MySQL 실행 계획 : MySQL의 주요 처리 방식(4)
5. 임시 테이블(Using temporary)
MySQL 엔진이 스토리지 엔진으로부터 받아온 레코드를 정렬하거나 그룹핑할 때는 내부적인 임시 테이블을 사용한다. "내부적"이라는 단어가 포함된 것은 여기서 이야기하는 임시 테이블은 "CREATE TEMPORARY TABLE"로 만든 임시 테이블과는 다르기 때문이다. 일반적으로 MySQL 엔진이 사용하는 임시 테이블은 처음에는 메모리에 생성됐다가 테이블의 크기가 커지면 디스크로 옮겨진다. 물론 특정 예외 케이스에는 메모리를 거치지 않고 바로 디스크에 임시 테이블이 만들어지지도 않는다. 원본 테이블의 스토리지 엔진과 관계없이 임시 테이블이 메모리를 사용할 때는 MEMORY 스토리지 엔진을 사용하며, 디스크에 저장될 때는 MyISAM 스토리지 엔진을 이용한다.
MySQL 엔진이 내부적인 가공을 위해 생성하는 임시 테이블은 다른 세션이나 다른 쿼리에서는 볼 수 없으며 사용하는 것도 불가능하다. 사용자가 생성한 임시 테이블(CREATE TEMPORARY TABLE)과는 달리 내부적인 임시 테이블은 쿼리의 처리가 완료되면 자동으로 삭제된다.
임시 테이블이 필요한 쿼리
다음과 같은 패턴의 쿼리는 MySQL 엔진에서 별도의 데이터 가공 작업을 필요로 하므로 대표적으로 내부 임시 테이블을 생성하는 케이스다. 물론 이 밖에도 인덱스를 사용하지 못할 때는 내부 임시 테이블을 생성해야 할 때가 많다.
- ORDER BY와 GROUP BY에 명시된 칼럼이 다른 쿼리
- ORDER BY나 GROUP BY에 명시된 칼럼이 조인의 순서상 첫 번째 테이블이 아닌 쿼리
- DISTINCT와 ORDER BY가 동시에 쿼리에 존재하는 경우 DISTINCT가 인덱스로 처리되지 못하는 쿼리
- UNION이나 UNION DISTINCT가 사용된 쿼리(select_type 칼럼이 UNION RESULT인 경우)
- UNION ALL이 사용된 쿼리(select_type 칼럼이 UNION RESULT인 경우)
- 쿼리의 실행 계획에서 select_type이 DERIVED인 쿼리
어떤 쿼리의 실행 계획에서 임시 테이블을 사용하는지는 Extra 칼럼에 "Using temporary"라는 키워드가 표시되는지 확인하면 된다. 하지만 "Using temporary"가 표시되지 않을 때도 임시 테이블을 사용할 수 있는데, 위의 예에서 마지막 3개 패턴이 그런 예다. 첫 번째부터 네 번째까지의 쿼리 패턴은 유니크 인덱스를 가지는 내부 임시 테이블이 만들어진다. 그리고 다섯 번째와 여섯 번째 쿼리 패턴은 유니크 인덱스가 없는 내부 임시 테이블이 생성된다. 일반적으로 유니크 인덱스가 있는 내부 임시 테이블은 그렇지 않은 쿼리보다 상당히 처리 성능이 느리다.
임시 테이블이 디스크에 생성되는 경우(MyISAM 스토리지 엔진을 사용)
내부 임시 테이블은 기본적으로 메모리상에 만들어지지만 다음과 같은 조건을 만족하면 메모리에 임시 테이블을 생성할 수 없으므로 디스크상에 MyISAM 테이블로 만들어진다.
- 임시 테이블에 저장해야 하는 내용 중 BLOB(Binary Large Object)과 TEXT와 같은 대용량 칼럼이 있는 경우
- 임시 테이블에 저장해야 하는 레코드의 전체 크기나 UNION이나 UNION ALL에서 SELECT 되는 칼럼 중에서 길이가 512 바이트 이상인 크기의 칼럼이 있는 경우
- GROUP BY나 DISTINCT 칼럼에서 512바이트 이상인 크기의 칼럼이 있는 경우
- 임시 테이블에 저장할 데이터의 전체 크기(데이터의 바이트 크기)가 tmp_table_size 또는 max_heap_table_size 시스템 설정 값보다 큰 경우
첫 번째부터 세 번째까지는 처음부터 디스크에 MyISAM 스토리지 엔진을 사용해서 내부 임시 테이블이 만들어진다. 하지만 네 번째는 처음에는 MEMORY 스토리지 엔진을 이용해 메모리에 내부 임시 테이블이 생성되지만 테이블의 크기가 시스템 설정 값을 넘어서는 순간 디스크의 MyISAM 테이블로 변환된다.
임시 테이블 관련 상태 변수
실행 계획상에서 "Using temporary"가 표시되면 임시 테이블을 사용했다는 사실을 알 수 있다. 하지만 임시 테이블이 메모리에 처리됐는지 디스크에 처리됐는지를 알 수 없으며, 몇 개의 임시 테이블이 사용됐는지도 알 수 없다. "Using temporary"가 한번 표시됐다고 해서 임시 테이블을 하나만 사용했다는 것을 의미하지는 않는다. 임시 테이블이 디스크에 생성됐는지 메모리에 생성됐는지 파악하려면 MySQL 서버의 상태 변수(SHOW SESSION STATUS LIKE 'Created_tmp%';)를 확인해 보면 된다.
mysql > SHOW SESSION STATUS LIKE 'Created_tmp%';
+---------------------------+--------+
| Variable name | Value |
+---------------------------+--------+
| Created_tmp_disk_tables | 1 |
| Created_tmp_tables | 3 |
+---------------------------+--------+위의 내용을 보면 쿼리를 실행하기 전에 "SHOW SESSION STATUS LIKE 'Created_tmp%;' 명령으로 임시 테이블의 사용 현황을 먼저 확인해 둔다. 그리고 SELECT 쿼리를 실행한 후, 다시 상태 조회 명령을 실행해 보면 된다. 예제의 두 상태 변수가 누적하고 있는 값의 의미는 다음과 같다.
1.Created_tmp_tables
쿼리의 처리를 위해 만들어진 내부 임시 테이블의 개수를 누적하는 상태 값. 이 값은 내부 임시 테이블이 메모리에 만들어졌는지 디스크에 만들어졌는지를 구분하지 않고 모두 누적한다.
2.Created_tmp_disk_tables
디스크에 내부 임시 테이블이 만들어진 개수만 누적해서 가지고 있는 상태 값
이 예제에서 내부 임시 테이블의 사용 현황을 보자. 임시 테이블이 1개(3-2=1)가 생성됐는데, "Created_tmp_disk_tables" 상태 변수 값의 변화를 보면 해당 임시 테이블이 디스크에 만들어졌음을 알 수 있다.
임시 테이블 관련 주의사항
레코드 건수가 많지 않으면 내부 임시 테이블이 메모리에 생성되고 MySQL의 서버의 부하에 크게 영향을 미치지는 않는다. 성능상의 이슈에 될만한 부분은 내부 임시 테이블이 MyISAM 테이블로 디스크에 생성되는 경우다.
SELECT * FROM employees GROUP BY last_name ORDER BY first_name;이 쿼리는 GROUP BY와 ORDER BY 칼럼이 다르고, last_name 칼럼에 인덱스가 없기 때문에 임시 테이블과 정렬 작업까지 수행해야 하는 갖아 골칫거리가 되는 쿼리 형태다.
| id | select_type | table | type | key | key_len | ref | rows | Extra |
| 1 | SIMPLE | employees | ALL | 300584 | Using temporary; Using filesort |
Rows 칼럼의 값을 보면 이 쿼리는 대략 처리해야 하는 레코드 건수가 30만 건 정도라는 사실을 알 수 있다. 이 실행 계획의 내부적인 작업 과정을 살펴보면 다음과 같다.
- Employees 테이블의 모든 칼럼을 포함한 임시 테이블을 생성(MEMEORY 테이블)
- Employees 테이블로부터 첫 번째 레코드를 InnoDB 스토리지 엔진으로부터 가져와서
- 임시 테이블에 같은 last_name이 있는지 확인
- 같은 last_name이 없으면 임시 테이블에 INSERT
- 같은 last_name이 있으면 임시 테이블에 UPDATE 또는 무시
- 임시 테이블의 크기가 특정 크기보다 커지면 임시 테이블을 MyISAM 테이블로 디스크 이동
- Employees 테이블에서 더 읽을 레코드가 없을 때까지 2~6번 과정(이 쿼리에서는 30만 회 반복)
- 최종 내부 임시 테이블에 저장된 결과에 대해 정렬 작업을 수행
- 클라이언트에 결과 반환
SELECT 절에 포함된 칼럼의 특징에 따라 3번 ~ 5번 과정은 조금씩 차이가 있지만 임시 테이블이 일반적으로 이러한 과정을 거친다고 생각하면 될 듯하다. 여기서 중요한 것은 임시 테이블이 메모리에 있는 경우는 조금 다르겠지만 디스크에 임시 테이블이 저장된 경우라면 30만 건을 임시 테이블로 저장하려면 적지 않은 부하가 발생하리라는 것이다. 가능하다면 인덱스를 이용해 처리하고, 처음부터 임시 테이블이 필요하지 않게 만드는 것이 가장 좋다. 만약 이렇게 하기가 어렵다면 내부 임시 테이블이 메모리에만 저장될 수 있게 가공 대상 레코드를 적게 만드는 것이 좋다. 하지만 가공해야할 데이터를 줄일 수 없다고 해서 tmp_table_size 또는 max_heap_table_size 시스템 설정 변수를 무조건 크게 설정하면 MySQL 서버가 사용할 여유 메모리를 내부 임시 테이블이 모두 사용해버릴 수도 있으므로 주의해야 한다.
임시 테이블에 MEMORY(HEAP) 테이블로 물리 메모리에 생성되는 경우에도 주의해야 할 사항이 있다. MEMORY(HEAP) 테이블의 모든 칼럼은 고정 크기 칼럼이라는 점이다. 만약, 위의 예제 쿼리에서 first_name 칼럼이 VARCHAR(512)라고 가정해보자. 실제 메모리 테이블에서 first_name 칼럼이 차지하는 공간은 512 * 3(문자집합을 utf8로 가정) 바이트가 될 것이다. 실제 first_name 칼럼의 값이 1글자이든 2글자이든 관계없이, 테이블에 정의된 크기만큼 메모리 테이블에서 공간을 차지한다는 것이다. 이러한 임시 테이블의 저장 방식 때문에 SELECT하는 칼럼은 최소화하고(특히 불필요하고 BLOB 이나 TEXT 칼럼은 배제하는 것이 좋음), 칼럼의 데이터 타입 선정도 가능한 한 작게 해주는 것이 좋다.
6. 테이블 조인
MySQL은 다른 DBMS보다 조인을 처리하는 방식이 단순한다. 현재 릴리즈된 MySQL의 모든 버전에서 조인 방식은 네스트드-루프로 알려진 중첩된 루프와 같은 형태만 지원한다. 그리고 조인되는 각 테이블 간의 레코드를 어떻게 연결할지에 따라 여러 가지 종류의 조인으로 나뉜다.
조인의 종류
조인의 종류는 크게 INNER JOIN과 OUTER JOIN으로 구분할 수 있고, OUTER JOIN은 다시 LEFT OUTER JOIN과 RIGHT OUTER JOIN 그리고 FULL OUTER JOIN으로 구분할 수 있다. 그리고 조인의 조건을 어떻게 명시하느냐에 따라 NATURAL JOIN과 CROSS JOIN(FULL JOIN, CARTESIAN JOIN)으로도 구분할 수 있다.
조인의 처리에서 어느 테이블을 먼저 읽을지를 결정하는 것은 상당히 중요하며, 그에 따라 처리할 작업량이 상당히 달라진다. INNER JOIN은 어느 테이블을 먼저 읽어도 결과가 달라지지 않으므로 MySQL 옵티마이저가 조인의 순서를 조절해서 다양한 방법으로 최적화를 수행할 수도 있다. 하지만 OUTER JOIN은 반드시 OUTER가 되는 테이블을 먼저 읽어야 하기 때문에 조인 순서를 옵티마이저가 선택할 수 없다.
JOIN (INNER JOIN)
일반적으로 "조인"이라 함은 INNER JOIN을 지칭하는데, 별도로 아우터 조인과 구분할 때 "이너 조인(INNER JOIN)"이라고도 한다. MySQL에서 조인은 네스티드-루프 방식만 지원한다. 네스티드-루프란 일반적으로 프로그램을 작성할 때 두 개의 FOR나 WHILE과 같은 반복 루프 문장을 실행하는 형태로 조인이 처리되는 것을 의미한다.
FOR (record1 IN TABLE1) { // 외부 루프(OUTER)
FOR (record2 IN TABLE2){ // 내부 루프(INNER)
IF (record1.join_column == record2.join_column) {
join_record_found(record1.*, record2.*);
} else {
join_record_notfound();
}
}
} 위의 의사 코드에서 알 수 있듯이 조인은 2개 반복 루프로 두 개의 테이블을 조건에 맞게 연결해주는 작업이다(이 의사 코드의 FOR 반복문이 풀 테이블 스캔을 의미하는 것이 아니다). 두 개의 FOR 문장에서 바깥쪽을 아우터(OUTER) 테이블이라고 하며, 안쪽을 이너(INNER) 테이블이라고 표현한다. 또한 아우터 테이블은 이너 테이블보다 먼저 읽어야 하며, 조인에서 주도적인 역할을 한다고 해서 드라이빙(Driving) 테이블이라고도 한다. 이너 테이블은 조인에서 끌려가는 역할을 한다고 해서 드리븐(Driven) 테이블이라고도 한다.
중첩된 반복 루프에서 최종적으로 선택될 레코드가 안쪽 반복 루프 (INNER 테이블)에 의해 결정되는 경우를 INNER JOIN이라고도 한다. 즉, 두 개의 반복 루프를 실행하면서 TABLE2(INNER 테이블)에 "IF (record1.join_column == record2.join_column)" 조건을 만족하는 레코드만 조인의 결과로 가져온다.
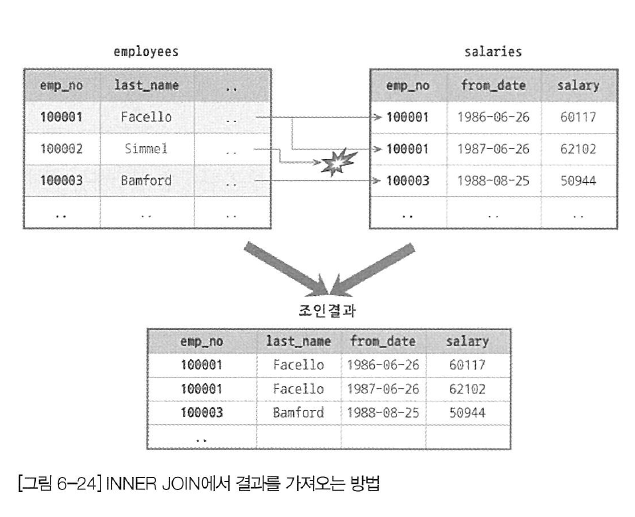
위의 그림에서는 employees 테이블이 드라이빙 테이블이며, salaries 테이블이 드리븐 테이블이 되어 INNER JOIN이 실행된 결과를 가져오는 과정을 보여준다. INNER JOIN을 실행하는 과정에서 emp_no가 100002인 레코드는 salaries 테이블에 존재하지 않는다는 것을 알게 되고, 이렇게 짝을 찾지 못하는 레코드는(드라이빙 테이블에만 존재하는 레코드) 조인 결과에 포함되지 않는다.
OUTER JOIN
INNER JOIN에서 살펴본 의사 코드를 조금만 수정해서 살펴보자.
FOR (record1 IN TABLE1) { // 외부 루프(OUTER)
FOR (record2 IN TABLE2) { // 내부 루프(INNER)
IF (record1.join_column == record2.join_column) {
join_record_found(record1.*, record2.*);
} else {
join_record_found(record1.*, NULL);
}
}
}위 코드에서 TABLE2에 일치하는 레코드가 있으면 INNER 조인과 같은 결과를 만들어내지만, TABLE2(INNER 테이블)에 조건을 만족하는 레코드가 없는 경우에는 TABLE2의 칼럼을 모두 NULL로 채워서 가져온다. 즉, INNER JOIN에서는 일치하는 레코드를 찾지 못했을 때는 TABLE1의 결과를 모두 버리지만 OUTER JOIN에서는 TABLE1의 결과를 버리지 않고 그대로 결과에 포함한다.
INNER 테이블이 조인의 결과에 전혀 영향을 미치지 않고, OUTER 테이블의 내용에 따라 조인의 결과가 결정되는 것이 OUTER JOIN의 특징이다. 물론 OUTER 테이블과 INNER 테이블의 관계(대표적으로 1:M 관계일 때)에 의해 최종 결과 레코드 건수가 늘어날 수는 있지만, OUTER 테이블의 레코드가 INNER 테이블에 일치하는 레코드가 없다고 해서 버려지지는 않는다. 아래 그림은 OUTER JOIN의 처리 방식을 묘사하고 있는데, 이 그림에서 emp_no가 100002번인 레코드는 salaries 테이블에서 일치하는 레코드를 찾지 못했다. 하지만 emp_no가 100002번인 레코드는 최종 아우터 조인의 결과에 포함된다. 물론 이때 salaries 테이블에는 일치하는 레코드가 없으므로 최종 결과의 salaries 테이블 칼럼은 NULL로 채워진다.
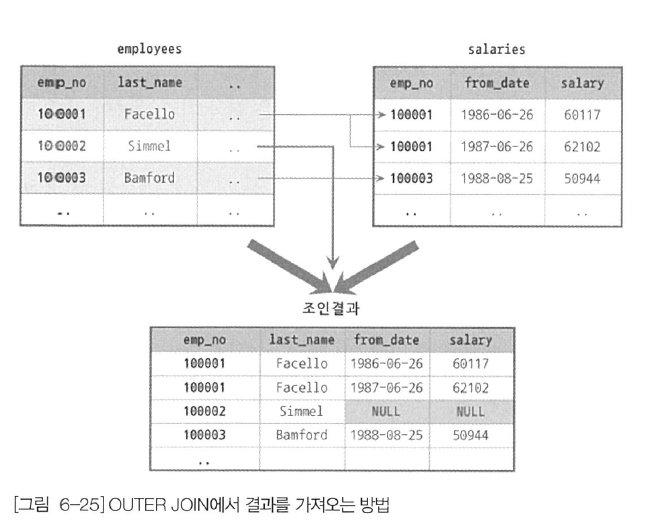
그리고 OUTER JOIN은 조인의 결과를 결정하는 아우터 테이블이 조인의 왼쪽에 있는지 오른쪽에 있는지에 따라 LEFT OUTER JOIN과 RIGHT OUTER JOIN, 그리고 FULL OUTER JOIN으로 다시 나뉜다.
SELECT *
FROM employees e
LEFT OUTER JOIN salaries s ON s.emp_no = e.emp_no;
SELECT *
FROM salaries s
RIGHT OUTER JOIN employees e ON e.emp_no = s.emp_no;위 예제에서 첫 번째 쿼리는 LEFT OUTER JOIN이며, 두 번째 쿼리는 RIGHT OUTER JOIN의 예제다. 두 쿼리의 차이점을 한번 비교해보자.
-
첫 번째 쿼리는 LEFT OUTER JOIN을 사용했는데, LEFT OUTER JOIN 키워드의 왼쪽에 employees 테이블이 사용됐고 오른쪽에 salaries 테이블에 사용됐기 때문에 employees가 아우터 테이블이 된다. 그래서 조인의 최종 결과는 salaries 테이블의 레코드 존재 여부에 관계없이 employees 테이블의 레코드에 의해 결정된다.
-
두 번째 쿼리는 RIGHT OUTER JOIN이 사용됐으며, RIGHT OUTER JOIN 키워드를 기준으로 오른쪽에 employees 테이블이 사용됐고 왼쪽에 salaries 테이블이 사용됐으므로 employees 테이블이 아우터 테이블이 된다. 그래서 두 번째 쿼리의 최종 결과도 salaries 테이블의 레코드 존재 여부에 관계없이 employees 테이블의 레코드에 의해 결정된다.
예제의 두 쿼리는 각각 LEFT OUTER JOIN과 RIGHT OUTER JOIN을 사용했지만 결국은 같은 처리 결과를 만들어내는 쿼리다. LEFT OUTER JOIN과 RIGHT OUTER JOIN은 결국 처리 내용이 같으므로 혼동을 막기 위해 LEFT OUTER JOIN으로 통일해서 사용하는 것이 일반적이다.
JOIN 키워드를 기준으로 왼쪽의 테이블도 OUTER JOIN을 하고 싶고, 오른쪽의 테이블도 OUTER JOIN을 하고 싶은 경우 사용하는 쿼리가 FULL OUTER JOIN인데, MysQL에서는 FULL OUTER JOIN을 지원하지 않는다. 하지만 INNER JOIN과 OUTER JOIN을 조금만 섞어서 활용하면 FULL OUTER JOIN과 같은 기능을 수행하도록 쿼리를 작성할 수 있다.
LEFT OUTER JOIN에서는 쉽게 실수 할 수 있는 부분이 여러 가지 있다. 이제 LEFT OUTER JOIN을 사용할 때 어떤 부분에 주의해야 하고, 그런 실수를 막기 위해 어떻게 해야 할지 조금 더 자세히 살펴보겠다.
MySQL의 실행 계획은 INNER JOIN을 사용했는지 OUTER JOIN을 사용했는지 알려주지 않으므로 OUTER JOIN을 의도한 쿼리가 INNER JOIN으로 실행되지는 않는지 주의해야 한다. 이 부분도 실수하기 쉬운 부분인데, OUTER JOIN에서 레코드가 없을 수도 있는 쪽의 테이블에 대한 조건은 반드시 LEFT JOIN의 ON 절에 모두 명시하자. 그렇지 않으면 옵티마이저는 OUTER JOIN을 내부적으로 INNER JOIN으로 변형시켜 처리해 버릴 수도 있다. LEFT OUTER JOIN의 ON 절에 명시되는 조건은 조인되는 레코드가 있을 때만 적용된다. 하지만 WHERE 절에 명시되는 조건은 OUTER JOIN이나 INNER JOIN에 관계없이 조인된 결과에 대해 모두 적용된다. 그래서 OUTER JOIN으로 연결되는 테이블이 있는 쿼리에서는 가능하다면 모든 조건을 ON 절에 명시하는 습관을 들이는 것이 좋다.
SELECT *
FROM employees e
LEFT OUTER JOIN salariers s ON s.emp_no=e.emp_no
WHERE s.salary > 5000;위 쿼리의 LEFT OUTER JOIN 결과 WHERE 절은 서로 충돌되는 방식으로 사용된 것이다. OUTER JOIN으로 연결되는 테이블의 칼럼에 대한 조건이 ON 절에 명시되지 않고 WHERE 절에 명시됐기 때문이다. 그래서 MySQL 서버는 이 쿼리를 최적화 단계에서 다음과 같은 쿼리로 변경한 후 실행한다. MySQL 옵티마이저가 쿼리를 변경해버리면 원래 쿼리를 작성했던 사용자의 의도와는 다른 결과를 반환받는다.
SELECT *
FROM employees e
INNER JOIN salaries s ON s.emp_no=e.emp_no
WHERE s.salary > 5000;이런 형태의 쿼리는 다음 2가지 중의 한 방식으로 수정해야 쿼리 자체의 의도나 결과를 명확히 할 수 있다.
-- // 순수하게 OUTER JOIN으로 표현한 쿼리
SELECT *
FROM employees e
LEFT OUTER JOIN salaries s ON s.emp_no=e.emp_no AND s.salary > 5000;
-- // 순수하게 INNER JOIN으로 표현한 쿼리
SELECT *
FROM employees e
INNER JOIN salaries s ON s.emp_no=e.emp_no
WHERE s.salary > 5000;LEFT OUTER JOIN이 아닌 쿼리에서는 검색 조건이나 조인 조건을 WHERE 절이나 ON 절 중에서 어느 곳에 명시해도 성능상의 문제나 결과의 차이가 나지 않는다.
오라클과 같은 DBMS에서는 OUTER JOIN 테이블에 대한 조건이라는 표기로 "(+)" 기호를 칼럼 뒤에 사용할 수도 있다. 하지만 MySQL은 이러한 형태의 표기법을 허용하지 않고 LEFT JOIN 또는 LEFT OUTER JOIN 절을 이용하는 SQL 표준 문법만을 지원한다.
참고
- Real MySQL
