부스트캠프 강의 정리
1.Maximum Likelihood Estimation(MLE)

부스트캠프 ai tech 1주차에 배운 내용을 정리하는 글입니다.Maximum Likelihood Estimation란?maximum likelihood method(최대가능도방법, 최대우도법): 어떤 확률변수에서 표집(sampling)한 값들을 토대로 그 확률변수의
2.Gradient Descent
부스트캠프 ai tech 1주차에 배운 내용을 정리하는 글입니다.Gradient Descent란?함수의 기울기를 구하고 기울기의 반대 방향으로 계속 이동시켜 극값에 이를 때까지 반복시키는 방법https://ko.wikipedia.org/wiki/경사\_하강법예
3.자동 미분
계산 그래프(computational graph)란?계산 그래프는 계산 과정을 그래프로 나타낸 것계산 그래프를 사용하는 이유는?계산 그래프의 장점은 국소적 계산 - 전체적인 계산이 복잡해도 각 노드는 자신과 관련된 계산만 하면 됨. 또한 중간 계산 결과를 노드에 저장할
4.Optimization
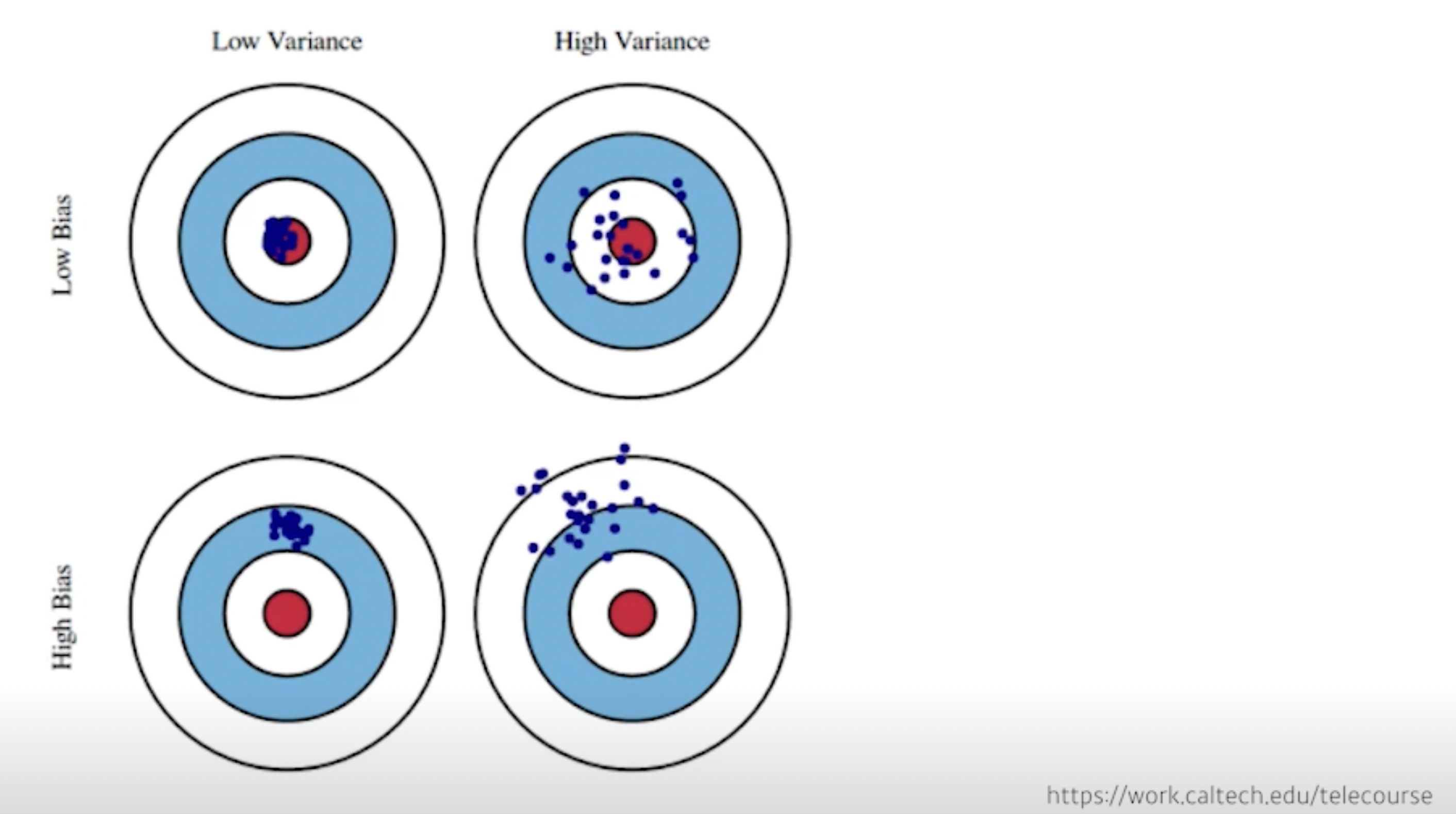
부스트캠프 ai tech 3주차에 배운 내용을 정리하는 글입니다. (핸즈온 머신러닝 2판 참고)아래 용어의 컨셉을 잘 이해하자Generalization(일반화 성능): training error와 test error의 차이/일반화 성능이 좋다는 것은 test data에
5.Modern Convolutional Neural Networks
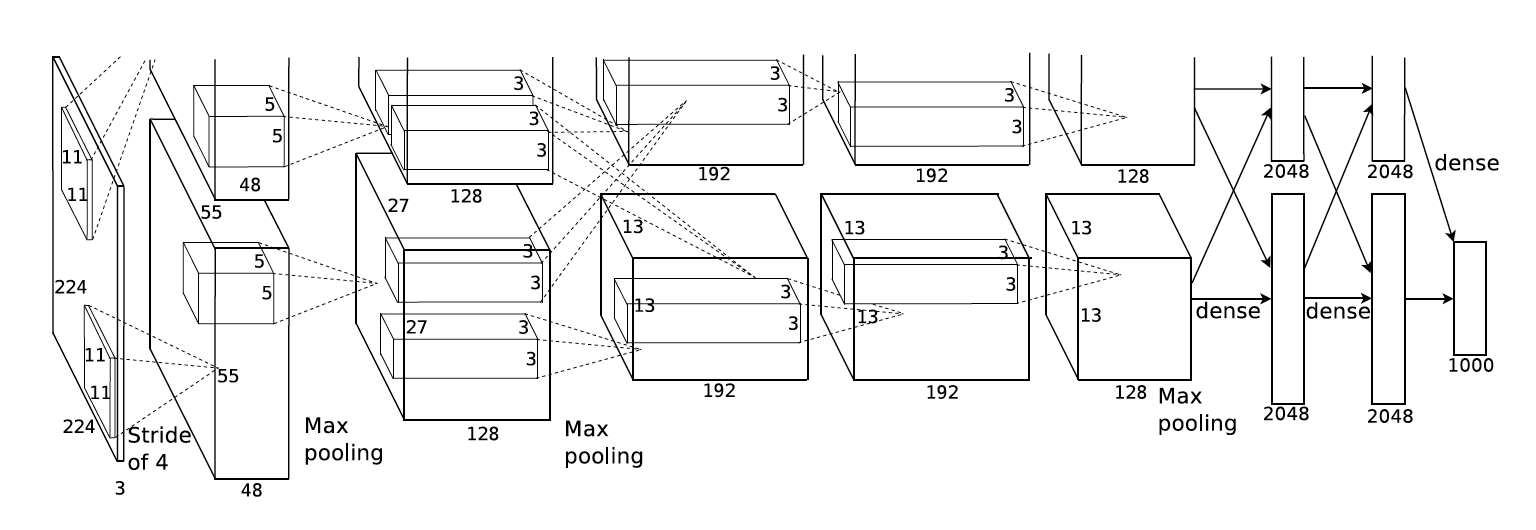
부스트캠프 ai tech 3주차에 배운 내용을 정리하는 글입니다.모델의 파라미터 수가 늘어날수록 학습이 어렵고 generalization performance가 떨어진다고 알려짐 → 그렇기 때문에 파라미터 숫자를 줄이는 여러 테크닉이 존재어떤 모델을 봤을 때 파라미터가
6.Computer Vision Applications (Semantic Segmentation and Detection)
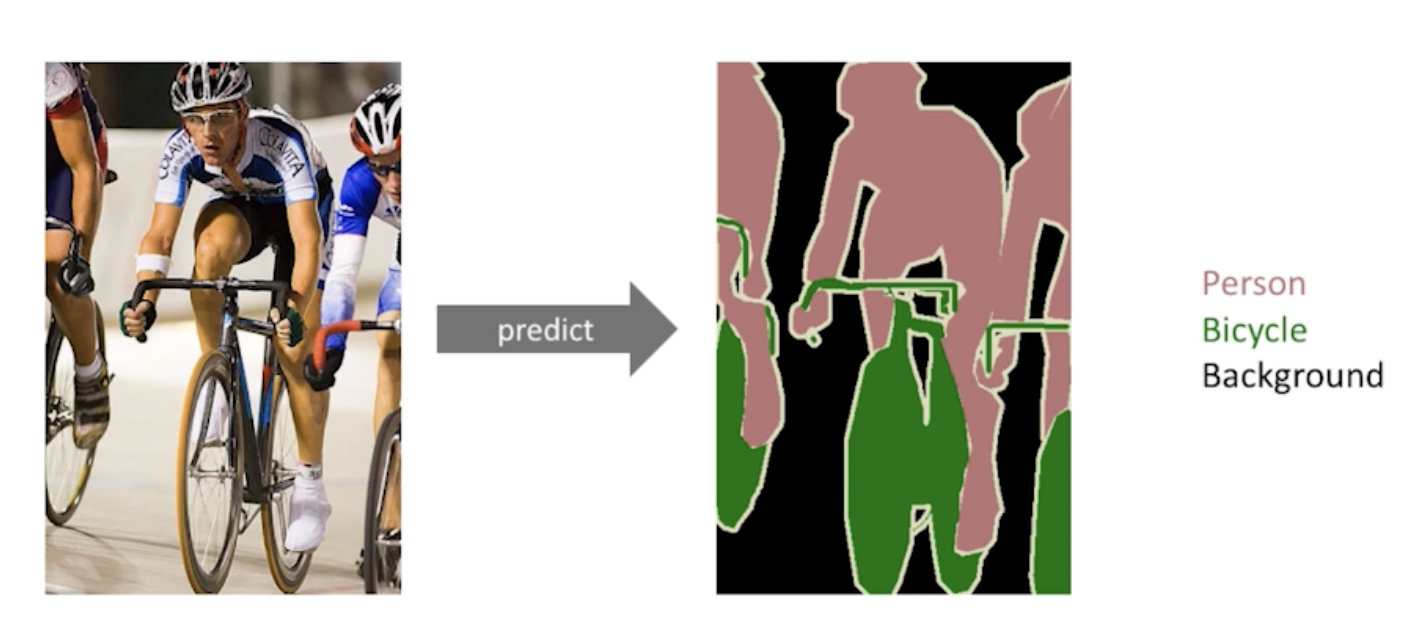
부스트캠프 ai tech 3주차에 배운 내용을 정리하는 글입니다.이미지의 각 픽셀이 어떤 라벨에 속하는지를 알아내는 문제(각 픽셀마다 분류)convolutionalization: (dense layer를 없애는 과정, 위 사진에서 아래 사진처럼)두 과정 모두 파라미터
7.Recurrent Neural Networks
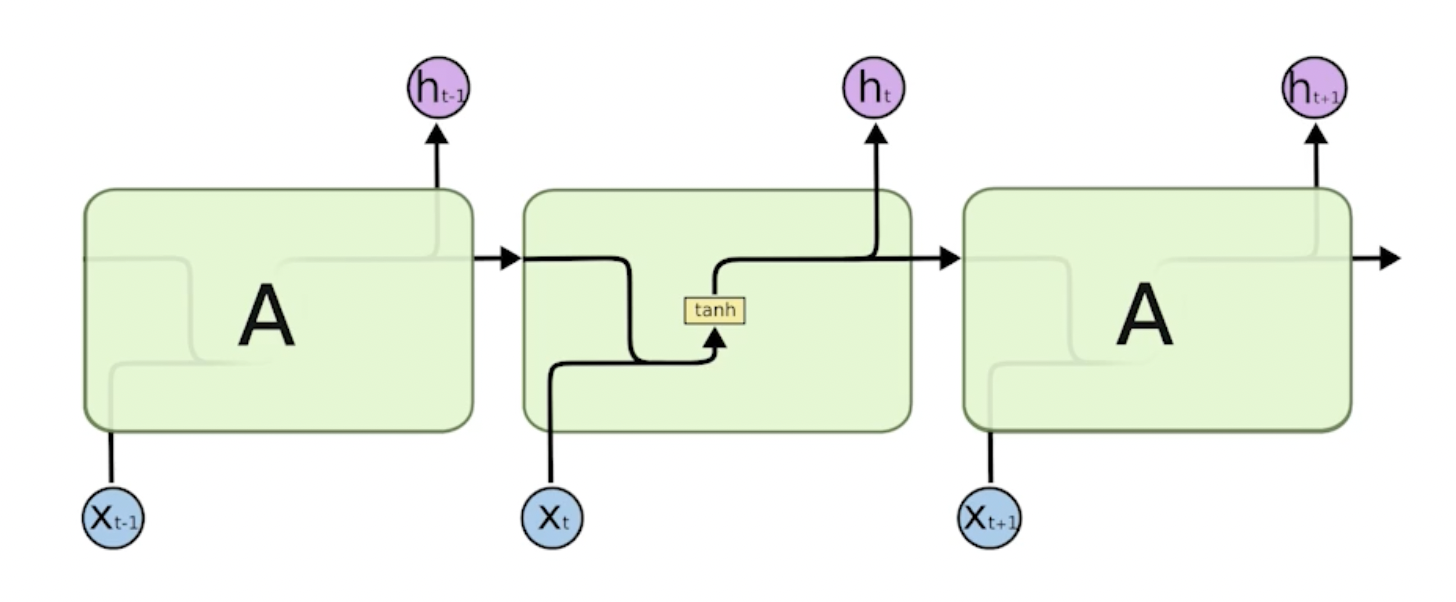
부스트캠프 ai tech 3주차에 배운 내용을 정리하는 글입니다.기본 RNNLSTMprevious cell state: 네트워크 밖으로 나가지 않고 0부터 t까지의 정보를 summarize해줌(컨베이어 벨트)gate: 컨베이어 벨트에 올리고, 빼고, 조작함previou
8.Transformer
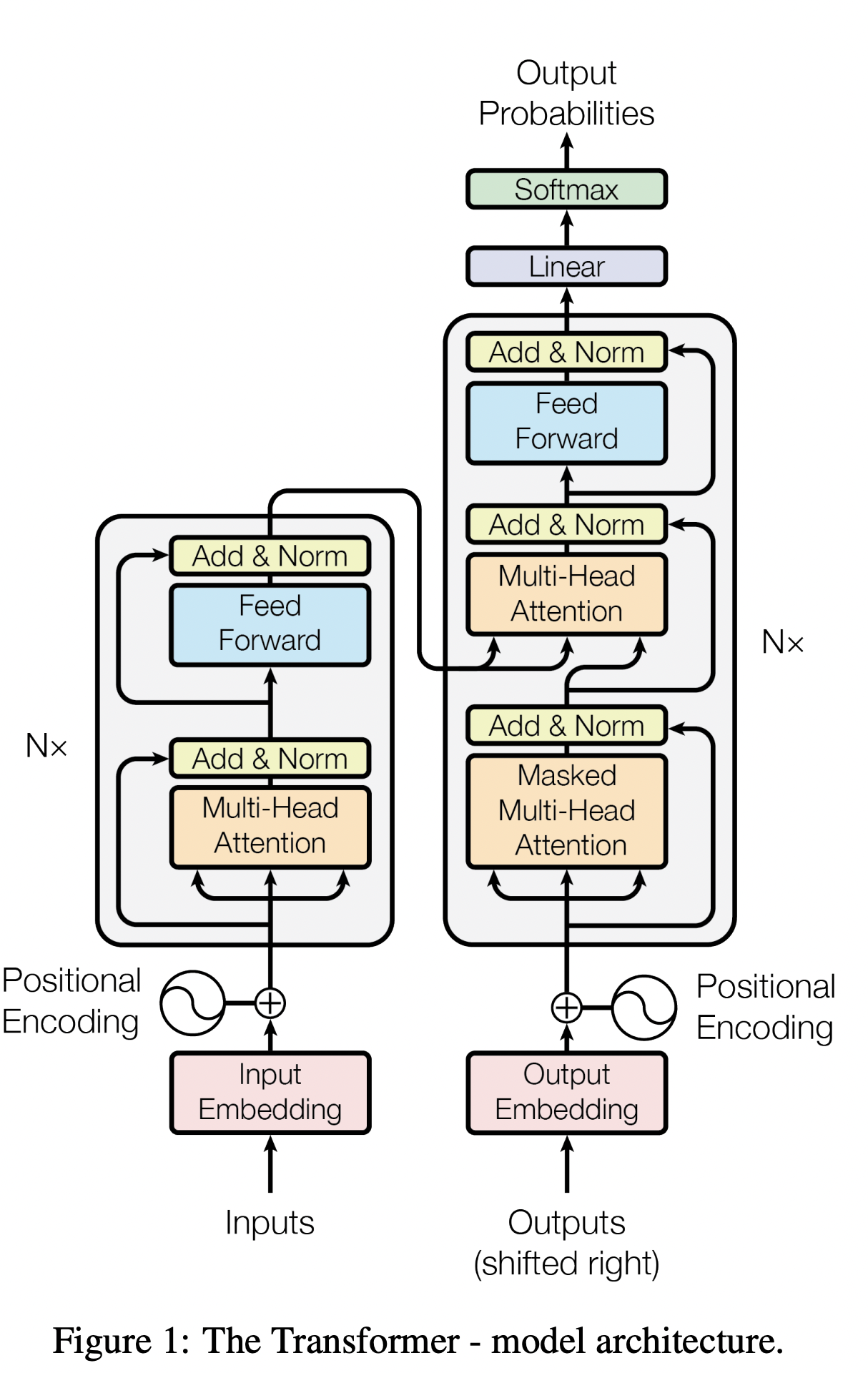
부스트캠프 ai tech 3주차에 배운 내용을 정리하는 글입니다.참고 자료https://jalammar.github.io/illustrated-transformer/https://acdongpgm.tistory.com/2211 2 3 4 5 6 7이라
9.Beyond ResNets
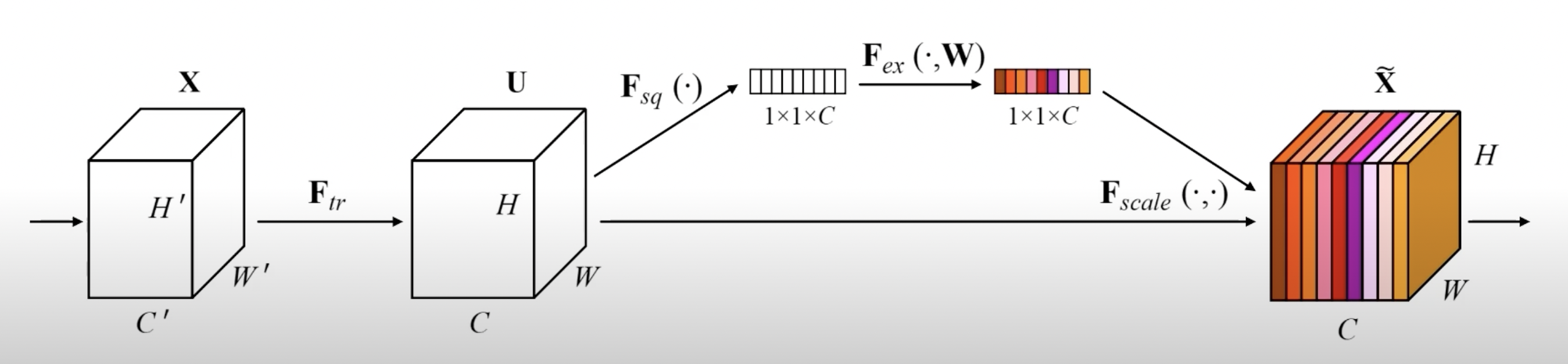
부스트캠프 ai tech 4주차에 배운 내용을 정리하는 글입니다.3주차 내용과 이어지는 내용입니다.(https://velog.io/@jswon/Modern-Convolutional-Neural-Networks)DenseNetdense block에서는 각 lay
10.Leveraging pre-trained information and unlabeled dataset for training
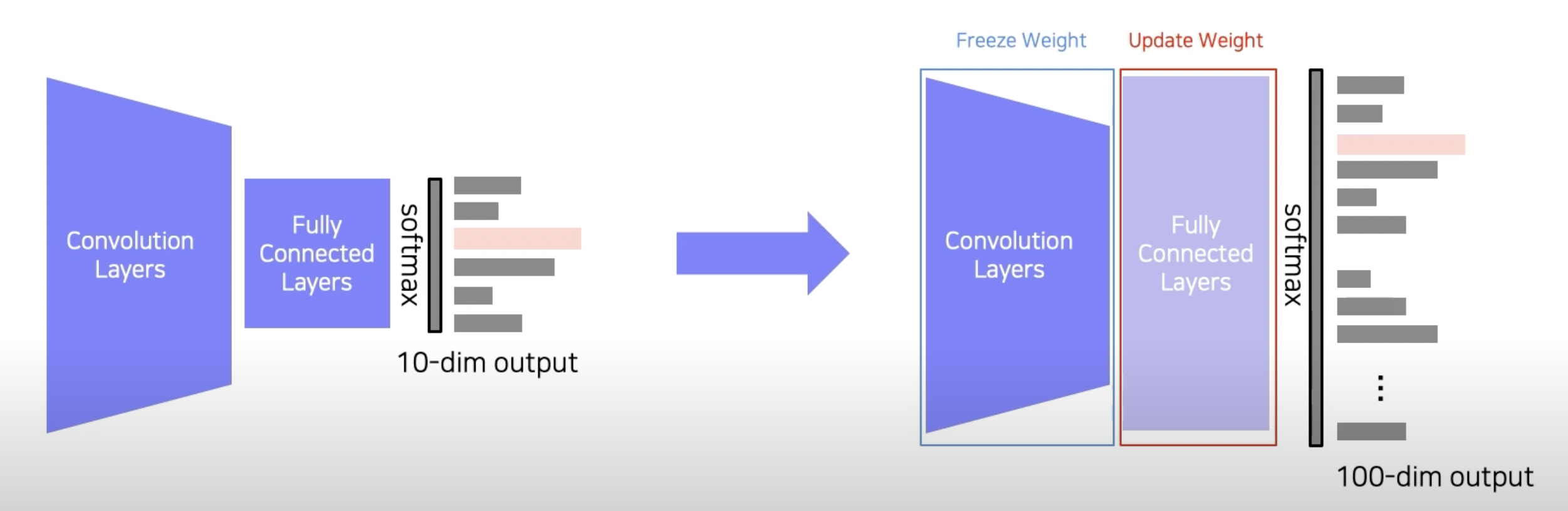
부스트캠프 ai tech 4주차에 배운 내용을 정리하는 글입니다.input을 teacher model(pre-trained)과 student model(not trained, 보통 teacher model보다 작음)에 넣음각 output의 차이를 KL divergenc
11.Semantic Segmentation
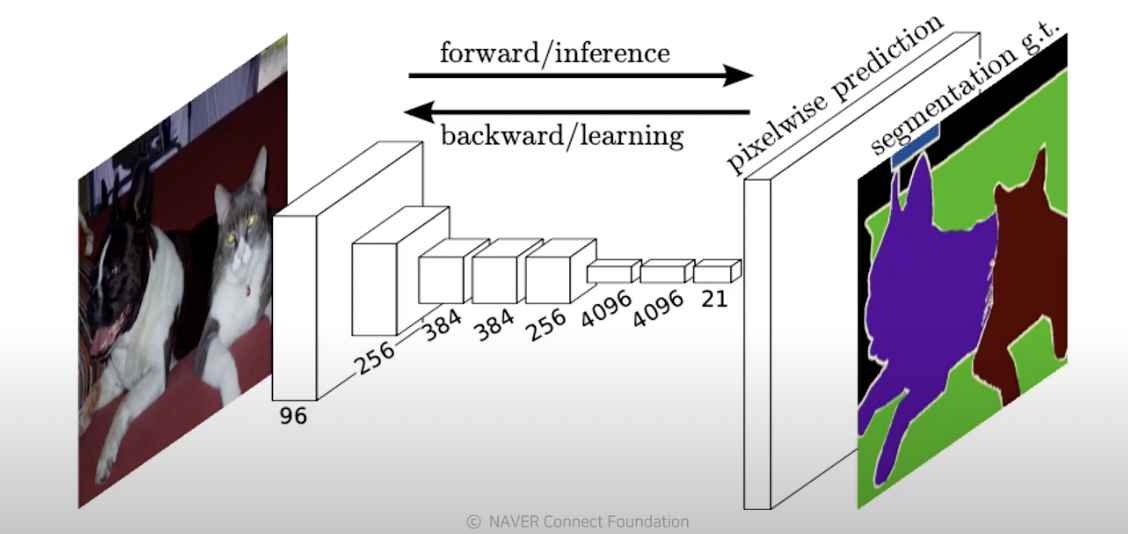
부스트캠프 ai tech 4주차에 배운 내용을 정리하는 글입니다.픽셀 단위로 카테고리를 분류하는 작업instance 단위까지 구분하진 않음(어깨동무를 하고 있는 두 사람이 있을 때 두 사람을 각각 분류하진 않음)왼쪽으로 갈수록 receptive field가 작음 → 디