정글 week01. 핵심 키워드
자료구조

Array 배열
index,element로 구성
같은 타입의 데이터를 여러개 나열한 선형 자료구조.
연속적인 메모리 공간에 순차적으로 데이터를 저장(삽입 순서대로 저장)
최초에 메모리 크기를 정적으로 할당.
이미 삽입된 값도 수정 가능함
중복 데이터 삽입 가능
배열 안에 배열을 배치 가능 (다차원 배열)


-> 순차적으로 메모리 저장 -> index를 통해 특정 요소를 찾고 조작이 가능하다는 장점. 그러나 요소가 삽입/삭제 되는 경우 모든 요소들을 한 칸씩 재배치해야 함!
배열과 리스트의 차이 ?
배열: 찾고자 하는 인덱스 값을 알고 있으면 RandomAccess 속도 빠름, 그러나 삽입, 삭제 과정
연결 리스트 linked list

Array는 메모리 상에 데이터가 연속적으로 저장되고,
List는 메모리 상에 데이터가 비연속적으로 저장된다.
배열은 연속적인 메모리 공간에 할당되어 인덱스를 통한 빠른 접근이 가능 but 크기가 고정되어 있고, 삽입과 삭제가 번거롭다. 중간에 원소를 삽입하거나 삭제할 때, 나머지 원소들을 이동해야 한다.
리스트는 비연속적인 메모리 공간에 할당되어 순차적으로 접근해야 하지만 크기가 가변적이고, 임의의 위치에 원소를 삽입, 삭제하기가 빠르다. 원소들이 연결된 포인터를 수정하기만 하면 된다.
파이썬의 리스트는 연결 리스트의 자료구조가 아니라 모든 원소를 연속으로 메모리에 배치하는 배열로 내부에서 구현 -> 속도가 급격하게 떨어지지 않음,원소 추가, 삽입할 때마다 메모리를 확보하거나 해체하지 않음, 실제 필요한 메모리보다 여유있게 미리 마련해놓음!
-
단일 연결 리스트

-
이중 연결 리스트

-
원형 연결 리스트

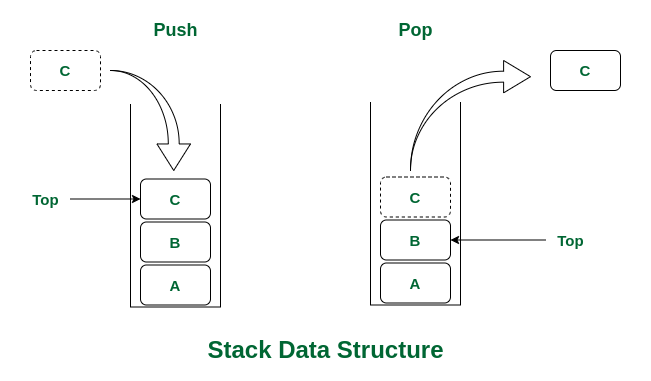
Stack 스택
후입선출(LIFO, Last In First Out)
나중에 들어온 것이 가장 먼저 빠져 나간다!
스택에 데이터를 추가하는 것을push
가장 마지막에 추가된 데이터부터 꺼내는 것을pop
visits = [] # 방문 기록지
# 1. 처음으로 구글에 방문
visits.append('google') # ['google']
# 2. 그다음 인스타그램에 방문
visits.append('instagram') # ['google', 'instagram']
# 3. 그다음 페이스북에 방문
visits.append('facebook') # ['google', 'instagram', 'facebook']
# 4. 뒤로가기 버튼을 누름
visits.pop()
print(visits) # ['google', 'instagram'] => 다시 인스타그램 페이지로 돌아옴Queue 큐
큐는선입선출(FIFO, First In First Out)구조
큐는 앞쪽부터 자료가 빠져나가며 삽입은 리스트 뒤로 이어지게 됩니다.
큐에 데이터를 추가하는 것을 'enqueue'
가장 먼저 추가된 데이터부터 꺼내는 것을 'dequeue'

people = ['april', 'jane', 'bob', 'brad']
# 줄이 줄어든다면? => 앞쪽부터 빠져나간 것!
people.pop(0)
print(people) # ['jane', 'bob', 'brad']
# 줄에 사람이 추가된 경우?
people.append('kelly')
print(people) # ['jane', 'bob', 'brad', 'kelly']
# 중간에 추가된 경우나, 인원이 나가는 경우도 슬라이싱 삽입이나 insert 등으로 구현 가능합니다.예시) OS의 스케줄러 FCFS 선입선처리할 때
우선순위 큐

우선순위 큐(Priority Queue)는 들어간 순서에 상관없이 우선순위가 높은 데이터가 먼저 나온다.
우선순위 큐는 힙(Heap)이라는 자료구조를 가지고 구현할 수 있다.
insert(x) : 우선순위 큐에 요소 x 추가
remove() : 우선순위 큐에서 가장 우선순위가 높은 요소를 삭제하고 반환
find() : 우선순위 큐에서 가장 우선순위가 높은 요소를 반환
우선순위 큐 구현 방식 - 배열, 연결 리스트, 힙 => 그 중 힙 방식이 worst case라도 시간 복잡도 O(logN)을 보장하기 때문에 일반적으로 완전 이진트리 형태의 힙을 이용
양방향 대기열 덱의 구조
맨 앞과 맨 끝 양쪽에서 데이터를 넣고 꺼낼 수 있는 자료 구조
- 2개의 포인터를 사용하여 양쪽에서 삭제, 삽입할 수 있으며 큐와 스택을 합친 형태

해쉬 테이블
해쉬 함수?
임의의 길이를 갖는 데이터를 고정된 길이의 해쉬값으로 변환시켜주는 함수
암호 알고리즘에는 키가 사용되지만, 해시 함수는 키를 사용하지 않으므로 같은 입력에 대해서는 항상 같은 출력 -> 해쉬 함수의 시간 복잡도 O(1)
예시) SHA(Secure Hash Algorithm)256
키-값 쌍을 저장하고 있는 자료 구조로, 해시함수(Hash Function)를 사용하여 변환한 값을 색인(index)으로 삼아 키(key)와 데이터(value)를 저장한다. 빠르게 데이터를 검색할 수 있다!


용어
1) storage: 해시테이블에서 자료를 저장하는 전체 공간
2) bucket: 해쉬 테이블 충돌을 해결하기 위해 사용되는 하위 저장 구조
3) tuple: 해시 충돌시 버켓 내부에 자료들을 연결시켜 저장할 때 사용 - 하나의 키와 하나의 값으로 구성
4) hash table: 해쉬값을 인덱스로 하여 원소를 새로 저장한 배열
색인(index) 에 해시 값을 사용함으로써 모든 데이터를 살피지 않아도 탐색과 삽입/삭제 을 빠르게 수행 가능!
해시 테이블 탐색/삽입,삭제의 시간 복잡도 O(1)
해시 충돌 (Hash Collision)
데이터를 Key로 간소화하여 저장한다는 아이디어는 좋지만, 다른 내용의 데이터가 같은 키를 갖는다면?
yoon → 해싱함수 → 5
Kim → 해싱함수 → 3
Park → 해싱함수 → 2
Chun → 해싱함수 → 5 // yoon와 해싱값 충돌같은 키값을 갖는 데이터가 생긴다는 것은, 특정 키의 버켓에 데이터가 집중된다는 뜻이다.
해시함수의 입력값은 무한하지만, 출력값의 가짓수는 유한(출력값, 즉 키가 유한하지 않다면 해시기법을 사용하는 의미가 없다.)하므로 해시 충돌은 반드시 발생한다.(비둘기집 원리)

해쉬 충돌 해결 방법
체인법: 해쉬값이 같은 원소를 연결 리스트로 관리

장점: 해시 테이블의 크기에 영향을 받지 않고 일정한 성능을 유지할 수 있다.
단점: 연결 리스트를 위한 추가 메모리가 필요. 연결리스트가 길어지면 해시 테이블의 값을 찾는데 시간이 많이 소요될 수 있다.
오픈 주소법: 빈 버킷을 찾을 때까지 해쉬를 반복, 충돌 발생시 다른 버킷에 데이터를 저장

메모리 사용량이 적습니다. 해시 테이블에 직접 데이터를 저장하므로 연결 리스트와 같은 추가 메모리가 필요하지 않음.
단점:
클러스터란 해시 테이블에서 연속된 위치에 여러 개의 요소가 모여있는 상황연속된 해시 충돌이 발생하면 클러스터가 형성되어 삽입, 삭제, 검색 속도가 저하될 수 있습니다.
삭제 연산이 복잡할 수 있습니다. 삭제된 위치를 표시하거나 특별한 마커로 표시해야 할 수 있다.
해시 함수의 선택이 중요!
참고)
https://preamtree.tistory.com/20
https://rosweet-ai.tistory.com/48
아직 해쉬테이블과 충돌 해결 방법은 아직 잘 모르겠다.
