DPM : 이미지 전체를 전역적으로 분석한다. 슬라이딩 윈도우 접근 방식을 사용한다.
1. Introduction
- YOLO는 객체 탐지를 단일 회귀 문제로 재정의한 혁신적인 시스템이다.
- 이미지를 한 번만 보고 (You Only Look Once) 객체의 종류와 위치를 '동시에' 예측한다.
- 기존의 복잡한 탐지 파이프 라인과 달리 단일 신경망으로 처리된다.
- 파이프 라인
⑴ 각 단계가 서로 독립적이고, 개별적으로 학습된다.
⑵ 지역 제안, CNN 실행, 분류 등 여러 단계를 거치므로 연산량이 많고 속도가 느리다.
⑶ 각 단계가 따로따로 동작하기 때문에 전체 시스템을 통합적으로 최적화하기 어렵다. - 단일 신경망
⑴ YOLO의 입력 이미지를 처리해 경계 상자와 클래스 확률을 한 번에 예측한다.
⑵ 이미지 → 단일 신경망 → 최종 출력 (객체 탐지 결과)
⑶ 지역 제안이나 분리된 특징 추출 단계가 없어서 기존 파이프라인 방식보다 훨씬 빠르다.
⑷ 하나의 신경망으로 모든 작업을 처리하므로 실시간 처리가 가능하다.
⑸ 전체 모델을 통합적으로 학습할 수 있다.
- 파이프 라인
YOLO의 장점
- 속도가 빠르다.
- 실시간으로 비디오를 처리할 수 있다.
- 다른 실시간 탐지 시스템보다 두 배 이상의 평균 정밀도를 달성한다.
- 슬라이딩 윈도우, 지역 제안 기반 방식과 달리 훈련 및 테스트 시 이미지 전체를 분석한다.
- DPM이나 R-CNN보다 새로운 데이터나 예상치 못한 입력에서 더 안정적으로 동작한다.
YOLO의 단점
- 정확도 면에서 뒤쳐진다.
- 작은 객체의 정밀한 위치(localization) 탐지에서 어려움이 있다.
객체 탐지란?
- Localiszation(바운딩 박스 처리) + Classification(이미지 분류)
- 이미지로부터 특정 객체를 찾아주는 기술
- 이미지, 영상으로부터 객체를 찾아서 바운딩 박스를 표시해준다.
2. Unified Detection
- 개별적 구성 요소들을 하나의 신경망으로 통합했다.
- 전체 이미지의 특징을 사용하여 각 바운딩 박스를 예측한다.
- 이미지에 대한 모든 클래스의 모든 바운딩 박스를 동시에 예측한다.
- 이미지 전체와 이미지 내의 모든 객체에 대해 전역적으로 분석한다.
- 탐지 성능을 유지하면서 실시간 속도와 최적의 평균 정밀도를 가능하게 한다.
그리드 구조
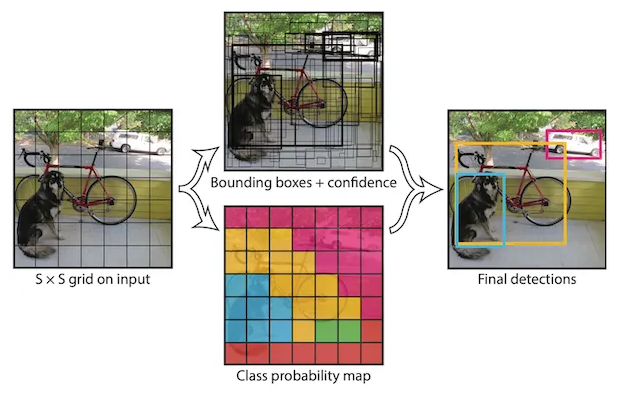
- 이미지를 S x S 그리드로 나눈다. (1 x 1 비율)
- 그리드 셀을 기준으로 바운딩 박스를 예측하고, 해당 바운딩 박스에 객체가 잇을 확률도 예측한다.
- 그리드 셀에 객체가 있을 경우에 클래스 별 확률도 예측한다.
- 두 과정을 조합하여 최종 결과를 만들어 낸다.
신뢰도 점수 (Confidence Score)
Confidence Score=Pr*IoU
Pr: 객체가 해당 상자에 존재할 확률
IoU(Truth Pred) : 실제 객체와 예측 객체의 교집합과 합집합을 통해 예측이 얼마나 정확한 지를 나타내는 값 (수치가 1에 가까울수록 좋다)- (바운딩 박스 안에 객체가 확실히 없으면)
0*IoU=0 - (바운딩 박스 안에 객체가 확실히 있으면)
1*IoU=IoU
- (바운딩 박스 안에 객체가 확실히 없으면)
- 바운딩 박스 안에 객체가 있다면, 신뢰도 점수는 예측된 실제 상자 간의
IoU와 동일해야 한다.
바운딩 박스 예측
x,y: 상자의 중심 좌표 (그리드 셀 기준 상대 좌표)w,h: 상자의 너비와 높이 (이미지 전체 기준 상대 크기)- Confidence : 예측된 상자와 실제 상자 간의 IoU
클래스 확률 예측
- 각 그리드 셀은 조건부 클래스 확률을 예측한다.
- 하나의 그리드 셀은 하나의 클래스 확률 세트만 예측하며, 예측된 상자 B의 개수와는 관계가 없다.
최종 클래스별 신뢰도 점수 계산
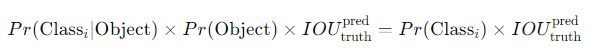
- 조건부 클래스 확률로 각 상자의 신뢰도 점수를 곱하여 계산한다.
출력 텐서의 구조
- 입력 이미지를 S x S 그리드로 나누고, 각 그리드 셀에서 정보를 예측한다.
B: 경계 상자의 수5: 각 상자의 좌표와 신뢰도 (x,y,w,h,confidence)C: 클래스 확률 (데이터셋의 클래스 개수)
=>S x S ( B x 5 + C)
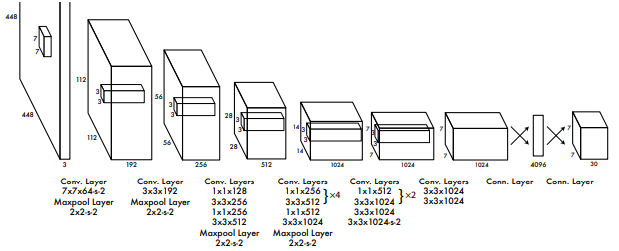
2.1 Network Design

448 * 448크기의 이미지를 입력받는다.7 * 7필터를 통해 이미지의 간단한 특징을 추출한다.- 스트라이드 값을 통해 이미지의 크기를 줄여나간다.
- 2, 3번 과정을 반복하며 최종 결과에서 입력받은 이미지의 객체(클래스)를 결정한다.
일단 내가 이해한거
- 합성곱 계층 : 이미지에서 중요한 저수준 특징(가장자리, 간단한 패턴)을 추출한다.
- 필터 : 입력 이미지에서 특징 패턴을 감지하는 역할을 하는 작은 행렬
- 스트라이드 : 합송곱 계층에서 필터가 입력 데이터를 가로지르며 이동하는 간격 (입력 데이터에서 샘플링의 밀도와 출력 크기에 영향을 미친다.)
- 작은 스트라이드 : 더 세밀한 특징을 유지한다.
- 큰 스트라이드 : 크기를 빠르게 줄이고, 연산량을 감소시킨다. - 만약 스트라이드가 2라면, 이미지의 크기는
⁒2만큼 줄어든다. (112 * 112→56 * 56..)
- 입력 이미지
1 2 0 1 2
4 5 1 3 1
1 0 2 4 1
3 1 0 1 2
1 1 3 0 2- 필터링 (3 * 3)
-1 0 1
-1 0 1
-1 0 1- 계산 결과 (특징 맵)
-3 1 0
-5 2 0
3 -2 4- 이런식으로 필터 크기와 스트라이드를 조절함으로써 이미지의 크기를 줄여나간다.
- 필터링하면서 이미지의 크기를 줄여나가지만, 채널의 개수(직육면체의 가로)가 늘어나면서 더 많은 패턴을 학습한다.
- 초기 계층에서는 간단한 모양을, 중간 계층에서는 구조적 특징을 감지한다. 최종 계층에서는 감지한 특징들을 통해 최종 클래스를 결정하게 된다.
- 초기 계층과 중간 계층의 과정은 동일하나, 각 계층에서 감지하는 특징에 차이가 있다. (위 설명과 동일)
- 위 이미지에서는 최종적으로
7 * 7 * 30텐서를 출력한다.
2.2 학습 (Training)
- 합성곱 계층을 1000개의 클래스 데이터셋에서 미리 학습시켰다.
- 미리 학습시킨 모델에 합성곱 계층(convolutional layer)과
average pooling layer,fully connected layer을 사용하였다. - 약 1주일 간 학습한 결과, 단일 크롭 기준 상위 5개의 정확도가 88%에 도달했으며, 이는 GoogleNet 모델과 비슷한 수준이다.
- 그 후, 이 모델을 탐지 작업에 맞게 수정했다. 사전 학습된 네트워크에 합성곱 계층과 완전 연결 계층을 추가하면 성능이 향상된다고 주장하였다.
Loss Function
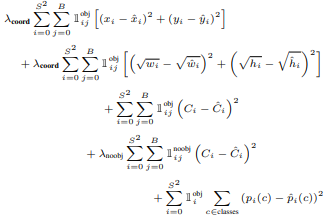
[ 1 ] : i번째 그리드 셀의 j번째 바운딩 박스가 객체 하나를 책임지고 있는지에 대한 여부
[ 2 ] : Localization의 비중을 늘리기 위한 값
[ 3 ] : 바운딩 박스의 크기에 따른 오차 차별을 없애기 위해 루트(√)를 씌운다.
λcoord: 위치 손실의 중요도를 강화하기 위해 사용됨λnoobj: 객체가 없는 배경 셀의 손실을 줄이기 위해 사용됨
i : 그리그 셀 (7 x 7의 경우 49개의 그리드 셀이 된다.)
j : 바운딩 박스
(그리드 셀마다 갖고 있는 바운딩 박스의 수??)
지시 함수 : i번째 그리드 셀에 j번째 바운딩 박스가 객체 하나를 책임지고 있는지에 대한 여부이다.
-> 책임을 지고 있다면 1, 아니면 0
- YOLO에서는 여러 개의 그리드 셀, 여러 개의 바운딩 박스에 속하는 것이 아니라, 한 개의 그리드 셀, 한 개의 바운딩 박스에 속하게 된다. ⇒ "그리드 셀을 책임진다"
- 바운딩 박스의 중심점이 위치한 그리드 셀만이 강아지 객체를 갖게 된다. → 나머지 그리드 셀은 객체가 없는 그리드 셀이 된다.
- 객체가 있는 바운딩 박스의
x좌표와,y좌표, 높이와 너비를 학습시킨다. - 너비와 높이의 루트(√) : 바운딩 박스의 크기에 따라 로스율 차별을 없애기 위함
예시) 실제 10, 예측 5 → 차이 5 / 실제 100, 예측 50 → 차이 50 ⇒ 바운딩 박스가 크면 객체의 크기가 크면 더 큰 오류로 인식한다. 그렇기 때문에 루트(√)를 씌움으로써 차이를 줄인다.
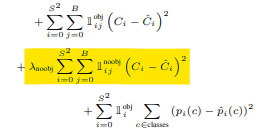
-
x,y,w,h⇒ Localization 값 -
Localization 값에 비중을 주기 위해서 '이 값'을 준다고 ...?
-
논문의 경우 Localization 값에 5를 주었다. ⇒ 로스율이 커진다.
-
로스율이 커지면 비중이 커진다.
-
confidence score는 객체가 없으면 0이라는 답을 줘야 한다.
그렇기 때문에 객체가 없는 경우도 학습을 해야 한다.
보통은 이미지에서 객체가 없는 그리드 셀이 훨씬 많기 때문에 학습 비중을 맞춰주기 위해 비중을 줄여준다. -> 1보다 작은 값을 줘야 함 (논문에서는 0.5)
- 각 그리드 셀 별로 객체가 있을 경우에 클래스의 확률
- 그리드 셀 별 값이니까 지시 함수가 그리드 셀까지만 있다 ..?
- 객체가 없으면 0이 된다 -> 객체가 있는 경우에만 클래스 별로 전부 예측을 한다.

- 이미지가 입력되면 7 x 7 x 30의 텐서가 만들어진다.
- 49개의 그리드 셀
- 셀마다 30개의 값
- 5개의 바운딩 박스 두 개
- 객체가 존재할 경우 클래스별 확률 (20개의 클래스)
객체가 존재할 경우에
클래스 별 confidence score 값
그리드 셀마다 바운딩 박스가 두 개씩 존재한다.
객체가 존재할 경우 클래스 별 확률은 20개
뭘 어떻게 다 곱하면 총 40개가 만들어짐
그리드가 49개이므로, 바운딩 박스는 그 두 배의 값인 98개가 된다.
클래스 별로 객체 탐지 과정을 수행한다.
예시 : 강아지 클래스 - 5번
클래스 별 confidence score가 특정 값 이하인 경우를 다 제거한다.
임계값이 2라고 했을 때, confidence score가 0.2 이하인 놈들은 다 제거된다. ⇒ 강아지 주변에만 바운딩 박스가 남는다.
NMS 알고리즘
- 바운딩 박스들의 서로 IoU 값을 비교한다.
- IoU 값이 서로 0이면 같은 클래스지만, 다른 객체로 본다.
- 예시 : IoU 값이 0이면 같은 강아지 클래스지만, 서로 다른 강아지로 인식된다.
- 만약 IoU 값이 0보다 크면, 바운딩 박스가 겹친다는 의미
같은 객체가 아닌데도 겹친다 -> 임계값을 지정해준다
임계값이 0.5면 절반만 겹쳐도 같은 객체로 본다고 ..?
겹치는 객체 중에 confidence score 값이 높은 객체만 남겨둔다.
2.3 Interference
2.4 Limitations of YOLO
- 강한 공간적 제약 : 각 그리드 셀이 두 개의 경계 상자만 예측할 수 있고, 하나의 클래스만 가질 수 있다.
- 새롭거나 독특한 구성을 다루기 어렵다.
- 바운딩 박스 예측 시 사용되는 특징이 비교적 조잡하다.
- 손실 함수의 한계 : 작은 바운딩 박스와 큰 바운딩 박스의 오류를 동일하게 취급한다.
- 모델이 정확한 위치를 찾는 데 어려움이 있다.
3. 다른 감지 시스템과의 비교
- DPM (Deformable Ports Model)
DPM은 정적 특징(이미지, 신호 등) 추출, classify region. 바운딩 박스 예측 등의 작업이 분리된 파이프라인을 가집니다.
하지만, YOLO는 feature extraction, 바운딩 박스 예측, non-maximal suppression, contextual reasoning 모두 동시에 가능하여 빠르고 정확합니다. - R-CNN
R-CNN에서 진행하는 파이프라인은 상당히 복잡합니다. DPM에서 사용한 슬라이딩 윈도우 대신에 region proposal 을 사용합니다.
세부적으로는, selective search 로 potential 바운딩 박스들을 찾고, convolutional network 가 특징을 추출하고, SVM이 박스들을 scoring 하고, linear model 이 바운딩 박스를 조정하고, non-maximal suppression 이 duplicate detection 을 제거합니다. 이러한 과정들은 각각 개별적으로 tuning 되어야 하고 학습이 느립니다.
하지만, YOLO는 이러한 individual components 를 하나의 모델로 optimize 할 수 있어서 더 빠릅니다. - Other Fast Detectors
Fast R-CNN, Faster R-CNN 은 sharing computation 과 selective search 대신 neural network 를 사용해 R-CNN 의 속도를 개선합니다. 하지만 그럼에도 real-time performance 부족했습니다. 같은 맥락으로 많은 연구가 DPM pipeline 을 speed-up 하는데 초점을 맞추었지만 30Hz 까지만 지원하는 등 부족한 점이 존재했습니다.
YOLO 는 그 방법론에 대한 디자인 자체가 빠르기 때문에 real-time performance 에서도 좋은 성능을 보입니다. - Deep MultiBox
R-CNN 과 달리 multibox 는 selective search 대신 convolutional neural network 를 사용했습니다. 하지만 single object detection 은 가능하지만 multiple object detection 을 구현하지는 못했습니다.
YOLO 는 classification probabilities 를 두어 multiple object detection 이 가능합니다. - OverFeat
OverFeat 은 앞서 등장했던 R-CNN 과 DPM 과 마찬가지로 disjoint 한 system 을 가지고 있는 문제를 포함해서 prediction 을 내릴 때 local information 만을 보아 prediction 에 global context 반영하기 어려웠습니다. 또한 일관된 결과를 내려면 significant 한 post-processing 이 필요한 점도 단점입니다.
YOLO 는 local 한 patch 에 대한 classifying 이 아닌 한 번의 모델 학습으로 이루어지기 때문에 global context 를 충분히 반영할 수 있습니다. - MultiGrasp
YOLO 의 grid approach 의 기원인 MultiGrasp 는 하나의 object 를 포함한 이미지에서 graspable region 을 예측해내는 비교적 간단한 작업에 사용됩니다.
YOLI 는 이런 MultiGrasp 에 기반하여 이미지 속 다중 라벨의 다중 물체의 bounding box 와 classification probabilities 를 찾아낸다는 점에서 더욱 복잡한 문제를 해결했습니다.
5. Real-Time Detection in the Wild
- YOLO는 빠르고 정확하게 물체를 감지한다.
- 웹캠을 사용하여 카메라에서 이미지를 가져오고, 표시하느 시간을 포함하여 실시간 성능을 유지하는지 확인할 수 있다.
- 결과적으로 YOLO는 상호작용적이고, 동시 이미지에 부착된 경우 개별적으로 이미지를 처리한다.
- 웹캠은 추적 시스템처럼 작동하며, 물체가 이동하는 동안 물체를 감지하고 외관을 변화시킨다.
- 시스템 및 소스 코드 데모 : http://pjreddie.com/yolo/
6. Conclusion
- YOLO는 객체 감지를 위한 통합 모델이다.
- YOLO는 구성이 간단하고 학습이 가능하다.
- 전체 이미지에 직접 표시된다.
- 분류 기반 접근 방식과 달리, YOLO는 직접적으로 대응하는 손실 함수에 대해 훈련된다.
- 실시간 성능을 감지하고 전체 모델이 학습된다.
