부스트캠프 ai tech 3주차에 배운 내용을 정리하는 글입니다.
참고 자료
https://jalammar.github.io/illustrated-transformer/
https://acdongpgm.tistory.com/221
1 2 3 4 5 6 7이라는 문장이 있음(original sequence)
1 2 3 4 5 → Trimmed sequence
1 2 4 7 → Omitted sequence
2 3 4 6 5 7 → Permuted sequence
sequence가 항상 1 2 3 4 5 6 7이 아님. 섞일 수도 있고 빠질 수도 있고.. → 모델링 하기 어려움 → 그래서 나온 것이 Transformer
Transformer
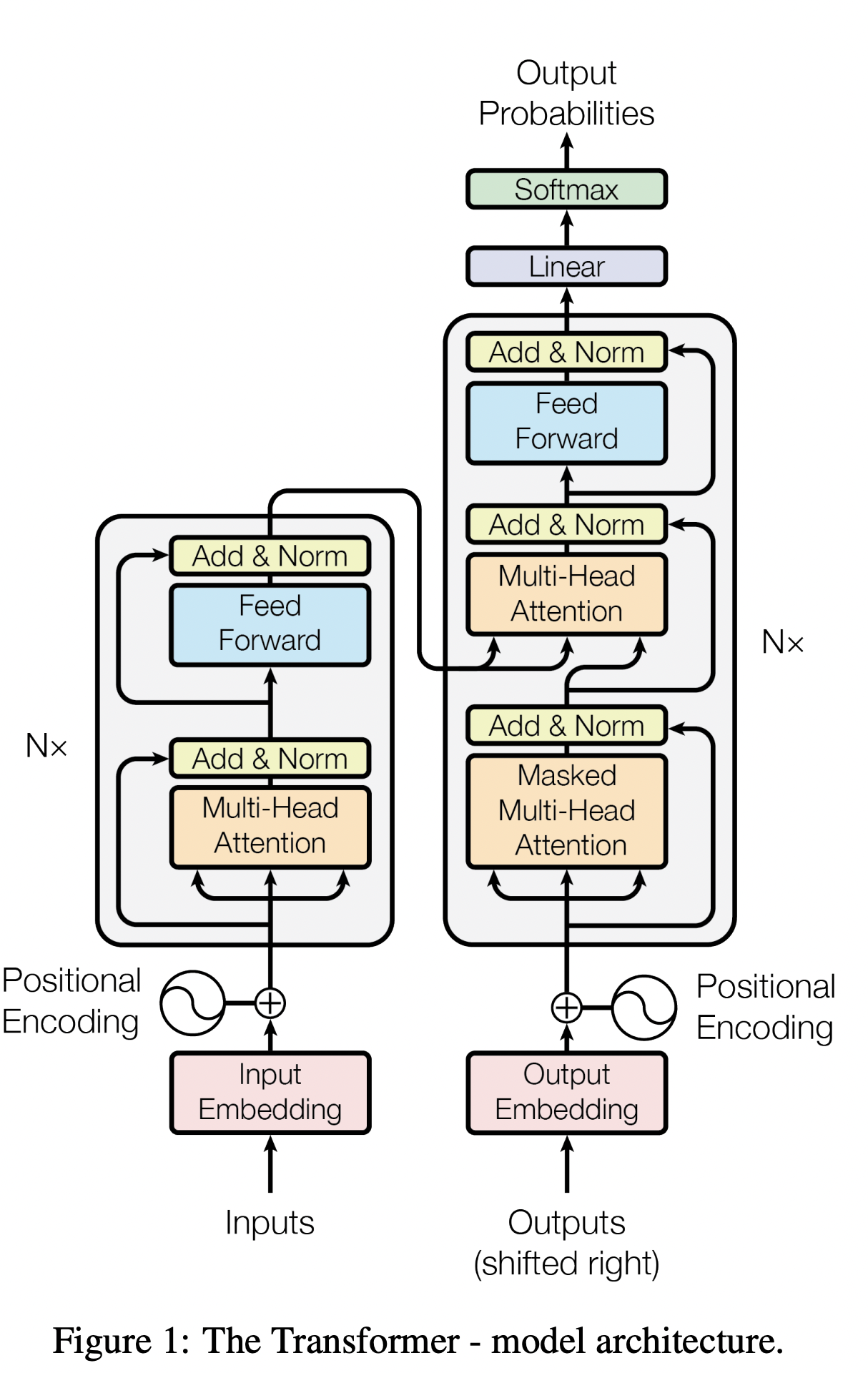
Transformer는 Sequential 한 데이터를 처리하고 encoding 하는 방법임
가장 큰 특징: Attention이라는 구조를 사용함
아래 Transformer 설명은 NMT(기계어 번역, Neural Machine Translation)를 하는 과정임(Transformer는 Sequential 한 데이터를 처리하고 encoding 하는 방법이기 때문에 NMT뿐 아니라 여러 문제에 적용될 수 있음)

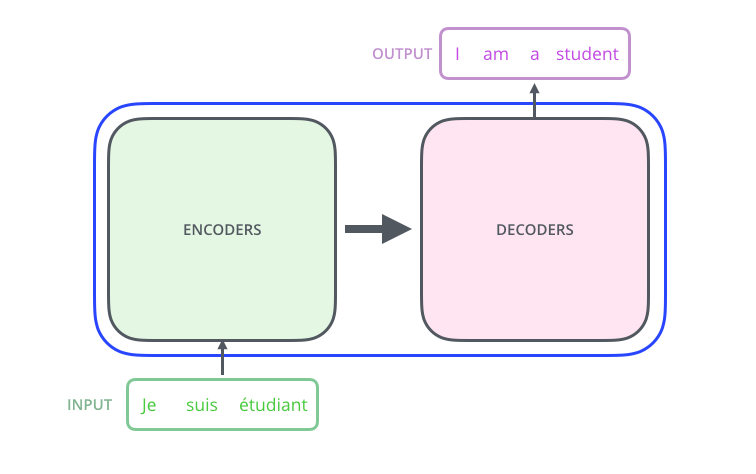
sequence to sequence model
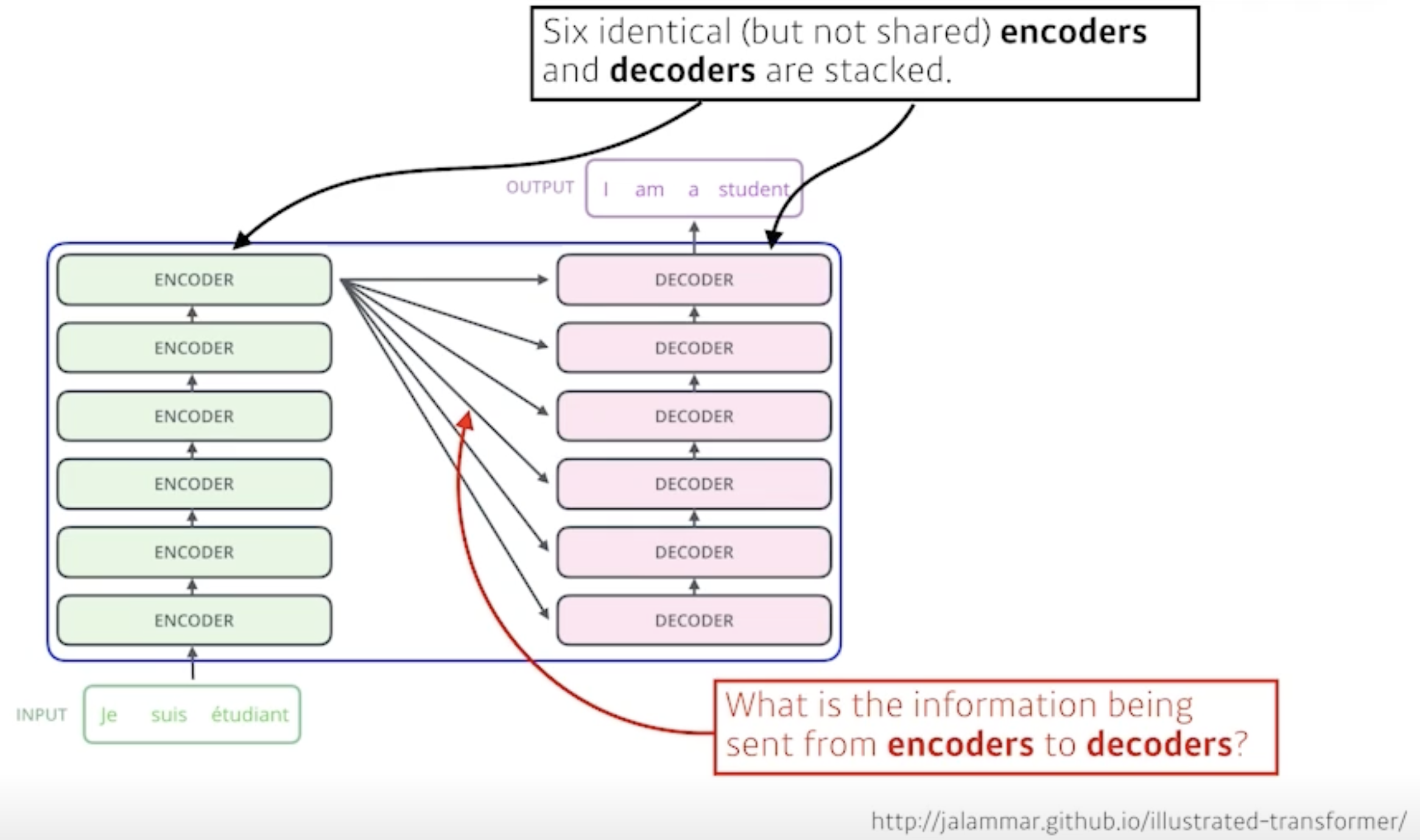
위 사진으로부터 알 수 있는 점
- 입력 sequence의 단어 수(3)와 출력 sequence의 단어 수(4)가 다를 수 있다.
- 입력 sequence의 domain(불어)과 출력 sequence의 domain(영어)이 다를 수 있다.
- 모델은 하나다.
- 입력 단어가 몇 개든 encoder가 한 번에 처리한다.(RNN처럼 한 단어, 한 단어 재귀적으로 돌지 않음)
- 서로 다른 파라미터를 갖지만 동일한 구조인 encoder와 decoder가 stack 되어 있는 구조다.
이해해야 할 점
- n개의 단어가 encoder에서 어떻게 한 번에 처리되나?
- encoder와 decoder 사이에 어떤 정보를 주고 받나?
- decoder가 어떻게 generate를 할 수 있나?
Encoder
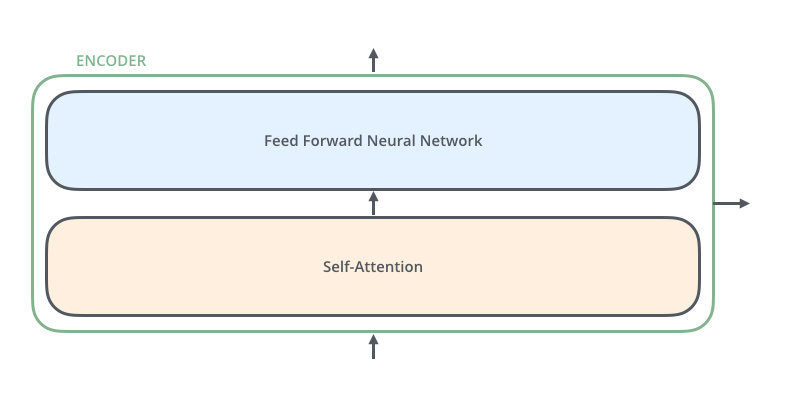
Feed Forward Neural Network는 MLP와 동일함
Self-Attention이 중요!
Self-Attention
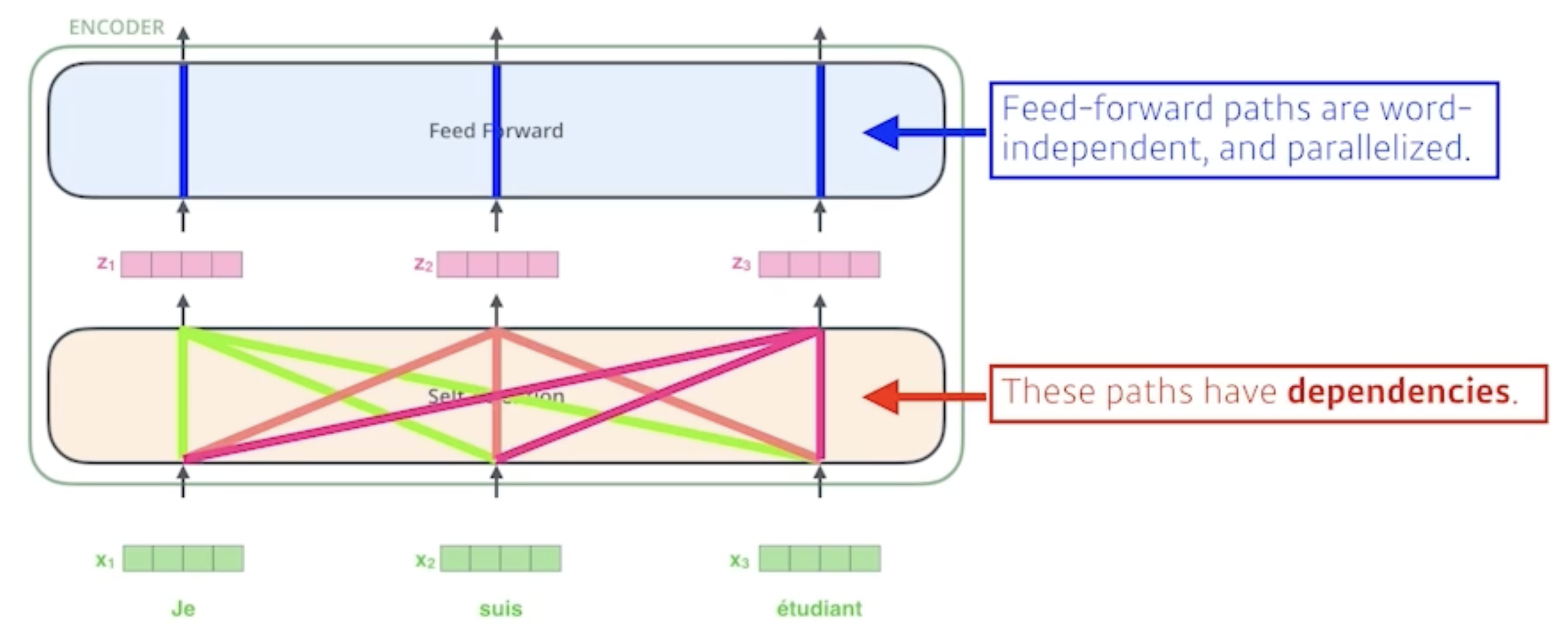
n개의 벡터(위 그림에서는 x1, x2, x3)가 들어오면 각각의 벡터(z1, z2, z3)를 찾아줌
중요한 점이 z1을 만드는 데 x1뿐만 아니라 x2, x3도 고려함
z2를 만드는 데에도 x2만 사용하는 것이 아니라 x1, x3도 고려함
z3도 마찬가지
→ 각 단어들이 흘러가는 경로가 dependent함(Feed Forward는 independent하게 통과)
왜 이렇게 함?

The animal didn’t cross the street because it was too tired.라는 문장이 있을 때
it이 뭔지 모르니 어떤 단어와 dependent 한지를 알고 싶음 → it이 문장 속 다른 단어들과 어떻게 interaction 하는지 알아야 함 → self attention 과정을 통해 it이 animal과 관련되어 있다는 것을 학습할 수 있음
어떻게 함?
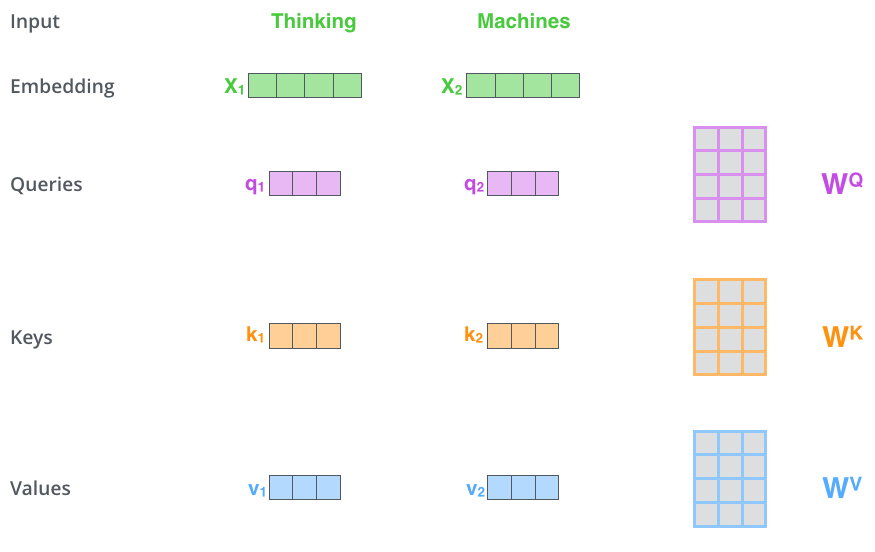
각 input(그림에서는 Thinking이라는 단어와 Machines라는 단어)에 대해 각각 3개의 벡터를 만듦(3개의 뉴럴 네트워크가 있다는 뜻) → x1의 Query, key, value와 x2의 Query, key, value → 얘네를 통해 x1 벡터, x2 벡터를 새로운 벡터로 바꿔줄 것임
x1 벡터 encoding 하기
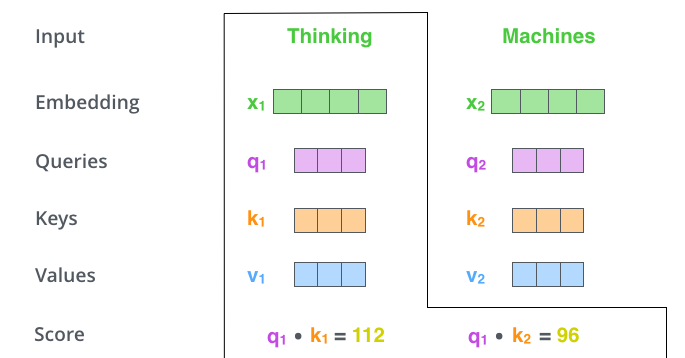
score vector: x1의 query vector인 q1과 모든 input의 key vector를 내적(i 번째 단어가 나머지 n개의 단어와 얼마나 유사한지 → Attention → 어떤 단어를 더 주의 깊게 볼지)
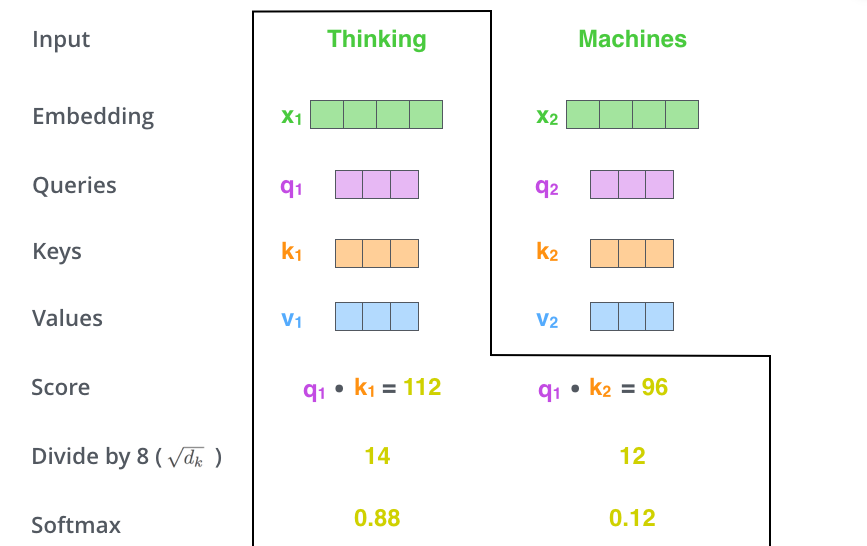
score vector normalize: key vector의 dimension(, 얘는 하이퍼파라미터임. 위 예시에서는 64)에 square root를 취해서 나눠줌(score 값이 너무 커지지 않게 하려고 하는 것)
다음으로 softmax 취해줌
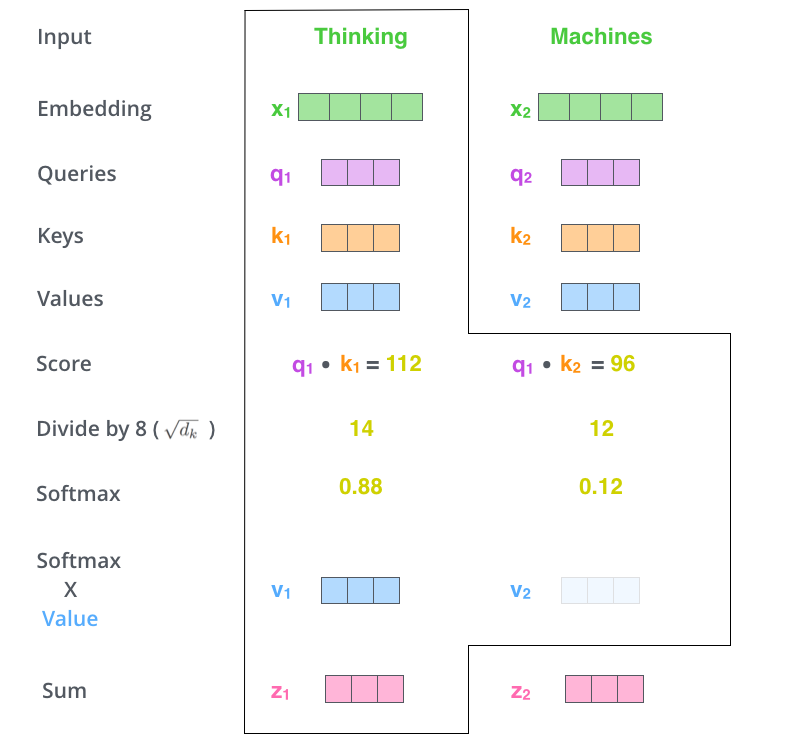
softmax를 취해서 나온 값을 각각의 value vector와 곱한 뒤 다 더함 → 각 value vector에 weight를 준 뒤 더하는 것임(z1 = 0.88 v1 + 0.12 v2)
(다시 말해 value vector의 weight을 query vector와 key vector로 구한 것임)
여기서 알 수 있는 점
- query vector와 key vector는 내적을 해야 하기 때문에 차원이 같아야 함
- value vector는 차원이 같을 필요가 없겠지
- encoding된 vector의 차원은 value vector의 차원과 같겠지
정리
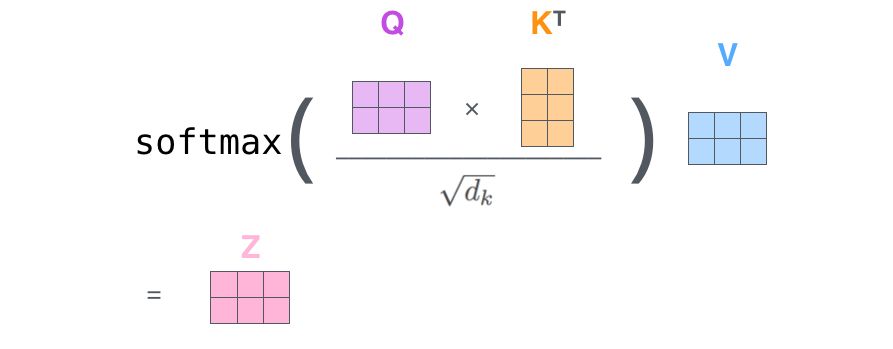
이게 왜 잘 되는 것일까?
a라는 입력이 있을 때 출력이 b로 고정되는 것이 아니라 a 옆에 뭐가 있느냐에 따라 출력이 c가 될 수도 있고 d가 될 수도 있음(옆에 뭐가 있냐에 따라 encoding 한 값이 달라지니까) → 유연하기 때문에 많은 것을 표현할 수 있음
유연한 만큼 계산도 많음 → bottleneck: 단어가 1000개 들어오면 1000 by 1000짜리 입력을 처리해야 함(RNN은 단어 1개씩 1000번 돌리면 됨)
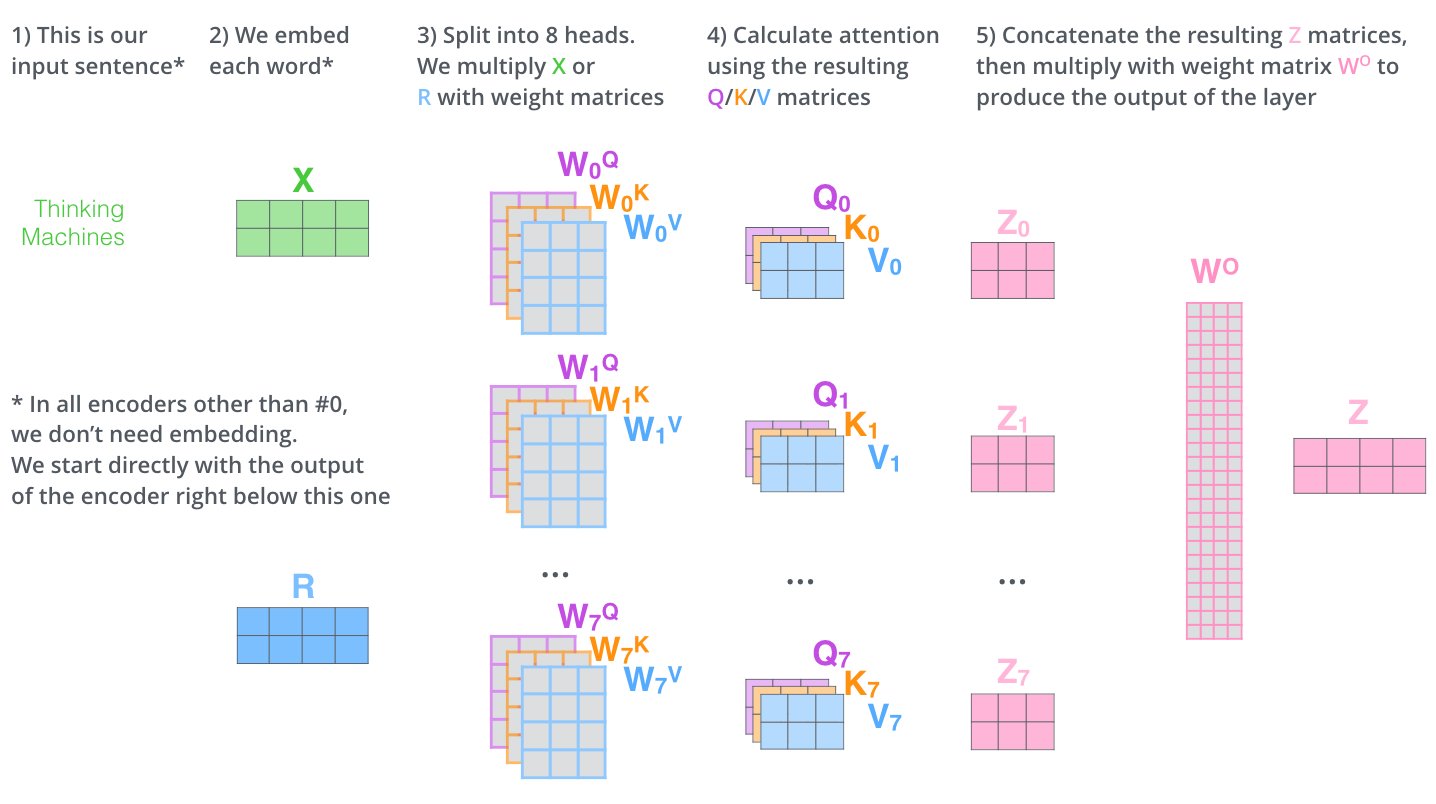
multi-headed attention
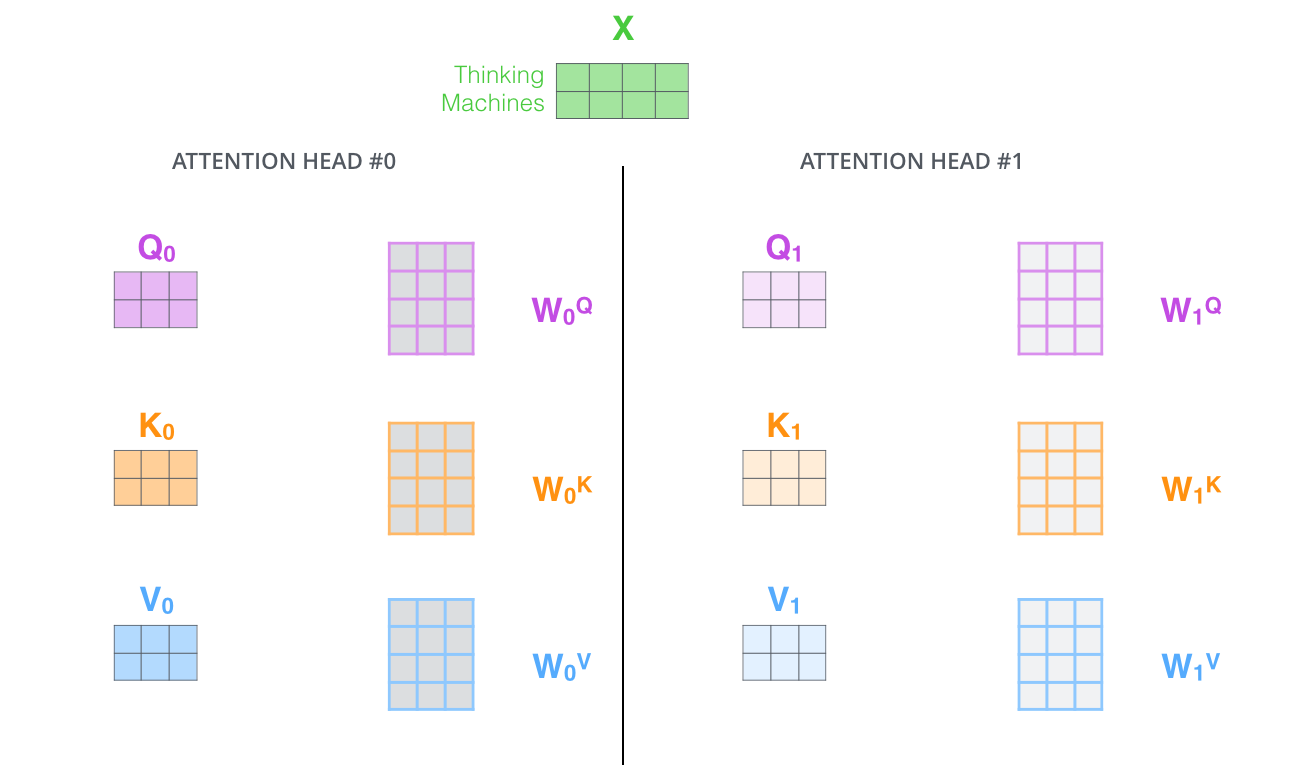
하나의 입력에 대해서 query, key, value를 여러 개 만듦
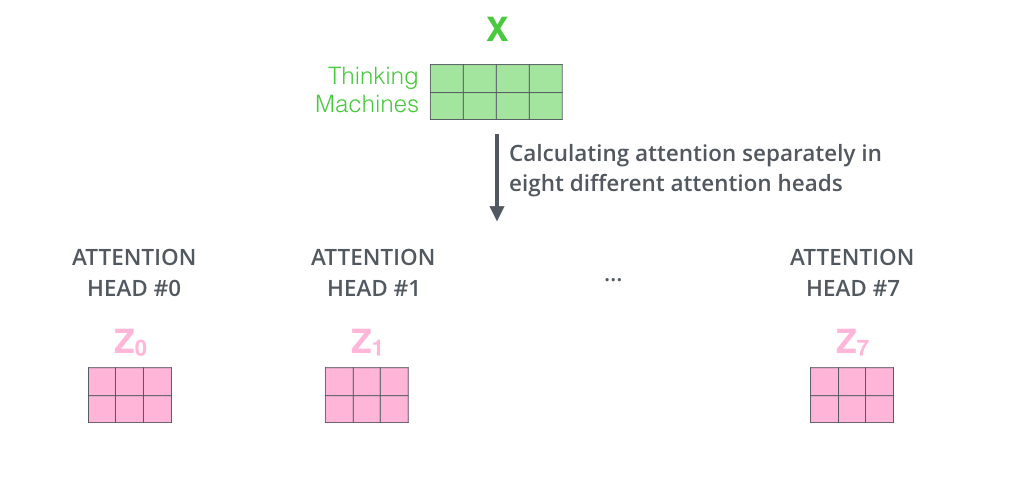
여기선 8개의 encoding된 vector가 나옴
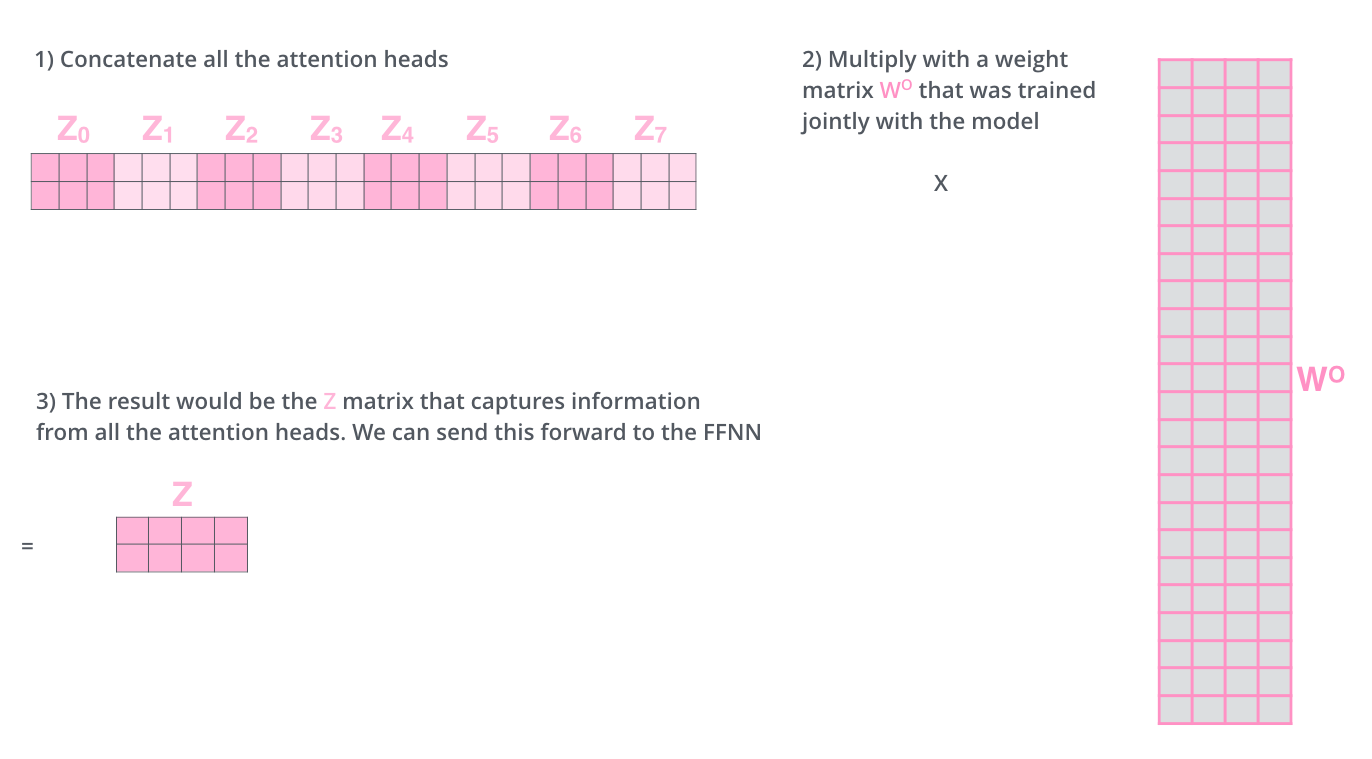
encoding된 vector가 다음 encoder로 넘어가야 하기 때문에 input과 차원이 같아야 함
10차원 8개를 합치면 80차원 → 80 by 10 행렬을 곱해서 다시 10차원으로 줄여줌
실제 구현에서는 다름. 만약 input이 100차원이고 head가 10개면 input을 10개로 쪼개서 10차원짜리 입력 10개에 대한 query, key, value vector를 만듦
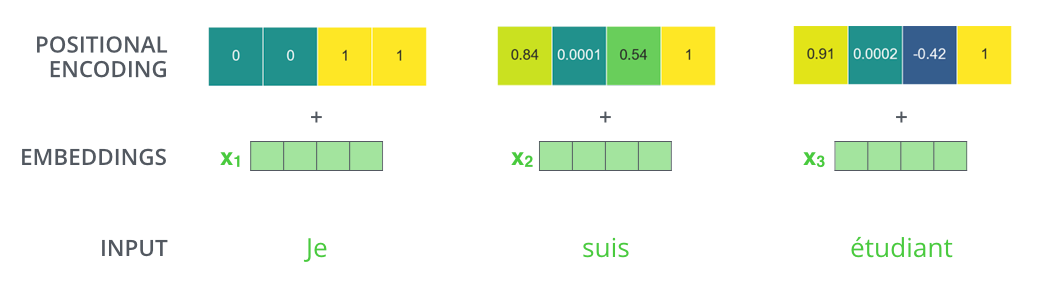
Positional Encoding
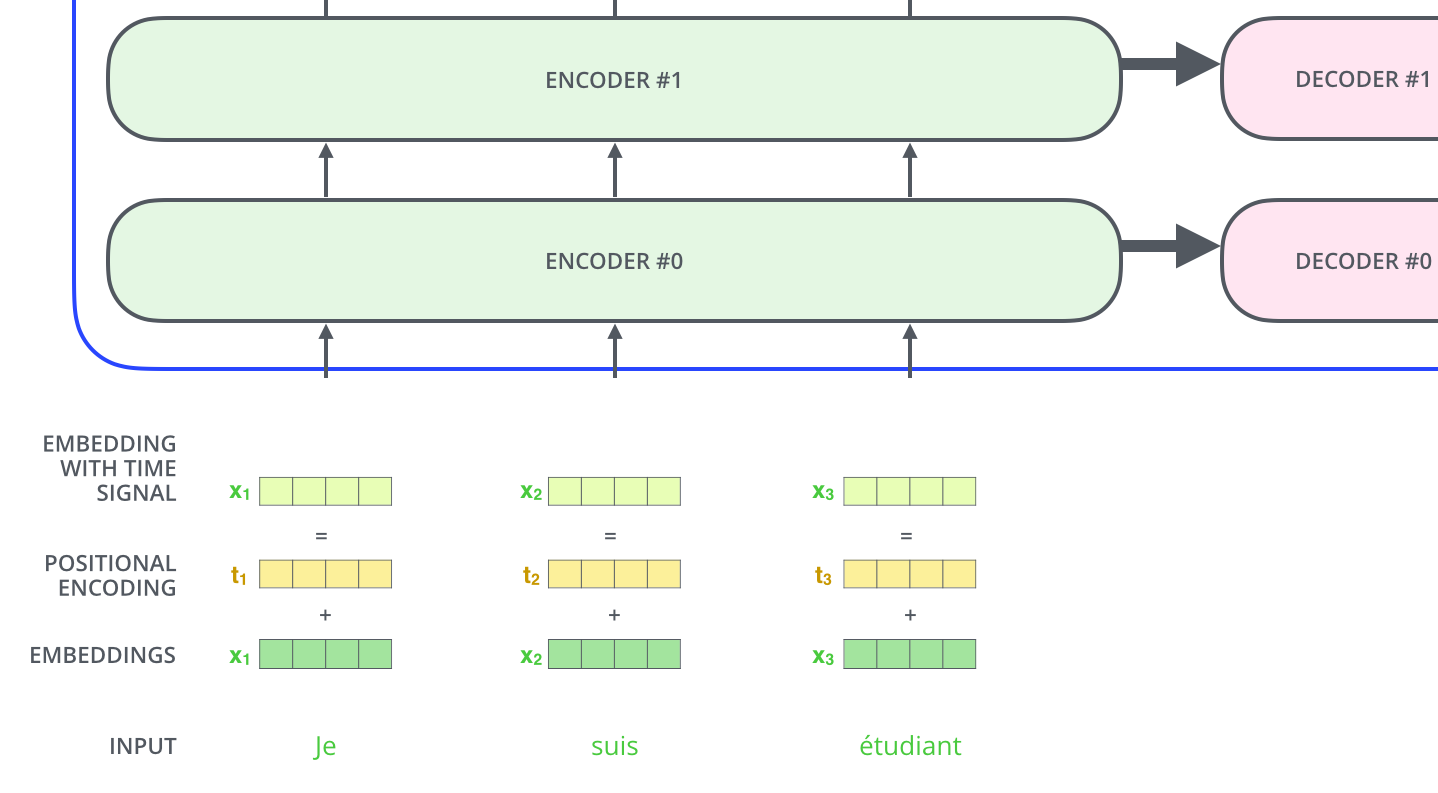
입력에 특정 값을 더해 줌으로써 position 정보를 가짐(bias처럼)
왜 함?
sequential 한 여러 단어를 넣어줬지만 순서에 대한 정보는 없음
self-attention에 a b c d를 넣어주고 a를 encoding 한 결과와 b c a d를 넣어주고 a를 encoding 한 결과는 같겠지
Decoder
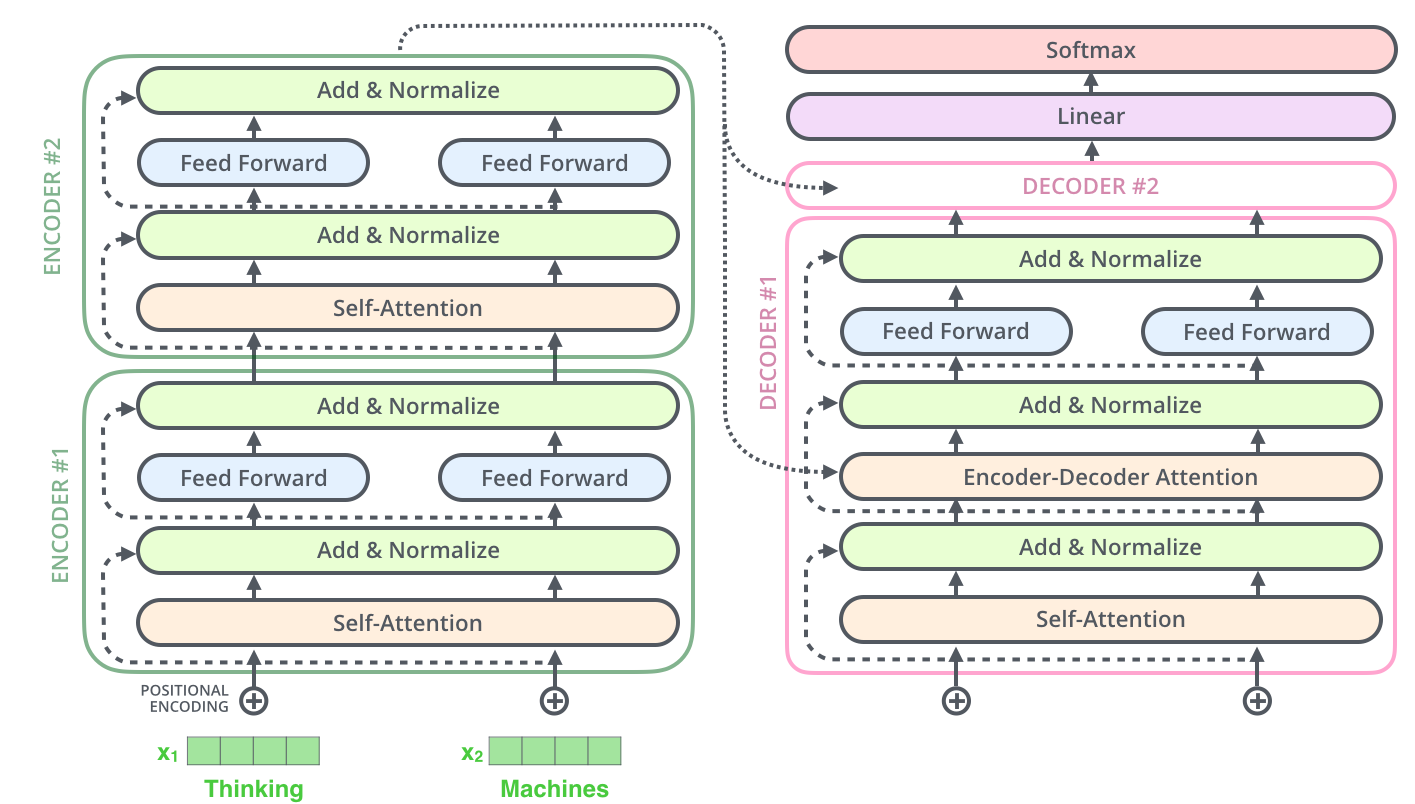
- decoder의 self-attention layer(
masked multi-head attention)- 자기보다 앞에 있는 애들의 score만 볼 수 있음
- 위 input에서 Je는 suis와 etudiant의 score를 볼 수 없다.
- suis는 Je의 score를 볼 수 있고, etudiant의 score를 볼 수 없다.
- 그렇기 때문에 masking(가리기)이 필요함
- Je에 대해 suis와 etudiant의 score 값을 -inf로 줌(행렬로 계산하기 때문에 순차적으로 계산하는 것은 아니고 가리고 계산하는 것임)
- suis에 대해서는 Je의 score 값을 넣어주겠지
- 참고: https://acdongpgm.tistory.com/221
- 자기보다 앞에 있는 애들의 score만 볼 수 있음
- decoder의
encoder-decoder attention layer- encoder를 거쳐서 나온 값이 query가 됨
- key와 value는 encoder에서 쓴 것을 가져옴

너무 어렵네요....