4. 어디에 담아야 하는지...
Transfer Object 객체 내부에서는 대부분 Collection과 Map 인터페이스를 상속받는 객체가 많이 사용된다. 그것을 일반적으로 목록 데이터를 가장 담기 좋은 것이 배열이고, 그 다음으로 Collections 관련 객체들이기 때문이다.
배열은 처음부터 크기를 지정해야 하지만, Collection의 객체 대부분은 그럴 필요 없이 객체들이 채워질 때마다 자동으로 크기가 증가된다.
그렇다면 객체마다 성능상 차이가 실제로 얼마나 발생하는지 알아보자.
1. Collection 및 Map 인터페이스의 이해
앞서 말했듯이 배열을 제외하면 데이터를 담기 가장 좋은 객체는 Collection과 Map 인터페이스를 상속한 객체이다. 이 인터페이스의 구성은 다음의 그림과 같다.
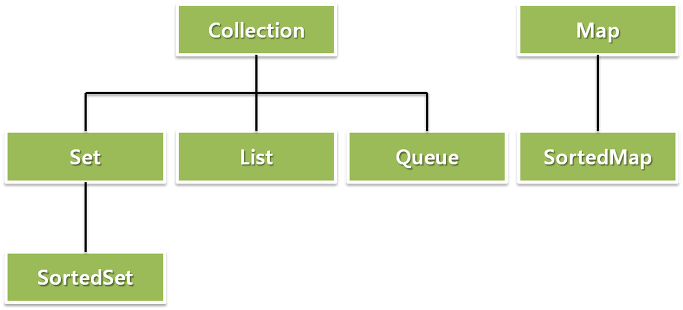
이 글미의 Queue 인터페이스는 JDK 5.0에서 추가되었다. 간단하게 각 인터페이스에 대해서 살펴보자.
- Collection : 가장 상위 인터페이스이다.
- Set : 중복을 허용하지 않는 집합을 처리하기 위한 인터페이스이다.
- SortedSet : 오름차순을 갖는 Set 인터페이스이다.
- List : 순서가 있는 집합을 처리하기 위한 인터페이스이기 때문에 인덱스가 있어 위치를 지정하여 값을 찾을 수 있다. 중복을 허용하며, List 인터페이스를 상속받는 클래스 중에 가장 많이 사용하는 것으로 ArrayList가 있다.
- Queue : 여러 개의 객체를 처리하기 전에 담아서 처리할 때 사용하기 위한 인터페이스이다. 기본적으로 FIFO를 따른다.
- Map : Map은 키와 값의 쌍으로 구성된 객체의 집합을 처리하기 위한 인터페이스이다. 이 객체는 중복되는 키를 허용하지 않는다.
- SortedMap : 키를 오름차순으로 정렬하는 Map 인터페이스이다.
먼저 Set 인터페이스에 대해서 알아보자. Set 인터페이스는 중복이 없는 집합 객체를 만들 때 유용하다. Set 객체에 데이터를 집어 넣으면 중복된 데이터는 들어가지 않는다.
Set 인터페이스를 구현한 클래스로는 HashSet, TreeSet, LinkedHashSet 세가지가 있다.
- HashSet : 데이터를 해쉬 테이블에 담는 클래스로 순서 없이 저장된다.
- TreeSet : red-black이라는 트리에 데이터를 담는다. 값에 따라서 순서가 정해진다. 데이터를 담으면서 동시에 정렬을 하기 때문에 HashSet보다 성능상 느리다.
- LinkedHashSet : 해쉬 테이블에 데이터를 담는데, 저장된 순서에 따라서 순서가 정해진다.
red-black 트리란 이진 트리 구조로 데이터를 담는 구조를 말하며, 다음과 같은 특징이 있다.
1. 각각의 노드는 검은색이나 붉은색이어야 한다.
2. 가장 상위(root) 노드는 검은색이다.
3. 가장 말단(leaves) 노드는 검은색이다.
4. 붉은 노드는 검은 하위 노드만을 가진다(따라서 검은 노드는 붉은 상위 노드만을 가진다).
5. 모든 말단 노드로 이동하는 경로의 검은 노드 수는 동일하다.
List 인터페이스를 구현한 클래스들에 대해서 알아보자. List는 배열의 확장판이라고 보면 된다. C나 Java의 배열은 모두 최초 선언 시 담을 수 있는 데이터의 개수가 한정되어 있다. 하지만, List 인터페이스를 구현한 클래스들은 담을 수 있는 크기가 자동으로 증가되므로, 데이터의 개수를 확실히 모를 때 유용하게 사용된다. 구현한 클래스에는 ArrayList와 LinkedList 클래스가 있으며, 원조 클래스 격인 Vector가 있다.
- Vector : 객체 생성 시에 크기를 지정할 필요가 없는 배열 클래스이다.
- ArrayList : Vector와 비슷하지만, 동기화 처리가 되어 있지 않다.
- LinkedList : ArrayList와 동일하지만, Queue 인터페이스를 구현했기 때문에 FIFO 큐 작업을 수행한다.
Map은 Key와 Value의 쌍으로 저장되는 구조체이다. 그래서, 단일 객체만 저장되는 다른 Collection API들과는 다르게 따로 분리되어 있다. 이러한 Map은 ID와 패스워드, 코드와 이름 등 고유한 값과 그 값을 설명하는 데이터를 보관할 때 유용하다. Map 인터페이스를 구현한 클래스들은 HashMap, TreeMap, LinkedHashMap 세 가지가 있고, 원조 클래스 격인 Hashtable 클래스가 있다.
- Hashtable : 데이터를 해쉬 테이블에 담는 클래스이다. 내부에서 관리하는 해쉬 테이블 객체가 동기화되어 있으므로, 동기화가 필요한 부분에서는 이 클래스를 사용해야 한다.
- HashMap : 데이터를 해쉬 테이블에 담는 클래스이다. Hashtable 클래스와 다른 점은 null 값을 허용한다는 것과 동기화되어 있지 않다는 것이다.
- TreeMap : red-black 트리에 데이터를 담는다. TreeSet과 다른 점은 키에 의해서 순서가 정해진다는 것이다.
- LinkedHashMap : HashMap과 거의 동일하며 이중 연결 리스트(doubly-linkedlist)라는 방식을 사용하여 데이터를 담는다는 점만 다르다.
Queue는 데이터를 담아 두었다가 먼저 들어온 데이터부터 차례대로 처리하기 위해서 사용된다. 예를 들어 SMS와 같은 문자를 처리할 때 서버에서 들어온 순서대로 처리해 주려면 이 Queue에 던져 주고, 처음에 요청한 데이터부터 처리하면 된다. 그런데, List도 순서가 있고, Queue도 순서가 있는데 왜 굳이 Queue가 필요할까?
List의 가장 큰 단점은 데이터가 많은 경우 처리 시간이 늘어난다는 점이다. 가장 앞에 있는 데이터(0번 데이터)를 지우면 그다음 1번 데이터부터 마지막 데이터까지 한 칸씩 옯기는 작업을 수행해야 하므로, 데이터가 적을 때는 상관 없지만 데이터가 많으면 많을수록 가장 앞에 있는 데이터를 지우는데 소요되는 시간이 증가된다.
Queue 인터페이스를 구현한 클래스는 두 가지로 나뉜다. java.util 패키지에 속하는 LinkedList와 PriorityQueue는 일반적인 목적의 큐 클래스이며, java.util.concurrent 패키지에 속하는 클래스들은 컨커런트 큐 클래스이다.
- PriorityQueue : 큐에 추가된 순서와 상관없이 먼저 생성된 객체가 먼저 나오도록 되어 있는 큐다.
- LinkedBlockingQueue : 저장할 데이터의 크기를 선택적으로 정할 수도 있는 FIFO 기반의 링크 노드를 사용하는 블로킹 큐다.
- ArrayBlockingQueue : 저장되는 데이터의 크기가 정해져 있는 FIFO 기반의 블로킹 큐이다.
- PriorityBlockingQueue : 저장되는 데이터의 크기가 정해져 있지 않고, 객체의 생성순서에 따라서 순서가 저장되는 블로킹 큐다.
- DelayQueue : 큐가 대기하는 시간을 지정하여 처리하도록 되어 있는 큐다.
- SynchronousQueue : put() 메서드를 호출하면, 다른 스레드에서 take() 메서드가 호출될 때까지 대기하도록 되어 있는 큐다. 이 큐에는 저장되는 데이터가 없다. API에서 제공하는 대부분의 메서드는 0이나 null을 리턴한다.
블로킹 큐(blocking queue)란 크기가 지정되어 있는 큐에 더 이상 공간이 없을 때, 공간이 생길 때가지 대기하도록 만들어진 큐를 의미한다.2. Set 클래스 중 무엇이 가장 빠를까?
먼저 Set 관련 클래스들의 성능을 비교해 보기 위해서 다음과 같이 JMH 테스트 코드를 만든다. 데이터를 담을 때 얼마나 시간 차이가 발생하는지 확인해 보자.
package com.perf.collection;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Set;
import java.util.TreeSet;
import java.util.concurrent.TimeUnit;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.GenerateMicroBenchmark;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.State;
@State(Scope.Thread)
@BenchmarkMode({ Mode.AverageTime })
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class SetAdd {
int LOOP_COUNT=1000;
Set<String> set;
String data = "abcdefghijklmnopqrstuvwxyz";
@GenerateMicroBenchmark
public void addHashSet() {
set=new HashSet<String>();
for(int loop=0;loop<LOOP_COUNT;loop++) {
set.add(data+loop);
}
}
@GenerateMicroBenchmark
public void addTreeSet() {
set=new TreeSet<String>();
for(int loop=0;loop<LOOP_COUNT;loop++) {
set.add(data+loop);
}
}
@GenerateMicroBenchmark
public void addLinkedHashSet() {
set=new LinkedHashSet<String>();
for(int loop=0;loop<LOOP_COUNT;loop++) {
set.add(data+loop);
}
}
}결과는 다음과 같다.
| 대상 | 평균 응답 시간(마이크로초) |
| HashSet | 375 |
| TreeSet | 1,249 |
| LinkedHashSet | 378 |
HashSet과 LinkedHashSet의 성능이 비슷하고, TreeSet의 순서로 성능 차이가 발생한다. 추가로 다음과 같이 Set의 초기 크기를 지정하여 객체를 생성한 후 데이터를 add하는 테스트 코드를 작성해 볼 수 있다.
@GenerateMicroBenchmark
public void addHashSetWithInitialSize() {
set=new HashSet<String>(LOOP_COUNT);
for(int loop=0;loop<LOOP_COUNT;loop++) {
set.add(data+loop);
}
}이 경우는 데이터 크기를 미리 알고 있을 때 사용할 수 있으며, HashSet만의 성능을 비교해 보면 다음과 같다.
| 대상 | 평균 응답 시간(마이크로초) |
| HashSet | 375 |
| HashSetWithInitialSize | 352 |
큰 차이는 발생하지 않지만 저장되는 데이터의 크기를 알고 있을 경우에는 객체 생성시 크기를 미리 지정하는 것이 성능상 유리하다.
이번에는 Set 클래스들이 데이터를 읽을 때 얼마나 많은 차이가 발생하는지 확인해보자.
package com.perf.collection;
import java.util.HashSet;
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.Set;
import java.util.TreeSet;
import java.util.concurrent.TimeUnit;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.GenerateMicroBenchmark;
import org.openjdk.jmh.annotations.Level;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.Setup;
import org.openjdk.jmh.annotations.State;
@State(Scope.Thread)
@BenchmarkMode({ Mode.AverageTime })
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class SetIterate {
int LOOP_COUNT=1000;
Set<String> hashSet;
Set<String> treeSet;
Set<String> linkedHashSet;
String data = "abcdefghijklmnopqrstuvwxyz";
String []keys;
String result=null;
@Setup(Level.Trial)
public void setUp() {
hashSet=new HashSet<String>();
treeSet=new TreeSet<String>();
linkedHashSet=new LinkedHashSet<String>();
for(int loop=0;loop<LOOP_COUNT;loop++) {
String tempData=data+loop;
hashSet.add(tempData);
treeSet.add(tempData);
linkedHashSet.add(tempData);
}
}
@GenerateMicroBenchmark
public void iterateHashSet() {
Iterator<String> iter = hashSet.iterator();
while(iter.hasNext()) {
result = iter.next();
}
}
@GenerateMicroBenchmark
public void iterateTreeSet() {
Iterator<String> iter = treeSet.iterator();
while(iter.hasNext()) {
result = iter.next();
}
}
@GenerateMicroBenchmark
public void iterateLinkedHashSet() {
Iterator<String> iter = linkedHashSet.iterator();
while(iter.hasNext()) {
result = iter.next();
}
}
}결과를 확인해 보자.
| 대상 | 평균 응답 시간(마이크로초) |
| HashSet | 26 |
| TreeSet | 35 |
| LinkedHashSet | 16 |
확인해 보면 LinkedHashSet이 가장 빠르고, HashSet, TreeSet 순으로 데이터를 가져오는 속도가 느려진다. 그런데, 일반적으로 Set은 여러 데이터를 넣어 두고 해당 데이터가 존재하는지를 확인하는 용도로 많이 사용된다. 따라서 데이터는 Iterator로 가져오는 것이 아니라, 랜덤하게 가져와야 한다.
데이터를 랜덤하게 가져오기 위해서 다음과 같이 RandomKeyUtil 클래스에 generateRandomKeysSwap()이라는 메서드를 만들었다.
package com.perf.collection;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Random;
import java.util.Set;
import java.util.concurrent.TimeUnit;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.GenerateMicroBenchmark;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.State;
@State(Scope.Thread)
@BenchmarkMode({ Mode.AverageTime })
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class RandomKeyUtil {
public static String[] generateRandomSetKeysSwap(Set<String> set) {
int size=set.size();
String result[] = new String[size];
Random random = new Random();
int maxNumber = size;
Iterator<String> iterator=set.iterator();
int resultPos=0;
while (iterator.hasNext()) {
result[resultPos++]=iterator.next();
}
for (int loop = 0; loop < size; loop++) {
int randomNumber1 = random.nextInt(maxNumber);
int randomNumber2 = random.nextInt(maxNumber);
String temp=result[randomNumber2];
result[randomNumber2]=result[randomNumber1];
result[randomNumber1]=temp;
}
return result;
}
}이처럼 generateRandomSetKeysSwap() 메서드를 활용하면, 데이터의 개수만큼 불규칙적인 키를 뽑아 낼 수 있다. 다음에는 비순차적으로 데이터를 뽑는 SetContains 클래스를 만들자.
package com.perf.collection;
import java.util.HashSet;
import java.util.LinkedHashSet;
import java.util.Set;
import java.util.TreeSet;
import java.util.concurrent.TimeUnit;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.GenerateMicroBenchmark;
import org.openjdk.jmh.annotations.Level;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.Setup;
import org.openjdk.jmh.annotations.State;
@State(Scope.Thread)
@BenchmarkMode({ Mode.AverageTime })
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class SetContains {
int LOOP_COUNT=1000;
Set<String> hashSet;
Set<String> treeSet;
Set<String> linkedHashSet;
String data = "abcdefghijklmnopqrstuvwxyz";
String []keys;
@Setup(Level.Trial)
public void setUp() {
hashSet=new HashSet<String>();
treeSet=new TreeSet<String>();
linkedHashSet=new LinkedHashSet<String>();
for(int loop=0;loop<LOOP_COUNT;loop++) {
String tempData=data+loop;
hashSet.add(tempData);
treeSet.add(tempData);
linkedHashSet.add(tempData);
}
if(keys==null || keys.length!=LOOP_COUNT) {
keys=RandomKeyUtil.generateRandomSetKeysSwap(hashSet);
}
}
@GenerateMicroBenchmark
public void containsHashSet() {
for(String key:keys) {
hashSet.contains(key);
}
}
@GenerateMicroBenchmark
public void containsTreeSet() {
for(String key:keys) {
treeSet.contains(key);
}
}
@GenerateMicroBenchmark
public void containsLinkedHashSet() {
for(String key:keys) {
linkedHashSet.contains(key);
}
}
}이 클래스를 수행한 결과는 다음과 같다.
| 대상 | 평균 응답 시간(마이크로초) |
| HashSet | 32 |
| TreeSet | 841 |
| LinkedHashSet | 32 |
HashSet과 LinkedHashSet의 속도는 빠르지만, TreeSet의 속도는 느리다는 것을 알 수 있다. 그러면 왜 결과가 왜 항상 느리게 나오는 TreeSet 클래스를 만들었을까? TreeSet은 데이터를 저장하면서 정렬한다. TreeSet의 선언문을 보자.
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, Serializable구현한 인터페이스 중에 NavigableSet이 있다. 이 인터페이스는 특정 값보다 큰 값이나 작은 값, 가장 큰 값, 가장 작은 값 등을 추출하는 메서드를 선언해 놓았으며 JDK 1.6부터 추가된 것이다. 즉, 데이터를 순서에 따라 탐색하는 작업이 필요할 때는 TreeSet을 사용하는 것이 좋다는 의미다. 하지만, 그럴 필요가 없을 때는 HashSet이나 LinkedHashSet을 사용하는 것을 권장한다.
3. List 관련 클래스 중 무엇이 빠를까?
이번에는 List 인터페이스를 구현한 ArrayList, LinkedList, Vector 클래스들의 속도를 비교해 보자.
package com.perf.collection;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Vector;
import java.util.concurrent.TimeUnit;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.GenerateMicroBenchmark;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.State;
@State(Scope.Thread)
@BenchmarkMode({ Mode.AverageTime })
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class ListAdd {
int LOOP_COUNT=1000;
List<Integer> arrayList;
List<Integer> vector;
List<Integer> linkedList;
@GenerateMicroBenchmark
public void addArrayList() {
arrayList=new ArrayList<Integer>();
for(int loop=0;loop<LOOP_COUNT;loop++) {
arrayList.add(loop);
}
}
@GenerateMicroBenchmark
public void addArrayListWithInitialSize() {
arrayList=new ArrayList<Integer>(LOOP_COUNT);
for(int loop=0;loop<LOOP_COUNT;loop++) {
arrayList.add(loop);
}
}
@GenerateMicroBenchmark
public void addVector() {
vector=new Vector<Integer>();
for(int loop=0;loop<LOOP_COUNT;loop++) {
vector.add(loop);
}
}
@GenerateMicroBenchmark
public void addLinkedList() {
linkedList=new LinkedList<Integer>();
for(int loop=0;loop<LOOP_COUNT;loop++) {
linkedList.add(loop);
}
}
}결과를 확인해 보자.
| 대상 | 평균 응답 시간(마이크로초) |
| ArrayList | 28 |
| Vector | 31 |
| LinkedList | 40 |
보는 것과 같이 데이터를 넣는 속도는 어떤 클래스든 큰 차이가 없는 것을 볼 수 있다. 이번에는 데이터를 꺼내는 속도를 확인해 보자. 테스트 코드는 다음과 같다.
package com.perf.collection;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Vector;
import java.util.concurrent.TimeUnit;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.GenerateMicroBenchmark;
import org.openjdk.jmh.annotations.Level;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.Setup;
import org.openjdk.jmh.annotations.State;
@State(Scope.Thread)
@BenchmarkMode({ Mode.AverageTime })
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class ListGet {
int LOOP_COUNT=1000;
List<Integer> arrayList;
List<Integer> vector;
LinkedList<Integer> linkedList;
int result=0;
@Setup(Level.Trial)
public void setUp() {
arrayList=new ArrayList<Integer>();
vector=new Vector<Integer>();
linkedList=new LinkedList<Integer>();
for(int loop=0;loop<LOOP_COUNT;loop++) {
arrayList.add(loop);
vector.add(loop);
linkedList.add(loop);
}
}
@GenerateMicroBenchmark
public void getArrayList() {
for(int loop=0;loop<LOOP_COUNT;loop++) {
result=arrayList.get(loop);
}
}
@GenerateMicroBenchmark
public void getVector() {
for(int loop=0;loop<LOOP_COUNT;loop++) {
result=vector.get(loop);
}
}
@GenerateMicroBenchmark
public void getLinkedList() {
for(int loop=0;loop<LOOP_COUNT;loop++) {
result=linkedList.get(loop);
}
}
}데이터를 추가하는 시간은 비슷했지만, 데이터를 가져오는 시간은 다음과 같다.
| 대상 | 평균 응답 시간(마이크로초) |
| ArrayList | 4 |
| Vector | 105 |
| LinkedList | 1,512 |
ArrayList의 속도가 가장 빠르고, Vector와 LinkedList는 속도가 매우 느리다. LinkedList가 터무니없게 느리게 나온 이유는 LinkedList가 Queue 인터페이스를 상속받기 때문이다. 이를 수정하기 위해서는 순차적으로 결과를 받아오는 peek() 메서드를 사용해야 한다.
LinkedList는 peek() 메서드로 처리하도록 다음과 같이 timeGetData() 메서드를 변경하자.
@GenerateMicroBenchmark
public void peekLinkedList() {
for(int loop=0;loop<LOOP_COUNT;loop++) {
result=linkedList.peek();
}
}변경 후 결과는 다음과 같다.
| 대상 | 평균 응답 시간(마이크로초) |
| ArrayList | 4 |
| Vector | 105 |
| LinkedList | 1,512 |
| LinkedListPeek | 0.16 |
LinkedList 클래스를 사용할 때는 get() 메서드가 아닌 peek() 메서드나 poll() 메서드를 사용해야 한다.
그런데 왜 ArrayList와 Vector의 성능 차이가 이렇게 클까? ArrayList는 여러 스레드에서 접근할 경우 문제가 발생할 수 있지만, Vector는 여러 스레드에서 접근할 경우를 방지하기 위해서 get() 메서드에 synchronized가 선언되어 있다. 따라서, 성능 저하가 발생할 수 밖에 없다.
마지막으로 데이터를 삭제하는 속도를 비교해보자.
package com.perf.collection;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Vector;
import java.util.concurrent.TimeUnit;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.GenerateMicroBenchmark;
import org.openjdk.jmh.annotations.Level;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.Setup;
import org.openjdk.jmh.annotations.State;
@State(Scope.Thread)
@BenchmarkMode({ Mode.AverageTime })
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class ListRemove {
int LOOP_COUNT=10;
List<Integer> arrayList;
List<Integer> vector;
LinkedList<Integer> linkedList;
@Setup(Level.Trial)
public void setUp() {
arrayList=new ArrayList<Integer>();
vector=new Vector<Integer>();
linkedList=new LinkedList<Integer>();
for(int loop=0;loop<LOOP_COUNT;loop++) {
arrayList.add(loop);
vector.add(loop);
linkedList.add(loop);
}
}
@GenerateMicroBenchmark
public void removeArrayListFromFirst() {
ArrayList<Integer> tempList=new ArrayList<Integer>(arrayList);
for(int loop=0;loop<LOOP_COUNT;loop++) {
tempList.remove(0);
}
}
@GenerateMicroBenchmark
public void removeVectorFromFirst() {
List<Integer> tempList=new Vector<Integer>(vector);
for(int loop=0;loop<LOOP_COUNT;loop++) {
tempList.remove(0);
}
}
@GenerateMicroBenchmark
public void removeLinkedListFromFirst() {
LinkedList<Integer> tempList=new LinkedList<Integer>(linkedList);
for(int loop=0;loop<LOOP_COUNT;loop++) {
tempList.remove(0);
}
}
@GenerateMicroBenchmark
public void removeArrayListFromLast() {
ArrayList<Integer> tempList=new ArrayList<Integer>(arrayList);
for(int loop=LOOP_COUNT-1;loop>=0;loop--) {
tempList.remove(loop);
}
}
@GenerateMicroBenchmark
public void removeVectorFromLast() {
List<Integer> tempList=new Vector<Integer>(vector);
for(int loop=LOOP_COUNT-1;loop>=0;loop--) {
tempList.remove(loop);
}
}
@GenerateMicroBenchmark
public void removeLinkedListFromLast() {
LinkedList<Integer> tempList=new LinkedList<Integer>(linkedList);
for(int loop=0;loop<LOOP_COUNT;loop++) {
tempList.removeLast();
}
}
}실행 결과는 다음과 같다.
| 대상 | 평균 응답 시간(마이크로초) |
| ArrayListFirst | 418 |
| ArrayListLast | 146 |
| VectorFirst | 687 |
| VectorLast | 426 |
| LinkedListFirst | 423 |
| LinkedListLast | 407 |
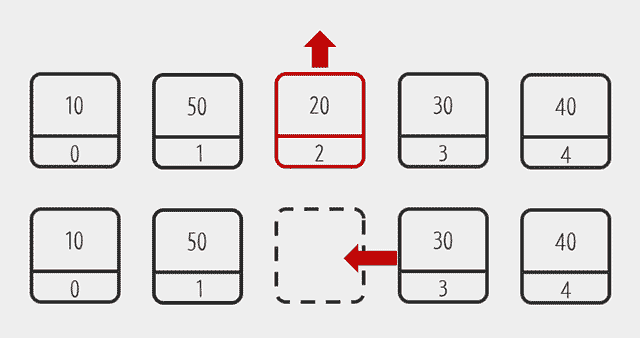
결과를 보면 첫 번째 값을 삭제하는 메서드와 마지막 값을 삭제하는 메서드의 속도 차이가 크다. 그리고, LinkedList는 별 차이가 없다. 그 이유가 뭘까? ArrayList나 Vector는 실제로 그 안에 배열을 사용한다. 그 배열의 0번째 값을 삭제하면 첫 번째에 있던 값이 0번째로 와야만 한다. 그런데, 하나의 값만 옮겨야 하는 것이 아니라 위의 그림과 같이 첫번째부터 마지막까지 있는 값까지 위치를 변경해야만 한다.
따라서, ArrayList와 Vector의 첫번째 값을 삭제하면 이렇게 느릴 수 밖에 없다.
4. Map 관련 클래스 중에서 무엇이 빠를까?
마지막으로 Map 관련 클래스의 속도를 비교해 보자. 대부분의 데이터 추가 작업의 속도는 비슷하므로, get() 메서드를 사용하여 데이터를 꺼내는 시간을 살펴보자.
package com.perf.collection;
import java.util.HashMap;
import java.util.Hashtable;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.TreeMap;
import java.util.concurrent.TimeUnit;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.GenerateMicroBenchmark;
import org.openjdk.jmh.annotations.Level;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.Setup;
import org.openjdk.jmh.annotations.State;
@State(Scope.Thread)
@BenchmarkMode({ Mode.AverageTime })
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class MapGet {
int LOOP_COUNT=1000;
Map<Integer,String> hashMap;
Map<Integer,String> hashtable;
Map<Integer,String> treeMap;
Map<Integer,String> linkedHashMap;
int keys[];
@Setup(Level.Trial)
public void setUp() {
if(keys==null || keys.length!=LOOP_COUNT) {
hashMap=new HashMap<Integer,String>();
hashtable=new Hashtable<Integer,String>();
treeMap=new TreeMap<Integer,String>();
linkedHashMap=new LinkedHashMap<Integer,String>();
String data="abcdefghijklmnopqrstuvwxyz";
for(int loop=0;loop<LOOP_COUNT;loop++) {
String tempData=data+loop;
hashMap.put(loop,tempData);
hashtable.put(loop,tempData);
treeMap.put(loop,tempData);
linkedHashMap.put(loop,tempData);
}
keys=RandomKeyUtil.generateRandomNumberKeysSwap(LOOP_COUNT);
}
}
@GenerateMicroBenchmark
public void getSeqHashMap() {
for(int loop=0;loop<LOOP_COUNT;loop++) {
hashMap.get(loop);
}
}
@GenerateMicroBenchmark
public void getRandomHashMap() {
for(int loop=0;loop<LOOP_COUNT;loop++) {
hashMap.get(keys[loop]);
}
}
@GenerateMicroBenchmark
public void getSeqHashtable() {
for(int loop=0;loop<LOOP_COUNT;loop++) {
hashtable.get(loop);
}
}
@GenerateMicroBenchmark
public void getRandomHashtable() {
for(int loop=0;loop<LOOP_COUNT;loop++) {
hashtable.get(keys[loop]);
}
}
@GenerateMicroBenchmark
public void getSeqTreeMap() {
for(int loop=0;loop<LOOP_COUNT;loop++) {
treeMap.get(loop);
}
}
@GenerateMicroBenchmark
public void getRandomTreeMap() {
for(int loop=0;loop<LOOP_COUNT;loop++) {
treeMap.get(keys[loop]);
}
}
@GenerateMicroBenchmark
public void getSeqLinkedHashMap() {
for(int loop=0;loop<LOOP_COUNT;loop++) {
linkedHashMap.get(loop);
}
}
@GenerateMicroBenchmark
public void getRandomLinkedHashMap() {
for(int loop=0;loop<LOOP_COUNT;loop++) {
linkedHashMap.get(keys[loop]);
}
}
}결과는 다음과 같다.
| 대상 | 평균 응답 시간 | 대상 | 평균 응답 시간 |
| SeqHashMap | 32 | RandomHashMap | 40 |
| SeqHashtable | 106 | RandomHashtable | 120 |
| SeqLinkedHashMap | 34 | RandomLinkedHashMap | 46 |
| SeqTreeMap | 197 | RandomTreeMap | 277 |
대부분의 클래스들이 동일하지만, 트리 형태로 처리하는 TreeMap이 가장 느린 것을 확인할 수 있따.
Sun에서 정리한 인터페이스별로 가장 일반적으로 사용되는 클래스는 다음과 같다.
| 인터페이스 | 클래스 |
| Set | HashSet |
| List | ArrayList |
| Map | HashMap |
| Queue | LinkedList |
5. Collection 관련 클래스의 동기화
HashSet, TreeSet, LinkedHashSet, ArrayList, LinkedList, HashMap, TreeMap, LinkedHashMap은 동기화(synchronized)되지 않은 클래스이다. 이와는 반대로 동기화되어 있는 클래스로는 Vector와 Hashtable이 있다. 다시 말해서 JDK 1.0 버전에 생성된 Vector나 Hashtable은 동기화 처리가 되어 잇지만, JDK 1.2 버전 이후에 만들어진 클래스는 모두 동기화 처리가 되어 있지 않다.
Collections 클래스에는 최신 버전 클래스들의 동기화를 지원하기 위한 synchronized로 시작하는 메서드들이 있다. 이 메서드들은 각각의 클래스에서 다음과 같이 사용할 수 있다.
Set s = Collections.synchronizedSet(new HashSet(...));
SortedSet s = Collections.synchronizedSortedSet(new TreeSet(...));
Set s = Collections.synchronizedSet(new LinkedHashSet(...));
List list = Collections.synchronizedList(new ArrayList(...));
List list = Collections.synchronizedList(new LinkedList(...));
Map m = Collections.synchronizedMap(new HashMap(...));
Map m = Collections.synchronizedMap(new TreeMap(...));
Map m = Collections.syncrhonizedMap(new LinkedHashMap(...));그리고, Map의 경우 키 값들을 Set으로 가져와 Iterator를 통해 데이터를 처리하는 경우가 발생한다. 이때 ConcurrentModificationException이라는 예외가 발생할 수 있다. 이 예외가 발생하는 여러 가지 원인 중 하나는 스레드에서 Iterator로 어떤 Map 객체의 데이터를 꺼내고 있는데, 다른 스레드에서 해당 Map을 수정하는 경우다. 이런 문제가 발생할 때는 직접 필요한 클래스를 구현하여 사용하는 것도 좋지만, 가장 편한 방법은 java.util.concurrent 패키지에 있는 클래스들을 확인해 보는 것이다. 왜냐하면 이 패키지에는 이러한 문제를 해결해 줄 수 있는 각종 클래스들이 존재하기 때문이다.
참고
- 자바 성능 튜닝 이야기
