1. 트랜잭션 격리 수준이란?
개발을 할 때 동시에 여러 쓰레드에서 같은 데이터에 접근할 수 있는 것처럼, 동시에 여러 트랜잭션이 처리될 때 같은 데이터에 접근할 수 있다. 이 경우에 동시에 write로 접근을 하는 경우에는 트랜잭션의 4가지 특성인 ACID(원자성 : Atomity, 일관성 : Consistency, Isolation : 격리성, Durability : 지속성) 중 격리성이 지켜지지 않을 수 있다.
그래서 한 트랜잭션이 DB에 접근하는 동안 다른 트랜잭션이 DB에 접근하지 못하게 하는 Locking이라는 개념이 등장했다. 그러나 무조건적인 Locking으로 동시에 수행되는 많은 트랜잭션들을 순서대로 처리하게 하는 방식으로 구현한면 DB의 성능이 떨어지게 된다.
따라서 한 트랜잭션이 데이터베이스를 다루는 동안
따라서 격리성을 만족하면서도 동시성(데이터베이스의 성능)을 적절히 만족시키기 위해 트랜잭션의 격리 수준(Isolation)이 등장했다.
2. 트랜잭션 격리 수준의 종류
격리 수준은 4개로 구분되며 level이 높아질수록 데이터의 무결성이 유지되지만 동시성이 떨어진다.
- Lv.0 : READ UNCOMMITTED
- Lv.1 : READ COMMITED
- Lv.2 : RREPETABLE READ
- Lv.3 : SELIALIZABLE
Lv.0 : READ UNCOMMITTED
- 다른 트랜잭션에서 일어난 변경사항이 커밋(COMMIT)되지 않아도, 현재 트랜잭션에서 그 변경된 값을 읽을 수 있다.
- N개의 트랜잭션이 하나의 공유 데이터에 접근해도 전혀 보호되지 않는다.
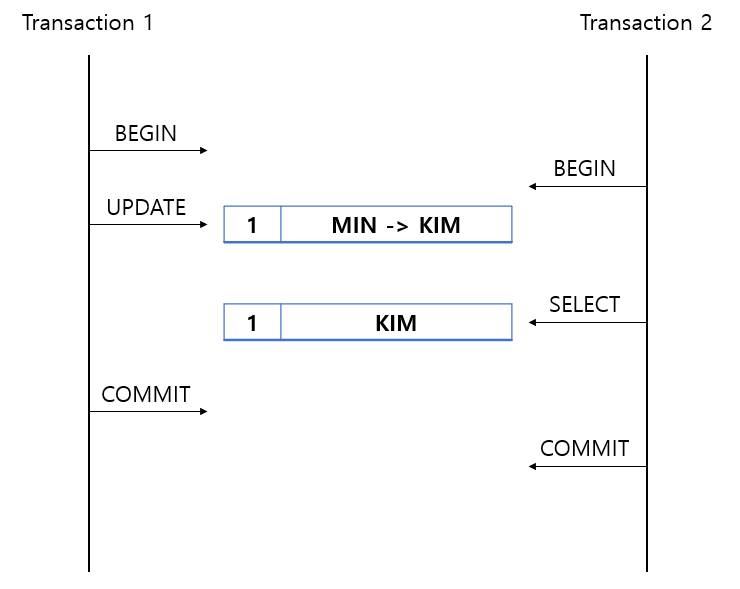
1. 트랜잭션 1을 시작한다.
2. 트랜잭션 2를 시작한다.
3. 트랜잭션 1이 ID = 1, VAL = 'MIN'인 데이터의 VAL을 KIM으로 변경했다.
4. 트랜잭션 2가 ID = 1을 조회한다. VAL='KIM'이 조회된다.
5. 트랜잭션 1, 2가 종료된다.이 수준에서 볼 수 있는 문제로는 Dirty Read가 있다. Diry Read란 트랜잭션 작업이 완료되지 않았는데도 다른 트랜잭션에서 Read(조회)할 수 있게 되는 현상을 말한다.
UPDATE 반영 전에 읽는 오류
- 순서 5에서 오류가 생겨 롤백이 되었다고 가정하자. ID = 1은 다시 MIN이 된다.
- 그러나 롤백 전인 순서 4번은 여전히 VAL=KIM으로 인식한다.
INSERT 반영 전에 읽는 오류
- 트랜잭션 1이 특정 데이터를 INSERT 한다.
- 트랜잭션 2가 그 데이터를 읽고 로직을 수행한다.
- 트랜잭션 1 수행 중 오류가 생겨 롤백되어 INSERT한 데이터가 삭제된다.
- 그러나 트랜잭션 2는 이미 로직을 수행한 상태이다.
Lv.1 : READ COMMITED
- 다른 트랜잭션에서 일어난 변경사항이 커밋되지 않았다면, 실제 테이블의 값을 가져오는 것이 아니라
Undo 영역에 백업된 레코드에서 값을 가져오게 되는 격리 수준이다. - 즉, 커밋된 결과만 읽어오기 때문에 Dirty Read가 발생하지 않는다.
- 하지만 현재 트랜잭션이 아직 진행중인데 다른 트랜잭션이 커밋을 해버렸다면, 그 결과가 트랜잭션 중에 반영되게 된다.
- 즉, 한 트랜잭션 내에서 동일 쿼리문으로 동일 레코드를 두번 이상 조회했을 때 상이한 결과를 얻을 수도 있다. 이러한 현상을
Non-Repeatable Read라고 한다. - 관계형 데이터베이스에서 대부분 기본적으로 사용하고 있는 격리 수준이다.
.png)
1. 트랜잭션 1을 시작한다.
2. 트랜잭션 1이 ID = 1인 데이터의 VALUE를 KIM으로 변경했다.
3. 트랜잭션 2가 시작되었다.
4. 트랜잭션 2가 ID = 1인 데이터를 조회한다. MIN이 검색된다.
5. 트랜잭션 1이 커밋을 하고 종료한다.
6. 트랜잭션 2가 ID = 1인 데이터를 조회한다. KIM이 검색된다.
7. 트랜잭션 2가 커밋을 하고 종료한다.위의 예에서 알 수 있듯이 같은 쿼리문으로 같은 데이터를 여러번 조회했을 때 다른 값이 검색되는Non-Repeatable Read 문제가 발생한다.
Lv.2 : REPEATABLE READ
트랜잭션이 시작되기 전에 변경(UPDATE, DELTE)된 내용에 대해서만 조회하도록 하는 격리수준이다. 먼저 일어난 트랜잭션인지 여부는 트랜잭션 ID를 보고 알 수 있다. 이러한 방식을 MVCC(Multi Version Concurrency Contorl)라고 부른다.
하지만 현재 트랜잭션 중간에 다른 트랜잭션에 INSERT가 발생한 레코드는 조회할 수 있으며 이를 Phantom Read라고 한다.
.png)
1. 트랜잭션 1을 시작한다.
2. 트랜잭션 1이 ID = 1인 데이터를 조회한다.
3. 트랜잭션 2가 시작되었다.
4. 트랜잭션 2가 ID = 1인 데이터를 KIM으로 변경한다.
5. 트랜잭션 ID = 1인 데이터를 조회한다. 트랜잭션 2의 변경 내역이 보이지 않는다.
6. 트랜잭션 2가 ID = 2인 데이터를 삽입 후 COMMIT하여 트랜잭션을 종료한다.
7. 트랜잭션 1이 ID = 2인 데이터를 조회한다. 데이터가 정상적으로 확인된다.
8. 트랜잭션 1이 종료된다.Phantom Read란 마치 유령을 보는 것처럼 있던 데이터가 사라지거나 없던 데이터가 생기는 현상을 말한다.
바로 위 예제의 순서 7에서 트랜잭션1이 ID = 2인 데이터를 조회하고 있다. 순서 8에서 트랜잭션이 정상적으로 종료되지 않고, 트랜잭션 2가 롤백되면 (2, 'KIM') 데이터는 사라지게 된다.
그리고 트랜잭션 1이 다시 ID = 1인 데이터를 조회하면 롤백처리로 인해 조회됐던 데이터가 보이지 않게 된다.
Lv.3 : SERIALIZABLE
- 가장 단순하면서도 가장 엄격한 격리수준이며 데이터 정합성을 가장 잘 보장한다.
- Repeatable Read와 다른 점은, Repeatable Read의 경우 이미 있던 레코드에 대해서만 보장하는 반면, Serializable은 새로 생길 레코드(INSERT 되는 레코드)도 고려하여 격리성을 유지하는 것이다.
- 읽기 작업에도 공유 LOCK을 설정함에 따라, 그동안 다른 트랜잭션에서 이 레코드를 변경하지 못하게 한다. 즉, 트랜잭션이 특정 테이블을 읽으면 다른 트랜잭션은 그 테이블의 데이터를 추가/변경/삭제할 수 없다.
- 이러한 특성 때문에 동시처리 능력이 다른 격리수준보다 떨어지고, 성능저하가 발생하게 된다.
- 모든 것이 순차적으로 진행되므로 Phantom Read가 발생하지 않는다.
참고
