왜 DB index로 B tree 계열이 사용되는가
B tree, B+ tree, B* tree
=> avg case, worst case
조회, 삽입, 삭제 모두 시간복잡도O(log N)
b-tree

b+tree

B+ 트리는 B 트리와 유사하지만, 모든 키는 리프 노드에만 존재, 내부 노드에는 키만 저장됨!
리프 노드는 링크드 리스트로 연결되어 있음!
self balancing BST -> binary search tree 이면서도 스스로 균형을 잡을 수 있는 트리
AVL tree
Red-Black tree
=> avg case, worst case
조회, 삽입, 삭제 모두 시간복잡도O(log N)
이렇게 Self balncing tree인 rb tree와 AVL 트리도 시간 복잡도는 똑같이 O(log N)인데 왜 Db index 에서는 B-tree 계열이 많이 사용되는 것일까?
Computer system
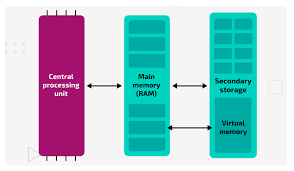
cpu: 프로그램 코드가 실제로 실행되는 곳
Main memory(RAM): 실행 중인 프로그램의 코드들과 코드 실행에 필요한 혹은 그 결과로 나온 데이터들이 상주 -> 휘발성 메모리로 동작
Secondary storage(SSD or HDD): 프로그램과 데이터가 영구적으로 저장되는 곳, 실행 중인 프로그램의 데이터 일부가 임시 저장되는 곳 -> 비휘발성 메모리
Database도 secondary storage에 저장됨
Secondary Storage
- 데이터를 처리하는 속도가 가장 느리다.
- 데이터를 저장하는 용량이 가장 크다.
- block 단위로 데이터를 읽고 쓴다._ => 불필요한 데이터까지 읽어오게 될 수 있음!
=>
block: file system이 데이터를 읽고 쓰는 논리적인 단위
block의 크기는 2의 승수로 표현되며 대표적인 block size는 4kb, 8kb, 16kb 등
- hdd는 물리적인 하드 웨어 장치가 있어서 ssd 보다는 느리다고 함

DB에서 데이터를 조회할 때 secondary storage에 최대한 적게 접근하는 것이 성능 면에서 좋을 것이다. 왜냐면 secondary storage가 데이터를 처리하는 속도가 가장 느리기 때문에
+ block 단위로 데이터를 읽고 쓰니까 연관된 데이터를 모아서 저장하면 더 효율적으로 읽고 쓸 수 있음
avl tree 기반으로 인덱스를 만들었을 때


5차 B-tree 기반으로 인덱스를 만들었을 때


비교
AVL Tree: secondary storage 4번 접근
자녀 노드 수 1~2개
노드의 데이터 수 1개5차 B-tree: secondary storage 2번 접근
자녀 노드 수 3~5 개
노드의 데이터 수 2~4개
B-tree => 데이터를 찾을 때 탐색 범위를 빠르게 좁힐 수 있다!
=> block 단위에 대한 저장 공간 활용도가 더 좋다.

예시 ) 101차 b-tree
best case
-> 최대 자녀수 : 101
최대 key 수: 100
최소 자녀 수: 51
최소 Key 수: 50

best case->높이 3으로 저장할 수 있는 데이터의 개수 1억
worst case
최대 자녀수: 101
최대 key 수: 100
최소 자녀 수: 51
최소 key 수: 50

worst case 26만개 저장 가능
avg case

=> b tree index는 self-balancing BST에 비해 secondary storage 접근을 적게 한다.
b tree 노드는 block 단위의 저장 공간을 최대한 효율적으로 사용할 수 있다.

hash index를 쓰면?
- hash index 는 삽입/삭제/조회 => O(1)
=> equality(=) 조회만 가능
범위 기반 검색이나 정렬에는 사용될 수 없음!
참고) 유튜브 쉬운 코드
