스케줄 정의하기
스케줄 간격을 정의하기 위해서 schedule_interval 인수를 설정한다. default 값은 None
import datetime ad dt
from airflow import DAG
dag = DAG(
'unscheduled',
start_date=dt.datetime(2019, 1, 1), # DAG 시작 날짜
schedule_interval=None, # 스케줄되지 않은 DAG로 지정
)스케줄 간격 정의하기 - Airflow 매크로 프리셋 사용
schedule_interval="@daily"와 같이 @daily 매크로는 매일 자정에 DAG를 실행하도록 예약한다.
이 외에도 다음과 같은 매크로를 지원한다.
자주 사용되는 스케줄 간격 프리셋
| 프리셋 | 설명 |
|---|---|
@once | 1회만 실행하도록 스케줄 |
@hourly | 매시간 변경 시 1회 실행 |
@daily | 매일 자정에 1회 실행 |
@weekly | 매주 일요일 자정에 1회 실행 |
@monthly | 매월 1일 자정에 1회 실행 |
@yearly | 매년 1월 1일 자정에 1회 실행 |
end_date 인수를 설정하면 DAG의 실행 중지 날짜를 지정할 수 있다.
아래 DAG는 2019-01-01에 시작하여 2019-01-05일에 종료로 정의되어 있다.
하지만 실제 실행은 2019-01-02에 최초 실행되어서 2019-01-06에 마지막 실행이 된다.
start_date와 end_date 각각에 정의된 날짜는 스케줄 간격 (schedule_interval)의 기점을 정의하기 때문이다. (후속편에서 자세히 다룸)
dag=DAG(
'with_end_date',
schedule_interval="@daily",
start_date=dt.datetime(2019, 1, 1),
end_date=dt.datetime(2019, 1, 5)
)스케줄 간격 정의하기 - Cron 활용
Airflow는 좀 더 복잡한 스케줄 간격을 지원하기 위해 MacOS/Linux 같은 Unix 기반 OS 스케줄러인 cron 구문을 지원한다.
cron 구성요소는 다음과 같다.
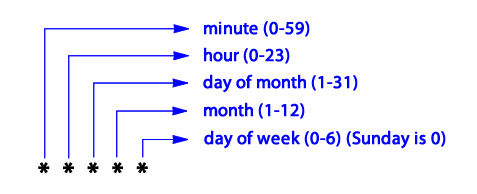
몇 가지 예시를 들어보자.
| 구문 | 설명 |
|---|---|
0 * * * * | 매시간 (정시 실행) |
0 0 * * * | 매일 (자정에 실행) |
0 0 * * 0 | 매주 (일요일 자정에 실행) |
0 0 1 * * | 매월 1일 자정 |
45 23 * * SAT | 매주 토요일 23시 45분 |
0 0 * * MON, WED, FRI | 매주 월, 화, 금 자정에 실행 |
0 0 * * MON-FRI | 매주 월~금 자정에 실행 |
0 0,12 * * * | 매일 자정 및 오후 12시 실행 |
스케줄 간격 정의하기 - 빈도 기반
cron 식은 특정 빈도 (frequency)마다 스케줄을 정의할 수 없다.
예를 들어 DAG를 3일에 한 번씩 실행하는 cron 식을 정의하긴 어렵다.
Airflow는 timedelta 인스턴스를 사용하여 빈도 기반 스케줄을 정의할 수 있다.
dag=DAG(
'time_delta',
schedule_interval=dt.timedelta(days=3),
start_date=dt.datetime(2019, 1, 1),
end_date=dt.datetime(2019, 1, 5),
)분은 timedelta(minutes=10), 시간은 timedelta(hours=2) 처럼 정의할 수 있다.
데이터 증분
@daily로 실행되는 DAG가 있을 때 전체 데이터 세트를 처리하는 것은 비효율적이다. 증분 방식(incremental approach)를 통해 스케줄된 하나의 작업에서 처리해야 할 데이터양을 크게 줄이는 것이 좋다.
특정 시간 간격에 대한 데이터 가져오기
특정 날짜의 데이터를 다운로드하거나, 시작 및 종료 날짜 매개변수를 함께 정의하여 해당 날짜에 대한 이벤트 데이터만 가져오도록 조정할 수 있다.
예를 들어 API를 호출할 때 매개변수를 조정한다.
curl -O http://localhost:5000/events?start_date=2019-01-01&end_date=2019-01-02
다음과 같이 DAG로 구현할 수 있다.
fetch_events=BashOperator(
task_id="fetch_events",
bash_command=(
"mkdir -p /data && "
"curl -o /data/events.json "
"http://localhost:5000/events?"
"start_date=2019-01-01&"
"end_date=2019-01-02"
),
dag=dag,
)실행 날짜(execution_date)를 사용하여 동적 시간 참조하기
Airflow는 execution_date라는 Task가 실행되는 특정 간격을 정의하는 추가 매개변수를 제공한다. execution_date는 DAG를 시작하는 시간의 특정 날짜(start_date)가 아니라 스케줄 간격으로 실행되는 시작 시간을 나타내는 timestamp이다.
스케줄 간격의 종료시간은 next_execution_date를 사용한다.
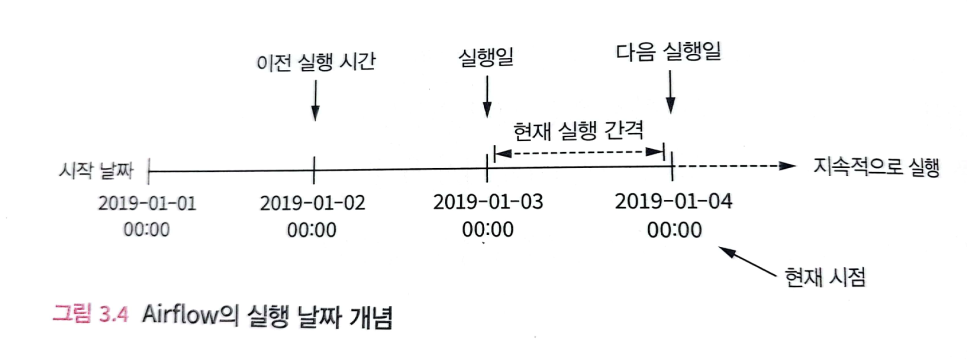
예를 들어 시작날짜가 2019-01-01인 DAG가 있다. 오늘은 2019-01-04이다.
DAG는 2019-01-02 하루만 실행이 된 상태이다. 그러면 2019-01-03 ~ 2019-01-04의 DAG를 실행시켜야 한다.
이 로직을 고정 날짜 값이 아닌 동적 시간을 참조할 수 있다.
다음과 같이 DAG를 작성할 수 있다.
fetch_events=BashOperator(
task_id="fetch_events",
bash_command=(
"mkdir -p /data && "
"curl -o /data/events.json "
"http://localhost:5000/events?"
"start_date={{execution_date.strftime('%Y-%m-%d')}}" # Jinja template으로 형식화된 execution_date 삽입
# strftime 메서드로 문자열 형식으로 반환 (datetime 개체이므로)
"end_date={{next_execution_date.strftime('%Y-%m-%d')}}" # next_execution_date로 다음 실행 간격의 날짜 정의
),
dag=dag,
)이 외에도 과거의 스케줄 간격의 시작을 정의하는 previous_execution_date 매개변수도 제공한다. 이 매개변수는 현재 시간 간격의 데이터와 이전 간격의 데이터를 대조하여 분석을 수행할 때 유용하다.
축약어 사용하기
Airflow는 일반적인 날짜 형식에 대한 여러 유형의 축약 매개변수(shorthand parameters)를 제공한다.
YYYY-MM-DD 및 YYYYMMDD 형식은 ds 및 ds_nodash로 표현할 수 있다.
이외에도 next_ds, next_ds_nodash, prev_ds, prev_ds_nodash가 있다.
fetch_events=BashOperator(
task_id="fetch_events",
bash_command=(
"mkdir -p /data && "
"curl -o /data/events.json "
"http://localhost:5000/events?"
"start_date={{ds}}" # YYYY-MM-DD 형식의 execution_date
"end_date={{next_ds}}" # YYYY-MM-DD 형식의 next_execution_date
),
dag=dag,
)데이터 파티셔닝
위 DAG는 fetch_events Task를 통해 새로운 이벤트 데이터를 @daily로 점진적으로 가져온다. 이 때 발생하는 문제는 각각의 새로운 Task가 전일의 데이터를 덮어쓰게 된다는 것이다.
문제해결 방법1 : 출력 파일에 새 이벤트 추가
이 문제를 해결하기 위해서는 출력 파일인 events.json 파일에 새 이벤트를 추가하는 것이다. 그러면 하나의 json 파일에 모든 데이터를 작성할 수 있다.
이 방법의 단점은 특정 날짜의 통계 계산을 하려고 하면 전체 데이터 세트를 load하는 downstream 프로세스 작업이 필요하다.
또한 이 파일은 장애 지점이 되어 파일이 손상되어 전체 데이터 세트가 손실될 위험을 가지게 된다.
문제해결 방법2 : 해당 실행 날짜의 이름이 적힌 파일에 기록 (파티셔닝)
또 다른 방식은 Task 출력을 해당 실행 날짜의 이름이 적힌 파일에 기록함으로써 데이터 세트를 일일 배치로 나누는 것이다.
fetch_events=BashOperator(
task_id="fetch_events",
bash_command=(
"mkdir -p /data/events && "
"curl -o /data/events/{{ds}}.json " # 반환된 값이 템플릿 파일 이름에 기록
"http://localhost:5000/events?"
"start_date={{ds}}"
"end_date={{next_ds}}"
),
dag=dag,
)데이터 세트를 더 작고 관리하기 쉬운 조각으로 나누는 작업은 데이터 저장 및 처리 시스템에 일반적인 전략이다. 이런 방법을 파티셔닝(partitioning) 이라고 한다. 데이터 세트의 작은 부분은 파티션(partitions)라고 한다.
파티션 이점
파티션의 이점은 다음과 같이 통계를 구하는 경우를 고려할 때 분명해진다.
비효율적인 이벤트 통계 작업
from pathlib import Path
import pandas as pd
def _calculate_stats(input_path, output_path):
Path(output_path).parent.mkdir(exist_ok=True)
events=pd.read_json(input_path)
stats=events.groupby(["date", "user"]).size().reset_index()
stats.to_csv(output_path, index=False)
calculate_stats = PythonOperator(
task_id="calculate_stats",
python_callable=_calculate_stats,
op_kwags={
"input_path": "/data/events.json",
"output_path": "/data/stats.csv",
},
dag=dag
)위 Task는 매일 사용자 이벤트에 대한 통계를 계산하는데, 매일 전체 데이터 세트를 load하고, 전체 이벤트 기록에 대한 통계를 계산한다.
Task의 입력, 출력에 대한 경로를 변경해 파티션된 데이터 세트를 사용하면, 각 파티션에 대한 통계를 효율적으로 계산할 수 있다.
효율적인 통계 계산 (실행 스케줄 간격마다 통계 계산)
def _calculate_stats(**context): # 모든 컨텍스트 변수를 수신
input_path=context["templates_dict"]["input_path"] # templates_dict 개체에서 템플릿 값 검색
output_path=context["templates_dict"]["output_path"]
Path(output_path).parent.mkdir(exist_ok=True)
events=pd.read_json(input_path)
stats=events.groupby(["date", "user"]).size().reset_index()
stats.to_csv(output_path, index=False)
calculate_stats = PythonOperator(
task_id="calculate_stats",
python_callable=_calculate_stats,
templates_dict={ # 템플릿되는 값 전달
"input_path": "/data/events/{{ds}}.json", #
"output_path": "/data/stats/{{ds}}.csv",
},
dag=dag
)PythonOperator에서 템플릿을 구현하려면 Operator의 templates_dict 매개변수를 사용하여 템플릿화해야 하는 모든 인수를 전달해야 한다.
