부스트캠프 ai tech 4주차에 배운 내용을 정리하는 글입니다.
Leveraging pre-trained information
Transfer learning
Approach 1: Transfer knowledge from a pre-trained task to a new task
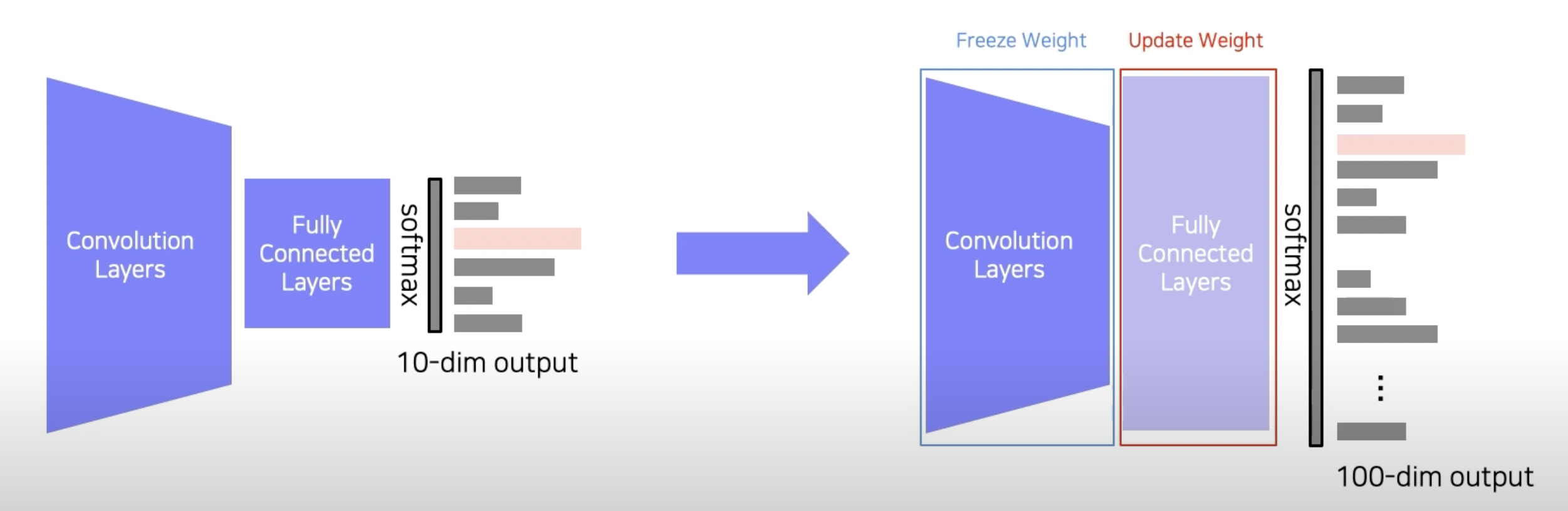
Approach 2: Fine-tuning the whole model
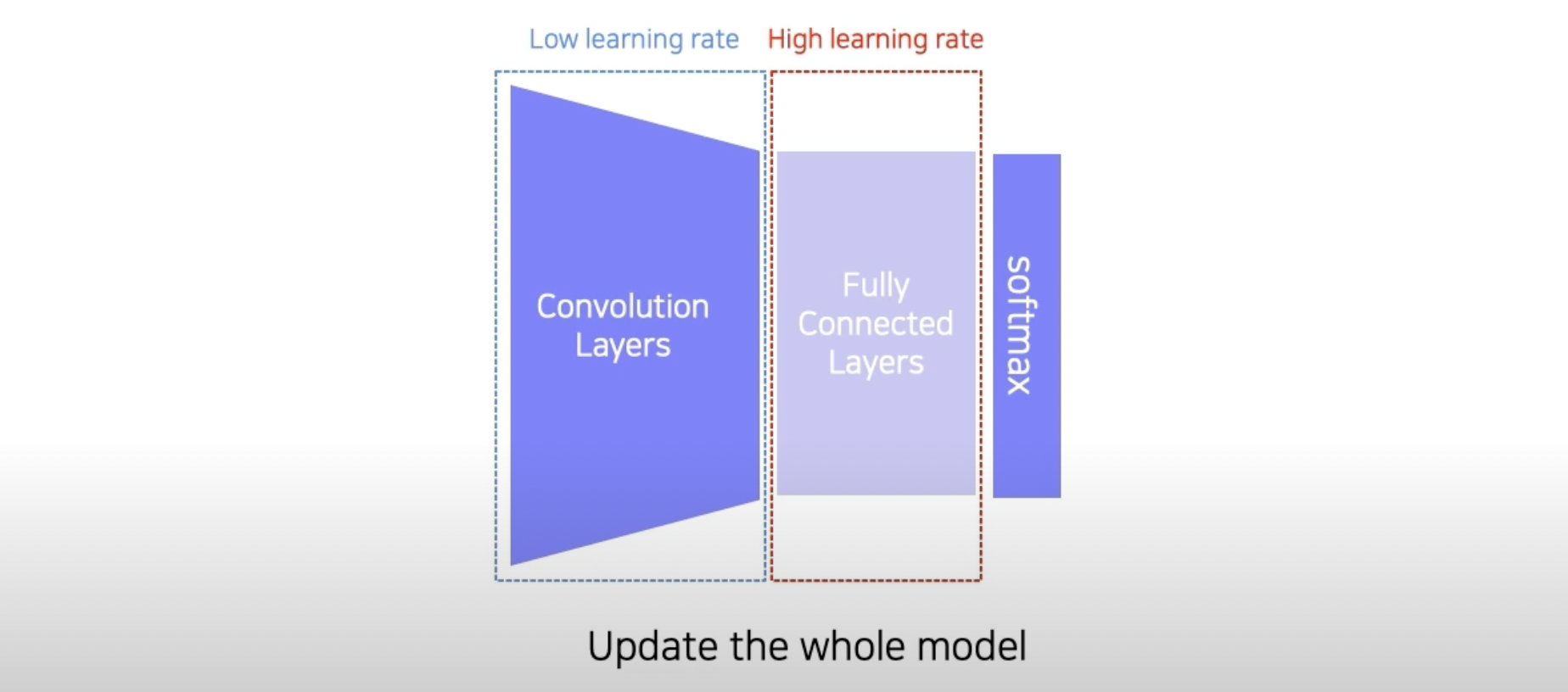
Knowledge distillation
Teacher-student network structure
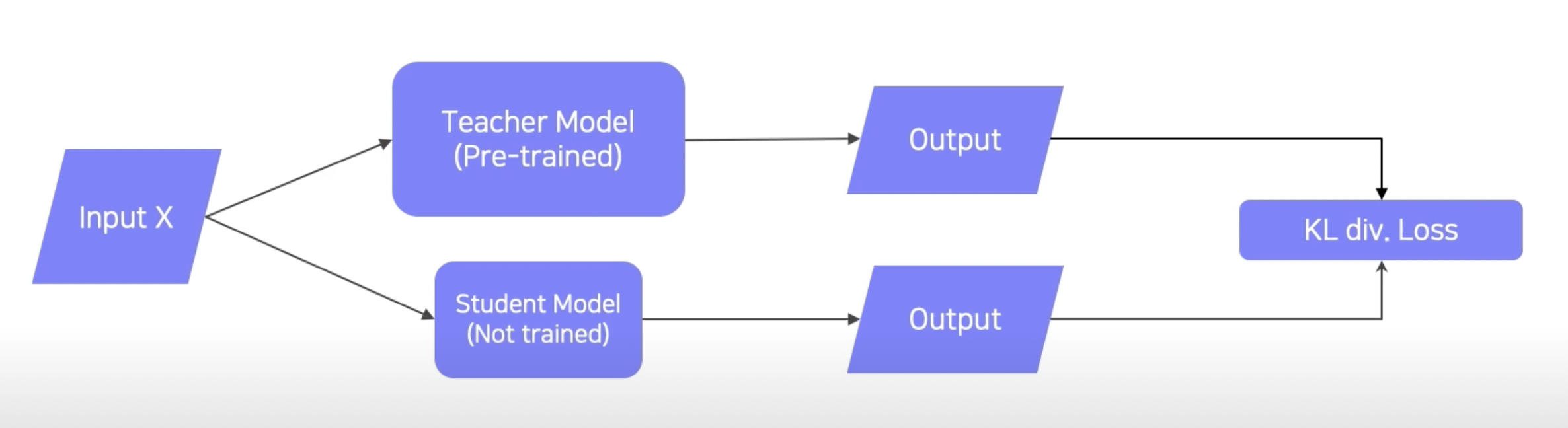
- input을 teacher model(pre-trained)과 student model(not trained, 보통 teacher model보다 작음)에 넣음
- 각 output의 차이를 KL divergence loss로 측정
- back propagation을 통해 student model만 학습(KL divergence를 이용해 두 모델의 분포가 비슷해지게끔 학습 → student model을 teacher model처럼 학습시키기)
특징
- label을 사용하지 않음 → unsupervised learning처럼 생각해도 됨
- 넣어주는 input이 teacher model의 pre-train에 사용된 input과 같을 필요는 없음 → 임의의 데이터 사용 가능
labeling된 데이터를 가지고 있을 때의 Knowledge distillation
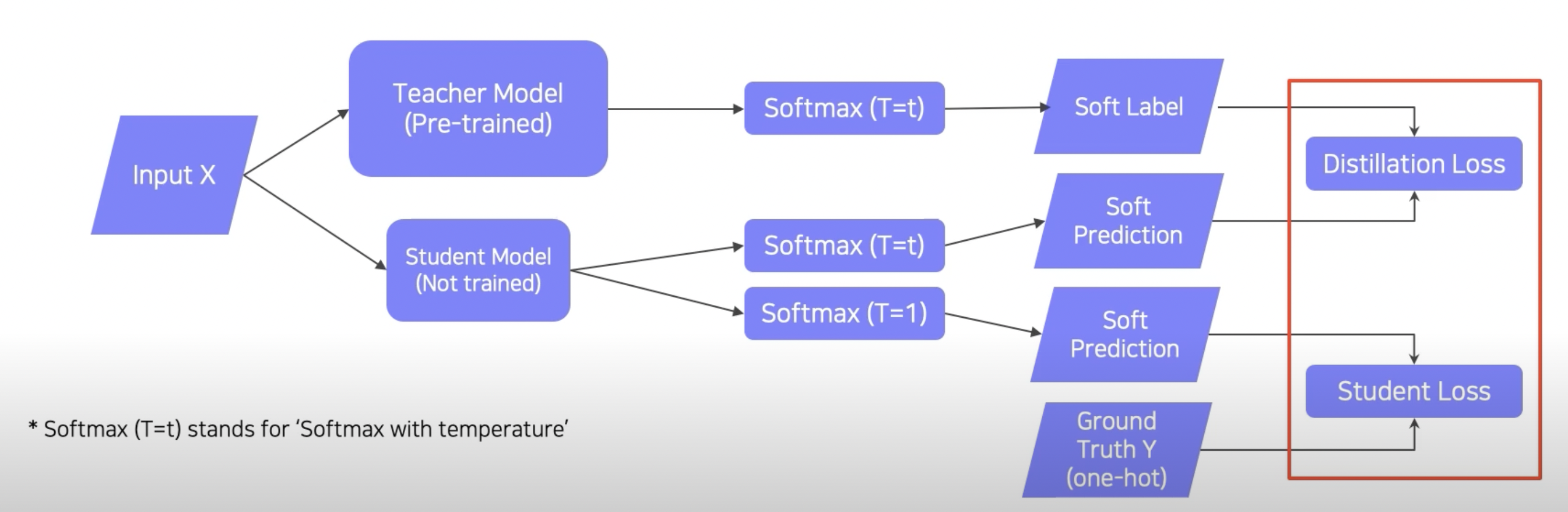
Ground Truth Y(one-hot): true labelStudent Loss: true label을 통해 나오는 loss- ground truth라는 hard label이 존재
- CrossEntropy(Hard label, Soft prediction)
- 목적: student model이 옳은 답을 찾게끔 만들기
Distillation Loss: KL divergence Loss- 목적: student model이 teacher model을 따라 하게 만들기
hard labelvs.soft label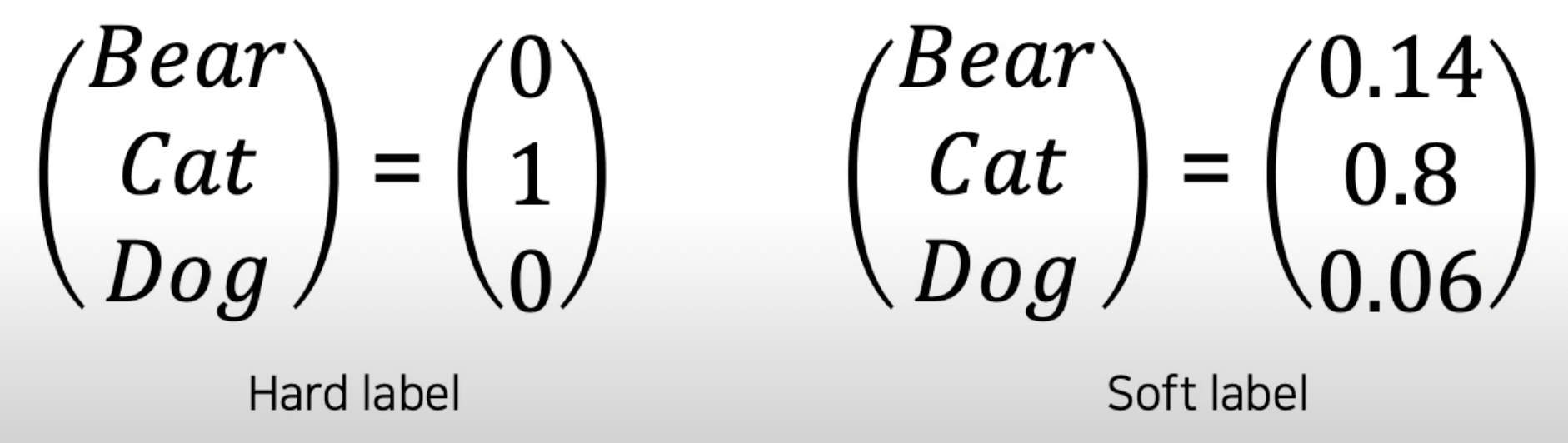
- Softmax with temperature(T)

- 마찬가지로 Distillation Loss와 Student Loss의 weighted sum을 이용한 back propagation을 통해 student model만 학습
Leveraging unlabeled dataset for training
Semi-supervised learning
labeling된 데이터(적음)와 labeling 되지 않은 데이터(많음)를 함께 사용
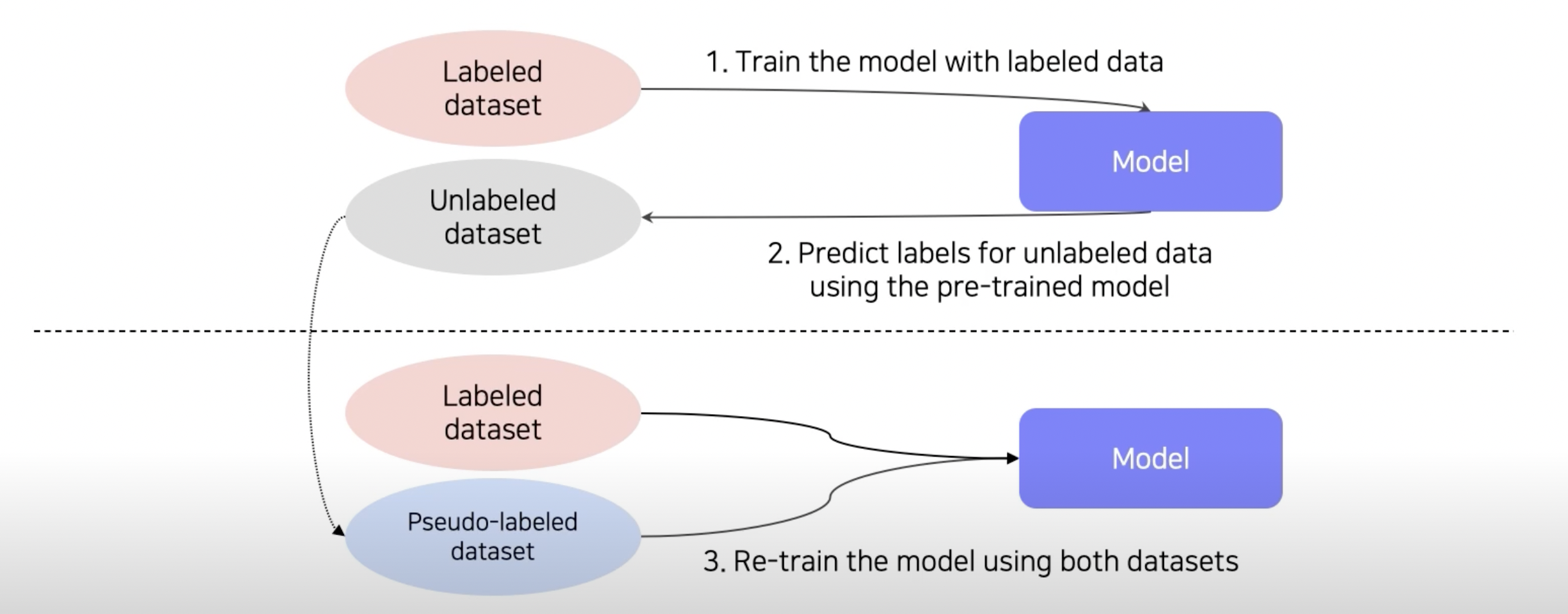
- labeled dataset을 이용해서 model을 pre-train
- pre-trained model을 이용해 unlabeled dataset의 pseudo-label을 잔뜩 생성
- 기존에 있던 labeled dataset과 우리가 만든 pseudo-labeled dataset을 합쳐서 re-train
Self-training
- Augmentation + Teacher-Student networks + semi-supervised learning
Self-training with noisy student
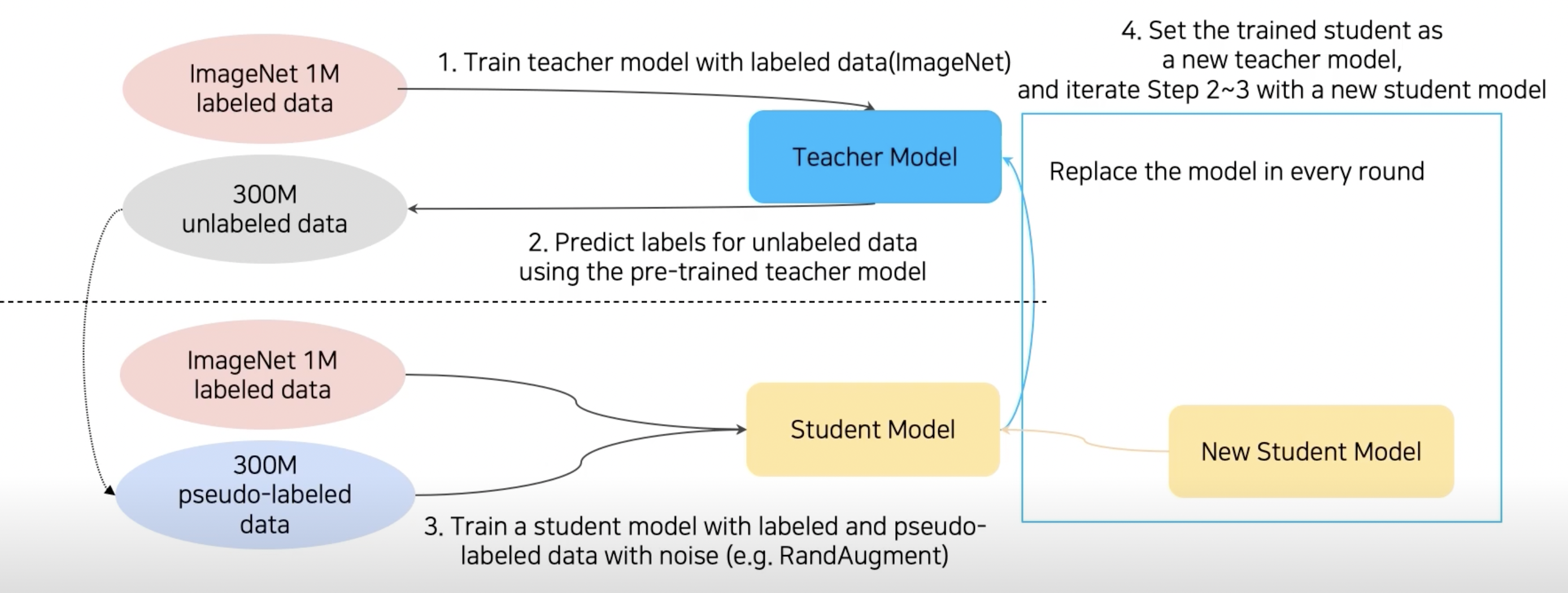
- ImageNet dataset을 이용해 teacher model을 학습
- teacher model을 이용해 unlabeled data → pseudo labeled data
- labeled data + pseudo labeled data에 RandAugment를 이용해 data를 더 증가시킴
- 이렇게 준비된 데이터를 통해 student model을 학습
- 기존 teacher model을 날려버리고 학습된 student model을 teacher model로 사용해 위 과정을 반복(위에 있는 Knowledge distillation에서는 student model이 teacher model보다 작았지만 이 방법에서는 round마다 더 큰 student model을 사용)
