Overview
- 방대한 데이터 셋 없이 ImageNet 데이터 셋만으로 transformer 모델에서 높은 성능을 얻을 수 있다.
- distillation token을 도입하고 hard distillation 하는 것이 성능이 더 좋다.
- transformer 모델은 많은 데이터셋이 필요한데 이는 augmentation 기법을 통해 보완할 수 있다.
Problem to solve
- These highperforming vision transformers are pre-trained with hundreds of millions
of images using a large infrastructure, thereby limiting their adoption. - The paper(ViT) concluded that transformers “do not generalize well when trained on insufficient amounts of data”, and the training of these models involved extensive computing resources.
- ViT는 100M이 넘는 데이터 셋으로 학습해야지 높은 성능을 얻을 수 있으며 ViT 논문에서도 충분하지 않은 양의 데이터 셋으로는 모델이 일반화되지 않는다고 서술되어었다.
Concepts
- 기존 ViT 모델 구조 그대로 사용
- training 시에는 낮은 해상도의 이미지를 사용하고 fine-tuning할 때 높은 해상도를 사용하면 훈련 시간도 빨라지고 성능이 상승
- patch size를 똑같이 하기 때문에 patch의 개수가 달라지는데 이 때 positional embedding interpolation이 필요하다.
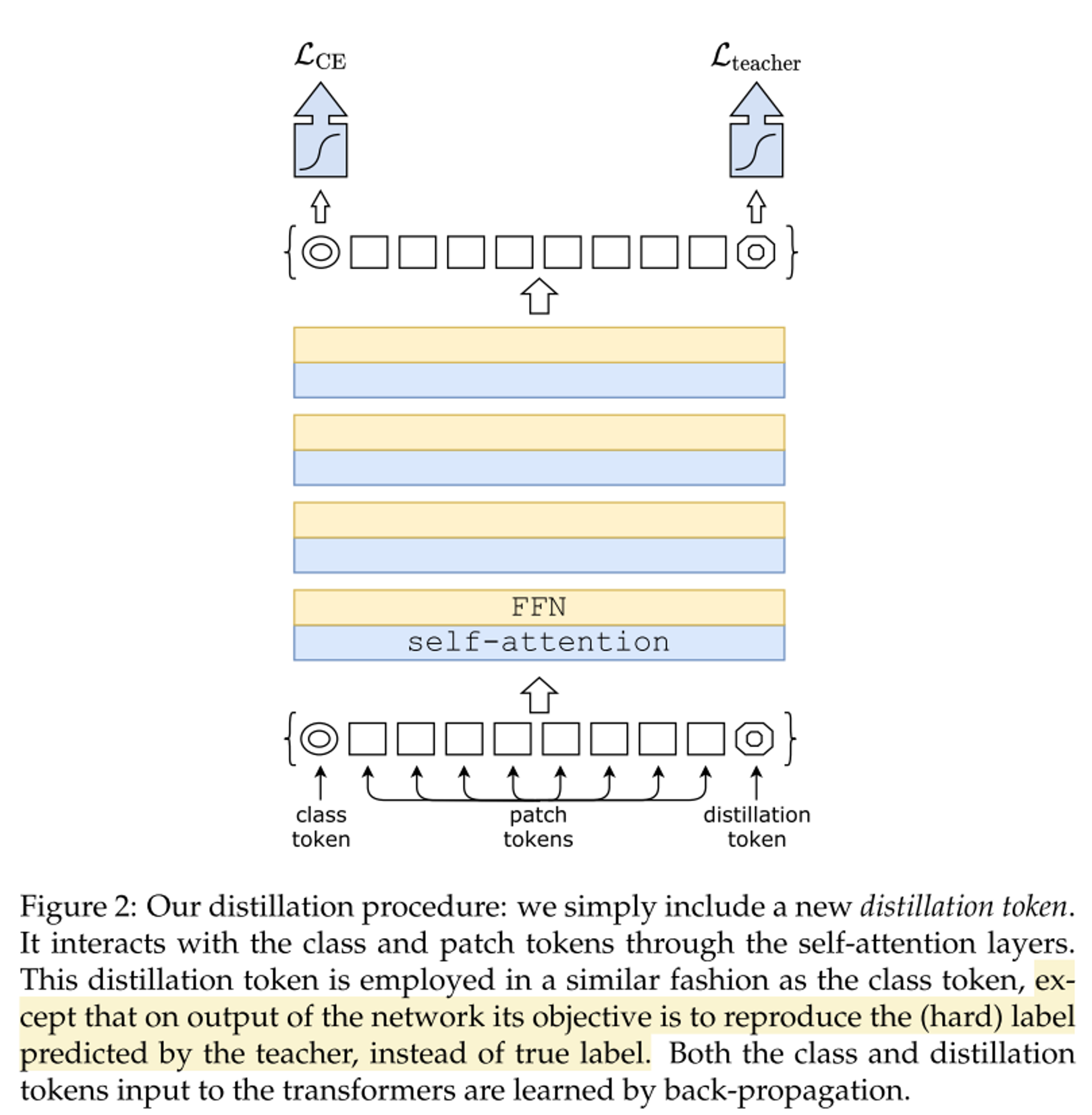
- Distillation token을 도입
- 정확도와 image throughput의 trade-off 관계를 참고하여 teacher model은 CNN 사용
- soft distillation vs hard-label distillation
- hard-label distillation에서도 label-smoothing을 사용하여 soft label처럼 수정했다. 이 기법은 정답을 1이 아닌 0.9로 바꾸고 남은 0.1을 나머지 label에 골고루 나눠주는 기법
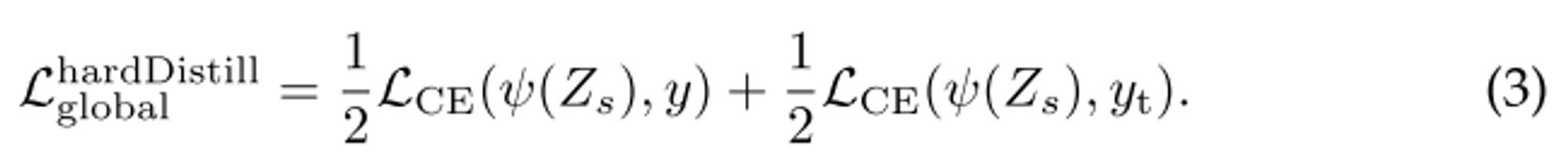
- hard-label distillation은 hyperparameter도 없고 간단하다.
- distillation token을 추가하여 이는 teacher model로부터 오는 label 활용
- cls token과 distill token은 유사도가 0.93으로 완전히 같지 않은 모습으로 나오며, 그냥 cls token을 2개 추가하여 했을 때는 0.99로 유사도가 1에 가까워 성능 향상에 효과가 없다.
- fine-tuning 할 때, 높은 해상도로 학습을 하는데 이 때 teacher 모델도 높은 해상도로 학습된 모델을 활용하여 teacher prediction을 사용하여 true label도 같이 사용한다.
- test 시 두 개의 classification token(cls token, distill token)이 나오는데 본 논문에서는 두 개의 토큰의 softmax 값을 더하여 예측하는 방식을 사용
- 8 GPUs 사용하여 2-3일 내에 학습 가능
Results
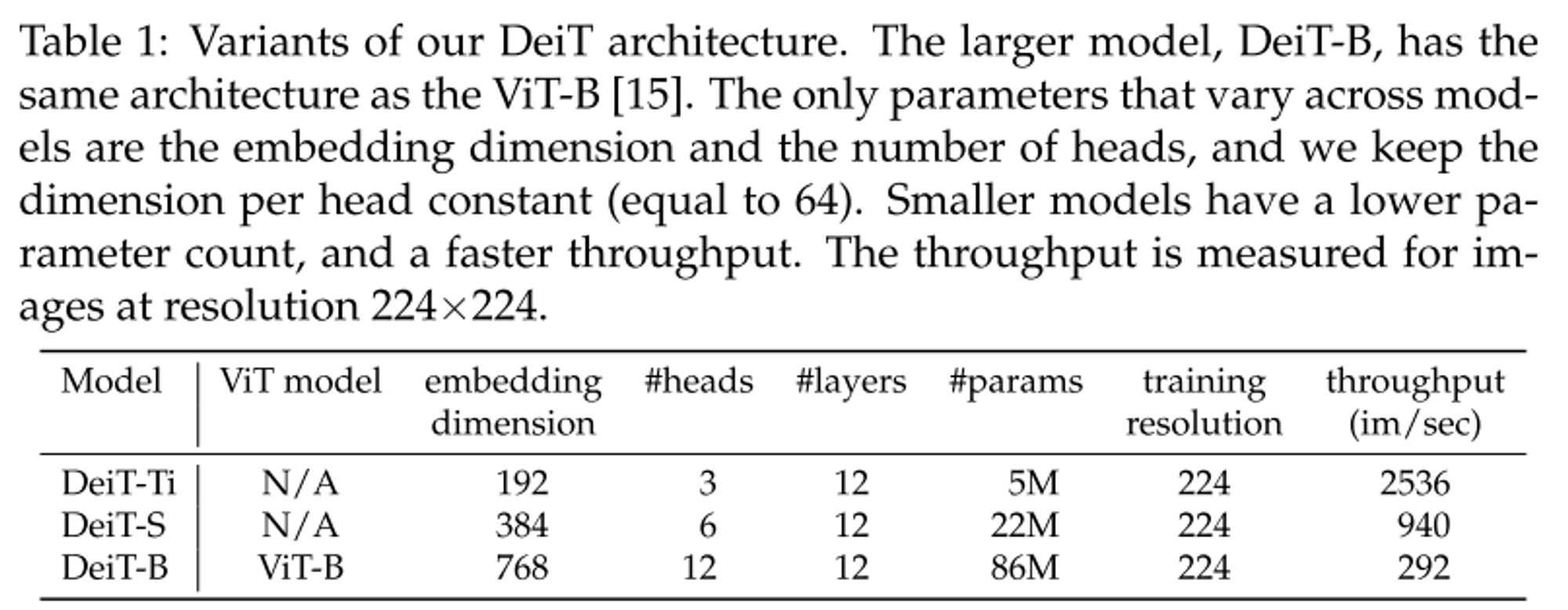
- DeiT의 다양한 모델 구성
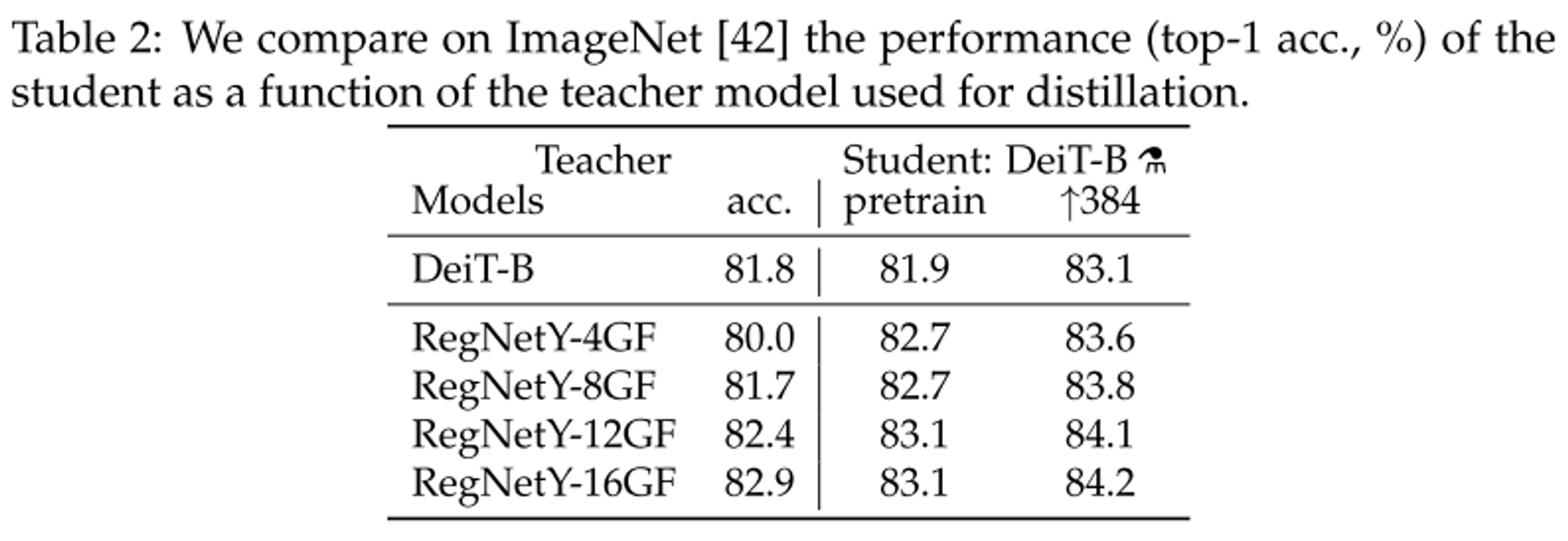
- Distillation 시 사용할 teacher model도는 transformer모델보다 CNN기반 모델을 사용하는 것이 더 높은 성능을 가진다.
- 이유는 CNN의 inductive bias를 활용할 수 있기 때문이다.
- 본 논문에서는 ResNetY-16GF 모델을 사용하였다.
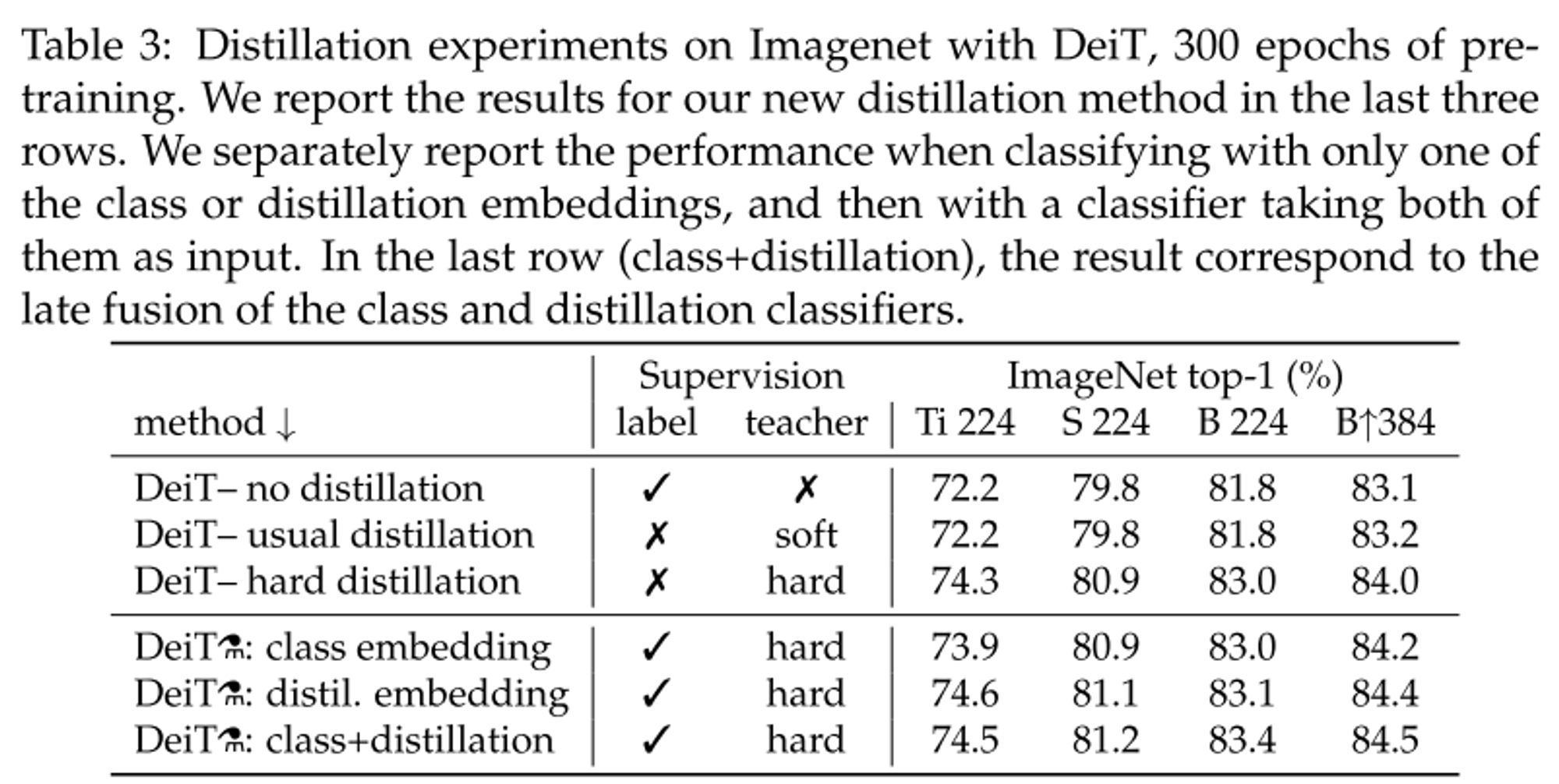
- 위쪽은 usual(soft) distillation과 hard distillation을 사용하였을 때 성능을 비교한 것으로 hard distillation이 더 높은 성능을 가진다는 것을 알 수 있다.
- 아래쪽은 distillation token을 사용하였을 때의 성능 비교이며, distillation token을 사용하였을 때 더 좋은 성능을 가진다.
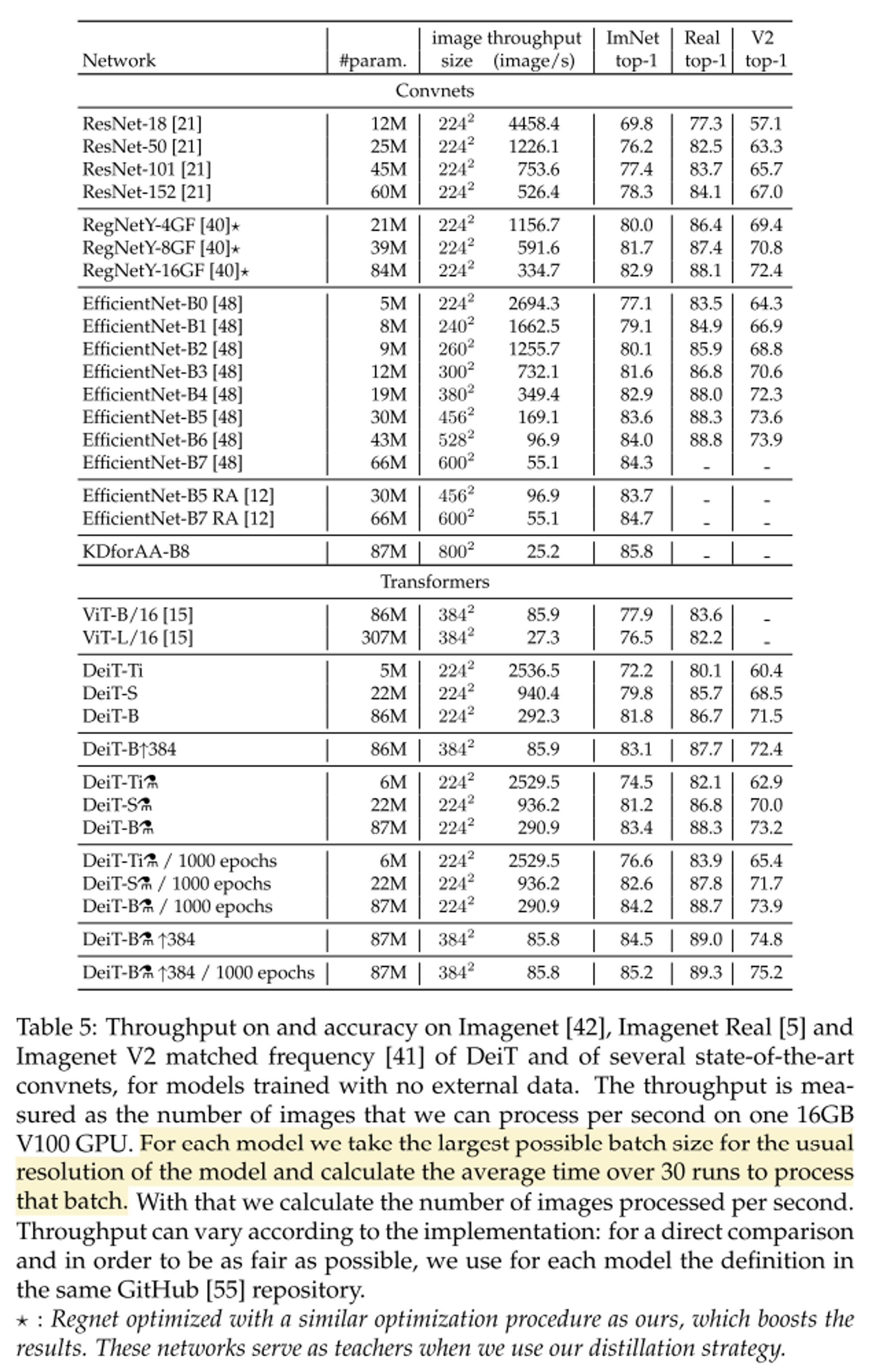
- ViT를 ImageNet만으로 학습한 모델과 비교했을 때 성능이 아주 높은 것을 확인할 수 있다.

- distillation은 사용하지 않은 모델은 400 epoch 이후에서 성능이 saturate되는 것을 확인할 수 있는데 distillation을 활용하면 그렇지 않기 때문에 더욱 성능이 높아질 수 있다.
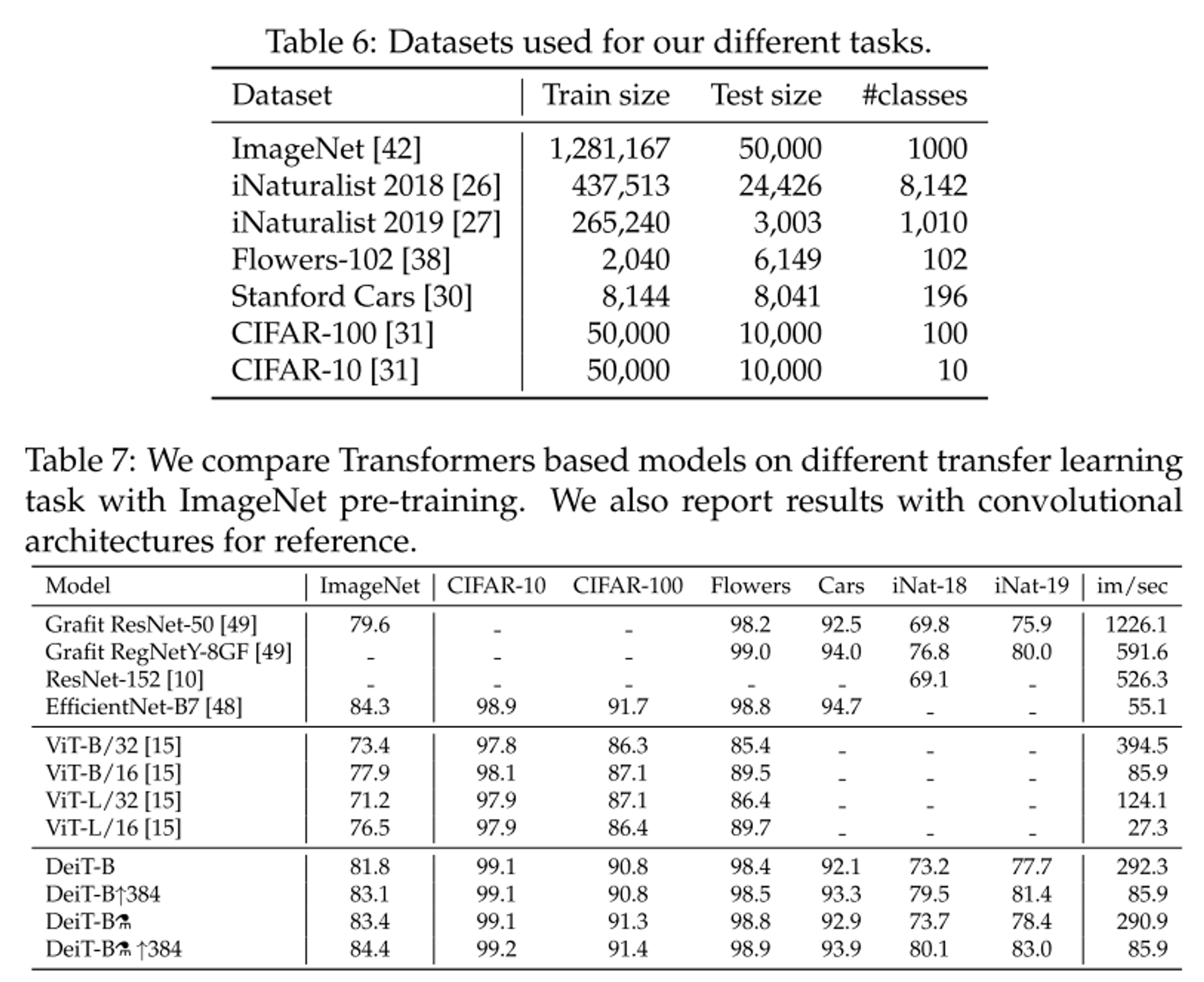
- 우리의 모델을 활용하여 fine-tuning을 진행하였을 때에도 높은 성능이 나오는 것을 확인할 수 있다.
Ablation study
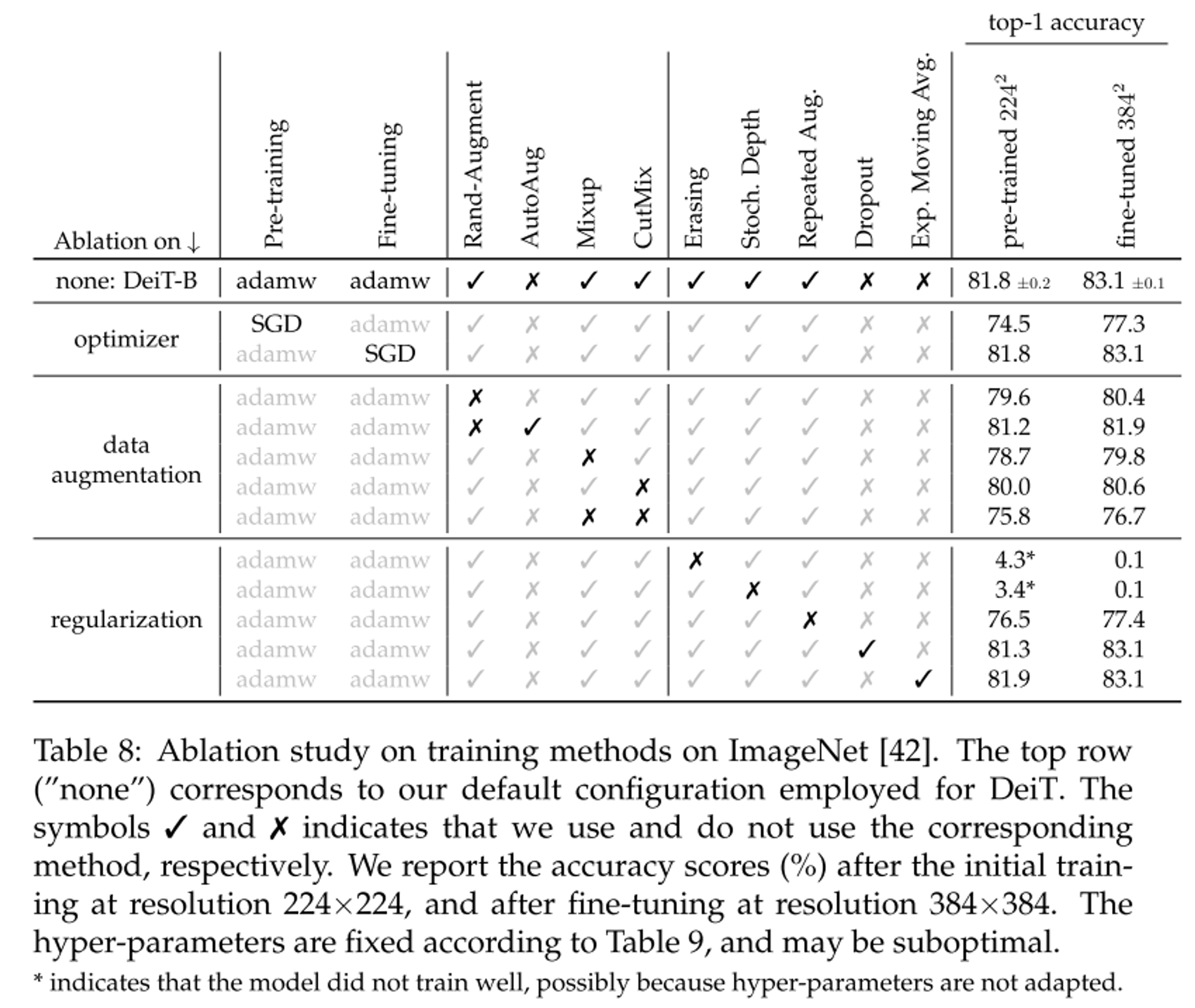
- Transformer는 초기화에 민감하다.
- truncated normal distribution을 활용하여 가중치 초기화 함.
-
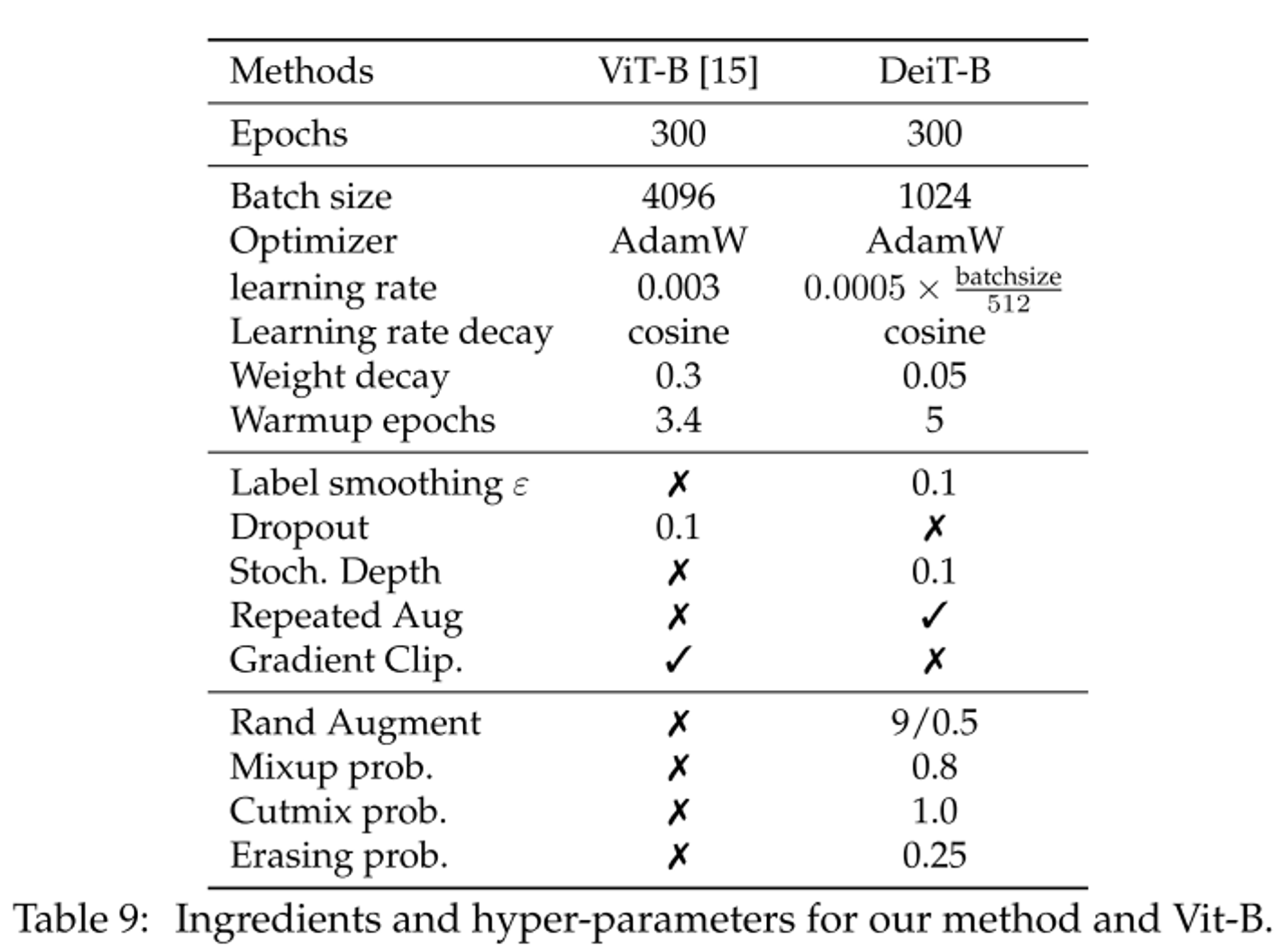
다음과 같은 하이퍼 파라미터를 활용하여 실험 진행
-
transformer 모델은 방대한 데이터셋이 필요하여 이를 위해 data augmentation 기법을 활용하였다.
-
Auto-Augment, Rand-Augment, random erasing이 성능에 영향을 주었으며 Timm library를 활용하여 적용하였고 AutoAugment대산 Rand-Augment를 하용하였다.
-
dropout은 사용하지 않았다.
-
Transformer는 hyper-parameter 설정에 민감하다.
-
본 논문에서는 Table.9와 같은 최적의 Hyperparameter 설정을 얻었다.

-
finetuning은 Fixefficientnet 논문에 따라 진행하였고 결과는 다음과 같다.
-
bicubic interporlation이 vector의 norm을 유지하는데 도움을 주어 이를 채택하였다.
-
학습 시간은 DeiT-B 기준 300epoch에 한 노드로 53시간이 소모된다.
-
repeated augmentation을 사용하기 때문에 1 epoch이 일반적인 epoch으로는 3 epoch을 가리킨다.
- 실제 코드에서는 300 epoch 학습으로 되어 있는데 이는 학습 데이터를 1/3씩 sampling하여 가져오기 때문에 실질적으로는 100 epoch과 같다.
Notes and comments
- ImageNet 데이터 셋만으로도 Transformer 모델의 성능을 높일 수 있다.
- distillation token 방식 필요
- Augmentation 기법 필요
