파티션이란 MySQL 서버의 입장에서는 데이터를 별도의 테이블로 분리해서 저장하지만 사용자 입장에서는 여전히 하나의 테이블로 읽기와 쓰기를 할 수 있게 해주는 솔루션이다. 일반적으로 DBMS의 파티션은 하나의 서버에서 테이블을 분산하는 것이며, 원격 서버 간에 분산을 지원하는 것은 아니다. MySQL 5.1부터 제공되는 파티션 기능은 MyISAM과 InnoDB 테이블 등 대부분의 스토리지 엔진에서 사용할 수 있다. 기본적으로 해시와 리스트, 그리고 키와 레인지로 4가지 파티션 방법을 제공하고 있으므로, 서브 파티셔닝 기능까지 사용할 수 있다.
파티션 : 개요
MySQL 파티션이 적용된 테이블에서 INSERT나 SELECT 등과 같은 쿼리가 어떻게 실행되는지 이해한다면 파티션을 어떻게 사용하는 것이 가장 최적일지 쉽게 익힐 수 있을 것이다. 이번 장에서는 파티션이 SQL 문장의 수행에 어떻게 영향을 미치는지, 그리고 파티션으로 기대할 수 있는 장점으로 무엇이 있는지 살펴보겠다.
1. 파티션을 사용하는 이유
테이블의 데이터가 많아진다고 해서 무조건 파티션을 적용하는 것이 효율적인 것은 아니다. 하나의 테이블이 너무 커서 인덱스의 크기가 물리적인 메모리보다 훨씬 크거나, 데이터 특성상 주기적인 삭제 작업이 필요한 경우 파티션이 필요한 대표적인 예라고 할 수 있다. 각각의 예에 대해 지금부터 하나씩 자세히 살펴보겠다.
단일 INSERT나 단일 또는 범위 SELECT의 빠른 처리
데이터베이스에서 인덱스는 일반적으로 SELECT를 위한 것으로 보이지만 UPDATE나 DELETE, 그리고 INSERT 쿼리를 위해 필요한 때도 많다. 물론 레코드를 변경하는 쿼리를 실행하면 인덱스의 변경을 위한 부가적인 작업이 발생하긴 하지만 UPDATE나 DELETE 처리를 위해 대상 레코드를 검색하려면 인덱스가 필수적이다. 하지만 이 인덱스가 커지면 커질수록 SELECT는 말할 것도 없고, INSERT나 UPDATE, 그리고 DELETE 작업도 당연히 느려진다는 점이 문제다.
특히 한 테이블의 인덱스 크기가 물리적으로 MySQL이 사용 가능한 메모리 공간보다 크다면 그 영향은 더 심각할 것이다. 테이블의 데이터는 실질적인 물리 메모리보다 큰 것이 일반적이겠지만 인덱스의 워킹 셋(Working set)이 실질적인 물리 메모리보다 크다면 쿼리 처리가 상당히 느려질 것이다. 아래 그림은 큰 테이블을 파티셔닝하지 않고 그냥 사용할 때와 작은 파티션으로 나눠서 워킹 셋의 크기를 줄였을 때 인덱스의 워킹 셋이 물리적인 메모리를 어떻게 사용하는지를 보여준다. 파티셔닝하지 않고 하나의 큰 테이블로 사용하면 인덱스도 커지고 그만큼 물리적인 메모리 공간도 많이 필요해진다는 사실을 알 수 있다. 결과적으로 파티션은 데이터와 인덱스를 조각화해서 물리적 메모리를 효율적으로 사용할 수 있게 만들어준다.
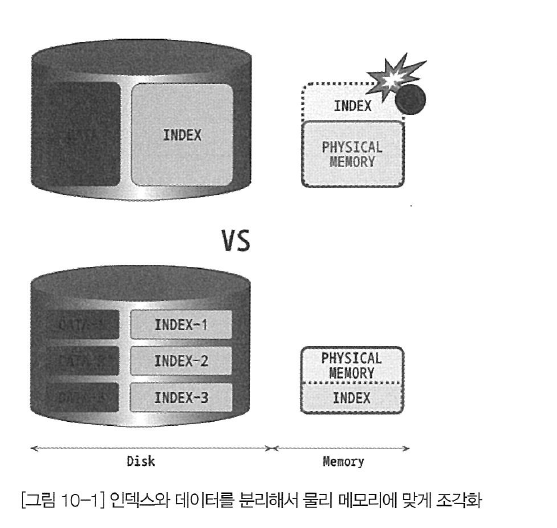
테이블의 데이터가 10GB이고 인덱스가 3GB라고 가정해보자. 하지만 대부분의 테이블은 13GB 전체를 항상 사용하는 것이 아니라 그중에서 활발하게 사용하는 부분을 주로 다시 사용한다. 즉, 회원이 100만 명이라 하더라도 그중에서 활발하게 사용하는 회원은 2~30% 수준이라는 것이다. 거의 대부분의 테이블 데이터가 이런 형태로 사용된다고 볼 수 있는데, 활발하게 사용되는 데이터를 워킹 셋이라고 표현한다. 테이블의 데이터를 워킹 셋과 그렇지 않은 부류로 파티셔닝 할 수 있다면 상당히 효과적으로 성능을 개선할 수 있을 것이다.
데이터의 물리적인 저장소를 분리
데이터 파일이나 인덱스 파일이 파일 시스템에서 차지하는 공간이 크다면 그만큼 백업이나 관리 작업이 어려워진다. 더욱이 테이블의 데이터나 인덱스를 파일 단위로 관리하고 있는 MySQL에서 더 치명적인 문제가 될 수도 있다. 이러한 문제는 파티션을 통해 파일의 크기를 조절하거나 각 파티션별 파일들이 저장될 위치나 디스크를 구분해서 지정해서 해결하는 것도 가능하다. 하지만 MySQL에서는 테이블의 파티션 단위로 인덱스를 순차적으로 생성하는 방법은 아직 허용되지 않는다.
이력 데이터의 효율적인 관리
요즘은 거의 모든 애플리케이션이 로그라는 이력 데이터를 가지고 있는데, 이는 단기간에 대량으로 누적됨과 동시에 일정 기간이 지나면 쓸모가 없어진다. 로그 데이터는 결국 시간이 지나면 별도로 아카이빙하거나 백업한 후 삭제해버리는 것이 일반적이며, 특히 다른 데이터에 비해 라이프 사이클이 상당히 짧은 것이 특징이다. 로그 테이블에서 불필요해진 데이터를 백업하거나 삭제하는 작업은 일반 테이블에서는 상당히 고부하의 작업에 속한다. 하지만 로그 테이블을 파티션 테이블로 관리한다면 불필요한 데이터 삭제 작업은 단순히 파티션을 추가하거나 삭제하는 방식으로 간단하고 빠르게 해결할 수 있다.
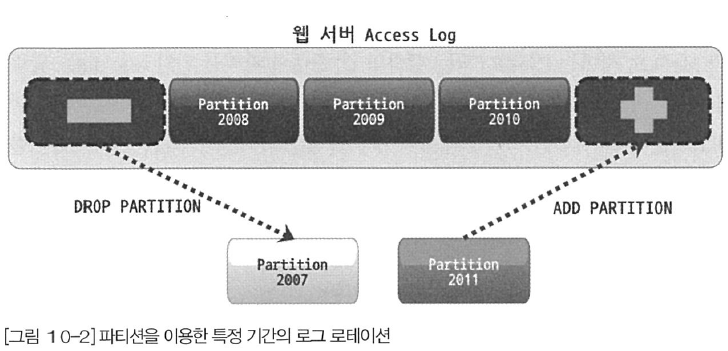
대량의 데이터가 저장된 로그 테이블을 기간 단위로 삭제한다면 MySQL 서버에 전체적으로 미치는 부하뿐 아니라 로그 테이블 자체의 동시성에도 영향을 미칠 수 있다. 하지만 파티션을 이용하면 이러한 문제를 대폭 줄일 수 있다.
2. MySQL 파티션의 내부 처리
파티션이 적용된 테이블에서 레코드의 INSERT 처리와 UPDATE, 그리고 SELECT가 어떻게 처리되는지 확인해보기 위해 다음과 같은 간단한 테이블을 가정해 보자.
CREATE TABLE tb_article (
article_id INT NOT NULL,
reg_date DATETIME NOT NULL,
..
PRIMARY KEY(article_id)
)
PARTITION BY RANGE (YEAR(reg_date)) (
PARTITION p2009 VALUES LESS THAN (2010),
PARTITION p2011 VALUES LESS THAN (2012)
PARTITION p9999 VALUES LESS THAN MAXVALUE
);여기서 게시물의 등록 일자(reg_date)에서 연도 부분은 파티션 키로서 해당 레코드가 어느 파티션에 저장될지를 결정하는 중요한 역할을 담당한다. 이제 tb_article 테이블에 대해 INSERT와 UPDATE, 그리고 SELECT와 같은 쿼리 등이 어떻게 처리되는지 하나씩 살펴보자.
파티션 테이블의 레코드 INSERT
INSERT 쿼리가 실행되면 MySQL 서버는 INSERT되는 칼럼의 값 중에서 파티션 키인 reg_date 칼럼의 값을 이용해 파티션 표현식을 평가하고, 그 결과를 이용해 레코드가 저장될 적절한 파티션을 결정한다. 새로 INSERT되는 레코드를 위한 파티션이 결정되면 나머지 과정은 파티션되지 않은 일반 테이블과 마찬가지로 처리한다. 아래 그림은 파티션 키를 이용해 레코드를 저장할 파티션을 결정하는 과정을 보여준다.
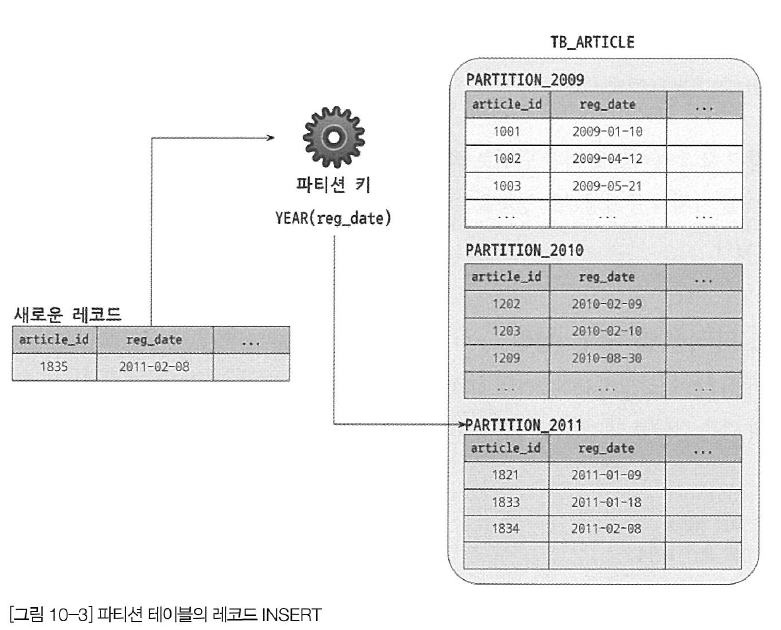
파티션 테이블의 UPDATE
UPDATE 쿼리를 실행하려면 변경 대상 레코드가 어느 파티션에 저장돼 있는지 찾아야 한다. 이때 UPDATE 쿼리의 WHERE 조건에 파티션 키 칼럼이 조건으로 존재한다면 그 값을 이용해 레코드가 저장된 파티션에서 빠르게 대상 레코드를 검색할 수 있다. 하지만 WHERE 조건에 파티션 키 칼럼의 조건이 명시되지 않았다면 MySQL 서버는 변경 대상 레코드를 찾기 위해 테이블의 모든 파티션을 검색해야 한다. 그리고 실제 레코드의 칼럼을 변경하는 작업의 절차는 UPDATE 쿼리가 어떤 칼럼의 값을 변경하는지에 따라 큰 차이가 생긴다.
- 파티션 키 이외의 칼럼만 변경될 때는 파티션이 적용되지 않은 일반 테이블과 마찬가지로 칼럼 값만 변경한다.
- 파티션 키 칼럼이 변경될 때는 아래 그림의 1번 단계와 같이 기존의 레코드가 저장된 파티션에서 해당 레코드를 삭제한다. 그리고 변경되는 파티션 키 칼럼의 표현식을 평가하고, 그 결과를 이용해 레코드를 이용시킬 새로운 파티션을 결정해서 레코드를 저장한다.
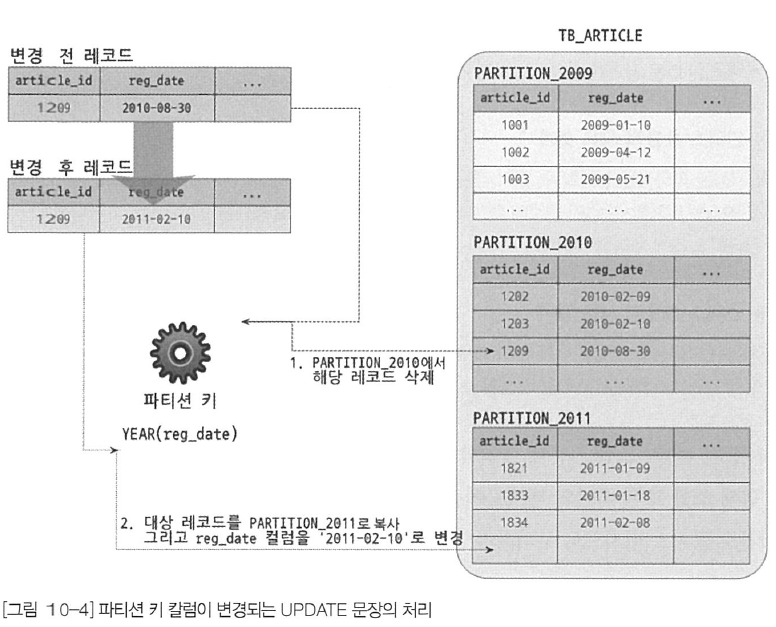
파티션 테이블의 검색
SQL이 수행되기 위해 파티션 테이블을 검색할 때 성능에 크게 영향을 미치는 조건은 다음과 같다.
- WHERE 절의 조건으로 검색해야 할 파티션을 선택할 수 있는가?
- WHERE 절의 조건이 인덱스를 효율적으로 사용(인데스 레인지 스캔)할 수 있는가?
두 번째 내용은 파티션 테이블뿐 아니라 파티션되지 않은 일반 테이블의 검색 성능에도 똑같이 영향을 미치는 것이다. 하지만 파티션 테이블에서는 첫 번째 선택사항의 결과에 의해 두 번째 선택사항의 작업 내용이 달라질 수 있다. 위의 두 가지 주요 선택사항의 각 조합이 어떻게 실행되는지 한번 살펴보자.
1.파티션 선택 가능 + 인덱스 효율적 사용 가능
두 선택사항이 모두 사용 가능할 때 쿼리가 가장 효율적으로 처리될 수 있다. 이때는 파티션의 개수에 관계없이 검색을 위해 꼭 필요한 파티션의 인덱스만 레인지 스캔한다.
2.파티션 선택 불가 + 인덱스 효율적 사용 가능
WHERE 조건에 일치하는 레코드가 저장된 파티션을 걸러낼 수 없기 때문에 우선 테이블의 모든 파티션을 대상으로 검색해야 한다. 하지만 각 파티션에 대해서는 인덱스 레인지 스캔을 사용할 수 있기 때문에 최종적으로 테이블에 존재하는 모든 파티션의 개수만큼 인덱스 레인지 스캔을 수행해서 검색하게 된다. 이 작업은 파티션 개수만큼의 테이블에 대해 인덱스 레인지 스캔을 한 다음 결과를 병합해서 가져오는 것과 같다.
3.파티션 선택 가능 + 인덱스 효율적 사용 불가
검색하려는 레코드가 저장된 파티션을 선별할 수 있기 때문에 파티션 개수에 관계없이 검색을 위해 필요한 파티션만 읽으면 된다. 하지만 인덱스는 이용할 수 없기 때문에 대상 파티션에 대해 풀 테이블 스캔을 한다. 이는 각 파티션의 레코드 건수가 많다면 상당히 느리게 처리될 것이다.
4.파티션 선택 불가 + 인덱스 효율적 사용 불가
WHERE 조건에 일치하는 파티션을 선택할 수가 없기 때문에 테이블의 모든 파티션을 검색해야 한다. 하지만 각 파티션을 검색하는 작업 자체도 인덱스 레인지 스캔을 사용할 수 없기 때문에 풀 테이블 스캔을 수행해야 한다.
위에서 살펴본 선택사항의 4가지 조합 가운데 마지막 세 번째와 네 번째 방식은 가능하다면 피하는 것이 좋다. 그리고 두 번째 조합 또한 하나의 테이블에 파티션의 개수가 많을 때는 MySQL 서버의 부하도 높아지고 처리 시간도 많이 느려지므로 주의하자.
파티션 테이블의 인덱스 스캔과 정렬
MySQL의 파티션 테이블에서 인덱스는 전부 로컬 인덱스에 해당한다. 즉, 아래 그림과 같이 모든 인덱스는 파티션 단위로 생성되며, 파티션에 관계없이 테이블 전체 단위로 글로벌하게 하나의 통합된 인덱스는 지원하지 않는다는 것을 의미한다.
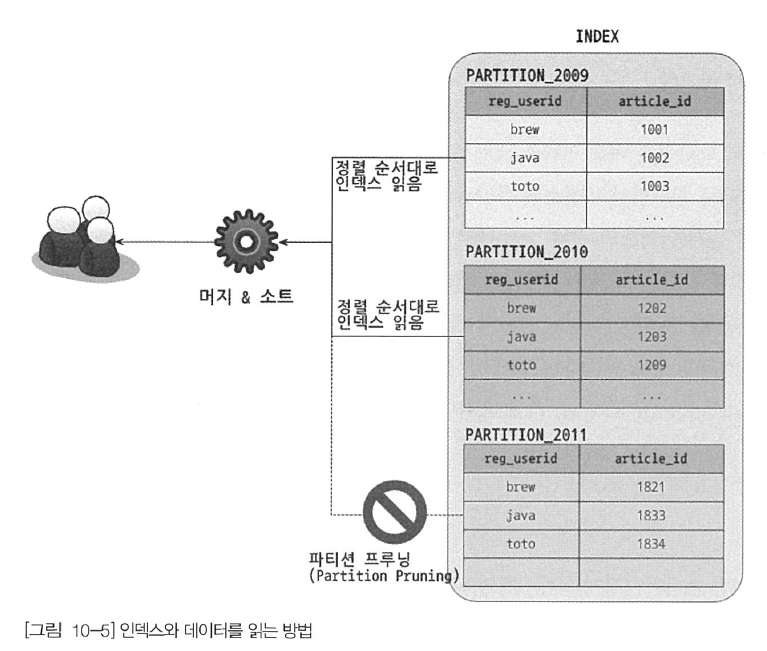
이 그림은 tb_article 테이블의 reg_userid 칼럼으로 만들어진 인덱스가 어떻게 구성되고 인덱스도 tb_article 테이블과 같이 연도별로 파티션되어 저장된다는 것을 보여준다.
이 그림에서 reg_userid 칼럼의 값은 파티션의 순서대로 정렬돼 있지 않다는 사실을 알 수 있다. 즉, 파티션되지 않은 테이블에서 인덱스를 순서대로 읽으면 그 칼럼으로 정렬된 결과를 바로 얻을 수 있지만 파티션된 테이블에서는 그렇지 않다는 것이다. 그렇다면 인덱스 레인지 스캔을 수행하는 쿼리가 여러 개의 파티션을 읽어야 할 때 그 결과는 인덱스 칼럼으로 정렬이 될지 다음 예제 쿼리로 한번 살펴보자.
SELECT * FROM tb_article
WHERE reg_userid BETWEEN 'brew' AND 'toto'
ORDER BY reg_userid;위 쿼리의 실행 계획을 확인해보면 Extra 칼럼에 별도의 정렬 작업을 의미하는 "Using filesort" 코멘트가 표시되지 않는다는 것을 알 수 있다. 간단히 생각해 보면 PARTITION_2009와 PARTITION_2010으로부터 WHERE 조건에 일치하는 레코드를 가져온 후, 각 파티션의 결과를 병합하고 reg_userid 칼럼의 값으로 다시 한번 정렬해야 될 것처럼 보인다. 하지만 쿼리의 실행 계획에는 별도의 정렬을 수행했다는 메시지는 표시되지 않는다.
실제 MySQL 서버는 여러 파티션에 대해 인덱스 스캔을 수행할 때, 각 파티션으로부터 조건에 일치하는 레코드를 정렬된 순서대로 읽으면서 우선순위 큐(Priority Queue)에 임시로 저장한다. 그리고 우선순위 큐에서 다시 필요한 순서(인덱스의 정렬 순서)대로 데이터를 가져가는 것이다. 이는 각 파티션에서 읽은 데이터가 이미 정렬돼 있는 상태라서 가능한 방법이다. 결론적으로 파티션 테이블에서 인덱스 스캔을 통해 레코드를 읽을 때 MySQL 서버가 별도의 정렬 작업을 수행하지는 않는다. 하지만 일반 테이블의 인덱스 스캔처럼 결과를 바로 반환하는 것이 아니라 내부적으로 큐 처리가 한번 필요한 것이다. 위의 그림에서 "머지 & 소트(Merge & Sort)"라고 표시한 부분이 바로 우선 순위 큐 처리 작업을 의미한다.
파티션 프루닝
위의 그림에서 보는 것처럼 옵티마이저에 의해 3개의 파티션 가운데 2개만 읽어도 된다고 판단되면 불필요한 파티션에는 전혀 접근하지 않는다. 이렇게 최적화 단계에서 필요한 파티션만 골라내고 불필요한 것들은 실행 계획에서 배제하는 것을 파티션 프루닝(Partition pruning)이라고 한다. 이러한 파티션 프루닝 정보는 실행 계획을 확인해보면 옵티마이저가 어떤 파티션만 접근하는지 알 수 있다. 파티션 프루닝에 관련된 실행 계획을 확인할 때는 "EXPLAIN PARTITIONS" 명령을 사용해야 한다.
참고
- Real MySQL
