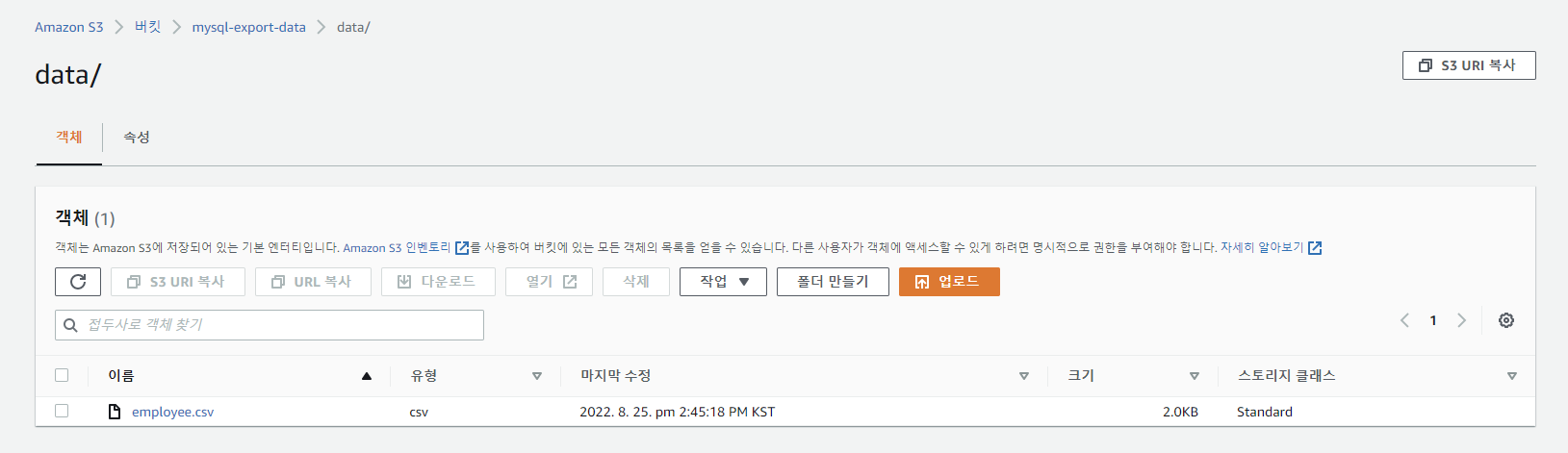
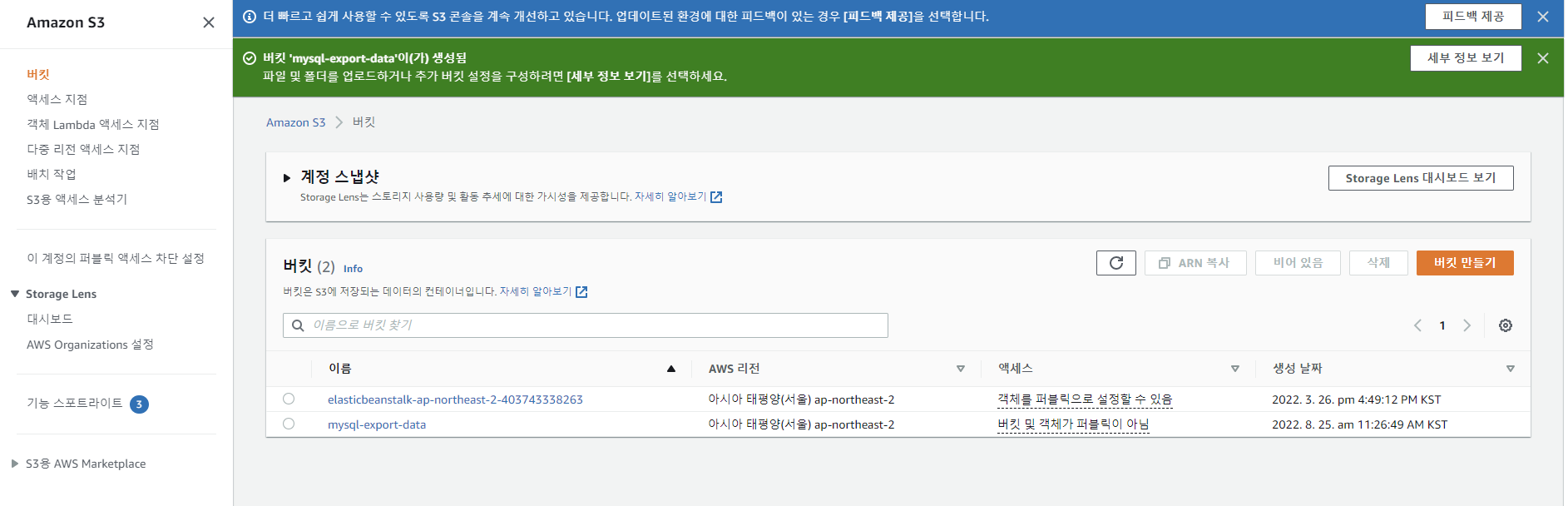
S3 버킷 만들기
AWS S3 서비스로 이동하여 [버킷 만들기] 클릭
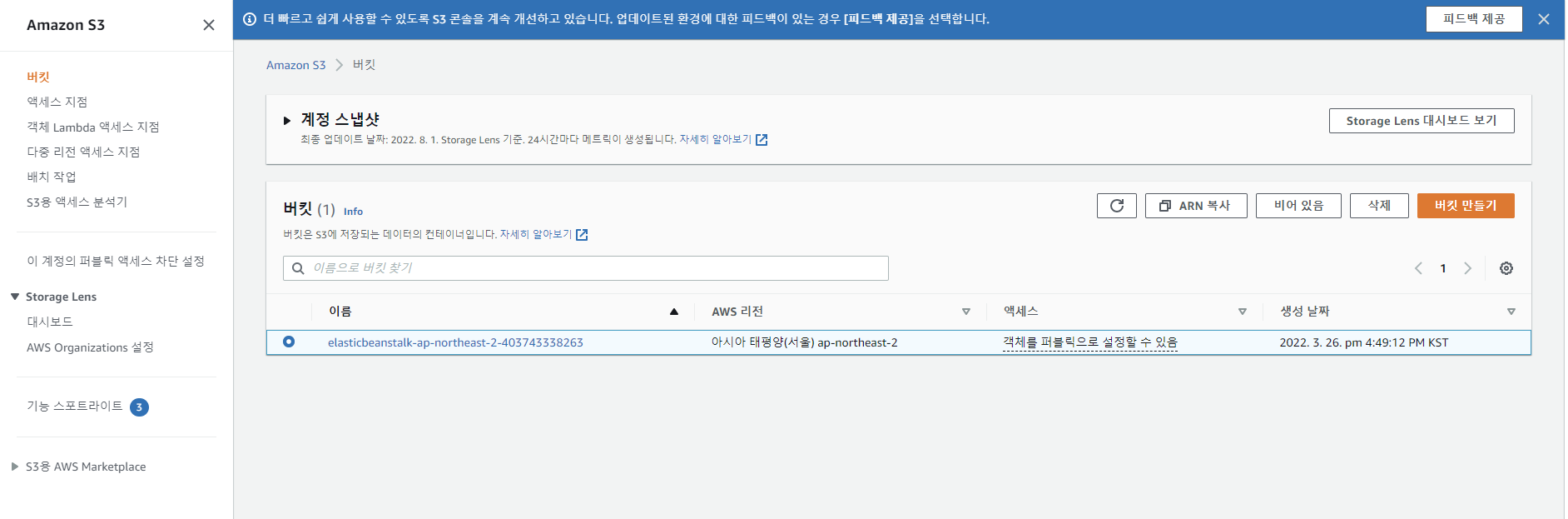
버킷 이름 입력 후 [버킷 만들기] 클릭
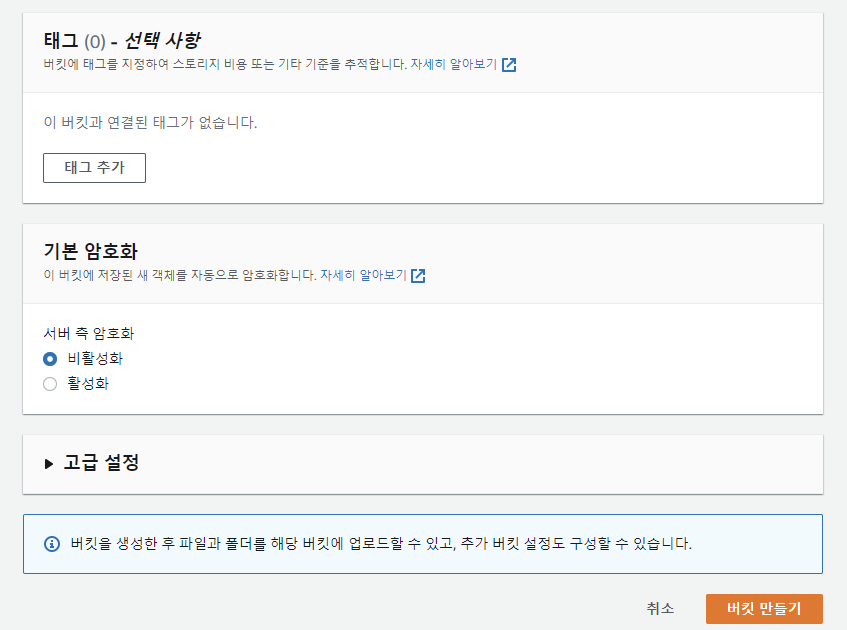
생성된 버킷 확인
AWS Access Key 생성하기
IAM 서비스로 이동한 뒤 로그인할 계정 선택한다.

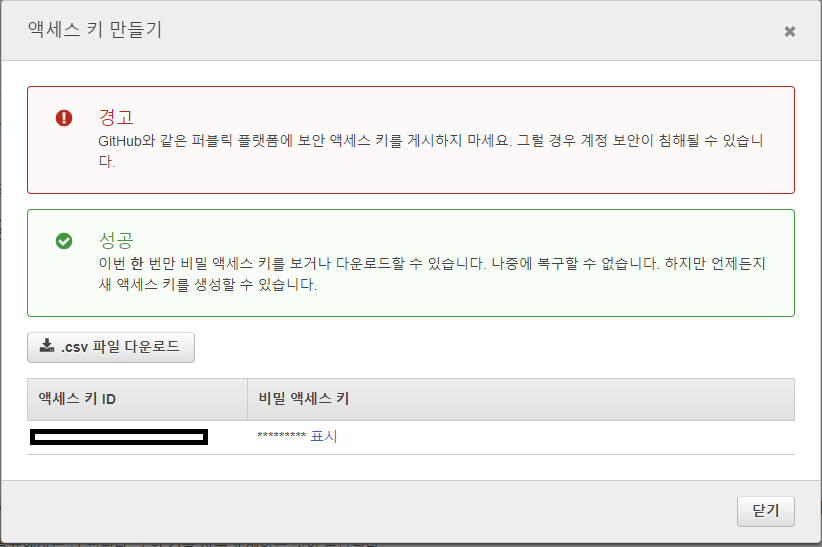
[보안 자격 증명] 탭 - [액세스 키] 에서 [엑세스 키 만들기] 클릭

액세스 키 ID와 비밀 액세스 키를 잘 저장한다.
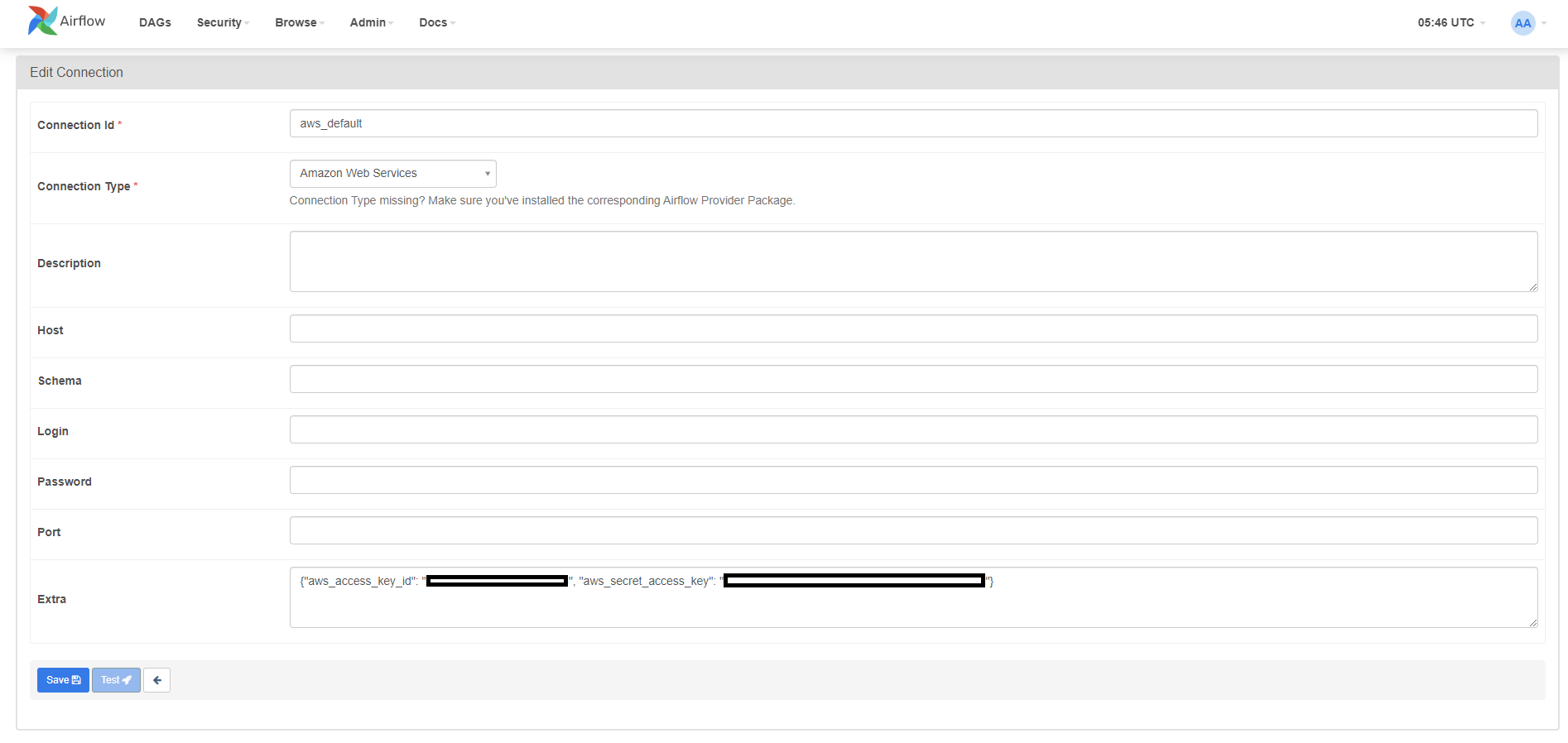
Airflow 연결 만들기
Connection Type으로 Amazon Web Services를 선택 후 Extra에 IAM에서 발급받은 액세스 키 ID와 비밀 액세스 키를 JSON 형태로 입력 후 [Save] 한다.
DAG 작성하기
라이브러리 설치
AWS를 사용하기 위해서 아래 라이브러리를 설치해준다.
pip3 install apache-airflow[amazon]
DAG 작성 시 S3 hook을 Import 해주면 된다.
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
DAG 작성하기
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
def upload_to_s3(filename: str, key: str, bucket_name: str) -> None:
hook = S3Hook('aws_default')
hook.load_file(filename=filename, key=key, bucket_name=bucket_name)
with DAG(
'upload_to_s3',
schedule_interval = timedelta(minutes=5),
start_date = datetime(2022, 1, 1),
catchup = False
) as dag:
upload = PythonOperator(
task_id = 'upload',
python_callable = upload_to_s3,
op_kwargs = {
'filename' : '/opt/airflow/data/employee_test.csv',
'key' : 'data/employee.csv',
'bucket_name' : 'mysql-export-data'
}
)
filename
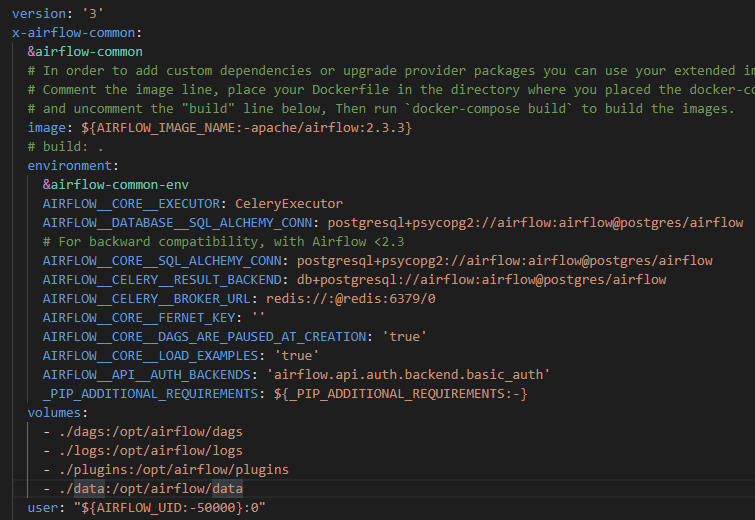
현재 내 Airflow는 Docker 위에서 동작한다. 따라서 파일은 Airflow가 동작하는 Container의 파일시스템에 위치시켜야 한다. Container에 매번 접속해서 파일을 컨트롤할 수 없으니 볼륨 설정을 해주었다.
실제 파일의 위치를 보면 WSL Ubuntu의
~/airflow/data에 있는 것을 볼 수 있다.
key
key는 bucket_name에 지정한 버킷 내에 파일을 어떤 경로에 어떤 이름으로 저장할지 지정해준다.bucket_name
업로드할 버킷을 지정한다.

DAG 실행하기
DAG를 저장한 뒤 Airflow Web UI에서 실행시켜 정상 동작을 확인한다.
S3 확인하기
mysql-export-data 버킷의 data 디렉토리 밑에 employee.csv로 저장된 것을 확인할 수 있다.