시나리오
A기업에서는 employee Dimension 데이터를 기준으로 Tableau를 통해 근무현황, 휴가현황과 같은 HR 대시보드를 운영하고 있으며, 대시보드는 daily로 집계 및 업데이트가 되고 있다.
더불어 여러 부서와 직원들이 동일한 HR 데이터를 가져다가 인건비 계산, 복지 개선 등을 목적으로 각각 분석을 하고 있다.
employee Master를 비롯한 Fact로 사용되고 있는 Transaction 데이터들은 On-prem으로 운영 중인 MySQL DB에 발생하고 있다.
문제점은 대시보드 뿐만 아니라 분석을 하는 여러 부서 및 직원들이 Tableau에 데이터를 가져갈 때 운영 DB에 직접적으로 Query를 날리고 있다는 것이다. 이런 부하로 인해 운영 DB에 많은 영향을 미치기 시작했다.
따라서 A기업에서는 데이터 분석을 위한 별도의 Data Warehouse를 구축하여 운영해야할 니즈가 발생하였다.
DW로는 MPP Architecture에 기반한 서비스인 대중적으로 많이 사용되는 AWS Redshift를 사용하기로 결정하였다.
기준이 되는 employee 데이터에 대한 간단한 Pipeline을 만들어보자. 파일 처리와 같은 디테일한 처리는 다루지 않는다.
Architecture
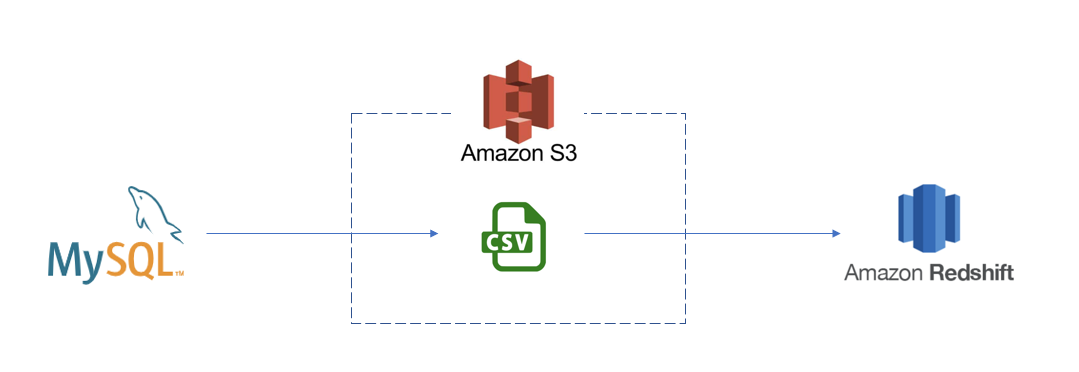
Source는 On-prem MySQL, Target은 Redshift로 정해졌다.
MySQL에서 Redshift로 데이터를 전달하는 Pipeline Architecture는 다음과 같다.
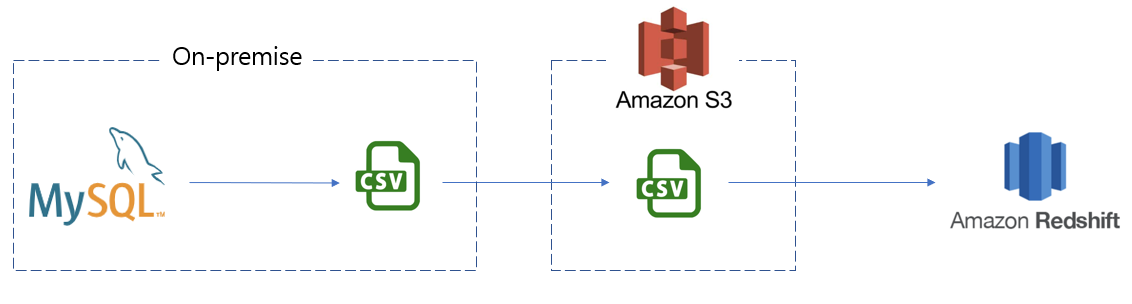
Redshift의 COPY 명령을 사용하기 위해 Staging Area로서 S3를 사용한다.
COPY 명령은 MPP Architecture를 사용해서 여러 데이터 원본에서 병렬로 데이터를 읽고 적재할 수 있다. S3의 구조를 잘 설계하면 병렬 처리의 장점을 잘 살릴 수 있을 것이다.
Pipeline은 세 부분으로 나눠볼 수 있다.
1) MySQL 데이터를 csv로 export 한다.
2) csv를 AWS S3에 업로드 한다.
3) S3에 업로드 된 csv 데이터를 Redshift로 전달한다.
연결 만들기
Pipeline을 만들기 위해서 3개의 Connection을 만들어주어야 한다.
1) MySQL
2) S3
3) Redshift
MySQL 연결
MySQL을 설치하면 기본적으로는 외부 접속을 허용하지 않는다. 따라서 외부 접속을 허용하는 계정을 우선 생성해주어야 한다.
아래 포스팅을 참고하여 외부 접속을 허용하는 계정을 생성해준다.
Airflow Pipeline 만들기 - MySQL Query 하기
https://velog.io/@jskim/Airflow-Pipeline-%EB%A7%8C%EB%93%A4%EA%B8%B0-MySQL-Query-%ED%95%98%EA%B8%B0

S3 연결을 위한 AWS 연결
S3를 연결하기 위한 Connection을 만들어주어야 한다.
그러기 위해서 AWS Access Key와 Secret Access Key가 필요하다.
IAM에서 Key를 발급받을 수 있으며 아래 포스팅을 참고한다.
Airflow Pipeline 만들기 - AWS S3에 파일 업로드하기
https://velog.io/@jskim/Airflow-Pipeline-%EB%A7%8C%EB%93%A4%EA%B8%B0-AWS-S3%EC%97%90-%ED%8C%8C%EC%9D%BC-%EC%97%85%EB%A1%9C%EB%93%9C%ED%95%98%EA%B8%B0
Redshift 연결
Redshift에 연결하기 위해서는 Cluster 생성과 방화벽 설정과 같은 설정이 필요하다.
아래 포스팅을 참고하여 Redshift Cluster 생성부터 연결을 위한 보안까지 설정한다.
Airflow Pipeline 만들기 - Redshift Query하기
https://velog.io/@jskim/Airflow-Pipeline-%EB%A7%8C%EB%93%A4%EA%B8%B0-Redshift-Query%ED%95%98%EA%B8%B0
DAG 생성
DAG 구조
Task는 다음과 같이 구성된다.

DAG Code
from datetime import datetime, timedelta
from airflow import DAG
from airflow.providers.mysql.operators.mysql import MySqlOperator
from airflow.operators.python import PythonOperator
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
from airflow.providers.amazon.aws.transfers.s3_to_redshift import S3ToRedshiftOperator
from airflow.providers.amazon.aws.operators.redshift_sql import RedshiftSQLOperator
# Local
DIR_PATH = 'C:/tmp/data/'
FILE_NAME = 'employee.csv'
FILE_PATH = DIR_PATH + FILE_NAME
# s3
S3_BUCKET_NAME = 'mysql-export-data'
S3_KEY = 'data/' + FILE_NAME
# Redshift
REDSHIFT_TABLE = 'employee'
mysql_sql = """
SELECT * FROM employees
INTO OUTFILE '{0}'
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n';
""".format(FILE_PATH)
redshift_sql = """
CREATE TABLE IF NOT EXISTS {0} (
employeeNumber int PRIMARY KEY,
lastName varchar(50) NOT NULL,
firstName varchar(50) NOT NULL,
extension varchar(10) NOT NULL,
email varchar(100) NOT NULL,
officeCode varchar(10) NOT NULL,
reportsTo int DEFAULT NULL,
jobTitle varchar(50) NOT NULL
);
""".format(REDSHIFT_TABLE)
def upload_to_s3(filename: str, key: str, bucket_name: str) -> None:
hook = S3Hook('aws_default')
hook.load_file(filename=filename, key=key, bucket_name=bucket_name)
with DAG(
'mysql_to_redshift',
schedule_interval = '@daily',
start_date = datetime(2022, 1, 1),
catchup = False
) as dag:
export_mysql_data = MySqlOperator(
task_id = 'export_mysql_data',
mysql_conn_id = 'mysql_local_test',
sql = mysql_sql
)
upload_to_s3 = PythonOperator(
task_id = 'upload_to_s3',
python_callable = upload_to_s3,
op_kwargs = {
'filename' : '/opt/airflow/data/{0}'.format(FILE_NAME),
'key' : S3_KEY,
'bucket_name' : '{0}'.format(S3_BUCKET_NAME)
}
)
create_table = RedshiftSQLOperator(
task_id = "create_table",
redshift_conn_id = "redshift_default",
sql = redshift_sql
)
transfer_s3_to_redshift = S3ToRedshiftOperator(
task_id = 'transfer_s3_to_redshift',
aws_conn_id = 'aws_default',
redshift_conn_id = 'redshift_default',
s3_bucket = S3_BUCKET_NAME,
s3_key = S3_KEY,
schema = 'public',
table = REDSHIFT_TABLE,
copy_options = ['csv']
)
export_mysql_data >> upload_to_s3 >> create_table >> transfer_s3_to_redshiftDAG 실행 결과
Redshift에 employee 테이블이 생성되었고, 데이터가 정상적으로 적재된 것을 확인할 수 있다.

