- 해시 테이블이라고도 불림
Key-Value쌍으로 데이터를 저장하는 자료구조- 내부적으로는 배열을 사용
- 해시 함수를 통해 키를 배열의 인덱스로 변환하여 데이터를 저장하고 검색
구성 요소
1. 키(Key)와 값(Value)
-
키(Key): 저장된 데이터를 고유하게 식별하는 값이다.
중복이 허용되지 않는다. -
값(Value): 키에 연결되어 저장되는 실제 데이터다.
값은 중복될 수 있다.
해시맵은 이 키와 값의 쌍(Key-Value Pair)을 하나의 단위(Entry 또는 Node)로 저장한다.
2. 해시 함수 (Hash Function)
키(Key)를 입력받아 정수 형태의 해시 코드(Hash Code)를 생성하는 함수
3. 버킷 (Bucket) 또는 슬롯 (Slot)
해시 함수에 의해 계산된 해시 코드가 가리키는, 데이터가 실질적으로 저장되는 공간
내부적으로는 배열의 각 칸으로 생각할 수 있으며, 버킷의 인덱스는 해시 코드를 배열의 크기로 나눈 나머지 값 등으로 결정된다.
핵심 동작 원리
-
저장:
put('key', 'value')key를 해시 함수에 넣는다.hash('key') -> 5- 해시 함수가 반환한 숫자
5를 인덱스로 삼아, 내부 배열의 5번 칸에value를 저장 - 만약 기존의 5번 칸에 이미 값이 저장되어 있었다면 새로운 값으로 대체된다.
-
검색:
get('key')key를 저장할 때와 똑같은 해시 함수에 넣는다.hash('key') -> 5- 내부 배열의 5번 칸으로 바로 찾아가서 값을 꺼내온다.
해시 함수
- 임의의 길이의 데이터를 고정된 길이의 문자열로 변환하는 함수
- 해시 맵에서는 저장하거나 검색하려는 데이터의 '키(Key)'를 입력받아, 해당 데이터가 저장될 위치를 나타내는 숫자 '인덱스(Index)'로 변환하는 역할
쉬운 비유
거대한 도서관에서 책을 찾는다고 가정한다.
책 제목(
key)를 사서(해시 함수)에게 말하면, 사서는 제목(key)를 바탕으로 "A-12-3" 같은 위치 번호(Index)를 즉시 계산하고 그곳으로 안내한다.
좋은 해시 함수의 조건
해시 테이블의 성능은 해시 함수에 크게 좌우되므로, 좋은 해시 함수는 다음과 같은 조건을 만족해야 한다.
-
효율성: 해시 값을 계산하는 과정이 빨라야 한다.
해시 함수 자체가 복잡하고 오래 걸린다면 해시 테이블의 장점인 속도를 살릴 수 없다. -
분포의 균일성: 키 값들이 배열의 특정 위치에 몰리지 않고, 인덱스 공간 전체에 최대한 고르게 분산되어야 한다.
이는 '해시 충돌'을 최소화하는 데 매우 중요하다. -
결정론성: 동일한 키에 대해서는 항상 동일한 해시 값(인덱스)이 나와야 한다.
이 특성 덕분에 언제든지 키를 통해 저장된 값을 다시 찾아갈 수 있다.
해시 충돌과 해결법
해시 충돌?
e.g.) 만약 'key1'과 'key2'가 해시 함수를 거쳤더니 둘 다 같은 인덱스를 반환하는 현상
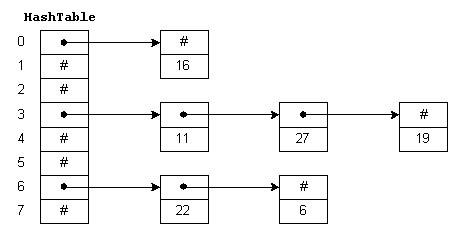
분리 연결법
- 내부 배열의 각 칸(버킷)에 값을 하나만 저장하는 대신, 연결 리스트를 하나씩 두는 것
- 충돌이 발생하면, 해당 인덱스의 연결 리스트에 새로운 노드를 추가해 데이터를 저장한다
예시
'lisa'와 'john'이 같은 인덱스 1로 해싱된 경우
Buckets (Array)
[0] -> null
[1] -> [key: 'lisa', val: 25] -> [key: 'john', val: 30] -> null // 연결 리스트 노드 추가
[2] -> [key: 'sandra', val: 28] -> null
...