
XAI 기술 간단 요약
| XAI기술 | 설명방법의 특징 |
|---|---|
| LIME | 이미지나 텍스트를 포함한 다양한 데이터에 대해 임의의 판별 AI 모델의 예측을 선형 유사로 설명 |
| SHAP | 각종 데이터에 대응하는 AI 모델의 예측에 대해 특징량의 공헌도를 게임 이론적인 지표를 사용해 고르게 나누어 설명 |
| Permutation Importance | 특징량의 값을 정렬하고 모델 예측 오차의 증가를 추정해 특징량과 결과의 관계를 명확히 한다. |
| Partial_Dependence_Plot/ Individual Conditional Expectation | 특징량의 변화가 기계학습 모델의 예측 결과에 반영되는 영향을 그래프로 표시한다(예측값의 평균을 사용할 지 각각의 예측을 사용할지 여부에 따라 방법명이 달라진다. |
| Tree Surrogate | AI 모델 예측의 대역적 경향을 유사하게 학습한 해석 가능한 의사결정 트리로 대리 설명한다. |
| CAM/Grad-CAM | CNN 계열 모델의 누적층의 경사를 사용해 이미지의 중요 요소를 강조한 지도를 생성한다. |
| Integrated Gradients | DNN 계열 모델 입,출력값의 경사의 적분을 유사하게 계산해 입력 특징의 중요도 점수를 할당한다. |
| Attention | RNN/CNN 계열 모델에 사용된 Attention기구를 사용해 예측을 설명한다. |
LIME
- 어떠한 설명 대상 데이터 1건에 대한 AI 모델의 결과 예측에 기여한 데이터의 특징을 산출한다. '국소 설명 기술'이라고 한다.
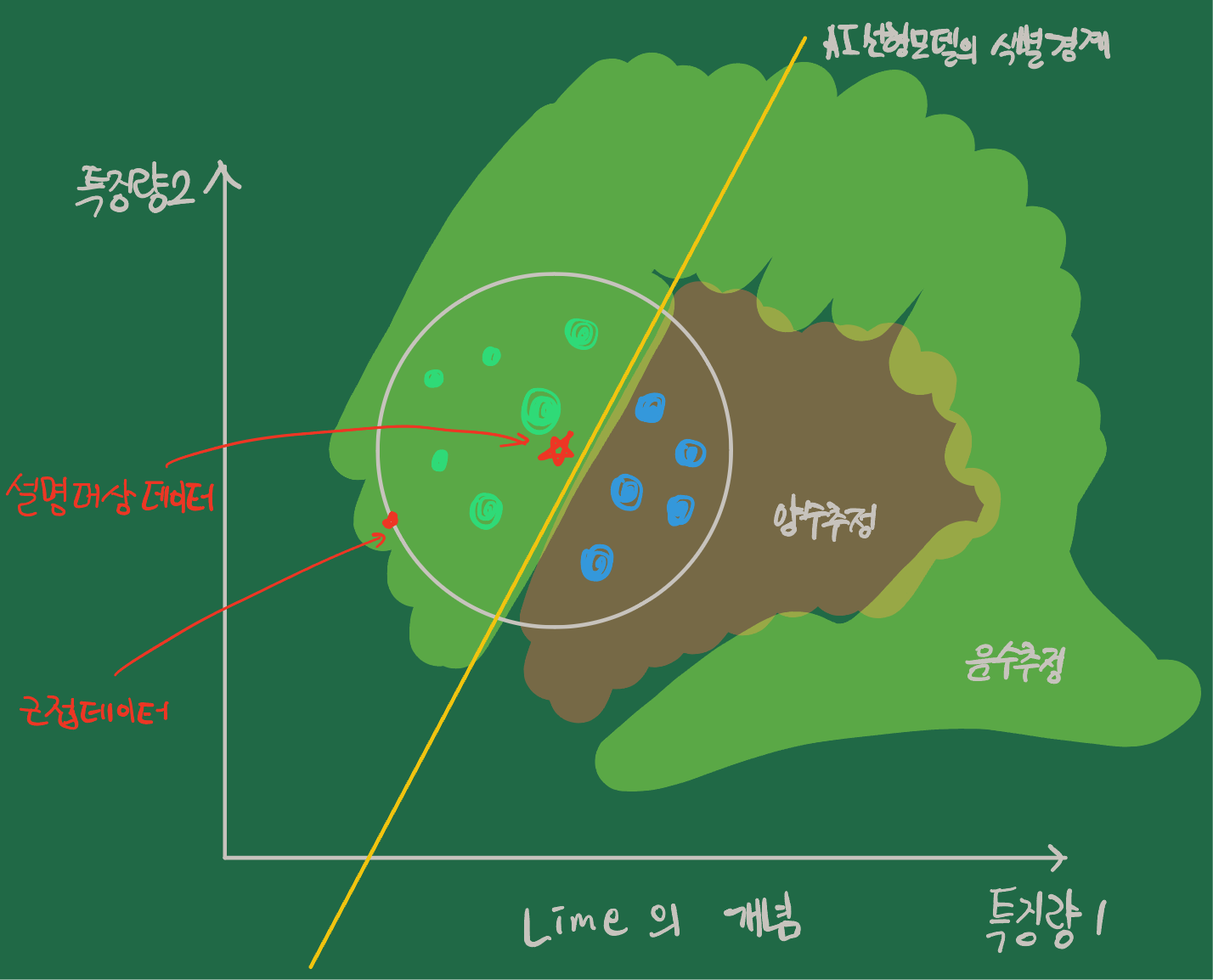
- 설명 대상 데이터를 일부 삭제하거나 노이즈 값을 더해서 근방 데이터를 생성한다.
- 근방 데이터에 대한 설명 대상 AI모델의 예측 결과를 얻는다.
- 근방 데이터와 2과정의 결과를 조합한 데이터로 해석 가능한 모델을 획득한다.
데이터 종류별 동작 원리
-
테이블 데이터 LIME의 경우 : 표 형식이라면 가공 전 상태가 이미지나 텍스트 등의 형식을 포함해 어떠한 데이터가 들어와도 입력 가능하다. 입력 데이터의 각 특징량이 가질 것 같은 값이나 통계쩍인 계산 정보를 바탕으로 근방 데이터 생성. 데이터 변화 자체는 근방에 한정되지 않고 각 특징량이 가질 것 같은 공간 전체에 무작위로 데이터 생성. 단, 설명 대상 데이터와의 거리가 가까운 데이터를 중요시하도록 유사 모델을 학습함으로써 실질적인 근방 데이터 생성 가능.
-
이미지 데이터 LIME의 경우 : 이미지 데이터를 화소 단위로 설명하는 경우 계싼량이 너무 커지고, 얻을 수 있는 설명 결과도 화소 단위에서는 해석이 어려워진다. 따라서 '세그먼트' 라는 영역으로 분할해 세그먼트마다 판정 기여도를 산출함. 근방 데이터의 생성은 세그먼트 단위에서 이미지를 백색이나 흑색, 이미지의 평균 RGB값 등으로 덧칠하여 적용.
-
텍스트 데이터 LIME의 경우 : 설명 대상문에 있는 단어를 감추도록 작성.
해당 책을 읽고 내용을 정리함.
XAI, 설명 가능한 AI

Machine Learning, Data Science, Data Engineering, Large Language Model