MySQL 실행 계획 : MySQL의 주요 처리 방식
MySQL의 실행 계획 중에서 성능에 미치는 영향이 미미하거나 별로 사용되지 않는 것들도 있지만 성능에 아주 큰 영향을 미치는 것들도 많이 있었다. 여기서는 성능에 미치는 영향이 큰 실행 계획과 연관이 있는 단위 작업에 대해 조금 더 자세히 살펴보자.
설명하는 내용 중에서 "풀 테이블 스캔"을 제외한 나머지는 모두 스토리지 엔진이 아니라 MySQL 엔진에서 처리되는 내용이다. 또한 MySQL 엔진에서 부가적으로 처리하는 작업은 대부분 성능에 미치는 영향력이 큰데, 안타깝게도 모두 쿼리의 성능을 저하시키는 데 한몫하는 작업이다. 스토리지 엔진에서 읽은 레코드를 MySQL 엔진이 아무런 가공 작업도 하지 않고 사용자에게 반환한다면 최상의 성능을 보장하는 쿼리가 되겠지만, 우리가 필요로 하는 대부분의 쿼리는 그렇지 않다. MySQL 엔진에서 처리하는 데 시간이 오래 걸리는 작업의 원리를 알아둔다면 쿼리를 튜닝하는 데 상당히 많은 도움이 될 것이다.
1. 풀 테이블 스캔
풀 테이블 스캔은 인덱스를 사용하지 않고 테이블의 데이터를 처음부터 끝까지 읽어서 요청된 작업을 처리하는 작업을 의미한다. MySQL 옵티마이저는 다음과 같은 조건이 일치할 때 주로 풀 테이블 스캔을 선택한다.
- 테이블의 레코드 건수가 너무 작아서 인덱스를 통해 읽는 것보다 풀 테이블 스캔을 하는 편이 더 빠른 경우(일반적으로 테이블이 페이지 1개로 구성된 경우)
- WHERE 절이나 ON 절에 인덱스를 이용할 수 있는 적절한 조건이 없는 경우
- 인덱스 레인지 스캔을 사용할 수 있는 쿼리라 하더라도 옵티마이저가 판단한 조건 일치 레코드 건수가 너무 많은 경우(인덱스의 B-Tree를 샘플링해서 조사한 통계 정보 기준)
- 반대로, max_seeks_for_key 변수를 특정 값(IN)으로 설정하면 MySQL 옵티마이저는 인덱스의 기수성(Cardinality)이나 선택도(Selectivity)를 무시하고, 최대 N건만 읽으면 된다고 판단하게 한다. 이 값을 작게 설정할수록 MySQL 서버가 인덱스를 더 사용하도록 유도함
일반적으로 테이블의 전체 크기는 인덱스보다 훨씬 크기 때문에 테이블을 처음부터 끝까지 읽는 작업은 상당히 많은 디스크 읽기가 필요하다. 그래서 대부분의 DBMS는 풀 테이블 스캔을 실행할 대 한꺼번에 여러 개의 블록이나 페이지를 읽어오는 기능이 있으며, 그 수를 조절할 수 있다. 하지만 MySQL에는 풀 테이블 스캔을 실행할 때 한꺼번에 몇 개씩 페이지를 읽어올지 설정하는 변수는 없다. 그래서 많은 사람은 MySQL이 풀 테이블 스캔을 실행할 때 디스크로부터 페이지를 하나씩 읽어 오는 것으로 생각할 때가 많다.
이것은 MyISAM 스토리지 엔진에는 맞는 이야기지만 InnoDB에서는 틀린 말이다. InnoDB 스토리지 엔진은 특정 테이블의 연속된 데이터 페이지가 읽히면 백그라운드 스레드에 의해 리드 어헤드(Read ahead) 작업이 자동으로 시작된다. 리드 어헤드란 어떤 영역의 데이터가 앞으로 필요해지리라는 것을 예측해서 요청이 오기 전에 미리 디스크에서 읽어 InnoDB의 버퍼 풀에 가져다 두는 것을 의미한다. 즉, 풀 테이블 스캔이 실행되면 처음 몇 개의 데이터 페이지는 포그라운드 스레드(Foreground thread, 클라이언트 스레드)가 페이지 읽기를 실행하지만 특정 시점부터는 읽기 작업을 백그라운드 스레드로 넘긴다. 백그라운드 스레드가 읽기를 넘겨받는 시점부터는 한번에 4개 또는 8개씩의 페이지를 읽으면서 계속 그 수를 증가시킨다. 이때 한 번에 최대 64개의 데이터 페이지까지 읽어서 버퍼 풀에 저장해 둔다. 포그라운드 스레드는 미리 버퍼 풀에 준비된 데이터를 가져다 사용하기만 하면 되므로 쿼리가 상당히 빨리 처리되는 것이다.
MySQL 5.1의 InnoDB 플러그인 버전부터는 언제 리드 어헤드를 시작할지 시스템 변수를 이용해 변경할 수 있다. 그 시스템 변수의 이름이 "innodb_read_ahead_threshold"인데, 일반적으로 디폴트 설정으로도 충분하지만 데이터웨어하우스용으로 MySQL을 사용한다면 이 옵션을 더 낮은 값으로 설정해서 더 자주 리드 어헤드가 시작되도록 유도하는 것도 좋은 방법이다.
2. ORDER BY 처리(Using filesort)
레코드 1~2건을 가져오는 쿼리를 제외하면 대부분의 SELECT 쿼리에서 정렬은 필수적으로 사용된다. 데이터웨어 하우스처럼 대량의 데이터를 조회해서 일괄 처리하는 기능이 아니라면 아마도 레코드 정렬 요건은 대부분의 조회 쿼리에 포함돼 있을 것이다. 정렬을 처리하기 위해서는 인덱스를 이용하는 방법과 쿼리가 실행될 때 "Filesort"라는 별도의 처리를 이용하는 방법으로 나눌 수 있다.
| 장점 | 단점 | |
| 인덱스를 이용 | INSERT, UPDATE, DELETE 쿼리가 실행될 때 이미 인덱스가 정렬돼 있어서 순서대로 읽기만 하면 되 므로 매우 빠르다. |
INSERT, UPDATE, DELETE 작업 시 부가적인 인덱 스 추가/삭제 작업이 필요하므로 느리다. 인덱스 때문에 디스크 공간이 더 많이 필요하다. 인덱스 개수가 늘어날수록 InnoDB의 버퍼 풀이 나 MyISAM이 키 캐시용 메모리가 많이 필요하다. |
| Filesort 이용 | 인덱스를 생성하지 않아도 되므 로 인덱스를 이용할 때의 단점이 장점으로 바뀐다. 정렬해야 할 레코드가 많지 않으 면 메모리에서 Filesort가 처리 되므로 충분히 삐르다. |
정렬 작업이 쿼리 실행 시 처리되므로 레코드 대 상 건수가 많아질수록 쿼리의 응답 속도가 느리다. |
물론 레코드를 정렬하기 위해 항상 "Filesort"라는 정렬 작업을 거쳐야 하는 것은 아니다. 하지만 다음과 같은 이유로 모든 정렬을 인덱스를 이용하도록 튜닝하기란 거의 불가능하다.
- 정렬 기준이 너무 많아서 요건별로 모두 인덱스를 생성하는 것이 불가능한 경우
- GROUP BY의 결과 또는 DISTINCT와 같은 처리의 결과를 정렬해야 하는 경우
- UNION의 결과와 같이 임시 테이블의 결과를 다시 정렬해야 하는 경우
- 랜덤하게 결과 레코드를 가져와야 하는 경우(때로는 인덱스를 이용할 수 있도록 개선할 수 있음)
MySQL이 인덱스를 이용하지 않고 별도의 정렬 처리를 수행했는지는 실행 계획의 Extra 칼럼에 "Using filesort"라는 코멘트가 표시되는지로 판단할 수 있다. 여기서는 MySQL의 정렬이 어떻게 처리되는지 살펴보고자 한다. MySQL의 정렬 특성을 이해하면 쿼리를 튜닝할 때 어떻게 하면 조금이라도 더 빠른 쿼리가 될지 쉽게 판단할 수 있을 것이다.
소트 버퍼(Sort buffer)
MySQL은 정렬을 수행하기 위해 별도의 메모리 공간을 할당받아서 사용하는데, 이 메모리 공간을 소트 버퍼라고 한다. 소트 버퍼는 정렬이 필요한 경우에만 할당되며, 버퍼의 크기는 정렬해야 할 레코드의 크기에 따라 가변적으로 증가하지만 최대 사용 가능한 소트 버퍼의 공간은 sort_buffer_size라는 시스템 변수로 설정할 수 있다. 소트 버퍼를 위한 메모리 공간은 쿼리의 실행이 완료되면 즉시 시스템으로 반납된다.
여기서는 아주 이상적인 부분만 이야기했지만 지금부터 정렬이 왜 문제가 되는지 살펴보자. 정렬해야 할 레코드가 아주 소량이어서 메모리에 할당된 소트 버퍼만으로 정렬할 수 있다면 아주 빠르게 정렬이 처리될 것이다. 하지만 정렬해야 할 레코드의 건수가 소트 버퍼로 할당된 공간보다 크다면 어떻게 될까? 이때 MySQL은 정렬해야 할 레코드를 여러 조각으로 나눠서 처리하는데, 이 과정에서 임시 저장을 위해 디스크를 사용한다.
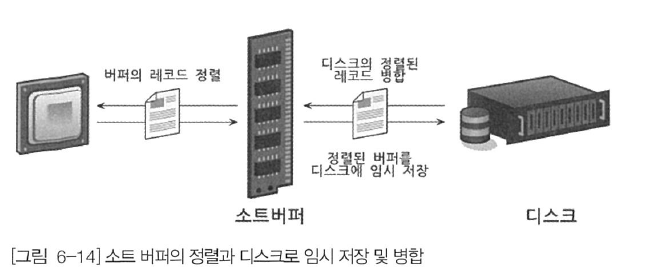
위의 그림처럼 메모리의 소트 버퍼에서 정렬을 수행하고, 그 결과를 임시로 디스크에 기록해 둔다. 그리고 그다음 레코드를 가져와서 다시 정렬해서 반복적으로 디스크에 임시 저장한다. 이처럼 각 버퍼 크기 만큼씩 정렬된 레코드를 다시 병합하면서 정렬을 수행해야 한다. 이 병합 작업을 멀티 머지(Multi-merge)라고 표현하며, 수행된 멀티 머지 횟수는 Sort_merge_passes라는 상태 변수(SHOW STATUS VARIABLES; 명령 참조)에 누적된다.
이 작업들이 모두 디스크의 쓰기와 읽기를 유발하며, 레코드 건수가 많을수록 이 반복 작업의 횟수가 많아진다. 소트 버퍼를 크게 설정하면 디스크를 사용하지 않아서 더 빨라질 것으로 생각할 수도 있지만 실제 벤치마크 결과로는 거의 차이가 없었다. 아래 그림은 MySQL의 소트 버퍼 크기를 확장해가면서 쿼리를 실행해 본 결과 걸리는 시간을 측정한 것이다. MySQL의 소트 버퍼 크기가 256KB에서 512KB 사이에서 최적의 성능을 보였으며, 그 이후로는 아무리 소트 버퍼 크기가 확장돼도 성능상 차이가 없었다. 하지만 8MB 이상일 때 성능이 조금 더 향상되는 것으로 벤치마킹됐다는 자료도 있는데, 이는 웹과 같은 OLTP 성격의 쿼리가 아니라 대용량의 정렬 작업에 해당하는 내용일 것으로 보인다. 소트 버퍼의 이러한 특성은 리눅스의 메모리 할당 방식이 원인일 것으로 예측하는 사람들이 많았지만 정확한 원인은 확인된 바가 없다.
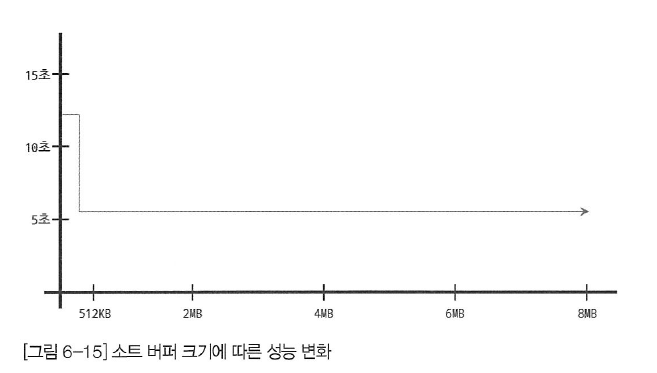
지금까지의 경험상, 소트 버퍼의 크기는 56KB에서 1MB 미만이 적절할 것으로 생각한다. MySQL은 글로벌 메모리 영역과 세션(로컬) 메모리 영역으로 나눠서 생각할 수도 있는데, 정렬을 위해 할당받는 소트 버퍼는 세션 메모리 영역에 해당된다. 즉 소트 버퍼는 여러 클라이언트가 공유해서 사용할 수 있는 영역이 아니다. 커넥션이 많으면 많을수록 정렬 작업이 많으면 많을수록 소트 버퍼로 소비되는 메모리 공간이 커짐을 의미한다. 소트 버퍼의 크기를 10~20MB와 같이 터무니없이 많이 설정할 수 있다. 이럴 때 대량의 레코드를 정렬하는 쿼리가 여러 커넥션에서 동시에 실행되면 운영체제는 메모리 부족 현상을 겪는다. 더는 메모리 여유 공간이 없는 경우에는 운영체제의 OOM-Killer가 여유 메모리를 확보하기 위해 프로세스를 강제로 종료시킬 것이다. 그런데 OOM-Killer는 메모리를 가장 많이 사용하고 있는 프로세스를 강제 종료한다. 일반적으로 MySQL 서버가 가장 많은 메모리를 사용하기 때문에 강제 종료 1순위가 된다.
소트 버퍼를 크게 설정해서 빠른 성능을 얻을 수는 없지만 디스크의 읽기와 쓰기 사용량은 줄일 수 있다. 그래서 MySQL 서버의 데이터가 많거나 디스크의 I/O 성능이 낮은 장비라면 소트 버퍼의 크기를 더 크게 설정하는 것이 도움될 수도 있다. 하지만 소트 버퍼를 너무 크게 설정하면 서버의 메모리가 부족해져서 MySQL 서버가 메모리 부족을 겪을 수도 있기 때문에 소트 버퍼의 크기는 적절히 설정하는 것이 좋다.
정렬 알고리즘
레코드를 정렬할 때, 레코드 전체를 소트 버퍼에 담을지 또는 정렬 기준 칼럼만 소트 버퍼에 담을지에 따라 (공식적인 명칭은 아니지만) 2가지로 정렬 알고리즘으로 나눠볼 수 있다.
1.싱글 패스(Single pass) 알고리즘
소트 버퍼에 정렬 기준 칼럼을 포함해 SELECT되는 칼럼 전부를 담아서 정렬을 수행하는 방법이며, MySQL 5.0 이후 최근 버전에서 도입된 정렬 방법이다.
SELECT emp_no, first_name, last_name
FROM employees
ORDER BY first_name;위 쿼리와 같이 first_name으로 정렬해서 emp_no, first_name, last_name을 SELECT하는 쿼리를 싱글 패스 정렬 알고리즘으로 처리하는 절차를 그림으로 보면 다음과 같다.
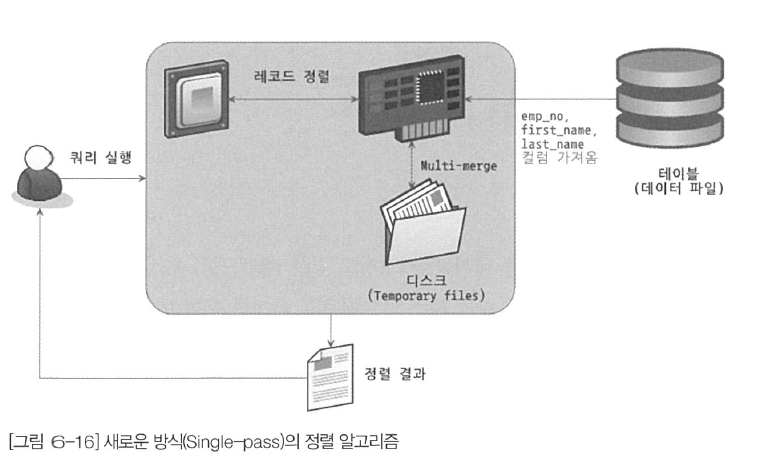
위의 그림에서 알 수 있듯이, 처음 employees 테이블을 읽을 때 정렬에 필요하지 않은 last_name 칼럼가지 전부 읽어서 소트 버퍼에 담고 정렬을 수행한다. 그리고 정렬이 완료되면 정렬 버퍼의 내용을 그대로 클라이언트로 넘겨주는 과정을 볼 수 있다.
2.투 패스(Two pass) 알고리즘
정렬 대상 칼럼과 프라이머리 키값만을 소트 버퍼에 담아서 정렬을 수행하고, 정렬된 순서대로 다시 프라이머리 키로 테이블을 읽어서 SELECT할 칼럼을 가져오는 알고리즘으로, 예전 버전의 MySQL에서 사용하던 방법이다. 하지만 MySQL 5.0 5.1 그리고 5.5 버전에서도, 특정 조건이 되면 이 방법을 사용한다.
아래 그림은 같은 쿼리를 MySQL의 예전 방식인 투 패스 알고리즘으로 정렬하는 과정을 표현하는 것이다. 처음 employees 테이블을 읽을 때는 정렬에 필요한 first_name 칼럼과 프라이머리 키인 emp_no만 읽어서 정렬을 수행했음을 알 수 있다. 이 정렬이 완료되면 그 결과 순서대로 employees 테이블을 한 번 더 읽어서 last_name을 가져오고, 최종적으로 그 결과를 클라이언트 쪽으로 넘기는 과정을 확인할 수 있다.
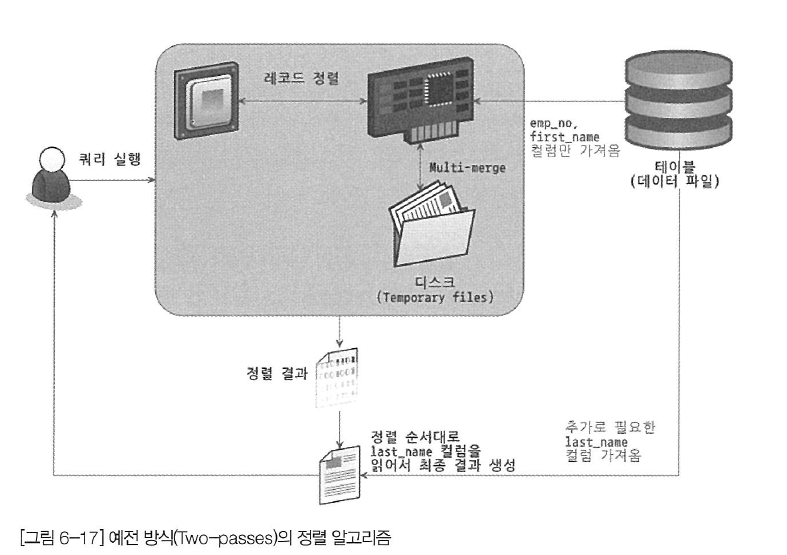
MySQL의 예전 정렬 방식인 투 패스 알고리즘은 테이블을 (그것도 같은 레코드를) 두 번 읽어야 하기 때문에 상당히 불합리하지만 새로운 정렬 방식인 싱글 패스 알고리즘은 이러한 불합리가 없다. 하지만 싱글 패스 알고리즘은 더 많은 소트 버퍼 공간이 필요하다. 즉 대략 128KB의 정렬 버퍼를 사용한다면 이 쿼리는 투 패스 알고리즘에서는 대략 7,000건의 레코드를 정렬할 수 있지만 싱글 패스 알고리즘에서는 그것의 반 정도밖에 정렬할 수 없다. 물론 이것은 소트 버퍼 공간의 크기와 레코드의 크기에 의존적이다.
최근의 MySQL 5.x 버전에서는 일반적으로 새로운 정렬 알고리즘인 싱글 패스 알고리즘인 싱글 패스 방식을 사용한다. 하지만 MySQL 5.x 버전 이상이라고 해서 항상 싱글 패스 알고리즘을 사용하는 것은 아니다. 다음과 같을 때 싱글 패스 방식을 사용하지 못하고 투 패스 정렬 알고리즘을 사용한다.
- 레코드의 크기가 max_length_for_sort_data 파라미터로 설정된 값보다 클 때
- BLOBL이나 TEXT 타입의 칼럼이 SELECT 대상에 포함할 때
얼핏 생각해 보면 예전 방식이 더 빠를 것도 같지만 항상 그런 것은 아니다. 싱글 패스 알고리즘(새로운 방식)은 정렬 대상 레코드의 크기나 건수가 작은 경우 빠른 성능을 보이며, 투 패스 알고리즘(예전 방식)은 정렬 대상 레코드의 크기나 건수가 상당히 많은 경우 효율적이라고 볼 수 있다.
SELECT 쿼리에서 꼭 필요한 칼럼만 조회하지 않고, 모든 칼럼(*)을 가져오도록 개발할 때가 많다. 하지만 이는 정렬 버퍼를 몇 배에서 몇 십배까지 비효율적으로 사용하게 만들 가능성이 크다. SELECT 쿼리에서 꼭 필요한 칼럼만 조회하도록 쿼리를 작성한는 것이 좋다고 권장하는 것은 바로 이런 이유 때문이다. 특히 정렬이 필요한 SELECT는 불필요한 칼럼을 SELECT하지 않도록 쿼리를 작성하는 것이 효율적이다. 이는 정렬 버퍼에만 영향을 미치는 것이 아니라 임시 테이블이 필요한 테이블에서도 영향을 미친다.
참고
- Real MySQL
