실행날짜(execution_date) 파헤치기
Airflow는 간격 기반(interval-based) 접근 방식을 사용한다. 이점은 작업이 실행되는 시간 간격(시작 및 끝)을 정확히 알고 있으므로 증분 데이터 처리 유형을 수행하는 데 적합하다. 증분 처리의 경우 일반적으로 시간은 해당 간격이 지나자마자 처리되는 개별적인 시간 간격으로 나뉜다.
이게 무슨 말인지 알아보자.
Airflow는 시작 날짜(start_date), 스케줄 간격(schedule_interval), 종료 날짜(end_date, 선택사항) 3가지 매개변수로 시간을 스케줄 간격으로 나눈다.

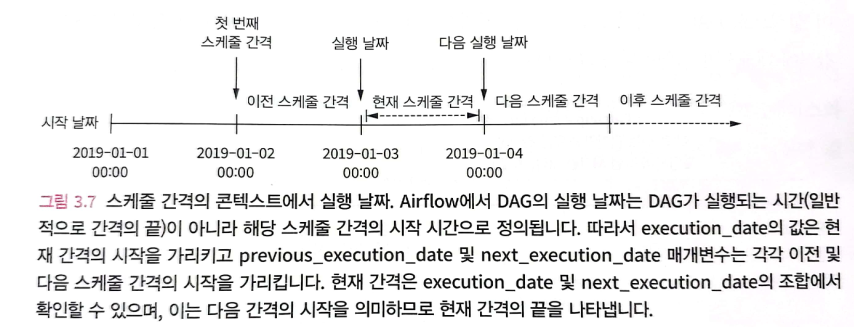
Airflow는 실행 날짜(execution_date)를 해당 간격의 시작 날짜로 정의한다. 개념적으로 DAG가 실제 실행되는 순간이 아니라 예약 간격의 시작을 표시한다고 생각하면 된다.
따라서 그림 3.5의 첫 번째 간격은 2019-01-01 23:59:59 이후에 가능한 한 바로 실행된다. 마찬가지로 2019-01-02 23:59:59 직후 두 번째 간격동안 실행된다.
예를 들어 특정 DAG가 매일 스케줄 간격(schedule_interval)로 정의되어 있고, 특정 날짜 2019-01-03에 대한 데이터를 처리할 수 있도록 처리한다고 가정한다. 그러면 Airflow는 2019-01-04 00:00:00 직후에 실행된다. 왜냐하면 이 시점에서는 2019-01-03 날짜에 대한 새로운 데이터가 더 이상 수신되지 않는다는 것을 알기 때문이다. 따라서 이 스케줄 간격을 위한 execution_date는 2019-01-03이다.
특정 간격의 시작과 끝 유추
Airflow 실행 날자를 해당 스케줄 간격(schedule_interval)의 시작으로 생각해 정의하면 특정 간격의 시작과 끝을 유추할 수 있다.
예를 들어 작업을 실행할 때 해당 간격의 시작과 끝은 execution_date와 next_execution 매개변수로 정의된다.
이전 스케줄 간격은 previous_execution_date와 execution_date 매개변수로 확인할 수 있다.
주의
태스크에서 previous_execution_date, next_execution_date 매개변수는 DAG 실행을 했을 경우에 정의된다.
따라서 Airflow UI/CLI를 통해 수동으로 실행하는 경우, Airflow가 다음 또는 이전 스케줄 간격에 대한 정보를 확인할 수 없기 때문에 매개변수 값이 정의되지 않아 사용할 수가 없다.
과거 데이터 간격을 메꾸기 위해 백필(backfill)사용하기
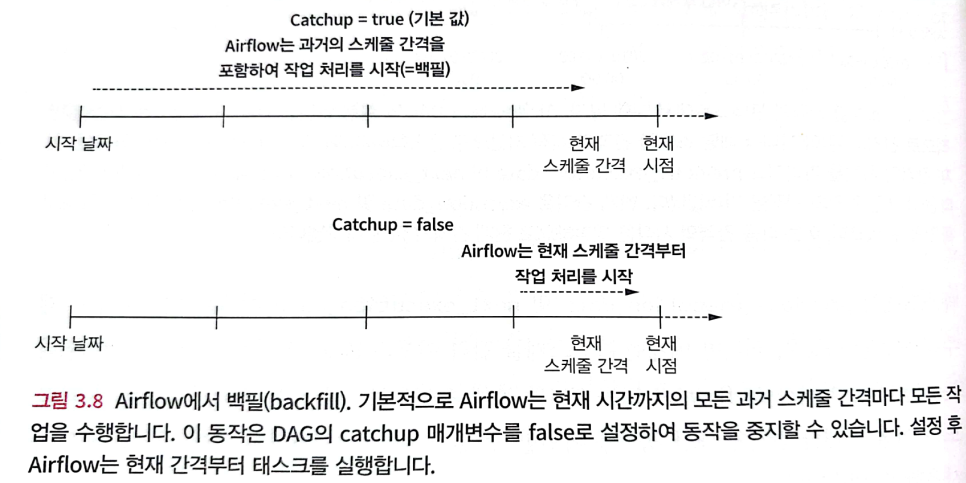
DAG의 과거 시점을 지정해 실행하는 프로세스를 백필(backfilling)이라고 한다.
DAG에 과거 시작 날짜를 지정하고 해당 DAG를 활성화하면 과거 시작 이후부터 현재 시간까지의 모든 스케줄 간격이 생성된다.
이 동작은 catchup 매개변수에 의해 제어되고, false로 설정하여 비활성화할 수 있다.
과거 시점의 태스크 실행을 피하기 위해 catchup 비활성화
dag=DAG(
"no_catchup",
schedule_interval="@daily",
start_date=dt.datetime(2019, 1, 1),
end_date=dt.datetime(2019, 1, 5),
catchup=False,
)이 설정으로 DAG는 과거 모든 스케줄 간격으로 태스크를 실행하는 대신 가장 최근 스케줄 간격에 대해서만 실행한다.
catchup기본값은 Airflow config 파일에서catchup_by_default설정으로 제어할 수 있다.
backfill을 사용할만한 사례
backfill은 코드를 변경한 후 데이터를 다시 처리하는 데 사용할 수 있다.
예를 들어 calc_statistics 함수를 변경하여 새로운 통계 계산을 추가한다고 가정할 때, backfill을 사용하면 calc_statistics Task의 과거 실행 결과를 지우고 새 코드를 이용해 과거의 데이터를 재분석할 수 있다.
Task 디자인을 위한 모범 사례
원자성
원자성은 모든 것이 완료되거나 완료되지 않도록 보장해야 한다. Airflow의 Task는 다음과 같이 구성되어야 한다는 걸 말한다.
- 성공적으로 수행하여 적절한 결과를 생성하거나
- 시스템 상태에 영향을 미치지 않고 실패하도록 정의한다.
예시)
위 이벤트 DAG 예시에서 DAG 실행이 끝날 때마다 사용자에게 E-mail을 발송하는 기능을 추가한다고 가정하자.
이 때 가장 간단한 방법은 통계 계산 함수에 E-mail을 보내는 함수를 추가하는 것이다.
하나의 Task에 두 개의 작업을 넣어 원자성을 무너뜨린 경우
def _calculate_stats(**context):
input_path=context["templates_dict"]["input_path"]
output_path=context["templates_dict"]["output_path"]
Path(output_path).parent.mkdir(exist_ok=True)
events=pd.read_json(input_path)
stats=events.groupby(["date", "user"]).size().reset_index()
stats.to_csv(output_path, index=False)
# csv 작성 후 e-mail을 보내면 단일 기능에서 두 가지 작업을 수행하여 원자성이 깨진다.
email_stats(stats, email="user@example.com")
calculate_stats >> email_stats원자성을 유지하는 방식으로 구현하기 위해서는 이메일 발송 기능을 별도의 Task로 분리한다.
다수 개의 Task로 분리하여 원자성 개선
def _calculate_stats(**context):
input_path=context["templates_dict"]["input_path"]
output_path=context["templates_dict"]["output_path"]
Path(output_path).parent.mkdir(exist_ok=True)
events=pd.read_json(input_path)
stats=events.groupby(["date", "user"]).size().reset_index()
stats.to_csv(output_path, index=False)
def _send_stats(email, **context):
stats=pd.read_csv(context["tempates_dict"]["stats_path"])
email_stats(stats, email=email)
calculate_stats = PythonOperator(
task_id="calculate_stats",
python_callable=_calculate_stats,
templates_dict={
"input_path": "/data/events/{{ds}}.json", #
"output_path": "/data/stats/{{ds}}.csv",
}
send_stats=PythonOperator(
task_id="send_stats",
python_callable="_send_stats,
op_kwargs={"email": "user@example.com"},
templates_dict={"stats_path": "/data/stats/{{ds}}.csv"}},
dag=dag,
)
calculate_stats >> send_stats멱등성
동일한 입력으로 동일한 Task를 여러 번 호출해도 결과에 효력이 없어야 한다. 즉 입력 변경없이 Task를 다시 실행해도 전체 결과가 변경되지 않아야 한다.
만약 아래 Task를 그대로 다시 실행한다면 /data/events 폴더에 있는 기존 json 파일에 동일한 결과를 덮어쓰게 된다. 즉 해당일의 이벤트 데이터가 중복된다.
fetch_events=BashOperator(
task_id="fetch_events",
bash_command=(
"mkdir -p /data/events && "
"curl -o /data/events/{{ds}}.json " # 템플릿 파일 이름을 설정하여 분할
"http://localhost:5000/events?"
"start_date={{ds}}"
"end_date={{next_ds}}"
),
dag=dag,
)따라서 Task를 추가로 실행하면 전체 결과에 반영되어 비멱등성(non-idempotent)을 확인할 수 있다.
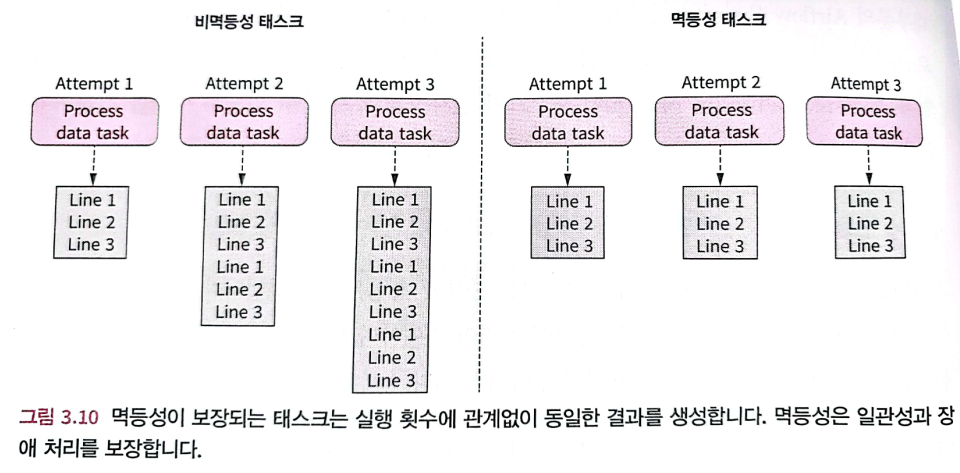
일반적으로 데이터를 쓰는 Task는 기존 결과를 확인하거나, 이전 Task 결과를 덮어쓸지 여부를 확인하여 멱등성을 유지할 수 있다.
