Abstract
- 지금까지는 intra-channel information 즉 한 layer 내에서 중요도를 판단하였지만 우리는 inter-channel 관점에서 layer간의 정보를 활용하여 channel independence를 측정한다.
- 덜 독립적인 feature map은 덜 유용한 정보나 지식이 있다고 판단하여 모델의 성능에 큰 영향을 주지 않을 것이다.
- CIFAR10 에서는 Resnet56, Resnet101 기준 0.9%, 0.94% 성능이 높아졌다. FLOPs는 48.3%와 52.1% 줄였다.
- ImageNet에서는 ResNet50 모델에서 0.15% 성능이 높아졌다.
1. Introduction
- CNN 모델은 많이 사용되지만 계산량과 저장 공간을 많이 차지하기 때문에 자원이 한정된 임베디드 플랫폼에 효율적인 배포가 어렵다.
- 모델 압축을 위해 network pruning, quantization, low-rank approximation, knowledge distillation과 structured matrix-based construction이 사용된다.
- network pruning은 산업과 학계에서 연구되고 있으며 weight pruning과 filter pruning으로 나뉜다.
Existing Filter Pruning Methods
- 지금까지 연구는 how to determine the important filters에 초점이 맞춰져 있었다.
- smaller-norm-less-important
- geometric median-based criterion
- determining those import feature maps
- capture rich and important information
Determining Importance: Intra-channel & Inter-channel Perspectives
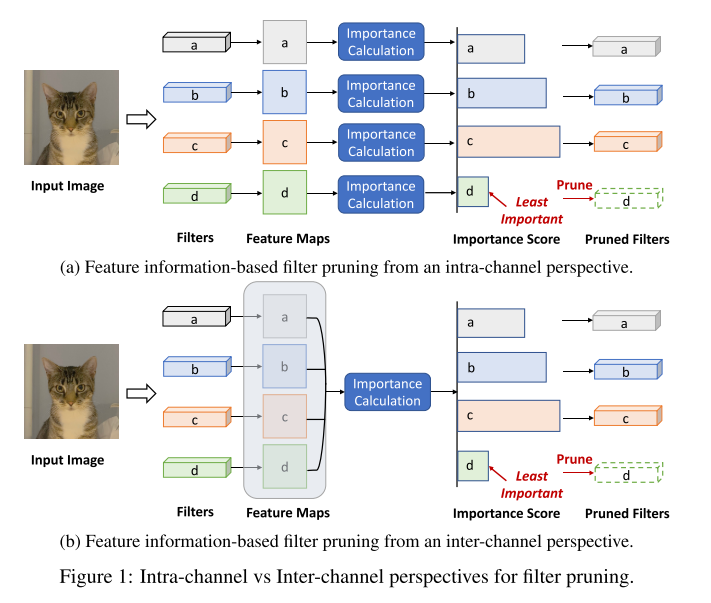
- Intra-channel
- 지금까지는 현재 채널 내부에서 중요도를 판단하였다.
- Inter-channel
- 여러 채널 간의 정보를 활용
Benefits of Inter-channel Perspective
- intra-channel 보다 더 풍부한 정보를 활용할 수 있다.
- inter-channel를 활용하는 구체적인 이유
- 하나의 채널에서의 feature map만을 활용하여 판단한다면 입력 데이터에 민감할 수 있으나 채널 간 feature map 정보를 활용하면 더 안정적이고 신뢰할만한 정보를 얻을 수 있다.
- filter pruning은 덜 중요한 필터를 찾는 것인데 다른 채널의 feature map을 활용한다면 잠재적으로 불필요한 것을 찾을 수 있어서 더 성능이 좋다.
Technical Preview and Contributions
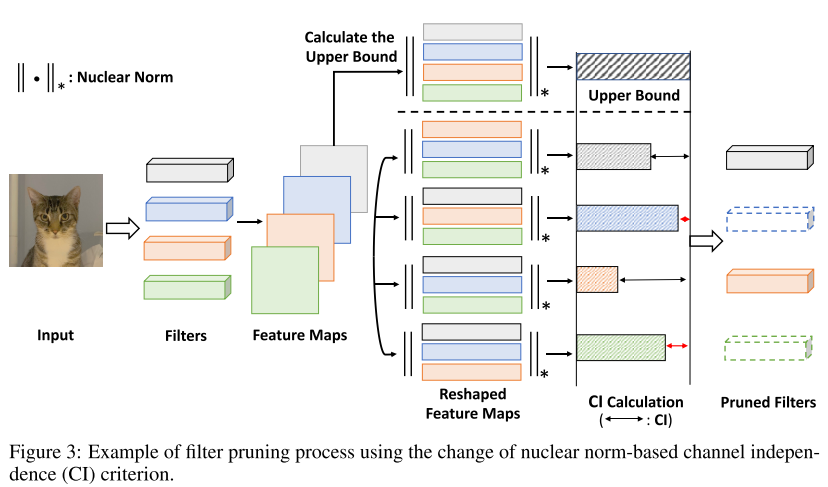
- 우리는 Channel Independece를 활용하여 filter pruning을 하며 이는 채널 간의 연관성을 기반으로 한 metrics이다.
- Channel Independence가 낮다는 것은 다른 feature map이 이를 대신할 수 있다는 것을 의미한다.
- Contributions
- channel independence를 제안하며 이는 기존 방식보다 더 넓고 정확한 방식으로 filter의 중요도를 판단할 수 있다.
- 시스템적으로 효율적인 channel indepence를 계산하기 위해 적은 비용이 소모되고 강건한 계산 방법을 제안한다.
- CIFAR10 dataset에 대해서 ResNet-56, ResNet-110 모델에서 좋은 성능과 ImageNet dataset에서 ResNet-50 모델에서 좋은 성능을 얻었다.
2. Preliminaries
Filter Pruning
- l-th convolutional layer
- optimization problem
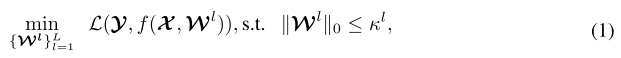
→ L : loss function
→ y : ground-truth labels
→ x : input data
→ f : output function of CNN model
→ the number of non-zero filters
Feature-guided Filter Pruning
- loss function
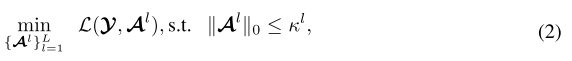
→ A : a set of feature maps output
3. The Proposed Method
3.1 Motivation
- state-of-arts를 살펴보면, 각각의 feature map에 있는 정보를 활용하여 중요도를 판단한다.
- 현존하는 filter pruning 에서는 이를 거의 사용하지 않는다.
Why Inter-channel Perspective?
- 채널 내에서만 중요도를 판단한다면 데이터에 따른 민감하고 불안정하지만, 채널 간 중요도를 본다면 더 신뢰할 수 있고 안정적으로 중요도를 판단할 수 있다.
- 채널 간 연관성은 더 좋은 모델을 찾을 수 있게 할 수 있다.
3.2 Channel Independence: A New Lens for Filter Importance
Key Idea
- channel independence로 각각의 feature map의 중요성을 판단한다.
- linearly dependent 하다면 중요하고 그렇지 않다면 다른 것으로 대체될 수 있기 때문에 모델에 성능에 영향을 작게 준다는 아이디어
How to Measure Channel Independence?
Q1. which mathematical metric should be adopted to quantify the independence of one feature map from other feature maps?
Analysis
- feature map set
- 직관적인 방법 (L0 norm)(singular value의 개수 = rank)
- rank를 사용하여 linearly independent rows/columns 개수를 찾는다.
- orignal feature map의 rank를 구한 후 row를 각각 하나씩 없앴을 때 rank 값과의 차이를 측정한다.
- rank의 차이가 적으면 덜 독립적이기 때문에 제거한다.
Our Proposal
- singular value의 nuclear norm)
- nuclear norm = singular value의 합
- 이 방법은 하나의 행의 영향을 더 풍부한 부드러운 값으로 얻을 수 있게한다.
- rank와 달리 하나의 행을 제거했을 때 값의 차이가 크게 다르다. → 좀 더 미세하게 independent한 feature map을 찾을 수 있다.
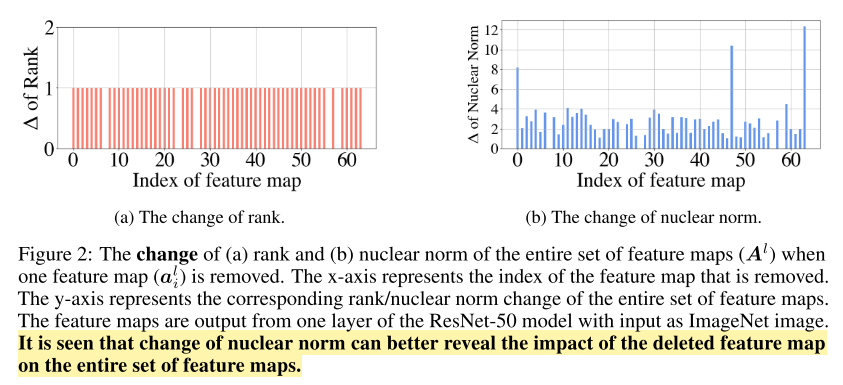
1. 한 행씩 없애고 원본 nuclear norm과 없앴을 때의 nuclear norm을 비교하여 그 차이를 측정한다.
2. 차이가 적으면 덜 독립적이기 때문에 제거한다.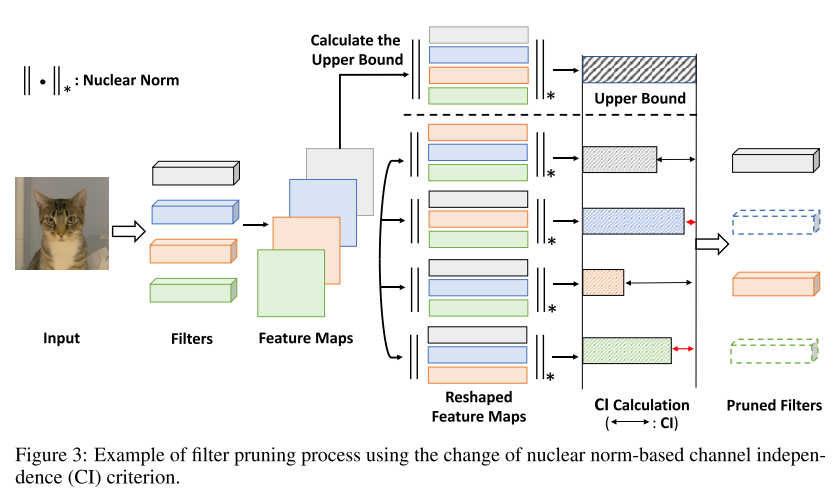
Q2. What is the proper scheme to quantify the independence of multiple feature maps?
Analysis

- 다음 수식을 활용하여 masking을 통해 CI(Channel Independence)를 구한다.
- 실제로는 feature map set에서 여러개의 불필요한 feature map을 선택해야하는데 이를 일일히 masking을 통해 찾으면 너무 시간이 오래걸린다.
Our Proposal
- 하나의 행씩 없애서 원본과 차이를 구해서 CI를 측정한다음 그 값이 작은 것부터 차례로 제거하려는 개수만큼 제거한다.

- 다음과 같이 근사화한 것이다.
Q3. How is the sensitiveness of channel independence related to the distribution of input data?
Our Observation
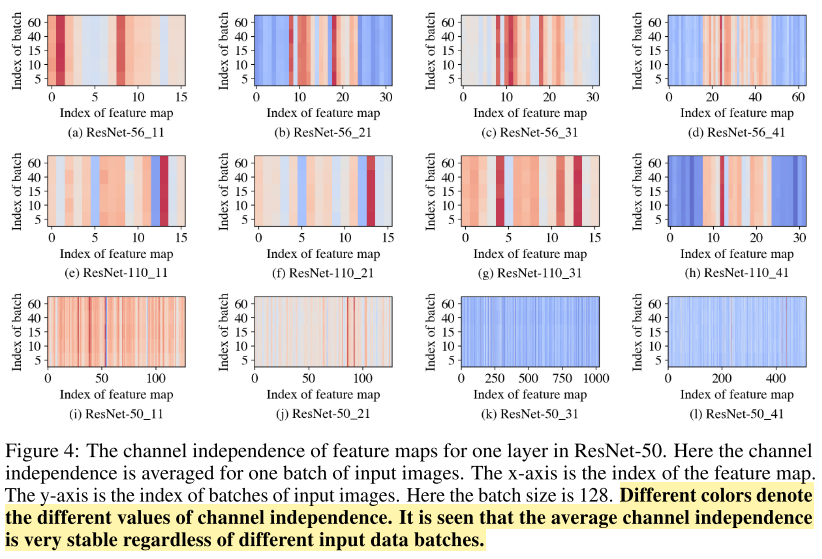
- batch level에서의 input data만으로도 channel independence의 평균값과 비슷한 결과가 나오는 것을 확인할 수 있다.
Q4. Is this one-shot importance determination scheme good enough? Do we need to further learn and adjust the pruning mask from the data?
Our Observation
- 제안한 방식을 원-샷이 아닌 학습기반의 방식을 통한다면 추가적인 성능 향상을 있을 것으로 기대되지만, 우리의 경험적인 평가로는 연속적인 학습 절차가 쉽게 정확도를 향상시키거나 압축률을 높이지는 못한다.
- 우리의 가설은 한번의 nuclear norm을 활용한 channel independence 측정 값이 고품질이라는 것이다.
The Overall Algorithm

4. Experiments
4.1 Experimental Settings
Baselines Models and Datasets
- Dataset
- CIFAR10
- ResNet-56
- ResNet-110
- VGG-16
- ImageNet
- ResNet-50
- CIFAR10
Pruning and Fine-tuning Configurations
- V100 GPUs
- Pytorch 1.7
- CI를 측정하기 위해 5 batch (640 input image)의 CI 값을 평균함 → Batch size = 128
- SGD
- CIFAR-10
- fine-tuning : 300 epochs
- batch size : 128
- momentum : 0.9
- weight decay : 0.05
- initial learning rate : 0.01
- ImageNet
- fine-tuning : 180 epochs
- batch size : 256
- weight decay : 0.99
- initial learning rate : 0.1
4.2 Evalutaion and Comparison on CIFAR-10 Dataset

- two scenarios
- 높은 정확도 목표
- 높은 model size와 FLOPs 감소 목표
- ResNet-56
- 우리의 방식은 비슷한 모델 크기와 계산량에서 HRank보다 1.33% 더 높은 정확도를 가진다.
- ResNet-110
- 우리의 방식은 baseline model보다 0.13% 더 높은 성능을 가진다.
- VGG-16
- 우리의 방식은 비슷한 압축률에서 1.38% 더 높은 성능을 가진다.
- 더 높은 압축률에서도 이전의 HRank보다 2% 더 높은 성능을 가진다.
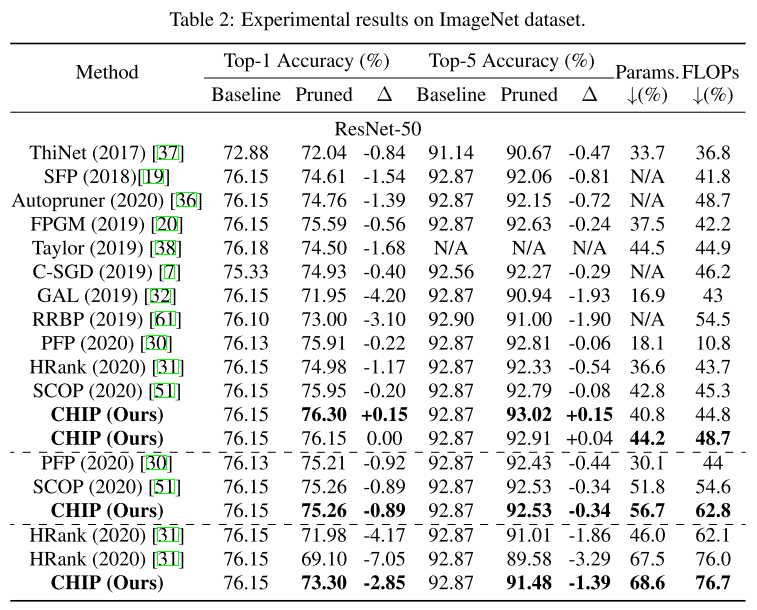
4.3 Evalutaion and Comparison on ImageNet Dataset
5. Conclusion
- 우리는 Channel independence를 제안하며 이는 채널 간 관점에서 중요도를 평가한다.
- channel independence의 quantification metric, 측정 체계와 민감도와 신뢰성을 체계적으로 탐색함으로서 우리는 CHIP(CHannel Independence-based filter pruning for neural network compression)을 개발했다.
- 다양한 모델과 데이터셋에 대한 실험을 통해 모델의 성능 유지하며 눈에 띄는 압축을 보여준다.
