[논문리뷰] Pruning-as-Search: Efficient Neural Architecture Search via Channel Pruning and Structural Reparameterization
논문리뷰
목록 보기
3/8
Abstract
- NAS는 모델을 찾는데 엄청난 cost가 소모된다.
- structured pruning은 layer당 filter를 얼마나 줄일지 자동화하는 것이 쉽지 않다.
- 이 논문에서는 Pruning-as-Search(PaS)를 제안하여 layer당 filter의 압축률을 자동으로 최적화하고 end-to-end로 기법을 적용하여 효율화한다.
- pruning policy를 학습하기 위해 depth-wise binary convolution을 추가하였다.
- structural reparameterization을 결합하였다.
- 실험을 통해 비슷한 inference 속도로 1.0% top-1 accuracy 향상을 이뤘고, instance segmentation과 image translation에도 적용하였다.
1. Introduction
- NAS는 모델의 depth와 with를 자동으로 찾지만 큰 searching overhead가 있다는 단점이 있다.
- network pruning(structured pruning)은 자동적으로 layer-wise pruning ratio를 결정하기 어려움을 겪고 있다.
- PaS는 end-to-end channel pruning 방법으로 기존과 비슷한 훈련 cost를 가지면서 자동으로 sub-network를 찾는다.
- 우리는 depth-wise binary convolutional(DBC) layer를 각 convolutionaly layer 뒤에 적용하여 pruning indicator로 활용한다.
- DBC layer의 훈련능력을 위해 Straight Through Estimator(STE)를 적용하였다.
- PaS는 잘 학습된 network로 시작하여 fine-tuning 한번만 추가로 필요하다.
- PaS는 magnitude trap에서 벗어나있다는 장점이 있어 이전의 pruning method와는 차이가 있다.
- flexibility of layer width를 위해 identiccal path를 CONV layer에 reparameterize하여 없앴다. 이는 inference할 때 sub-networks의 residual connection을 없애는 것이다.
main contribution
- DBC layer를 활용하여 pruning policy를 학습하여 PaS를 개발하였다.
- width optimization에 처음 structural reparameterization을 적용하였다.
- 우리의 width search와 reparameterization을 통해 새로운 backbone을 만들었다.
2. Related Work
Neural Architecture Search (NAS)
- NAS는 인간의 개입없이 최적의 network를 찾는 방법이다.
- 이전에는 RL-based, evolution-based가 연구되었는데 이는 긴 searching time이 필요하다.
- Gradient-based는 더 빨리 찾도록 설계되었다.
- 이러한 방법은 근사화 작업을 수행하거나 큰 메모리 용량을 필요로 한다.
Network Pruning
- unstructured와 structured pruning으로 나뉘어 있는데 unstructured pruning은 높은 압축률을 가질 수 있지만 가속하기 힘들고 structued pruning은 전체 filters/channels를 제거하기 때문에 가속이나 저장 공간을 줄일 수 있다.
Structural Reparameterization
- origin architecture의 정확도를 향상시키거나 branch operator를 mainstream operator와 결합하여 가속하기 위해 소개되었다.
- 훈련 때에는 residual connection의 이점을 사용하지만 배포할 때는 residual connection을 사용하지 않는다.
3. Challenges and Motivations
- C1 : Tremendous searching cost for NAS
- C2 : magnitude trap in pruning
- C3 : rgid width constraint
3.1 Tremendous Search Cost for NAS
- 후보군이 많을수록 저장 공간이 많이 필요하다.
3.2 Magnitude Trap for Pruning
- 일반적으로 filters/channels가 작은 magnitude를 가지면 최종 정확도에 덜 영향을 줄거라고 하여 제거한다.
- 이러한 방법은 반드시 참이 아니고, small channels를 바로 제거하면 정확도에 영향을 줄만큼 커질 기회를 없애는 문제가 발생하며 이를 Magnitude trap이라고 한다.
3.3 Rigid Width Design
- ResNet에는 residual connection이 있다. 이는 입력 차원과 출력 차원이 같아야한다는 제한이 생긴다. 이는 design flexibility를 감소시킨다.
3.4 Motivation
- 이전의 어려움을 극복하기 위해 PaS는 자동으로 모델의 width를 찾고 structural reparameterization에 기반한 새로운 pruning-deployment paradigm을 통해 새로운 차원의 layer 당 width 설계 유연성을 발휘한다.
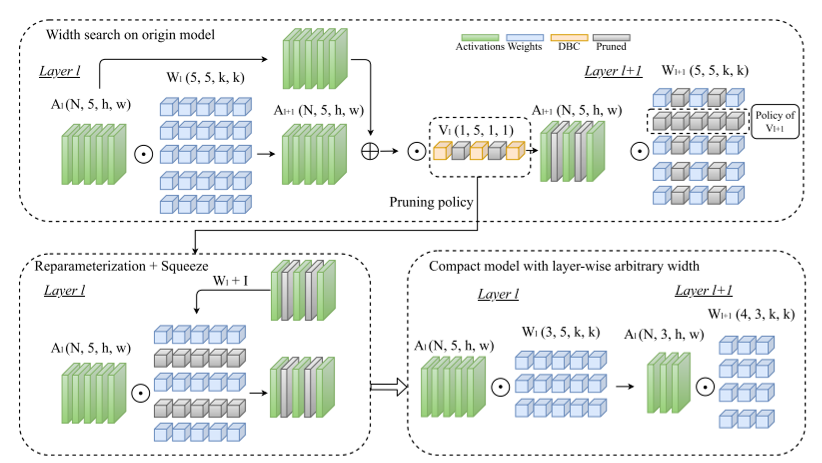
4. Pruning as Search Algorithm
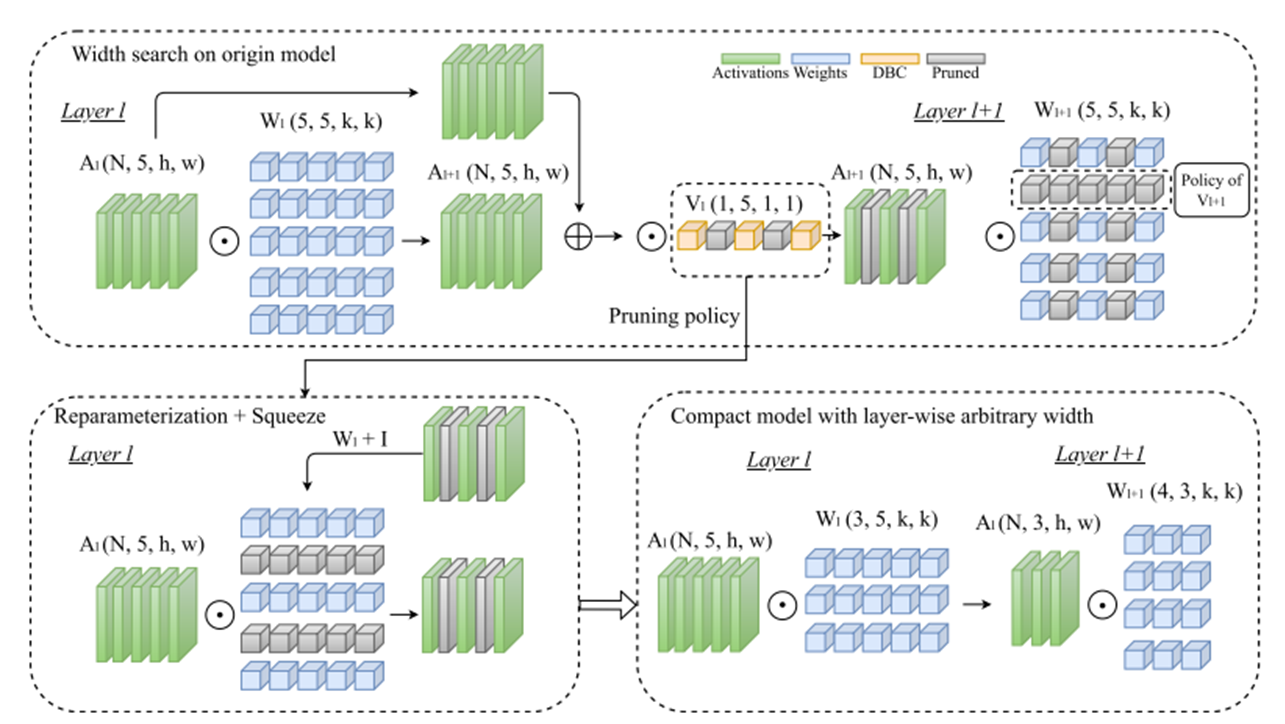
4.1 Depth-Wise Binary Convolution Layers
- automatic channel pruning을 위해 depth-wise 1x1 convolution layer을 사용하였다.
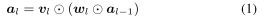
- 은 depth-wise convolution layer의 파라미터로 이를 이용하여 pruning indicator로 삼았다.
- 하지만 여기서 의 binarization으로 미분이 0이라서 backpropagation에서 문제가 발생하는데 이는 Straight Through Estimator(STE)을 이용하여 해결하였다.
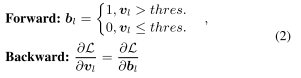
- thres는 0.5로 하여 0과 1로 값을 이진화하였다.
- 이를 통해 pruning policy와 network의 parameter 학습을 분리하였다.
- STE와 DBC layer를 결합하여 2가지 효과를 얻었다.
- pruning policy와 model parameter 학습 문제를 분리하였다
- DBC layer에서 gradient가 0으로 흐르지 않게 하여 pruned channel의 정보를 보존하였다.
- pruned 모델을 적용하기 위해서 DBC layer의 이진화 값을 이용하여 그룹화하고 없애는 단계가 필요하다.
- 이를 위해 이진화 값이 0인 것은 앞쪽으로 하고 1인 것은 뒤쪽으로 재구성한다.
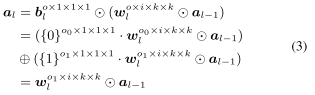
- 이를 위해 이진화 값이 0인 것은 앞쪽으로 하고 1인 것은 뒤쪽으로 재구성한다.
4.2 Training Loss Function
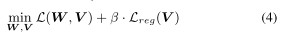
- 앞쪽 항은 모델 학습 시 loss이고 뒤쪽은 계산 복잡도에 관련된 regularization 항이다.
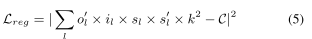
- 이는 현재 MACs와 목표 MACs 사이의 norm의 제곱으로 정의한다.
4.3 Simultaneous Pruning and Training for C1
- 우리의 end-to-end channel pruning 방식은 DBC와 STE를 활용하여 모델의 학습과 pruning indicator 학습을 동시에 할 수 있다.
- 따라서 학습 과정에서 효율성을 가져온다.
4.4 DBC Layer as Indicators for C2
- DBC layer는 pruning indicator로서 2가지 장점이 있다.
- SGD를 활용하여 자연스럽게 학습이 가능하며 이를 통해 pruning policy도 학습동안 역동적으로 업데이트된다.
- STE를 활용하였기 때문에 DBC layer에 의해서 pruning된 채널은 forward에서도 사용되지 않고 backward에서도 업데이트 되지 않는다.
- 이는 결과적으로 모델 원본 weight를 파괴하는 soft-mask와 구별된다.
4.5 Structural Reparameterization for C3
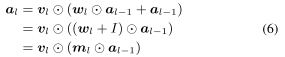
- 이는 skip connection이 하나의 convolution만 건너서 연결할 때 가능하기 때문에 기존의 ResNet을 사용하는 것이 아니라 RepVGG에서 제시한 모델 RepVGG-B1 모델을 사용한다.

- Add 연산 이후 DBC layer를 두어 reparameterization이 가능하도록 한다.
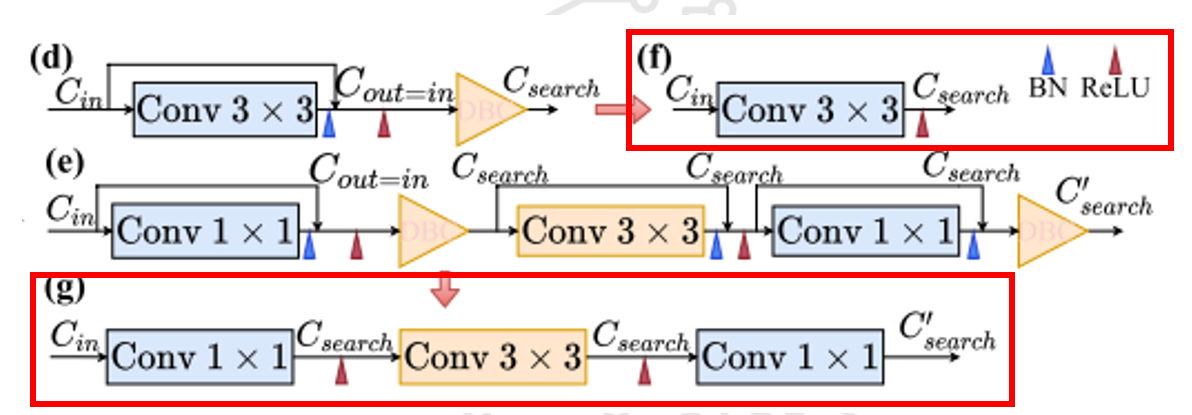
- 이 과정 이후 skip connection을 제거하여 압축모델을 만들어서 추론 속도를 가속한다.
전체 흐름
5. Experimental Results


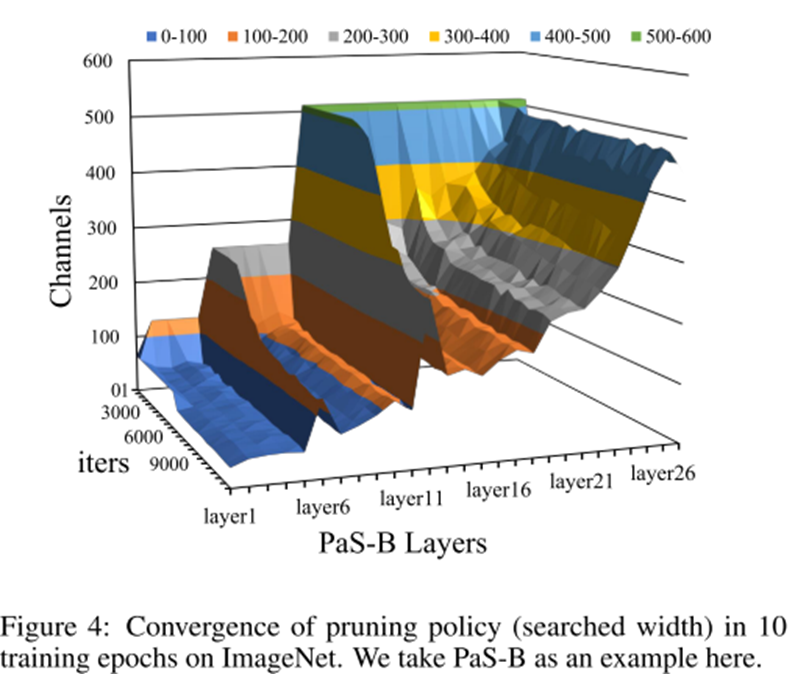
-
10 epochs면 모델이 수렴한다는 것을 보이며 이를 활용하여 10 epochs동안 모델을 찾고 50 epoch 동안 fine-tuning을 진행한다.
-
다음은 PaS-A, PaS-B, PaS-C의 모델이다. 이는 RepVGG-B1 모델을 경량화한 것이다.
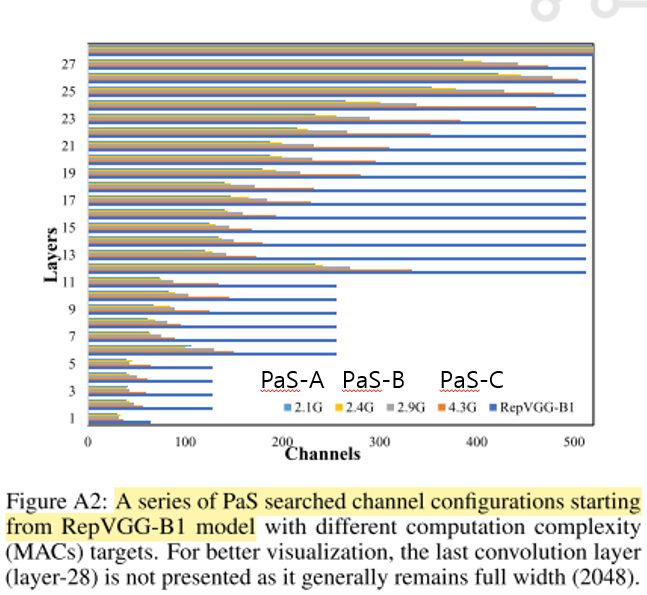
-
다음은 PaS-light-A, PaS-light-B, PaS-light-C이다.
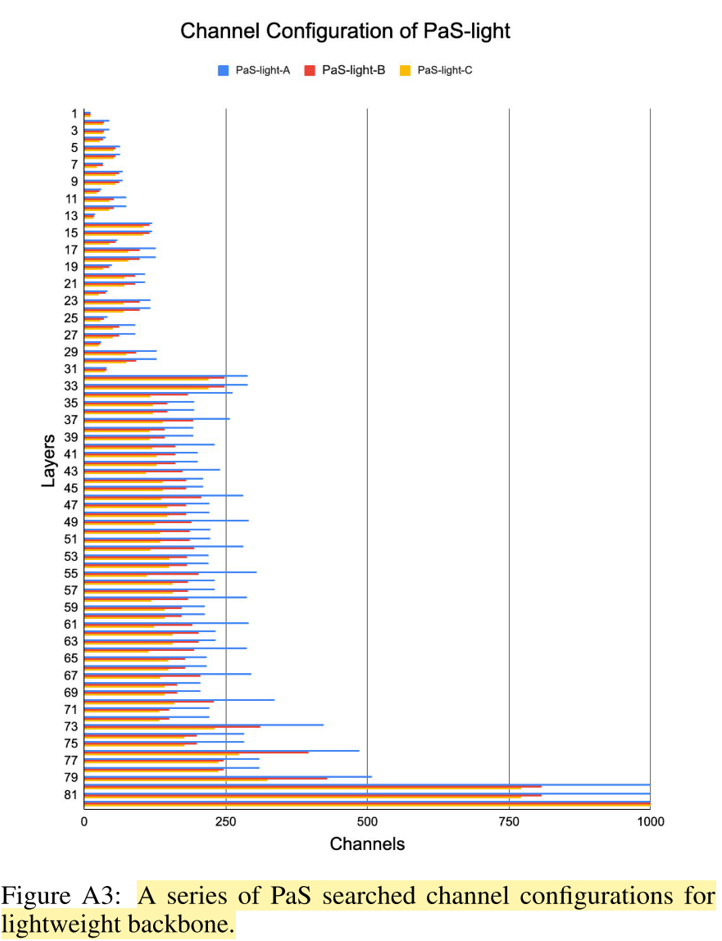

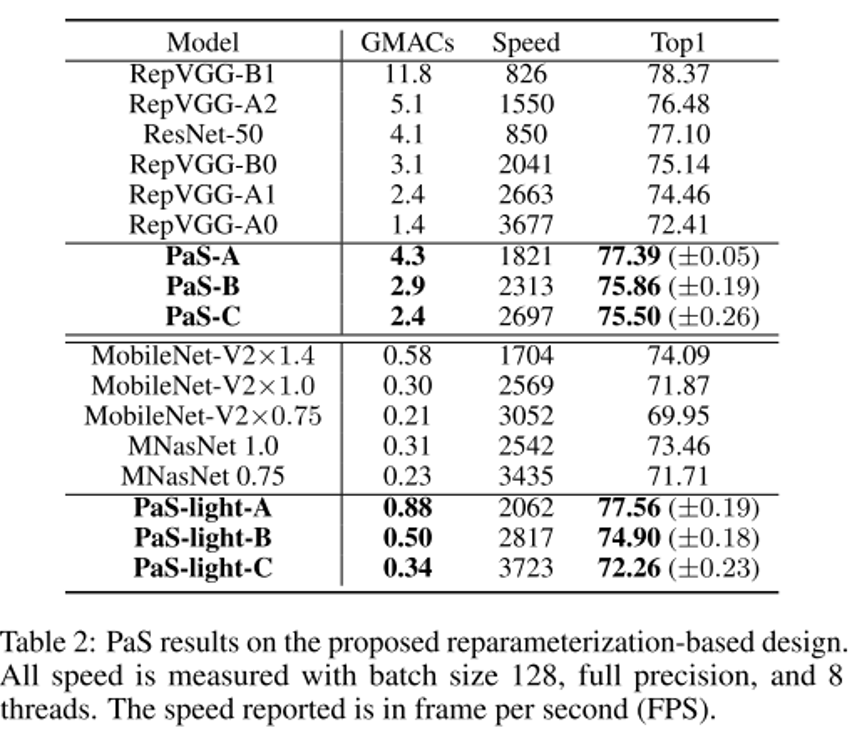
- ResNet-50의 성능과 inference speed를 능가하는 것으로 보아 RepVGG의 가능성을 보여준다.

- 위 그림을 보면 PaS-B는 RepVGG-B0보다 앞쪽 layer가 좁고 마지막 layer는 큰 것을 알 수 있다. 이는 뒤쪽 마지막 레이어가 고차원 특징을 추출하고 per-MACs-information에 더 기여한다는 것을 의미한다.

- YOLACT을 압축하고 Mobile-ResNet을 backbone으로하는 CycleGAN을 압축한 결과이다.

Conclusion
- 효율적이고 강인한 PaS를 제안하였다.
- reparameterization와 PaS를 결합하여 새로운 reparameterization-based networks를 만들었다. 이는 residual connection의 장점을 학습에 살리고 이를 reparameterization하여 inference시 없어지도록 하여 가속한다.
