파티션 : MySQL 파티션의 종류(2)
3. 해시 파티션
해시 파티션은 MySQL에서 정의한 해시 함수에 의해 레코드가 저장될 파티션을 결정하는 방법이다. MySQL에서 정의한 해시 함수는 복잡한 알고리즘이 아니라 파티션 표현식의 결과 값을 파티션의 개수로 나눈 나머지로 저장될 파티션을 결정하는 방식이다. 해시 파티션의 파티션 키는 항상 정수 타입의 칼럼이거나 정수를 반환하는 표현식만 사용될 수 있다. 해시 파티션에서 파티션의 개수를 레코드를 각 파티션에 할당하는 알고리즘과 연관되기 때문에 파티션을 추가하거나 삭제하는 작업에는 테이블 전체적으로 레코드를 재분배하는 작업이 따른다.
해시 파티션의 용도
해시 파티션은 다음과 같은 특성을 지닌 테이블에 적합하다.
- 레인지 파티션이나 리스트 파티션으로 데이터를 균등하게 나누는 것이 어려울 때
- 테이블의 모든 레코드가 비슷한 사용 빈도를 보이지만 테이블이 너무 커서 파티션을 적용해야 할 때
해시 파티션이나 이어서 설명할 키 파티션의 대표적인 용도로는 회원 테이블을 들 수 있다. 회원 정보는 가입 일자가 오래되서 사용하지 않는다거나 최선이어서 더 빈번하게 사용되거나 하지 않는다. 또한 회원의 지역이나 취미와 같은 정보 또한 사용 빈도에 미치는 영향이 거의 없다. 이처럼 테이블의 데이터가 특정 칼럼의 값에 영향을 받지 않고, 전체적으로 비슷한 사용 빈도를 보일 때 적합한 파티션 방법이다.
해시 파티션 테이블 생성
-- // 파티션의 개수만 지정할 때
CREATE TABLE employees (
id INT NOT NULL,
first_name VARCHAR(30),
last_name VARCHAR(30),
hired DATE NOT NULL DEFAULT '1920-01-01';
...
) ENGINE=INNODB
PARTITION BY HASH(id)
PARTITIONS 4
-- // 파티션의 이름을 별도로 지정하고자 할 때
CREATE TABLE employees (
id INT NOT NULL,
first_name VARCHAR(30),
last_name VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
..
) ENGINE=INNODB
PARTITION BY HASH(id)
PARTITION 4 (
PARTITION p0 ENGINE=INNODB,
PARTITION p1 ENGINE=INNODB,
PARTITION p2 ENGINE=INNODB,
PARTITION p3 ENGINE=INNODB
);해시 파티션으로 테이블을 생성하는 위의 예제를 간단히 살펴보자.
- PARTITION BY HASH 키워드로 파티션 종류를 해시 파티션으로 지정한다.
- PARTITION BY HASH 키워드 뒤에 파티션 키를 명시한다. 해시 파티션의 파티션 키는 MySQL 서버 5.1 그리고 5.5 모두 정수 타입의 칼럼이나 표현식만 사용할 수 있다.
- PARTITIONS n으로 몇 개의 파티션을 생성할 것인지 명시한다. 어떤 DBMS에서는 해시 파티션의 개수가 2n이어야 한다는 제약이 있지만, MySQL의 해시 파티션에는 그런 제약이 없으며 파티션의 개수가 1024보다 작은 값이면 된다.
- 파티션의 개수뿐 아니라 각 파티션의 이름을 명시하려면 두 번째 CREATE TABLE 명령과 같이 각 파티션을 나열하면 된다. 하지만 해시나 키 파티션에서는 특정 파티션을 삭제하거나 병합하는 작업이 거의 불필요하므로 파티션의 이름을 부여하는 것이 크게 의미는 없다. 만약 파티션의 개수만 지정하면 각 파티션의 이름은 기본적으로 "p0, 01, p2, p3, ...'과 같은 규칙으로 생성된다.
해시 파티션의 분리와 병합
해시 파티션의 분리와 병합은 리스트 파티션이나 레인지 파티션과는 달리, 대상 테이블의 모든 파티션에 저장된 레코드를 재분배하는 작업이 필요하다. 파티션의 분리나 병합으로 인해 파티션의 개수가 변경된다는 것은 해시 함수의 알고리즘을 변경하는 것이므로 전체적인 파티션이 영향을 받는 것은 피할 수 없다.
1.해시 파티션 추가
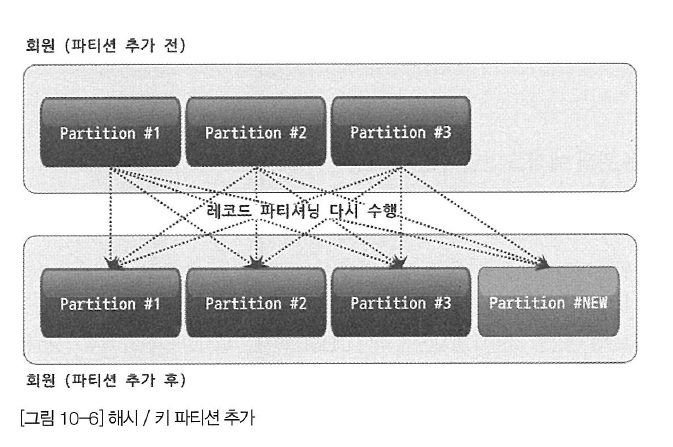
해시 파티션은 특정 파티션 키 값을 테이블의 파티션 개수로 MOD 연산한 결과 값에 의해 각 레코드가 저장될 파티션을 결정한다. 즉, 해시 파티션은 테이블에 존재하는 파티션의 개수에 의해 파티션 알고리즘이 변하는 것이다. 따라서 새로이 파티션이 추가된다면 기존의 각 파티션에 저장된 모든 레코드가 재배치돼야 한다. 다음 예제와 같이 해시 파티션을 새로 추가할 때는 별도의 영역이나 범위는 명시하지 않고 몇 개의 파티션을 더 추가할지만 지정하면 된다.
-- // 파티션 1개만 추가하면서 파티션 이름을 부여하는 경우
ALTER TABLE employees AND PARTITION(PARTITION p5 ENGINE=INNODB);
-- // 동시에 6개의 파티션을 별도의 이름 없이 추가하는 경우
ALTER TABLE clients ADD PARTITION PARTITIONS 6;실제로 해시 파티션이 사용되는 테이블에 새로운 파티션을 추가하면 아래 그림과 같이 기존의 모든 파티션에 저장돼 있던 레코드를 새로운 파티션으로 재분배하는 작업이 발생한다. 즉, 해시 파티션에서 파티션을 추가하거나 생성하는 작업은 많은 부하를 발생시킨다.
2.해시 파티션 삭제
해시나 키 파티션은 파티션 단위로 레코드를 삭제하는 방법이 없다. 해시나 키 파티션을 사용하는 테이블에서 특정 파티션을 삭제하려고 하면 다음과 같은 에러 메시지가 발생하면서 종료할 것이다.
ALTER TABLE employees DROP PARTITION p0;
Error Code : 1512
DROP PARTITION can only be used on RANGE/LIST partitionsMySQL 서버가 지정한 파티션 키 값을 가공해서 데이터를 각 파티션으로 분산한 것이므로 각 파티션에 저장된 레코드가 어떤 부류의 데이터인지 사용자가 예측할 수가 없다. 결국 해시 파티션이나 키 파티션을 사용한 테이블에서 파티션 단위로 데이터를 삭제하는 작업은 의미도 없으며 해서도 안 될 작업이다.
3.해시 파티션 분할
해시 파티션이나 키 파티션에서 특정 파티션을 두 개 이상의 파티션으로 분할하는 기능은 없으며, 테이블 전체적으로 파티션의 개수를 늘리는 것만 가능하다.
4.해시 파티션 병합
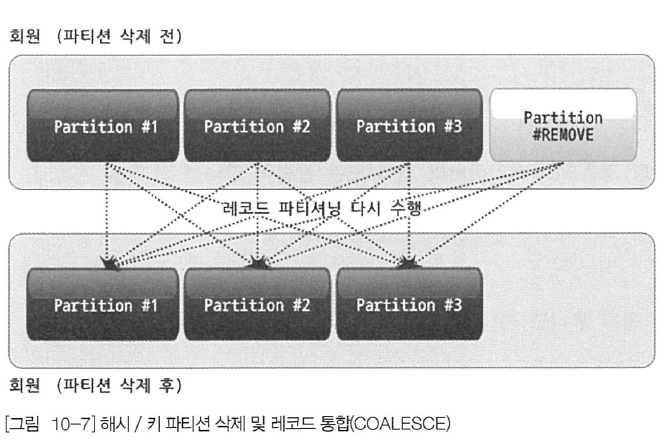
해시나 키 파티션은 2개 이상의 파티션을 하나의 파티션으로 통합하는 기능을 제공하지 않는다. 단지 파티션의 개수를 줄이는 것만 가능하다. 파티션의 개수를 줄일 때는 COALESCE PARTITION 명령을 사용하면 된다. 명령어 자체로만 보면 파티션을 통합하는 것처럼 보이지만 원래 파티션 4개로 구성된 테이블에 다음 명령이 실행되면 3개의 파티션을 가진 테이블로 다시 재구성하는 작업이 수행된다.
ALTER TABLE employees COALESCE PARTITION 1;COALESCE PARTITION 뒤에 명시한 숫자 값은 줄이고자 하는 파티션의 개수를 의미한다. 즉, 원래 employees 테이블이 4개의 파티션으로 구성돼 있었다면 COALESCE PARTITION 명령은 이 테이블이 파티션 3개만 사용하도록 변경할 것이다. 하지만 삭제되는 파티션에 저장돼 있던 레코드가 남은 3개의 파티션으로 복사되는 것이 아니라 테이블의 모든 레코드가 재배치되는 작업이 수행돼야 한다.
해시 파티션 주의사항
- 특정 파티션만 DROP하는 것이 불가능하다.
- 새로운 파티션을 추가하는 작업은 단순히 파티션만 추가하는 것이 아니라 기존의 모든 데이터의 재배치 작업이 필요하다.
- 해시 파티션은 레인지 파티션이나 리스트 파티션과는 상당히 다른 방식으로 관리하기 때문에 해시 파티션이 용도에 적합한 해결책인지 확인이 필요하다.
- 일반적으로 사용자들에게 익숙한 파티션의 조작이나 특성은 대부분 리스트 파티션이나 레인지 파티션에 제한적인 것들이 많다. 해시 파티션이나 키 파티션을 사용하거나 조작할 때는 주의가 필요하다.
4. 키 파티션
키 파티션은 해시 파티션과 사용법과 특성이 거의 같다. 해시 파티션은 해시 값을 계산하는 방법을 파티션 키나 표현식에 사용자가 명시한다. 물론, MySQL 서버가 그 값을 다시 MOD 연산을 수행해서 최종 파티션을 결정하기는 하지만 말이다. 하지만 키 파티션에서는 해시 값의 계산도 MySQL 서버가 수행한다. 키 파티션에서는 정수 타입이나 정수 값을 반환하는 표현식뿐 아니라 거의 대부분의 데이터 타입에 대해 파티션 키를 적용할 수 있다. MySQL 서버는 선정된 파티션 키의 값을 MD5() 함수를 이용해 해시 값을 계산하고, 그 값을 MOD 연산해서 데이터를 각 파티션에 분배한다. 이것이 키 파티션과 해시 파티션의 유일한 차이점이다.
키 파티션의 생성
-- // 프라이머리 키가 있는 경우 자동으로 프라이머리 키가 파티션 키로 사용됨
CREATE TABLE k1 (
id INT NOT NULL,
name VARCHAR(20),
PRIMARY KEY (id)
)
-- // 괄호의 내용을 비워두면 자동으로 프라이머리 키의 모든 칼럼이 파티션 키가 됨
-- // 그렇지 않고 프라이머리 키의 일부만 명시할 수도 있음
PARTITION BY KEY()
PARTITIONS 2;
-- // 프라이머리 키가 없는 경우 유니크 키(존재한다면)가 파티션 키로 사용됨
CREATE TABLE k1 (
id INT NOT NULL,
name VARCHAR(20),
UNIQUE KEY (id)
)
-- // 괄호의 내용을 비워두면 자동으로 프라이머리 키의 모든 칼럼이 파티션 키가 됨
-- // 그렇지 않고 프라이머리 키의 일부만 명시할 수도 있음
PARTITION BY KEY()
PARTITIONS 2;
-- // 프라이머리 키나 유니크 키의 칼럼 일부를 파티션 키를 명시적으로 설정(MySQL 5.1.6 이상 버전)
CREATE TABLE dept_emp (
emp_no INTEGER NOT NULL,
dept_no CHAR(4)
...
PRIMARY KEY (dept_no, emp_no)
)
-- // 괄호의 내용에 프라이머리 키나 유니크 키를 구성하는 칼럼들 중에세ㅓ
-- // 일부만 선택해 파티션 키로 설정하는 것도 가능하다.
PARTITION BY KEY(dept_no)
PARTITIONS 2;키 파티션을 생성하는 위의 예제를 간단히 살펴보자.
- PARTITION BY KEY 키워드로 키 파티션을 정의한다.
- PARTITION BY KEY 키워드 뒤에 파티션 키 칼럼을 명시한다. 첫 번째나 두 번째 예제와 같이 PARTITION BY KEY()에 아무 칼럼도 명시하지 않으면 MySQL 서버가 자동으로 프라이머리 키나 유니크 키의 모든 칼럼을 파티션 키로 선택한다. 만약 테이블에 프라이머리 키가 있다면 프라이머리 키의 모든 칼럼으로, 프라이머리 키가 없는 경우에는 유니크 인덱스의 모든 칼럼으로 파티션 키를 구성한다.
- MySQL 5.1.6부터는 예제의 세 번째 쿼리와 같이 프라이머리 키나 유니크 키를 구성하는 칼럼들 중에서 일부만 파티션 키로 명시하는 것도 가능하다.
- PARTITIONS 키워드로 생성할 파티션 개수를 지정한다.
- 10.3.4.2 키 파티션의 주의 및 특이사항
- 키 파티션은 MySQL 서버가 내부적으로 MD5() 함수를 이용해 파티셔닝하기 때문에 파티션 키가 반드시 정수 타입이 아니어도 된다. 해시 파티션으로 파티셔닝이 어렵다면 키 파티션 적용을 고려해보자.
- MySQL 5.1.6 미만의 버전에서 파티션 키는 항상 프라이머리 키나 유니크 키의 모든 칼럼을 명시해야 한다. 하지만 MySQL 5.1.6 부터는 프라이머리 키나 유니크 키를 구성하는 칼럼 중 일부만으로도 파티션할 수 있다.
- 유니크 키를 파티션 키로 사용할 때 해당 유니크 키는 반드시 NOT NULL이어야 한다.
- 해시 파티션에 비해 파티션 간의 레코드를 더 균등하게 분할할 수 있기 때문에 키 파티션이 더 자주 사용된다.
5. 리니어 해시 파티션 / 리니어 키 파티션
해시 파티션이나 키 파티션은 새로운 파티션을 추가하거나 파티션을 통합해서 개수를 줄일 때 대상 파티션만이 아니라 테이블의 전체 파티션에 저장된 레코드의 재분배 작업이 발생한다. 이러한 단점을 최소화하기 위해 리니어(Linear) 해시 파티션/리니어 키 파티션 알고리즘이 고안된 것이다. 리니어 해시 파티션/리니어 키 파티션은 각 레코드 분배를 위해 "Power-of-two(2의 승수)" 알고리즘을 이용하며, 이 알고리즘은 파티션의 추가나 통합 시 다른 파티션에 미치는 영향을 최소화할 수 있게 해준다.
리니어 해시 파티션 / 리니어 키 파티션의 추가 및 통합
리니어 해시 파티션이나 리니어 키 파티션의 경우, 단순히 나머지 연산으로 레코드가 저장될 파티션을 결정하는 것이 아니라 "Power-of-two" 분배 방식을 사용하기 때문에 파티션의 추가나 통합 시 특정 파티션의 데이터에 대해서만 이동 작업을 하면 된다. 그래서 파티션을 추가하거나 통합하는 작업에서 나머지 파티션의 데이터는 재분배 대상이 되지 않는 것이다.
1.리니어 해시 파티션 / 리니어 키 파티션의 추가
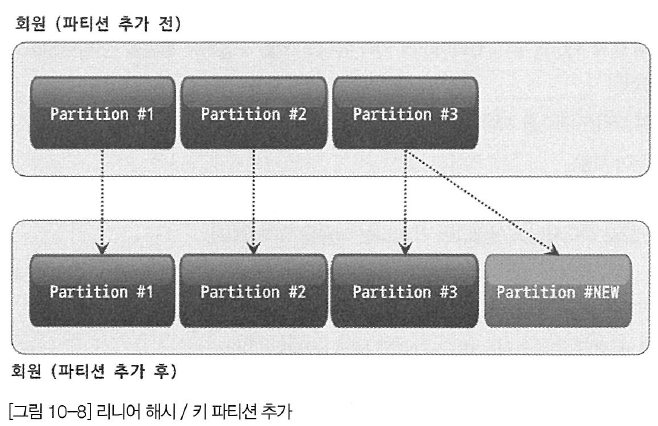
리니어 해시 파티션이나 리니어 키 파티션에 새로운 파티션을 추가하는 명령은 일반 해시 파티션이나 키 파티션과 동일하다. 하지만 리니어 해시 파티션이나 리니어 키 파티션은 "Power-of-two" 알고리즘으로 레코드가 분배돼 있기 때문에 새로운 파티션을 추가할 때도 아래 그림과 같이 특정 파티션의 레코드만 재분배하면 된다. 다른 파티션 데이터는 레코드 재분배 작업과 관련이 없기 때문에 일반 해시 파티션이나 키 파티션의 파티션 추가보다 매우 빠르게 처리할 수 있다.
2.리니어 해시 파티션 / 리니어 키 파티션의 추가
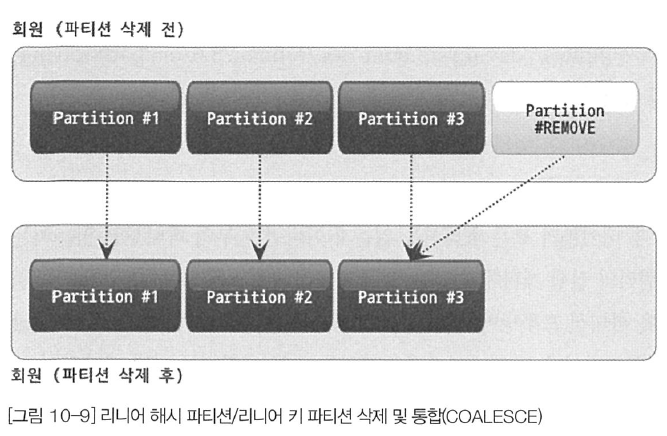
리니어 해시 파티션이나 리니어 키 파티션에서 여러 파티션을 하나의 파티션으로 통합하는 작업 또한 새로운 파티션을 추가할 때와 같이 일부 파티션에 대해서만 레코드 통합 작업이 필요하다. 아래 그림과 같이 통합이 되는 파티션만 레코드 이동이 필요하며, 나머지 파티션의 레코드는 레코드 재분배 작업에서 제외된다.
리니어 해시 파티션 / 리니어 키 파티션과 관련된 주의사항
일반 해시 파티션 또는 키 파티션은 데이터 레코드의 배치를 위해 단순히 해시 값의 결과를 파티션 수로 나눈 나머지 값으로 배치하는 데 비해 리니어(Linear) 파티션은 "Power-of-two" 알고리즘을 사용한다. 그래서 파티션을 추가하거나 통합할 때 작업의 범위를 최소화할 수 있는 대신 각 파티션이 가지는 레코드의 건수는 일반 해시 파티션이나 키 파티션보다는 덜 균등해질 수 있다. 해시 파티션이나 키 파티션으로 파티션된 테이블에 대해 새로운 파티션을 추가하거나 삭제해야 할 요건이 많다면 리니어 해시 파티션 또는 리니어 키 파티션을 적용하는 것이 좋다. 만약 파티션을 조정할 필요가 거의 없다면 일반 해시 파티션이나 키 파티션을 사용하는 것이 좋다.
6. 서브 파티션
다른 상용 DBMS와 같이 MySQL 또한 서브 파티션 기능을 제공한다. 서비스의 요건에 따라 기간 단위로 레인지 파티션을 생성하고, 각 레인지 파티션 내에서 다시 지역별로 리스트 서브 파티션을 구성하는 형태의 파티션이 가능한 것이다. 하지만 MysQL에서는 최대로 사용 가능한 파티션의 개수가 다른 DBMS보다 상당히 제한적이라서 서브 파티션으로 얻을 수 있는 이점은 별로 없다. 또한 서브 파티션이 사용된 테이블에서 적절히 파티션의 효과를 얻으려면 파티션의 특성을 이해하고 그에 맞는 쿼리 문장을 사용할 필요가 있다.
참고
- Real MySQL
