Overview
- ViT는 transformer만을 사용하여 컴퓨터 비전에 적용하여 CNN의 SOTA 성능을 넘은 최초의 논문
- transformer 모델은 inductive biases가 부족하기 때문에 아주 방대한 데이터셋 학습을 통해 이를 해결
Problem to solve
- self-attention을 활용하여 컴퓨터 비전 분야의 모델에 적용하려고 하지만 최신 하드웨어 가속기에서는 특수한 attention patterns 때문에 아직 효과적으로 적용되지 않고 여전히 고전적인 ResNet과 같은 구조가 최고 성능을 달성하고 있다.
- Transformer는 translation equivariance(입력이 다르면 출력도 다름), locality(주변 픽셀들과는 서로 관련이 있음)와 같은 inductive biases가 부족하여 적은 데이터로 학습 시 일반화가 잘 되지 않는다.
Concepts
- 아주 방대한 데이터 셋(14M-300M)으로 학습한다면 inductive bias를 극복할 수 있다.
- CNN에는 locality, two-demensional neighborhood structure, translation equivariance의 inductive biases 존재
- ViT에서는 MLP layer만 locality와 translationally equivariant가 있고 self-attention layer는 global 하기 때문에 이러한 inductive biases가 없다.
- Two-dimentional neighborhood structure에 경우 ViT에서 아주 드물게 사용되는데 이는 처음에 image를 patch로 나눌 때와 fine-tuning을 위해 해상도가 변경될 때 사용됨. CNN과는 다르게 2D 위치에 대한 정보가 없으며 학습을 통해 배움.
- transformer 모델의 최소한의 수정으로 컴퓨터 비전 task에 맞게 수정하였다.
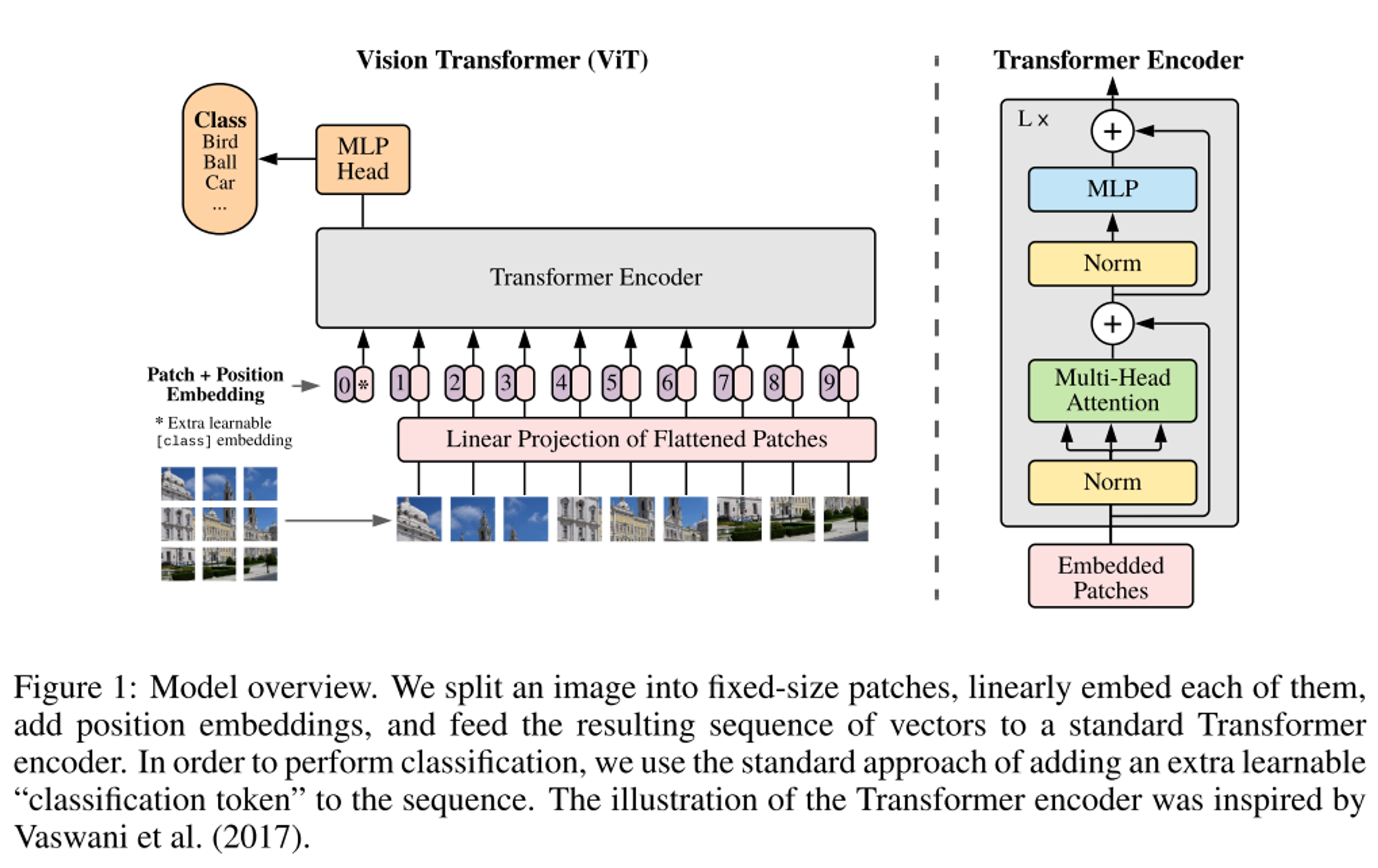
- BERT와 유사하게 class token을 추가하여 학습을 진행
- position embedding도 활용하였으며 2D-aware 보다 1D position embedding이 더 성능이 좋아 이를 사용ViT 구조 분석
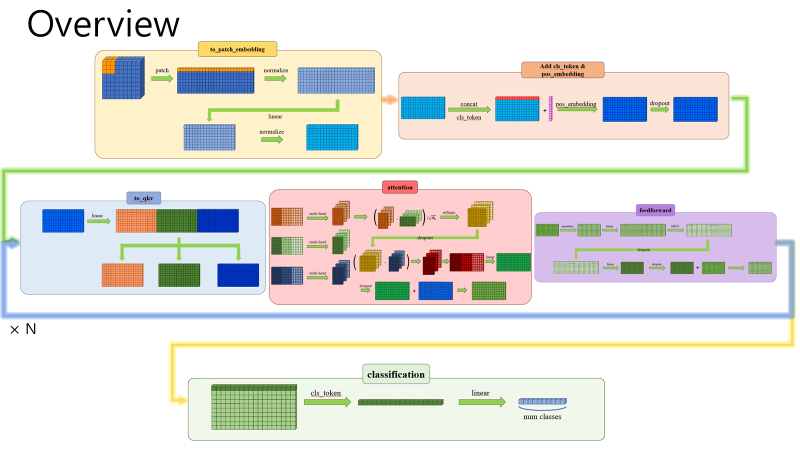
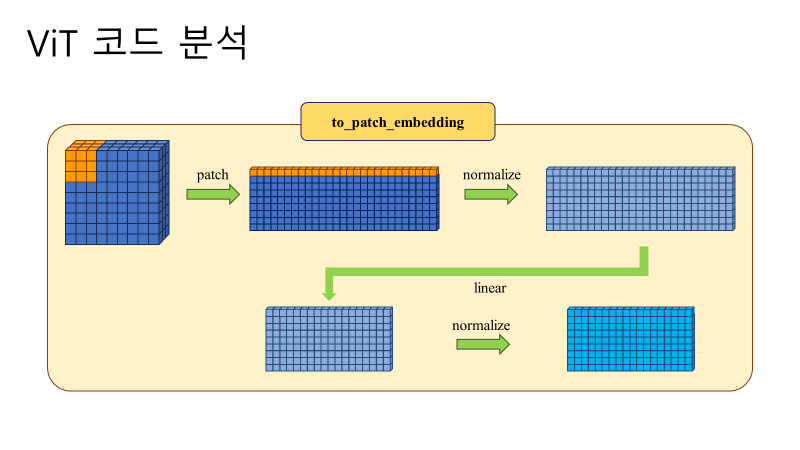
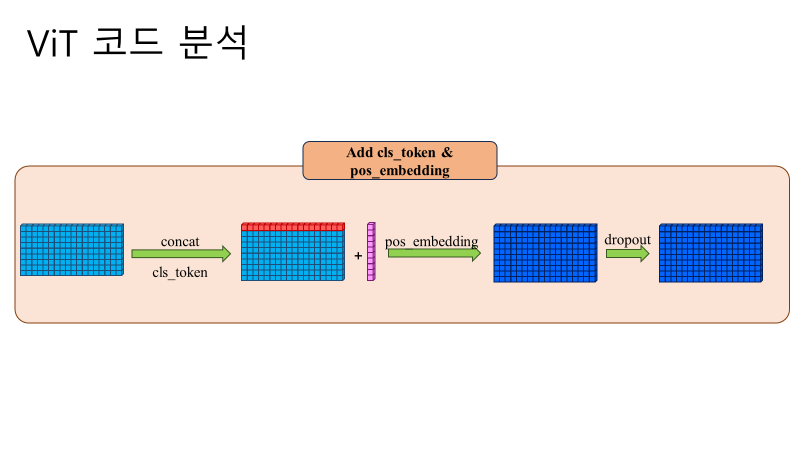

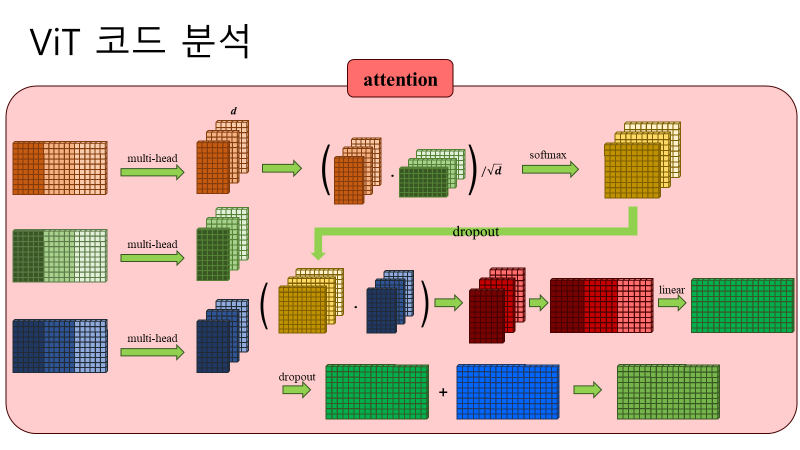


Results

- 기존의 CNN 기반의 SOTA 성능을 모두 뛰어넘는 것을 알 수 있다.
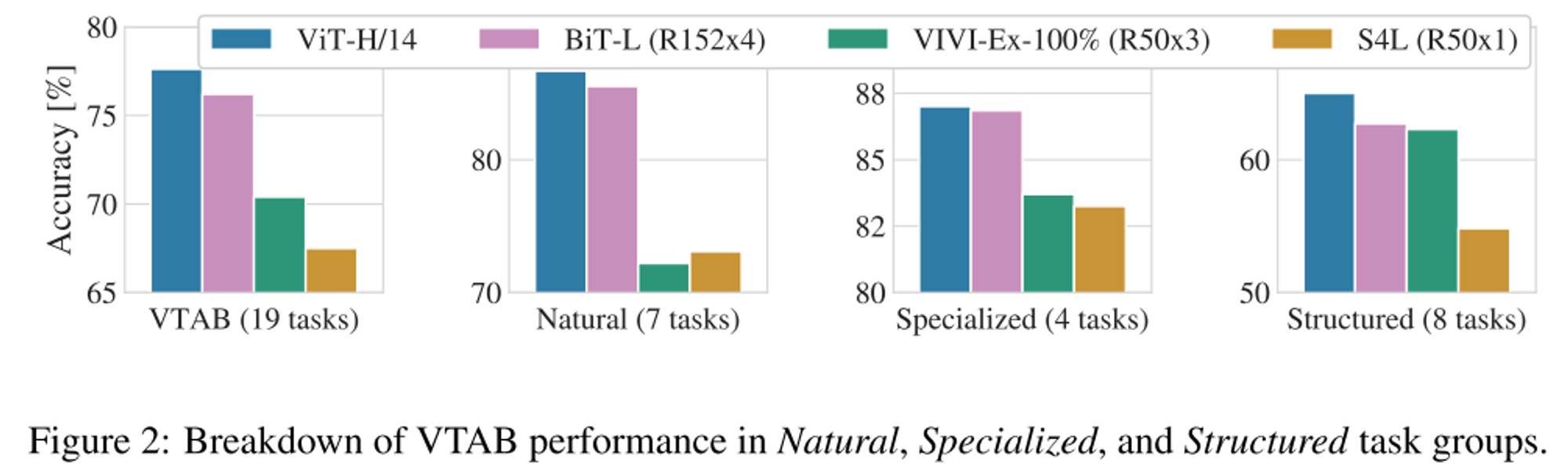
- VTAB task에서도 CNN기반의 BiT를 뛰어 넘는다.
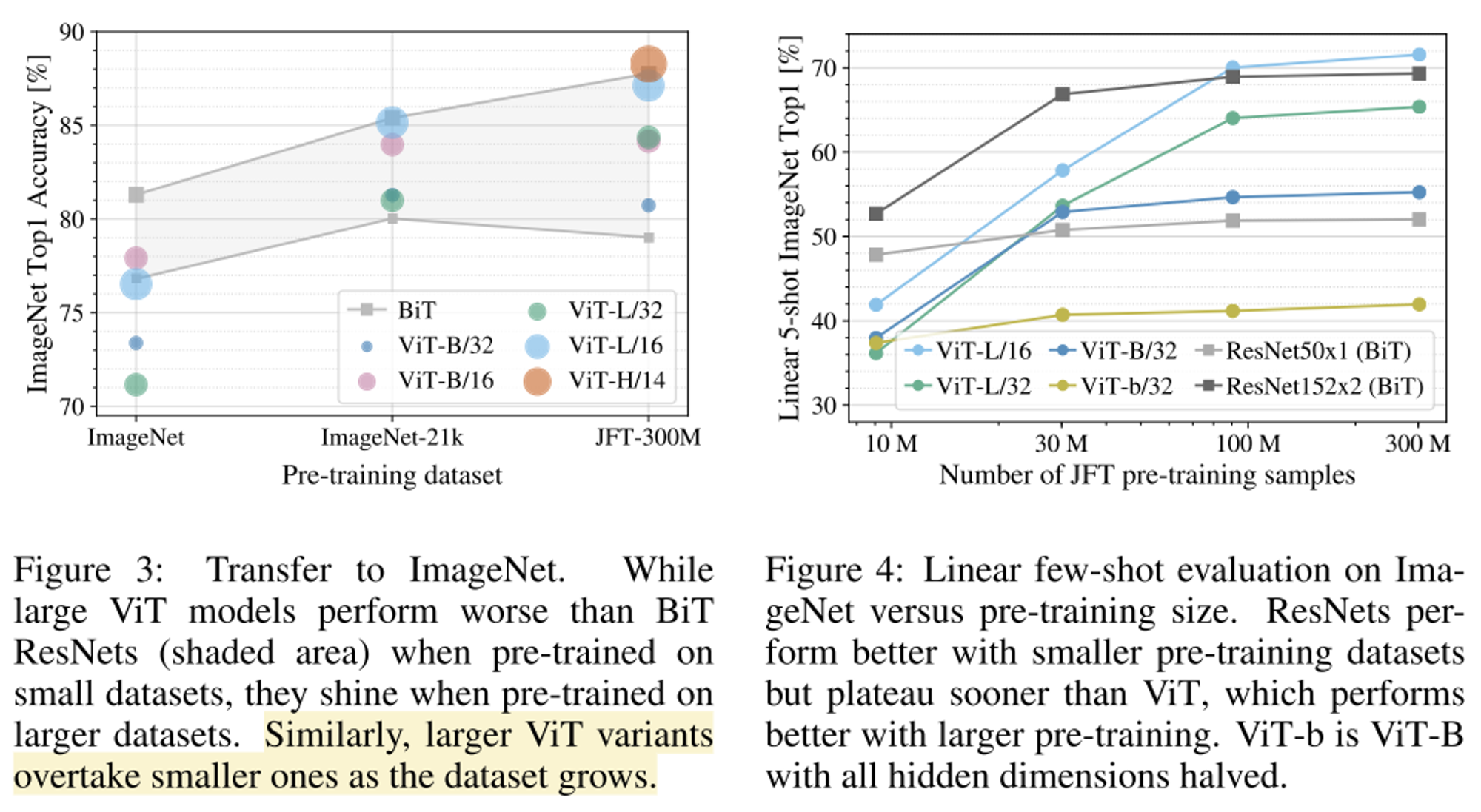
- pre-train 데이터 셋의 크기에 따른 성능 그래프로 가장 큰 JFT-300M 데이터셋을 활용하여 pre-train 했을 때 가장 성능이 높은 것을 확인할 수 있다.
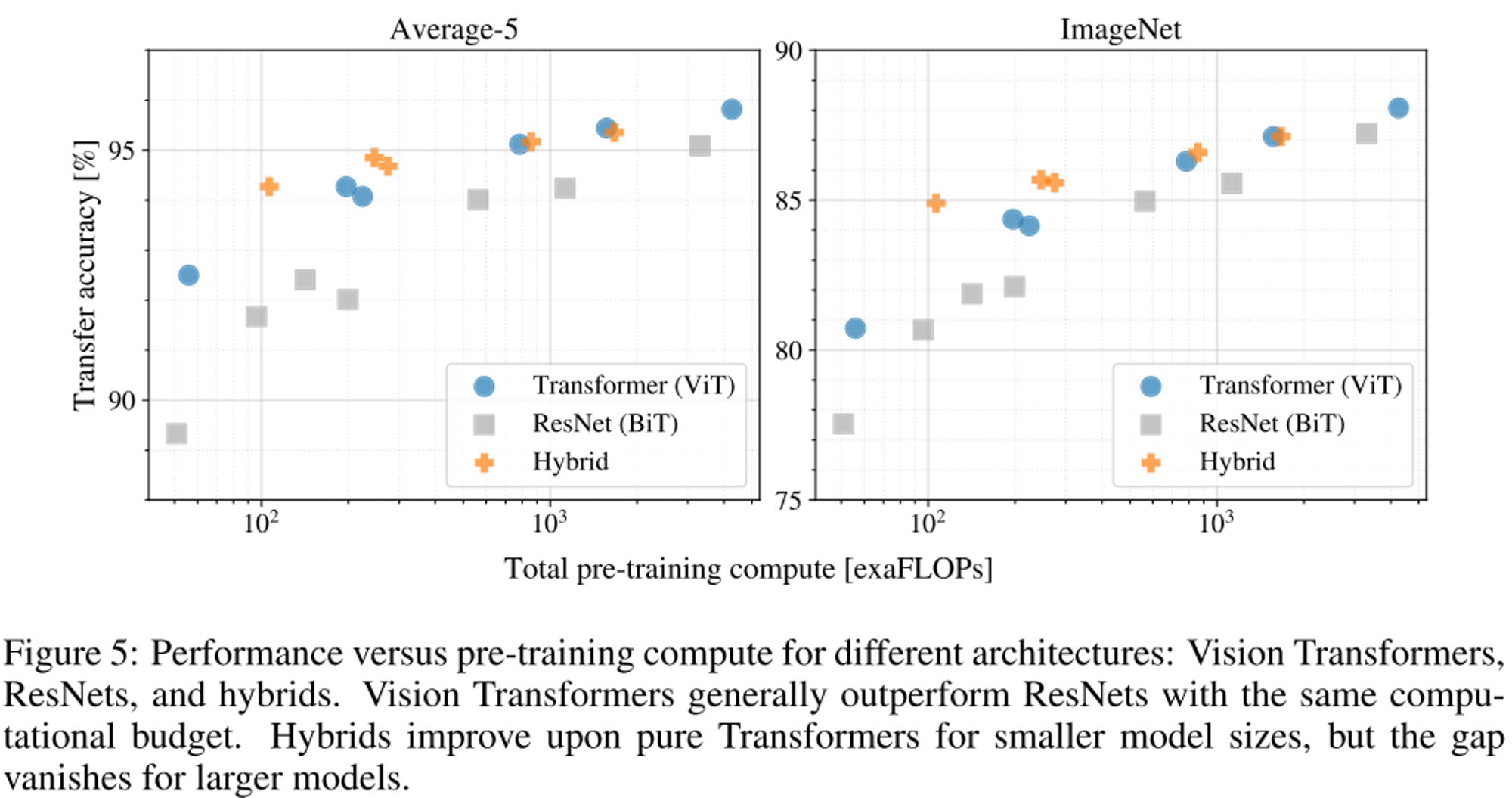
- ViT는 ResNet보다 같은 computational budget에서 높은 성능을 가지는 것을 확인
- hybrid 모델이 작은 모델에서는 성능이 높지만 모델 크기가 커지면 이 차이가 사라진다.

- position embedding이 위치에 맞게 잘 학습된 것을 확인
- mean attention distance는 CNN의 receptive field와 비슷한 개념으로 값이 낮으면 local 정보를 얻고 값이 크면 global 정보를 본다는 의미이다. 그래프를 보았을 때 얕은 레이어에서는 local 정보와 global 정보를 모두 보고, 깊은 레이어에서는 global 정보를 주로 본다는 것을 확인할 수 있다.
Notes and comments
- Transformer 모델을 컴퓨터 비전 모델에 도입하여 기존은 CNN의 SOTA 성능을 뛰어넘는 최초의 논문이다.
- transformer 모델에는 inductive biases(locality, two-dimension neighborhood dimension, translation equivariance)가 부족하기 때문에 성능이 낮았지만 아주 방대한 데이터셋 학습을 통해 이를 해결하였다.
- transformer 모델에서는 주로 global한 특징을 추출하기 때문에 이러한 inductive biases가 부족
- hybrid model이 모델 크기가 작을 때 transformer 모델보다 성능이 높다.
- transformer 모델은 얕은 레이어에서는 local, global 정보를 모두 보고, 깊은 레이어에서는 global 정보만을 본다.
