Overview
1. patch merging을 활용하여 CNN과 비슷한 계층적 표현 구조를 가진다.
2. window 기반 self attention 계산량을 줄였으며, shifted window를 활용하여 성능을 높였다.
3. relative position bias를 활용하여 성능을 높였다.
Problem to solve
- 현재 transformer 기반 모델은 모든 token의 크기가 고정되어 있기 때문에 비전 분야에 적합하기 않은 경우가 있다.
- 높은 해상도의 이미지의 경우 self-attention이 해상도의 제곱배로 계산량이 증가한다.
Concepts

- Swin transformer는 작은 크기의 패치에서 시작하여 더 깊은 transformer 계층에서 이웃 패치를 점진적으로 병합함으로서 계층적 표현을 구성한다.
- 각각의 window 간 서로 겹치지 않도록 self-attention을 계산하기 때문에 이미지 크기의 따라 선형적으로 계산량이 증가한다.
- 따라서 dense prediction인 경우까지도 다양한 경우에 backbone으로 사용할 수 있따.

- Shifted window를 통해서 window간 연관성을 파악할 수 있어 모델의 성능을 높일 수 있다.
- 기존의 sliding window 방식은 매번 다른 key, query set를 활용하여 낮은 latency를 가졌지만, 본 논문은 모든 query와 key set을 공유하기 때문에 효율적이다.
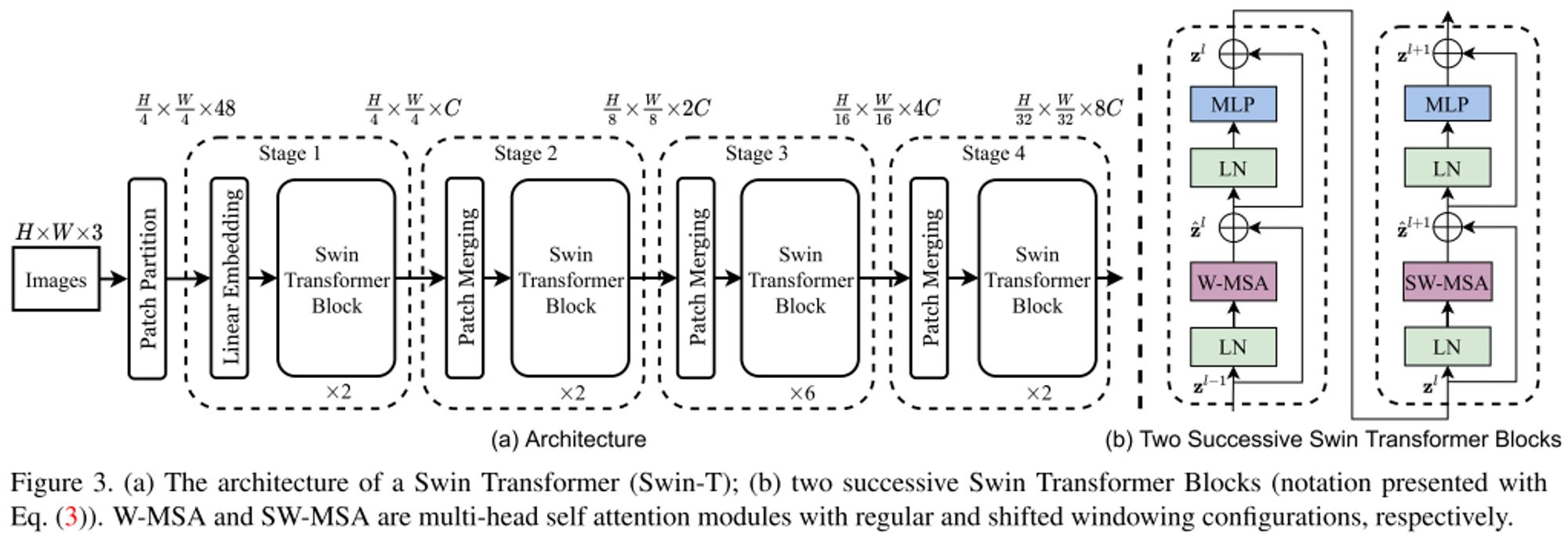
-
ViT에서 하는 것처럼 RGB 이미지를 patch 단위로 나누고 이를 token으로 다룬다.
- 본 논문에서는 patch size를 4x4로 하여, 각 token의 초기 feature dimension은 4x4x3으로 48이다. 이를 linear projection을 통해 원하는 채널로 변환한다.
- 처음 토큰의 개수는 이며, feature dimension은 48이다.
-
stage 1에서는 만들어진 토큰을 활용하여 Linear Embedding을 통해 cls_token, pos_embedding을 수행하고 이를 Swin Transformer Block을 통해 W-MSA와 SW-MSA를 수행한다.
- MLP는 2개의 layer로 이루어져 있으며 그 사이에 GELU 가 삽입된다. 또한 residual connection 존재
- W-MSA는 window 크기 M에 따라 개별적으로 self-attention을 수행한다. (기본 M은 7) 따라서 계산량이 제곱배가 아니라 linear하게 증가

- SW-MSA에서는 cyclic shift를 통해서 추가적인 계산량이 소모되지 않도록하며, masking mechanism을 활용하여 인접하지 않은 feature는 영향을 주지 않도록 한다.
-
stage 2부터는 맨 앞에 patch merging layer를 통과하고 Swin Transformer Block을 수행한다.
- Patch merging은 2x2의 주변 patches를 concatenation하여 붙이고 linear projection을 통해 4C인 dimension을 2C로 바꿔준다.
- Patch merging 이후 Swin Transformer Block을 수행
-
stage 3, stage 4에서도 동일하게 적용

- relative position bias를 활용하여 기존의 pos embedding보다 성능을 더 높였다.
Results

- Swin transformer는 DeiT보다 성능이 더 높은 것을 확인할 수 있다.
- CNN 모델과 비교했을 때 speed-accuracy trade-off 측면에서 Swin transformer가 좀더 우세
- RegNet의 경우 architecture search로 최종적으로 얻어진 것이지만 Swin transformer는 기본적인 성능으로 이보다 더 성능이 높아질 가능성이 있다.
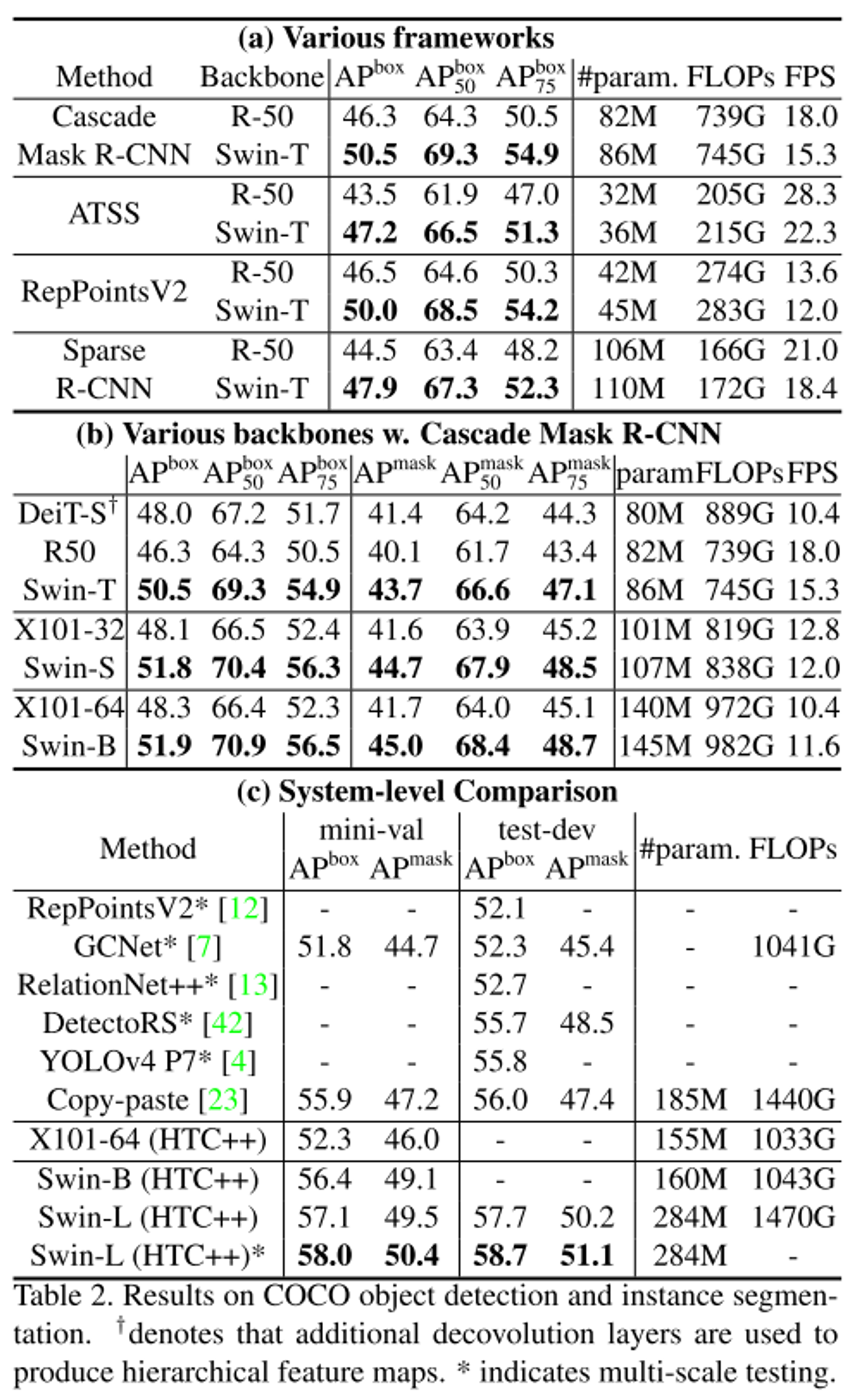
- Object detection 성능에서 backbone으로 Swin transformer를 사용하는 것이 더 성능이 높은 것을 확인할 수 있다.
- DeiT는 단일 해상도에 대해서만 적용이 가능하기 때문에 공평한 비교를 위해서 deconvolution layer를 활용하여 계층적 특징을 가질 수 있도록 수정하였다.
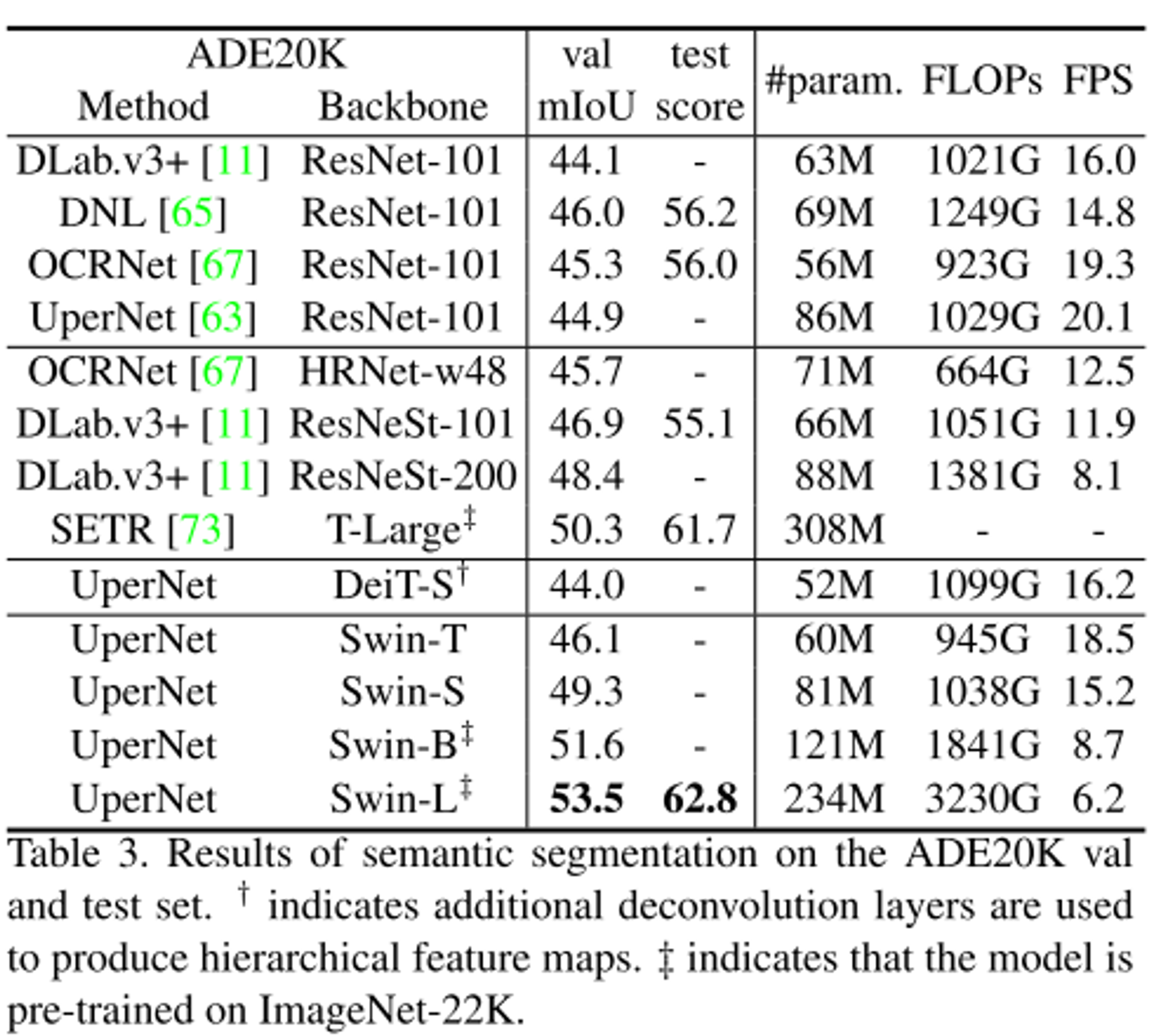
- Sementic segmentation에 대한 결과로 DeiT보다 성능이 높은 것을 확인할 수 있다.
Ablation study
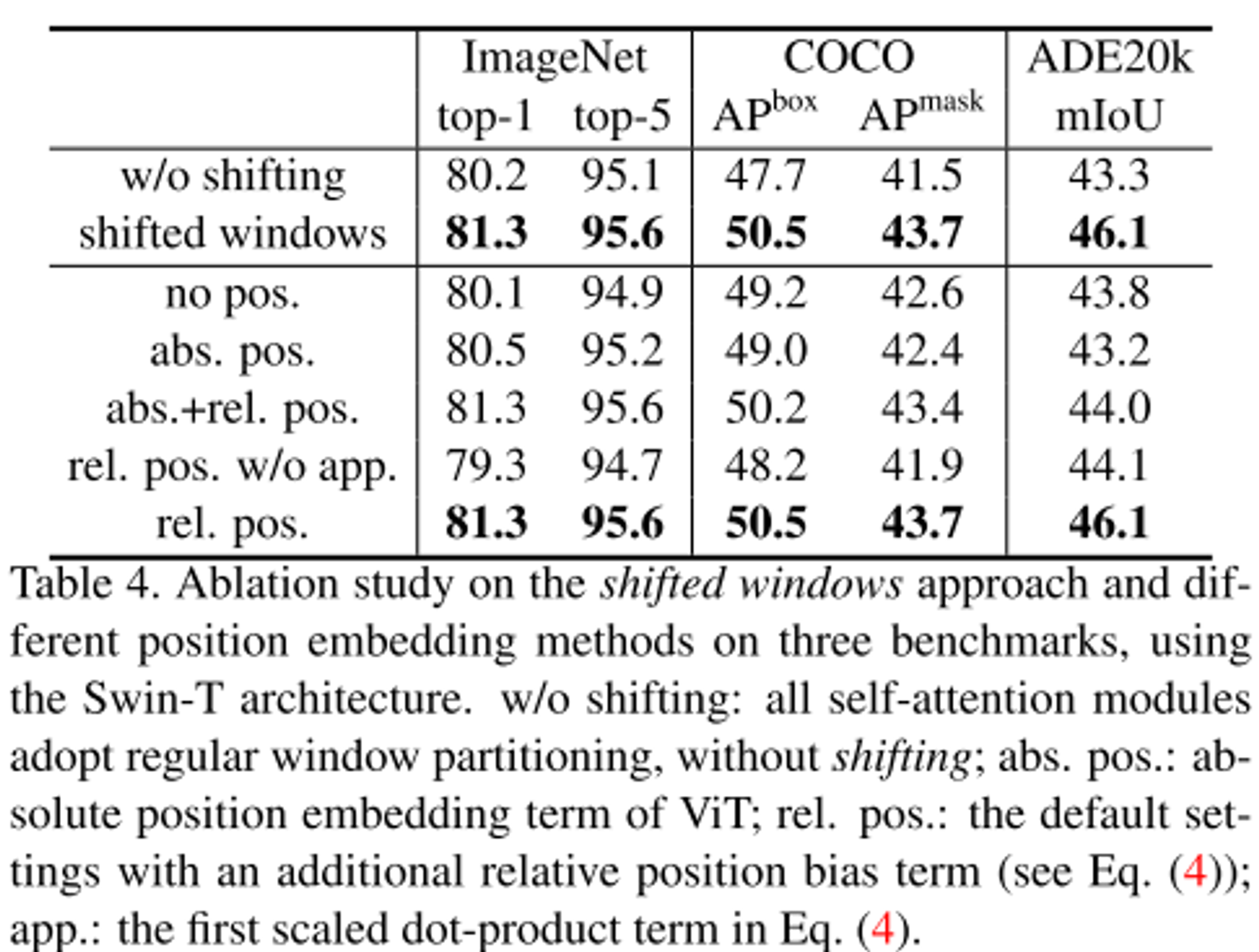
- shifted window를 적용하면 성능이 더 높아지는 것을 확인
- relative position bias가 absolute position embedding보다 성능이 모든 task를 고려했을 때 성능이 높은 것을 확인
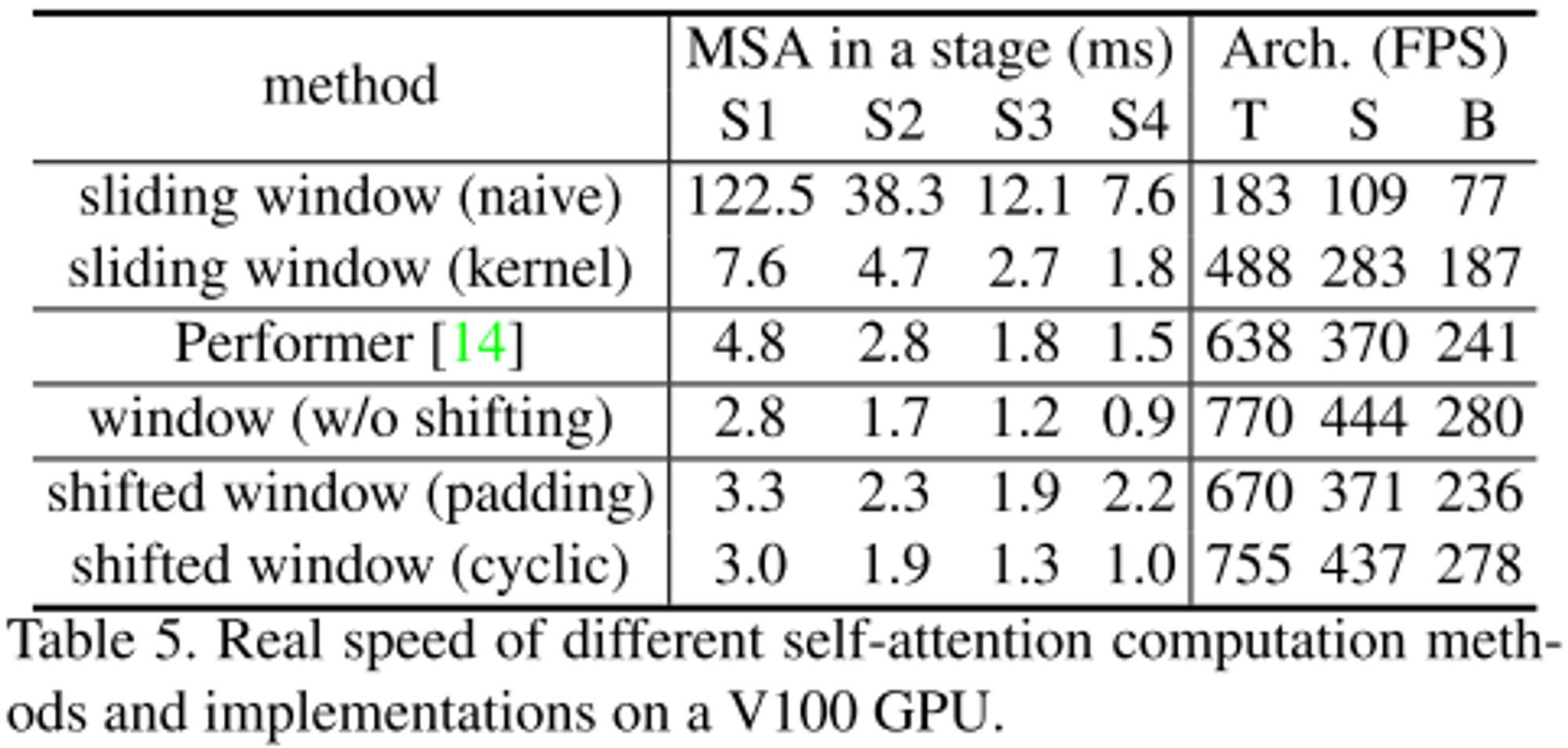
- shifted window의 overhead는 크기 않은 것으로 확인
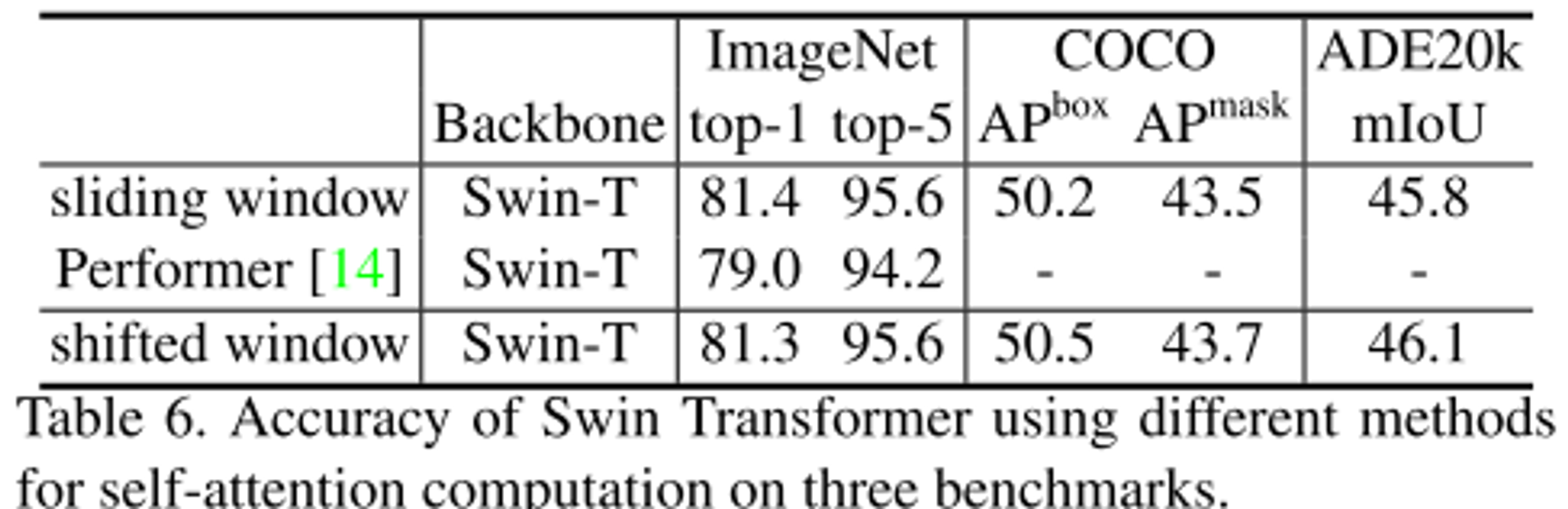
- 기존의 self attetion methods와 비교했을 때 shifted window 기법이 가장 성능이 높은 것으로 확인
Notes and comments
- patch merging 을 활용하여 CNN과 비슷하게 계층적 표현을 가질 수 있게 하였다.
- Window기반 MSA을 활용하여 self attention 계산량을 선형적으로 증가할 수 있게 하여 다양한 해상도에서 사용 가능하다.
- shifted window 기법의 self attention 을 활용하여 window 간 연관성도 고려할 수 있어 성능을 높였고 인접하지 않은 feature map은 masking machanism을 활용하여 처리하였다.
- relative position bias를 활용하여 성능을 높였다.
