 절이 필요없는 경우에 대비해 상수 테이블로 DUAL이라는 테이블을 참조한다. 또한 MySQL에서는 오라클과의 호환을 위해 FROM절에 'DUAL'이라는 테이블을 명시적으로 사용할 수도 있다. MySQL 옵타마이저가 FROM 절에 DUAL이라는 이름이 사용되면 내부적으로 FROM 절이 없는 쿼리 문장과 같은 방식으로 처리된다.
Not exists
프로그램을 개발하다 보면 A 테이블에는 존재하지만 B 테이블에는 없는 값을 조회해야 하는 쿼리가 자주 사용된다. 이럴 때는 주로 NOT IN (subquery) 형태나 NOT EXITST 연산자를 주로 사용한다. 이러한 형태의 조인을 안티-조인(Anti-JOIN)이라고 한다. 똑같은 처리를 아우터 조인(LEFT OUTER JOIN)을 이용해도 구현할 수 있다. 일반적으로 안티-조인으로 처리해야 하지만 레코드의 건수가 많을 때는 NOT IN (subquery)이나 NOT EXISTS 연산자보다는 아우터 조인을 이용하면 빠른 성능을 낼 수 있다.
아우터 조인을 이용해 dept_emp 테이블에는 있지만 departments 테이블에는 없는 dept_no를 조회하는 쿼리를 예제로 살펴보자. 아래의 예제 쿼리는 departements 테이블을 아우터로 조인해서 ON절이 아닌 WHERE절에 아우터 테이블(departments)의 dept_no 칼럼이 NULL인 레코드만 체크해서 가져온다. 즉 안티-조인은 일반 조인(INNER JOIN)을 했을 때 나오지 않는 결과만 가져오는 방법이다.
EXPLAIN
SELECT *
FROM dept_emp de
LEFT JOIN departments d ON de.dept_no=d.dept.no
WHERE d.dept_no IS NULL;이렇게 아우터 조인을 이용해 안티-조인을 수행하는 쿼리에서는 Extra 칼럼에 Not exists 메시지가 표시된다. Not exists 메시지는 이 쿼리를 NOT EXISTS 형태의 쿼리로 변환해서 처리했음을 의미하는 것이 아니라 MySQL이 내부적으로 어떤 최적화를 했는데 그 최적화의 이름이 "Not exists"인 것이다. Extra 칼럼의 Not exists와 SQL의 NOT EXISTS 연산자를 혼동하지 않도록 주의하자.
| id | select_type | table | type | key | key_len | ref | rows | Extra |
| 1 | SIMPLE | de | ALL | 334868 | ||||
| 1 | SIMPLE | d | eq_ref | PRIMARY | 12 | employees. de.dept_no |
1 | Using where; Not exists |
Range checked for each record (index map: N)
두 개의 테이블을 조인하는 다음의 쿼리를 보면서 이 메시지의 의미를 이해해 보자. 조인 조건에 상수가 없고 둘 다 변수(e1.emp_no와 e2.emp_no)인 경우, MySQL 옵티마이저는 e1 테이블을 먼저 읽고 조인을 위해 e2를 읽을 때, 인덱스 레인지 스캔과 풀 테이블 스캔 중에서 어느 것이 효율적일지 판단할 수 없게 된다. 즉, e1 테이블의 레코드를 하나씩 읽을 때마다 e1.emp_no 값이 계속 바뀌므로 쿼리의 비용 계산을 위한 기준값이 계속 변하는 것이다. 그래서 어떤 접근 방법으로 e2 테이블을 읽는 것이 좋을지 판단할 수 없는 것이다.
EXPLAIN
SELECT *
FROM employees e1, employees e2
WHERE e2.emp_no >= e1.emp_no;예를 들어 사번이 1번부터 1억까지 있다고 가정해 보자. 그러면 e1 테이블을 처음부터 끝까지 스캔하면서 e2 테이블에서 e2.emp_no >= e1.emp_no 조건을 만족하는 레코드를 찾아야 하는데, 문제는 e1.emp_no=1인 경우에는 e2 테이블의 1억건 전부를 읽어야 한다는 것이다. 하지만 e1.emp_no=100000000인 경우에는 e2 테이블을 한 건만 읽으면 된다는 것이다. 아래 그림은 이 시나리오를 그림으로 표현해 둔 것이다.
그래서 e1 테이블의 emp_no가 작을 때는 e2 테이블을 풀 테이블 스캔으로 접근하고, e1 테이블의 emp_no가 큰 값일 때는 e2 테이블을 인덱스 레인지 스캔으로 접근하는 형태를 수행하는 것이 최적의 조인 방법일 것이다. 지금까지 설명한 내용을 줄여서 표현하면 "매 레코드마다 인덱스 레인지 스캔을 체크한다"라고 할 수 있는데, 이것이 Extra 칼럼에 표시되는 "Range checked for each record"의 의미다.

| id | select_type | table | type | key | key_len | ref | rows | Extra |
| 1 | SIMPLE | e1 | ALL | 3 | 300584 | Using index | ||
| 1 | SIMPLE | e2 | ALL | 300584 | Range checked for each record (index map: 0x1) |
Extra 칼럼의 출력 내용 중에서 "(index map: 0x1)"은 사용할지 말지를 판단하는 후보 인덱스의 순번을 나타낸다. "index map"은 16진수로 표시되는데, 이를 해석하려면 우선 이진수로 표현을 바꿔야 한다. 위의 실행 계획에서는 0x1이 표시됐는데, 이는 이진수로 바꿔도 1이다. 그래서 이 쿼리는 e2(employees) 테이블의 첫 번째 인덱스를 사용할지 아니면 풀 테이블을 스캔할지를 매번 판단한다는 것을 의미한다. 여기서 테이블의 첫 번째 인덱스란 "SHOW CREATE TABLE employees" 명령으로 테이블의 구조를 조회했을 때 제일 먼저 출력되는 인덱스를 의미한다.
그리고 쿼리 실행 계획의 type 칼럼의 값이 ALL로 표시되어 풀 테이블 스캔으로 처리된 것으로 해석하기 쉽다. 하지만 Extra 칼럼에 "Range checked for each record"가 표시되면 type 칼럼에는 ALL로 표시된다. 즉 "index map"에 표시된 후보 인덱스를 사용할지 여부를 검토해서, 이 후보 인덱스가 별도 도움이 되지 않는다면 최종적으로 풀 테이블 스캔을 사용하기 때문에 ALL로 표시된 것이다.
"index map"에 대한 이해를 돕기 위해 조금 더 복잡한 "index map"을 예제로 살펴보자. 우선 아래와 같이 인덱스가 여러 개인 테이블에 실행되는 쿼리의 실행 계획에서 "(index map: 0x19)"이라고 표시됐다고 가정하자.
CREATE TABLE tb_member(
mem_id INTEGER NOT NULL,
mem_name VARCHAR(100) NOT NULL,
mem_nickname VARCHAR(100) NOT NULL,
mem_region TINYINT,
mem_gender TINYINT,
mem_phone VARCHAR(25),
PRIMARY KEY (mem_id),
INDEX ix_nick_name (mem_nickname, mem_name),
INDEX ix_nick_region (mem_nickname, mem_region),
INDEX ix_nick_gender (mem_nickname, mem_gender),
INDEX ix_nick_phone (mem_nickname, mem_phone)
);우선 0x19 값을 비트(이진) 값으로 변환해 보면 11001이다. 이 비트 배열을 해석하는 방법은 다음 표와 같다. 이진 비트 맵의 각 자리 수는 "CREATE TABLE tb_member ..." 명령에 나열된 인덱스의 순번을 의미한다.
| 자리수 | 다섯 번째 자리 | 네 번째 자리 | 세 번째 자리 | 두 번째 자리 | 첫 번째 자리 |
| 비트맵 값 | 1 | 1 | 0 | 0 | 1 |
| 지칭 인덱스 | ix_nick_phone | ix_nick_gender | ix_nick_region | ix_nick_name | PRIMARY KEY |
결론적으로 실행 계획에서 "(index map: 0x19)"의 의미는 위의 표에서 각 자리 수의 값이 1인 다음 인덱스를 사용 가능한 인덱스 후보로 선정했음을 의미한다.
- PRIMARY KEY
- ix_nick_gender
- ix_nick_phone
각 레코드 단위로 이 후보 인덱스 가운데 어떤 인덱스를 사용할지 결정하게 되는데, 실제 어떤 인덱스가 사용됐는지를 알 수 없다. 단지 각 비트 맵의 자리 수가 1인 순번의 인덱스가 대상이라는 것을 알 수 있다.
실행 계획의 Extra 칼럼에 "Range checked for each record"가 표시되는 쿼리가 많이 실행되는 MySQL 서버에서는 "SHOW GLOBAL STATUS" 명령으로 표시되는 상태 값 중에서 "Select_range_check"의 값이 크게 나타난다.
Scanned N database(MySQL 5.1부터)
MySQL 5.0부터는 기본적으로 INFORMATION_SCHEMA라는 DB가 제공된다. INFORMATION_SCHEMA DB는 MySQL 서버 내에 존재하는 DB의 메타 정보(테이블, 칼럼, 인덱스 등의 스키마 정보)를 모아둔 DB다. INFORMATION_SCHEMA 데이터베이스 내의 모든 테이블은 읽기 전용이며, 단순히 조회만 가능하다. 실제로 이 데이터베이스 내의 테이블은 레코드가 았는 것이 아니라, SQL을 이용해 조회할 때마다 메타 정보를 MySQL 서버의 메모리에서 가져와서 보여준다. 이런 이유로 한꺼번에 많은 테이블을 조회할 경우 시간이 많이 걸린다.
MySQL 5.1부터는 INFORMATION_SCHEMA DB를 빠르게 조회할 수 있게 개선됐다. 개선된 조회를 통해 메타 정보를 검색할 경우에는 쿼리 실행 계획의 Extra 칼럼에 "Scanned N databases"라는 메시지가 표시된다. "Scanned N databases"에서 N은 몇 개의 DB 정보를 읽었는지 보여주는 것인데, N은 0가 1 또는 all의 값을 가지며 각각의 의미는 다음과 같다.
- 0 : 특정 테이블의 정보만 요청되어 데이터베이스 전체의 메타 정보를 읽지 않음
- 1 : 특정 데이터베이스 내의 모든 스키마 정보가 요청되어 해당 데이터베이스의 모든 스키마 정보를 읽음
- All : MySQL 서버 내의 모든 스키마 정보를 다 읽음
이 코멘트는 INFORMATION_SCHEMA 내의 테이블로부터 데이터를 읽는 경우에만 표시된다.
EXPLAIN
SELECT table_name
FROM information_schema, tables
WHERE table_schema = 'employees' AND table_name = 'employees';위 쿼리는 employees DB의 employees 테이블 정보만 읽었기 때문에 employees DB 전체를 참조하지는 않았다. 그래서 다음과 같이 "Scanned 0 databases"로 Extra 칼럼에 표시된 것이다.
| id | select_type | table | type | .. | key | .. | .. | .. | Extra |
| 1 | SIMPLE | TABLES | ALL | .. | TABLE_SCHEMA, TABLE_NAME |
.. | .. | .. | Using where; Skip_open_table; Scanned 0 databases |
애플리케이션에서는 INFORMATION_SCHEMA DB에서 메타 정보를 조회하는 쿼리는 거의 사용하지 않으므로 실행 계획에 "Scanned N databases"라는 코멘트가 표시되는 쿼리는 거의 없을 것이다.
Select tables optimized away
MIN() 또는 MAX()만 SELECT 절에 사용되거나 또는 GROUP BY로 MIN(), MAX()를 조회하는 쿼리가 적절한 인덱스를 사용할 수 없을 때 인덱스를 오름차순 또는 내림차순으로 1건만 읽는 형태의 최적화가 적용된다면 Extra 칼럼에 "Select tables optimized away"가 표시된다.
또한 MyISAM 테이블에 대해서는 GROUP BY 없이 COUNT(*)만 SELECT할 때도 이런 형태의 최적화가 적용된다. MyISAM 테이블은 전체 레코드 건수를 별도로 관리하기 때문에 인덱스나 데이터를 읽지 않고도 전체 건수를 빠르게 조회할 수 있다. 하지만 WHERE 절에 조건을 가질 때는 이러한 최적화를 사용하지 못한다.
EXPLAIN;
SELECT MAX(emp_no), MIN(emp_no) FROM employees;
EXPLAIN
SELECT MAX(from_date), MIN(from_date) FROM salaries WHERE emp_no=10001;| id | select_type | table | type | possible_ keys |
key | key_len | ref | rows | Extra |
| 1 | SIMPLE | Select tables optimized away |
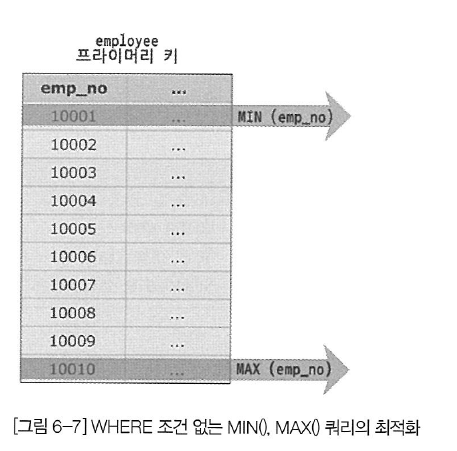
첫 번째 쿼리는 employees 테이블에 있는 emp_no 칼럼에 인덱스가 생성돼 있으므로 "Select tables optimized away" 최적화가 가능하다. 아래 그림은 employees 테이블의 emp_no 칼럼에 생성된 인덱스에서 첫 번째 레코드와 마지막 레코드만 읽어서 최솟값과 최댓값을 가져오는 표현하고 있다.
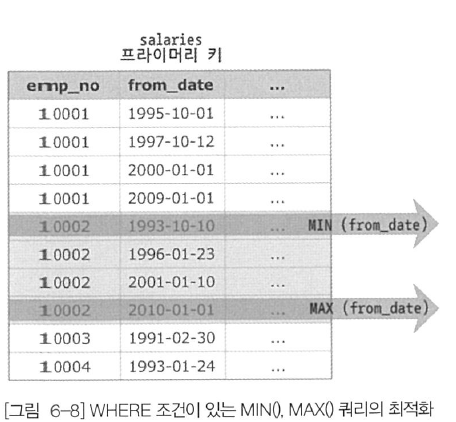
두 번째 쿼리의 경우 salaries 테이블에 emp_no + from_date로 인덱스가 생성돼 있으므로 인덱스가 emp_no=10001인 레코드를 검색하고, 검색된 결과 중에서 오름차순 또는 내림차순으로 하나만 조회하면 되기 때문에 이러한 최적화가 가능한 것이다. 아래 그림은 이 과정을 보여준다.
참고
- Real MySQL
