긴 코드를 읽기 전에 구조가 어떻게 되어있는지 알기 위해 찾아본 내용들을 정리
처음 배우는 내용들이라 틀린 내용이 있을 수 있으므로 추후 수정 필요.
1. SOLID 원칙
SOLID란 로버트 C. 마틴이 2000년대 초반에 명명한 객체 지향 프로그래밍 및 설계의 다섯 가지 기본 원칙🔗이다.
- SRP 단일 책임 원칙 (Single responsibility principle)
한 클래스는 하나의 책임만 가져야 한다. - OCP 개방-폐쇄 원칙 (Open/closed principle)
“소프트웨어 요소는 확장에는 열려 있으나 변경에는 닫혀 있어야 한다.” - LSP 리스코프 치환 원칙 (Liskov substitution principle)
“프로그램의 객체는 프로그램의 정확성을 깨뜨리지 않으면서 하위 타입의 인스턴스로 바꿀 수 있어야 한다.” 계약에 의한 설계를 참고하라. - ISP 인터페이스 분리 원칙 (Interface segregation principle)
“특정 클라이언트를 위한 인터페이스 여러 개가 범용 인터페이스 하나보다 낫다.” - DIP 의존관계 역전 원칙 (Dependency inversion principle)
프로그래머는 “추상화에 의존해야지, 구체화에 의존하면 안된다.” 의존성 주입은 이 원칙을 따르는 방법 중 하나다.
2. 의존성 역전 원칙(DIP)
참고
- Controller (컨트롤러)
클라이언트 요청을 처리하는 역할 (HTTP 요청을 받고, 응답을 반환)
비즈니스 로직을 직접 처리하지 않고 Service(서비스)에 위임
주로 API 엔드포인트를 정의- Service (서비스)
비즈니스 로직을 처리하는 핵심 계층
DB에서 데이터를 가져오거나 가공하는 작업 수행
컨트롤러에서 요청한 데이터를 조회, 수정, 삭제하는 역할- Interface (인터페이스)
객체의 형태(Shape)를 정의하는 역할
Port로도 표현됨
의존관계 역전 원칙DIP은 소프트웨어 모듈들을 분리하는 특정한 방식을 지칭한다.
전통적으로 모듈들은 상위 계층이(정책 결정)이 하위 계층(세부 사항)에 의존하는 관계를 가졌다.
이 경우 리팩토링 등의 이유로 저수준 모듈을 수정하는 경우 고수준 모듈도 같이 수정해줘야 할 가능성이 높다.
DIP는 이런 전통적인 의존관계를 역전(하위 계층 또한 추상화에 의존하게 함)시켜 상위 계층이 하위 계층의 구현으로부터 독립되게 한다.
이 원칙은 다음과 같은 내용을 담고 있다.
- 상위 모듈은 하위 모듈에 의존해서는 안된다. 상위 모듈과 하위 모듈 모두 추상화에 의존해야 한다.
- 추상화는 세부 사항에 의존해서는 안된다. 세부사항이 추상화에 의존해야 한다.
요약하면 상위와 하위 객체 모두가 동일한 추상화에 의존해야 한다는 객체 지향적 설계의 대원칙을 제공한다.
2.1. 예시1: DIP가 적용되지 않은 경우
아래 예시에서 컨트롤러는 서비스에 의존하고 있다.
Controller -> Service
# 저수준 모듈 (구체적인 서비스)
class UserService:
def get_user(self, user_id: int) -> str:
return f"User {user_id} data"
# 고수준 모듈 (컨트롤러)
class UserController:
def __init__(self):
self.service = UserService() # ⚠ 직접 특정 서비스 구현체를 생성해서 의존함
def get_user(self, user_id: int):
return self.service.get_user(user_id)
# 실행
controller = UserController()
print(controller.get_user(1)) # "User 1 data"2.2. 예시2: DIP가 적용된 경우
아래 예시에서 고수준, 저수준 모듈이 모두 UserServicePort라는 추상화(인터페이스, Port)에 의존하고 있다.
Controller -> Port <-(역전) Service
from typing import Protocol
# 1️⃣ Port 역할 (추상화, 인터페이스)
class UserServicePort(Protocol):
def get_user(self, user_id: int) -> str:
pass
# 2️⃣ 저수준 모듈 (구체적인 서비스)
class BasicUserService:
def get_user(self, user_id: int) -> str:
return f"Basic User {user_id} data"
class PremiumUserService:
def get_user(self, user_id: int) -> str:
return f"Premium User {user_id} data"
# 3️⃣ 고수준 모듈 (컨트롤러)
class UserController:
def __init__(self, service: UserServicePort): # 인터페이스(추상화)에 의존
self.service = service
def get_user(self, user_id: int):
return self.service.get_user(user_id)
# 실행
basic_controller = UserController(BasicUserService())
print(basic_controller.get_user(1)) # "Basic User 1 data"
premium_controller = UserController(PremiumUserService())
print(premium_controller.get_user(1)) # "Premium User 1 data"이렇게 하면 컨트롤러가 특정 서비스의 구현에 의존하지 않으며 서비스 로직을 변경하더라도 컨트롤러 수정이 필요가 없다.
또한 Mocking이 쉬워져 단위 테스트가 편리해진다.
3. 의존성 주입(DI)
DIP를 구현하는 방식 중 하나로 객체 내부에서 직접 의존성을 생성하는 대신, 외부에서 주입받는 방식을 말한다.
위의 코드에서 컨트롤러 인스턴스를 생성할 때 서비스 인스턴스를 인자로 전달하는 부분UserController(BasicUserService())이 의존성 주입(Dependency Injection)이다.
NestJS는 의존성 주입 컨테이너(DI Container)를 사용해서 객체 생성을 자동으로 관리한다.
따라서 직접new UserService()와 같이 객체를 직접 생성해주지 않아도 자동으로 재사용한다.
4. Hexagonal Architecture
https://medium.com/ssense-tech/hexagonal-architecture-there-are-always-two-sides-to-every-story-bc0780ed7d9c
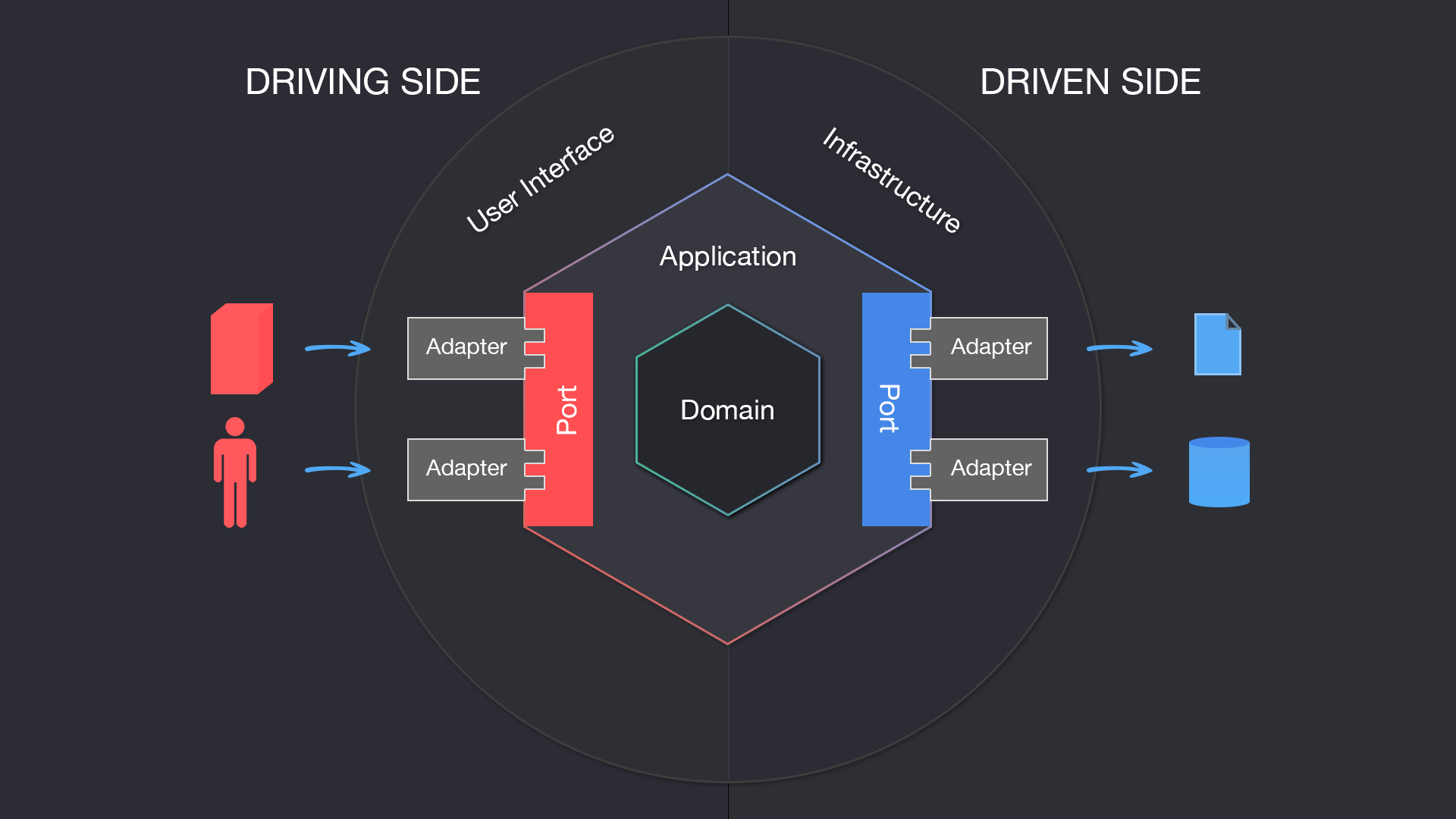 Hexagonal Architecture(Ports & Adapters 아키텍처)는 알리스테어 코번(Alistair Cockburn)이 제안한 소프트웨어 설계 방식이다.
Hexagonal Architecture(Ports & Adapters 아키텍처)는 알리스테어 코번(Alistair Cockburn)이 제안한 소프트웨어 설계 방식이다.
이 아키텍처의 핵심은 의존성 역전 원칙을 강하게 적용하는 것으로, 애플리케이션의 핵심 로직(애플리케이션 코어. 육각형으로 표현됨)을 모든 외부 시스템(데이터베이스, UI, 외부 API 등)과 분리하여 테스트 용이성과 유지보수성을 높이는 데 있다.
DI를 설명할 때의 예시에서 외부 사용자가 기능을 조작할 때(그림의 Driving side) Controller-Port-Service 계층을 통해 작동했던 것과 같이 Service에서 DB와의 통신 등을 할 때(즉 외부 인프라에 접근할 때, 그림의 Driven side)에도 Port와 Adapter를 거치도록 하여 애플리케이션 코어를 외부와 강하게 격리시키는 것이 핵심 아이디어이다.
4.1. 핵심 개념
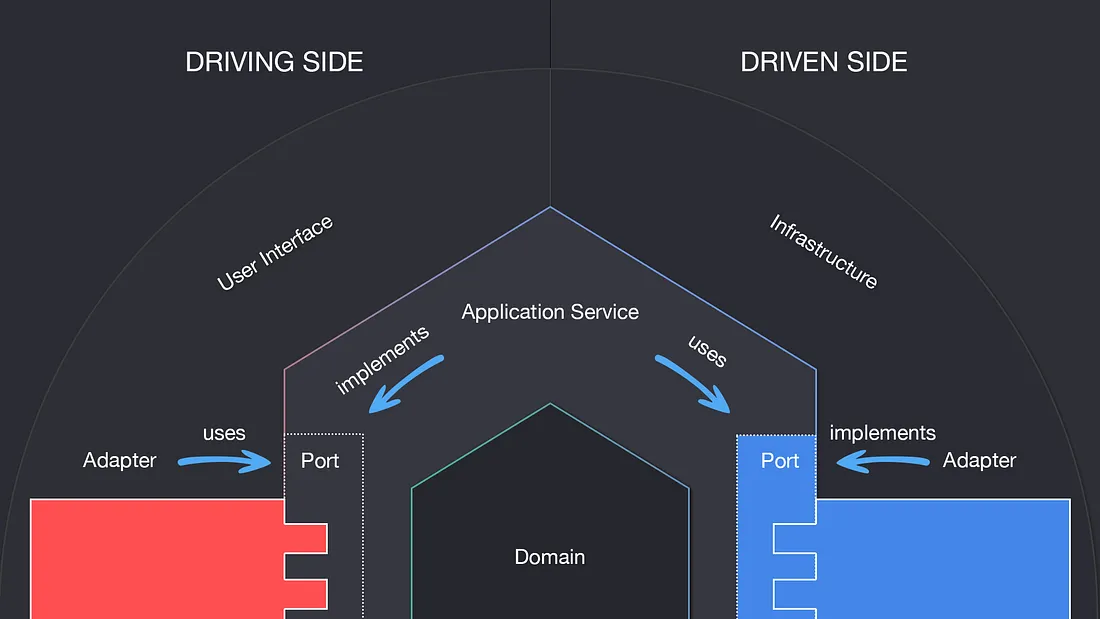 왼쪽에서 오른쪽으로 흐르며 입력 포트는 서비스가 구현하며, 출력 포트는 출력 어댑터가 구현한다.
왼쪽에서 오른쪽으로 흐르며 입력 포트는 서비스가 구현하며, 출력 포트는 출력 어댑터가 구현한다.
출력 포트를 사용한 외부 인프라로의 접근은 핵심 비즈니스 로직이 무관할 뿐더러, 코어(육각형)는 외부에 대한 정보가 없어야한다는 핵심 아이디어를 생각하면 당연하다.
- 애플리케이션 코어(Application Core)
애플리케이션의 핵심 비즈니스 로직(도메인 모델, 유스케이스, 비즈니스 규칙 등)이 위치
외부 시스템과 독립적이며, 비즈니스 규칙만 담당
애플리케이션 서비스 계층에서 호출되며, 도메인 모델을 사용해 데이터 처리 수행 - 포트(Ports)
포트는 도메인과 외부 세계를 연결하는 인터페이스- 입력 포트
외부에서 애플리케이션으로 데이터를 전달하는 인터페이스 (예: API 엔드포인트) - 출력 포트
애플리케이션에서 외부로 데이터를 전달하는 인터페이스 (예: 데이터베이스 접근)
- 입력 포트
- 어댑터(Adapters)
어댑터는 외부 시스템과의 통신을 담당- 입력 어댑터
외부 요청을 애플리케이션의 입력 포트로 전달 (예: REST Controller) - 출력 어댑터
애플리케이션의 출력 포트를 외부 시스템에 연결 (예: 데이터베이스 Repository)
- 입력 어댑터
- 애플리케이션 서비스(Application Service, Service)
도메인 로직을 직접 포함하지 않고, 유스케이스 흐름을 조정하는 역할
외부 시스템과 직접 연결되지 않으며, 포트를 통해 접근
입력 포트(Inbound Port)를 구현하여 UI(컨트롤러, API)와 도메인을 연결
출력 포트(Outbound Port)를 호출하여 외부 리소스(DB, API)와 연결
4.2. 특징
4.2.1. 장점
- 비즈니스 로직(Service)이 외부 환경(입출력, DB)과 독립적
기술이 아닌 '목적에 따라' 모든 시스템 인터페이스를 설계할 수 있음
=> 도메인 주도 설계(DDD)와 잘 어울림 - 유연한 확장성
- 새로운 데이터 저장소 추가, API 프로토콜 변경이 쉬움.
- REST API, gRPC, WebSocket 등을 쉽게 추가 가능.
- 유지보수성이 높음
변경 사항이 특정 Adapter에 한정되어 전체 코드 수정이 적음. - 테스트가 쉬움
Service는 Port 인터페이스만 알면 되므로, Mock 객체를 활용해 단위 테스트가 용이.
4.2.2. 단점
- 설계가 복잡해질 수 있음
작은 프로젝트에서는 단순한 계층형 아키텍처가 더 적합할 수 있음. - 개발자가 패턴을 정확히 이해하지 않으면 오히려 불필요한 추상화가 많아질 위험.
4.2.3. 사용하기 어려운 경우🔗
- 도메인 모델을 확실하게 정의하기 어려운 경우
Port와 Adapter의 경계를 명확히 설정하기 힘들 수 있음 - 코어 로직보다 외부 서비스에 크게 의존하는 경우
로직의 대부분이 연동 API에 의해 동작하는 서비스일 경우 Port와 Adapter에 로직이 과중됨
4.3. 파일 구조 예시
├adapter
│├in
││└controller
│└out
│ └repository
├port
│├in
││└UserServiceInterface
│└out
│ └RepositoryInterface
├service
│└UserService
├domain
└DomainEntity5. 도메인 주도 설계(Domain Driven Design, DDD)
기존의 개발 방식과 비교하여 설명
5.1. 전통적 개발 방식(예시)
기존의 방식에서는 요구사항을 기능 단위로 나누어 구현하였다.
데이터베이스 설계를 먼저 하고, 이를 기반으로 애플리케이션을 개발되는 것이 보통.
Controller, Service, Repository와 같은 계층구조는 전통적 개발 방식에도 존재
5.1.1. 장점
- 빠른 개발
복잡한 도메인 분석 없이 기능을 빠르게 구현 - 단순함
작은 규모의 애플리케이션에서 개발이 쉬움
5.1.2. 단점
- 도메인 이해 부족
도메인에 대한 이해를 하지 못한 채 개발하여 비즈니스 요구사항을 제대로 반영하지 못할 수 있음 - 유지보수 어려움
코드가 도메인 개념과 일치하지 않아 유지보수가 어려움 - 확장성 부족
복잡한 비즈니스 로직이 추가되면 코드가 복잡해지고 관리하기 어려움
5.2. DDD
개발자역시 도메인을 이해하고 이를 통해 구현
도메인 전문가와 개발자가 도메인 지식을 공유하여 의사소통과 코드 작성에 일관성을 유지
복잡한 도메인을 작은 단위로 나누어 정의한 명확한 컨텍스트(Bounded Context)에 기초해 개발
5.2.1. 장점
- 도메인 이해도 향상
도메인 이해를 바탕으로 비즈니스 요구사항을 정확히 반영 - 유지보수성
도메인 모델이 명확하므로 코드의 의도를 쉽게 이해 - 확장성
Bounded Context를 통해 관리하므로 계속해서 발전하는 비즈니스 모델의 구현이 쉬워짐
5.2.2. 단점
- 개발이 복잡해짐
일반적으로 모델을 순수하고 유용한 구성으로 유지하기 위해 상당한 양의 격리 및 캡슐화를 구현해야 함
=> 도메인에 대한 공통의 이해가 가져오는 장점이 명확한 복잡한 도메인의 경우에 사용할 것을 권장 - 초기 설계 비용
설계를 위해 도메인에 대한 깊은 이해가 필요
5.3. 결론
DDD는 복잡한 비즈니스 로직을 가진 프로젝트에 적합하며, 전통적 개발 방식은 단순한 애플리케이션에 더 적합
