3. 왜 자꾸 String을 쓰지 말라는 거야
String 클래스는 잘 사용하면 상관이 없지만, 잘못 사용하면 메모리에 많은 영향을 준다.
1. String 클래스를 잘못 사용한 사례
대부분의 웹 기반 시스템은 DB에서 데이터를 갖고 와서 그 데이터를 화면에 출력하는 시스템이기 때문에, 쿼리 문장을 만들기 위한 String 클래스와 그 결과를 처리하기 위한 Collection 클래스를 가장 많이 사용하게 된다.
다음은 일반적으로 사용하는 쿼리 작성 문장이다.
String strSQL = "";
strSQL += "select * ";
strSQL += "from ( ";
strSQL += "select A_column, ";
strSQL += "B_column ,";
// 중간 생략요즘은 myBatis, Hibernate와 같은 데이터 메핑 프레임워크를 사용하지만, 예전에는 보통 이렇게 쿼리를 작성했다. 꼭 쿼리 문장이 아니더라도, 문자열을 다루는 경우는 많을 것이다. 그런데 이렇게 쿼리를 작성하면, 개발 시에는 좀 편할지 몰라도 메모리를 많이 사용하게 된다는 문제가 있다. 총 400라인을 수행한다고 가정하면 실행 결과는 다음과 같다.
| 구분 | 결과 |
| 메모리 사용량 | 10회 평균 약 5MB |
| 응답 시간 | 10회 평균 약 5ms |
이 소스 코드를 StringBuilder로 변경하면 다음과 같다.
String Builder = new StringBuilder();
strSQL.append("select * ");
strSQL.append("from ( ");
strSQL.append("select A_column, ");
strSQL.append("B_column, ");
// 중간 생략변경 후 수행 결과는 다음과 같다.
| 구분 | 결과 |
| 메모리 사용량 | 10회 평균 약 371KB |
| 응답 시간 | 10회 평균 약 0.3ms |
2. StringBuffer 클래스와 StringBuilder 클래스
- JDK 5.0 기준으로 문자열을 만드는 클래스는 String, StringBuffer, StringBuilder가 가장 많이 사용된다. 여기서 StringBuilder 클래스는 JDK 5.0에서 새로 추가되었다.
- StringBuffer 클래스나 StringBuilder 클래스에서 제공하는 메서드는 동일하다.
- StringBuffer 클래스는 스레드에 안전하게(ThreadSafe) 설계되어 있으므로, 여러 개의 스레드에서 하나의 StringBuffer 객체를 처리해도 전혀 문제가 되지 않는다.
- 하지만 StringBuilder 클래스는 단일 스레드에서의 안전성만을 보장한다. 그렇기 때문에 여러 개의 스레드에서 하나의 StringBuilder 객체를 처리하면 문제가 발생한다.
간단하게 두 클래스의 생성자와 메서드를 정리해보자.
| 생성자 | 설명 |
| StringBuffer() | 아무 값도 없는 StringBuffer() 객체를 생성한다. 기본 용량은 16개의 char이다. |
| StringBuffer(CharSequence seq) | CharSequence를 매개변수로 받아 그 seq 값을 갖는 StringBuffer를 생성한다. |
| StringBuffer(int capacity) | capacity에 지정한 만큼의 용량을 갖는 StringBuffer를 생성한다. |
| StringBuffer(String str) | str의 값을 갖는 StringBuffer를 생성한다. |
- CharSequence는 인터페이스이다. 다시 말하면, 클래스가 아니기 때문에 이 인스턴스로 객체를 생성할 수 없다. 이 인터페이스를 구현한 클래스로는 CharBuffer, String, StringBuffer, StringBuilder가 있으며, StringBuffer나 StringBuilder로 생성한 객체를 전달할 때 사용된다.
package com.perf.string;
public class StringBufferTest1 {
public static void main(String[] args) {
StringBuilder sb = new StringBuilder();
sb.append("ABCDE");
StringBufferTest1 sbt = new StringBufferTest1();
sbt.check(sb);
}
public void check(CharSequence cs) {
StringBuffer sb = new StringBuffer(cs);
System.out.println("sb.length=" + sb.length());
}
}주로 사용하는 두 개의 메서드를 알아보자. 바로 append() 메서드와 insert() 메서드이다. 이 두 가지 메서드는 여러 가지 타입의 매개변수를 수용하기 위해서 다음의 타입들을 매개변수로 사용할 수 있다.
- boolean
- char
- char[]
- CharSequence
- double
- float
- int
- long
- Object
- String
- StringBuffer
append() 메서드는 말 그대로 기존 값의 맨 끝 자리에 넘어온 값들을 덧붙이는 작업을 수행하고, insert() 메서드는 지정된 위치 이후에 넘어온 값들을 덧붙이는 작업을 수행한다. 만약 insert() 메서드를 수행할 때 지정한 위치까지 값이 할당되지 않으면 StringIndexOutOfBoundsException이 발생한다.
package com.perf.string;
public class StringBufferTest2 {
public static void main(String[] args) {
StringBuffer sb = new StringBuffer();
// 이렇게 사용해도 되고
sb.append("ABCDE");
sb.append("FGHIJ");
sb.append("KLMNO");
// 이렇게 사용해도 된다.
sb.append("ABCDE")
.append("FGHIJ")
.append("KLMNO");
// 하지만 이렇게 사용하면 안된다.
sb.append("ABCDE"+"="+"FGHIJ");
sb.insert(3, "123");
System.out.println(sb);
}
}append() 메서드를 사용할 때 위의 코드처럼 append() 메서드 내에서 +를 이용해 문자열을 더하면 StringBuffer를 사용하는 효과가 전혀 없다. 그러므로 되도록으로 append() 메서드를 이용하여 문자열을 더해야 한다.
3. String vs StringBuffer vs StringBuilder
<%
final String aValue = "abcde";
for(int outLoop=0;outLoop<10;outLoop++) {
String a = new String();
StringBuffer b = new StringBuffer();
StringBuilder c = new StringBuilder();
for(int loop=0;loop<10000;loop++) {
a+=aValue;
}
for(int loop=0;loop<10000;loop++) {
b.append(aValue);
}
String temp = b.toString();
for(int loop=0;loop<10000;loop++) {
c.append(aValue);
}
String temp2 = c.toString();
}
%>
OK
<%= System.currentTimeMillis() %>소스를 JSP로 만든 이유는 이 코드를 java 파일로 만들어 반복 작업을 수행할 경우, 클래스를 메모리로 로딩하는 데 소요되는 시간이 발생하기 때문이다. 그래서 JSP로 만들어서 최초에 이 화면을 호출했을 때의 응답 시간 및 메모리 사용량은 측정에서 제외하고, 두 번째 호출부터 10회 반복 수행한 결과의 누적 값을 구하였다.
위 코드에 대해 간단히 살펴보자.
- 더할 값(aValue)에서 임시로 사용되는 객체가 생성되지 않도록 하기 위해서 final String으로 지정해 놓았다.
- 그리고 문자열을 더하기 위한 객체를 3가지로 만들었다.
- 각각의 객체를 만 번(10,000번)씩 수행하면서 각 객체에 'abcde'를 추가한다.
- StringBuffer와 StringBuilder가 String 클래스의 객체로 변환되는 동일한 일을 할 수 있도록 toString()를 호출한다.
- 이러한 행위를 10번 반복한다.
- 앞서 수행된 결과 화면과 다른지 확인하기 위해서 현재 시간을 프린트한다.
String, StringBuffer, StringBuilder 셋 중 어느 것이 가장 빠르고 메모리를 적게 사용할까? 총 반복 횟수를 알아보면 다음과 같다.
- 10,000회 반복하여 문자열을 더하고, 이러한 작업을 10회 반복한다.
- 그리고 이 화면을 10회 반복 호출한다.
그러므로 각 문자열을 더하는 라인은 총 100만 번씩 수행된다. 프로파일링 툴을 사용하여 위의 코드를 실행한 결과는 다음과 같다.
| 주요 소스 부분 | 응답 시간(ms) | 비고 |
| a+=aValue; | 95,801.41ms | 95초 |
| b.append(aValue); String temp=b.toString() |
247.48ms 14.21ms |
0.24초 |
| c.append(aValue); String temp2=b.toString() |
174.17ms 13.38ms |
0.17초 |
메모리 사용량은 다음과 같다.
| 주요 소스 부분 | 메모리 사용량(bytes) | 생성된 임시 객체 수 | 비고 |
| a+=aValue; | 100,102,000,000 | 4,000,000 | 약 95Gb |
| b.append(aValue); String temp=b.toString |
29,493,600 10,004,000 |
1,200 200 |
약 28Mb 약 9.5Mb |
| c.append(aValue); String temp2=b.toString() |
29,493,600 10,004,000 |
1,200 200 |
약 28Mb 약 9.5Mb |
응답 시간은 String보다 StringBuffer가 약 367배 빠르며, StringBuilder가 약 512배 더 빠르다. 메모리는 StringBuffer와 StringBuilder보다 String에서 약 3,390배 더 사용된다. 이러한 결과가 왜 발생하는지 알아보자.
a += aValue;이 소스 라인이 수행되면 어떻게 될까? a에 aValue를 더하면 새로운 String 클래스의 객체가 만들어지고, 이전에 있던 a 객체는 필요 없는 쓰레기 값이 되어 GC 대상이 되어 버린다.
a += aValue 값(첫 번째 수행) : abcde
a += aValue 값(두 번째 수행) : abcdeabcde
a += aValue 값(세 번째 수행) : abcdeabcdeabcde그림으로 나타내면 다음과 같다.
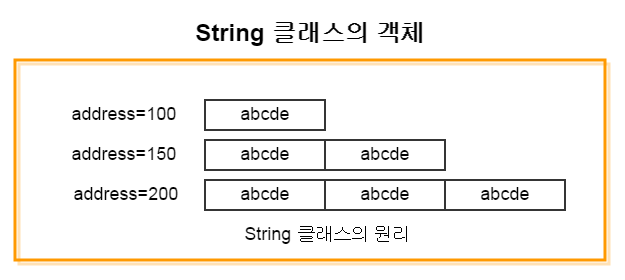
가장 처음에 a 객체에는 'abcde' 값이 저장되어 있었다. 값이 저장되기 전의 a 객체는 a+=aValue;를 수행하면서 사라지고(쓰레기가 되고), 새로운 주소와 'abcdeabcde'라는 값을 갖는 a 객체가 생성된다. 세 번째 수행되면 'abcdeabcdeabcde'라는 값을 갖는 또 다른 새로운 객체가 만들어진다.
이런 작업이 반복 수행되면서 메모리를 많이 사용하게 되고, 응답 속도에서 많은 영향을 미치게 된다. 앞에서도 보았지만, GC를 하면 할수록 시스템의 CPU를 사용하게 되고 시간도 많이 소요된다. 그래서 프로그래밍을 할 때, 메모리 사용률을 최소화하는 것은 당연한 일이다.
그러면 StringBuffer나 StringBuilder는 어떻게 작동되는지 알아보자. 이 두 가지 클래스가 동작하는 원리는 다음 그림과 같이 나타낼 수 있다.

StringBuffer나 StringBuilder는 String과는 다르게 새로운 객체를 생성하지 않고, 기존에 있는 객체의 크기를 증가시키면서 값을 더한다.
그렇다면 String을 쓰는 것은 무조건 나쁘고, 무조건 StringBuffer와 StringBuilder 클래스만을 사용해야 하는 것일까?
- String은 짧은 문자열을 더할 경우 사용한다.
- StringBuffer는 스레드에 안전한 프로그램이 필요할 때나, 개발 중인 시스템의 부분이 스레드에 안전할지 모를 경우 사용하면 좋다. 만약 클래스에 static으로 선언한 문자열을 변경하거나, singleton으로 선언된 클래스(JVM에 객체가 하나만 생성되는 클래스)에 선언된 문자열일 경우에는 이 클래스를 사용해야만 한다.
- StringBuilder는 스레드에 안전한지의 여부와 전혀 관계 없는 프로그램을 개발할 때 사용하면 좋다. 만약 메서드 내부에 변수를 선언했다면, 해당 변수는 그 메서드 내에서만 살아있으므로, StringBuilder를 사용하면 된다.
4. 버전에 따른 차이
만약 JDK 5.0 이상을 사용한다면 결과가 약간 달라진다. 아래와 같은 소스 코드가 있다고 하자.
package com.perf.string;
public class VersionTest {
String str = "Here " + "is " + "a " + "sample.";
public VersionTest() {
int i = 1;
String str2 = "Here " + "is " + "a " + "samples.";
}
}먼저 JDK 1.4를 사용해서 컴파일해 보자. 일반적으로 많이 쓰이는 JAD를 사용하여 역 컴파일한 소스는 다음과 같다.
package com.perf.string;
public class VersionTest {
public VersionTest() {
str = "Here is a sample."
int i = 1;
String s = "Here " + "is " + "a " + "samples.";
}
String str;
}역 컴파일한 소스를 보면 자바 컴파일러가 문자열 더한 것을 컴파일할 때 알아서 더해 놓고 있다. 그래도 중간에 int나 다른 객체가 들어가게 되면 위의 예와 같이 그대로 더하도록 되어 있다. 어차피 필요 없는 객체는 생성이 된다는 의미이다. 그럼 JDK 5.0에서는 얼마나 달라졌는지 알아보자.
package com.perf.string;
public class VersionTest {
public VersionTest() {
str = "Here is a sample."
int i = 1;
String str2= (new StringBuilder("Here is "))
.append(i).append(" samples.").toString();
}
String str;
}만약 WAS나 시스템이 JDK 5.0 이상을 사용한다면, 컴파일러에서 자동으로 StringBuilder로 변환하여 준다.
하지만 반복 루프를 사용해서 문자열을 더할 때에는 객체를 계속 추가한다는 사실에는 변함이 없다. 그러므로 String 클래스를 쓰는 대신, 스레드와 관련이 있으면 StringBuffer를, 스레드 안전 여부와 상관이 없으면 StringBuilder를 사용하는 것을 권장한다.
참고
- 자바 성능 튜닝 이야기
