
앞선 Part 1에서 우리는 문서를 무작정 많이 검색해서 밀어 넣는 기존의 방식이 오히려 모델의 주의력을 분산시키고 '가운데의 상실(Lost in the Middle)'을 유발한다는 구조적 한계를 확인했습니다.
그렇다면 이 문제를 어떻게 본질적으로 해결해야 할까요? 워싱턴 대학교(UW), 앨런 인공지능 연구소(AI2), IBM 리서치 연구진이 발표한 "SELF-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection" 논문은 매우 정교한 해답을 제시합니다. 이 모델의 핵심은 수동적으로 외부 문서에 의존하던 기존 RAG를 넘어, 모델 스스로 검색 시점을 판단하고 가져온 정보를 검열하는 '능동적 성찰 시스템'을 구축하는 것입니다.
1. On-Demand 검색: "이 질문, 진짜 검색이 필요한가요?"
기존의 RAG 시스템은 질문의 난이도나 특성을 가리지 않고 무조건 외부 문서를 검색(Indiscriminate retrieval)했습니다. 이는 모델 내부에 이미 정답이 있는 간단한 질문이나 창의적 글쓰기 작업에서도 불필요한 외부 노이즈를 유입시켜 답변의 질을 떨어뜨리는 원인이 되었습니다.
Self-RAG는 이를 극복하기 위해 텍스트 생성 전, 모델 스스로 검색의 필요성을 판단하는 '온디맨드(On-Demand) 검색'을 수행합니다. 모델은 Retrieve라는 특별한 성찰 토큰(Reflection Token)을 스스로 생성하여 의사결정을 내립니다.
- Retrieve = Yes: 외부 지식이나 정교한 팩트 체크가 필요할 때만 검색 엔진을 호출합니다.
- Retrieve = No: 창의적 글쓰기 등 검색이 불필요한 경우 자신의 내부 파라미터 지식만으로 답변을 생성합니다.
- Retrieve = Continue: 이전에 검색한 문서에 정보가 충분하여 계속 해당 맥락을 참고할 때 사용합니다.
💡 Thinking Model과의 연결고리
이전 시리즈에서 모델이 무분별한 생성을 멈추고 "Wait(잠깐만)"을 외치며 숙고했던 과정을 기억하시나요? Self-RAG의Retrieve토큰 역시 "내가 아는 지식인가, 찾아봐야 하는 지식인가?"를 메타적으로 판단하는 System-2의 '의도적 숙고' 과정이 RAG에 이식된 사례입니다.
2. 세 가지 '비판 토큰'을 통한 자기 교정 (Self-Correction)
단순히 문서를 가져오는 것보다 중요한 것은 '가져온 문서가 올바른가'와 '내가 이 문서를 올바르게 해석했는가'를 검증하는 것입니다. Self-RAG는 모델이 문장 단위(Segment-level)로 텍스트를 생성할 때마다 스스로를 채점하는 세 가지 비판 토큰(Critique Tokens)을 활용합니다.
- ISREL (관련성 평가): 검색해 온 문서가 질문을 해결하는 데 실질적인 도움이 되는가?
- ISSUP (지지도 평가): 생성된 문장이 검색된 문서의 팩트에 의해 완벽하게 뒷받침(Attribution)되는가?
- ISUSE (유용성 평가): 최종 답변이 사용자의 질문에 얼마나 유용하고 적절한가? (1점~5점 척도)
이 과정은 중간 풀이 단계마다 논리를 점검하던 과정 기반 보상 모델(PRM)의 원리와 궤를 같이합니다. Self-RAG는 문장을 뱉어내는 중간중간 이 토큰들을 통해 외부 지식과 자신의 출력 간 정합성을 한 땀 한 땀 스스로 검증(Self-Correction)하며 환각의 틈을 메웁니다.
3. 빔 서치와 커스텀 디코딩: 다중 경로 탐색의 구현
이 비판 토큰들은 추론(Inference) 단계에서 강력한 통제력을 발휘합니다. 모델은 검색된 여러 문서에 대해 병렬적으로 답변 후보(Segment)들을 생성합니다. 이후 자신이 매긴 비판 토큰들의 확률값을 선형적으로 합산(Linear weighted sum)하여 세그먼트 레벨 빔 서치(Segment-level beam search)를 수행, 최적의 답변 경로를 선택합니다.
놀라운 점은 각 비판 토큰의 가중치(Weight)를 조절하여 모델의 성향을 자유롭게 통제할 수 있다는 것입니다.
- 의료/법률 도메인 (팩트 최우선):
ISSUP(지지도) 가중치를 극단적으로 높이면, 모델은 유창성보다 문서에 기반한 100% 확실한 사실 전달에 집중합니다. - 마케팅/창의적 영역 (유용성 최우선):
ISUSE(유용성) 가중치를 높이면 팩트의 엄밀함보다는 독창적이고 매끄러운 문장 생성에 무게를 둡니다.
이는 여러 사고의 갈래를 뻗어놓고 최적의 길을 찾아가던 생각의 트리(ToT, Tree of Thoughts) 구조를 RAG의 디코딩 과정에 완벽하게 구현한 결과입니다.
4. 💡 [Deep Dive] 이 메커니즘은 어떻게 '환각'을 원천 차단하는가?
기존 RAG는 외부 문서를 제공하더라도 모델이 이를 무시하거나 왜곡 해석하는 '문맥 기반 환각(Contextual Hallucination)'을 막지 못했습니다. Self-RAG는 이를 두 단계 방어벽으로 차단합니다.
- 아는 척(Parametric Hallucination) 방지: 모델이 생성 전 스스로
<Retrieve = Yes>토큰을 뱉는 행위 자체가 "내 내부 지식만으로는 위험하니 팩트 체크를 하겠다"는 메타 인지(Meta-cognition)의 산물입니다. - 환각 경로의 자동 폐기: 모델이 문서와 모순되는 거짓말을 지어낼 경우, 확률적으로
<ISSUP = No support>토큰이 생성될 가능성이 커집니다. 빔 서치 과정에서 이러한 부정적 토큰이 달린 답변 경로는 점수가 깎여 최종 후보에서 자동으로 폐기(Filtering)됩니다.
즉, "환각 생성 → 스스로 감지 → 해당 경로 폐기 → 팩트 부합 경로 재선택"이라는 자동 방어 기제가 구축되는 것입니다.
5. 💡 [Deep Dive] 훈련의 효율성: 강화학습 없이 구현하다
이토록 고도화된 지능을 주입하기 위해 수조 원의 강화학습(RLHF) 비용이 들 것 같지만, 연구진은 매우 영리한 증류(Distillation) 방식을 택했습니다.
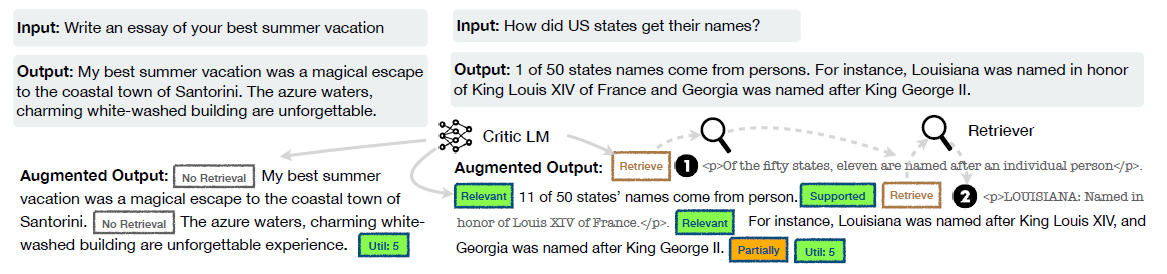
- 왼쪽 (검색이 불필요한 경우): 일상 대화나 창의적 글쓰기처럼 외부 지식이 필요 없는 경우, Critic 모델이
<No Retrieval>토큰을 달아줍니다. - 오른쪽 (검색이 필요한 경우): 팩트 체크가 필요한 질문의 경우, Critic 모델이 스스로
<Retrieve=Yes>토큰을 삽입하고 외부 문서를 가져옵니다. 이후 가져온 문서가 유용한지(<Relevant>), 내 답변이 문서를 잘 뒷받침하는지(<Fully Supported>,<Partially Supported>), 최종 답변이 유용한지(<Util: 5>)를 평가하는 '비판 토큰(Critique Tokens)'을 정교하게 삽입합니다.
- Critic 모델 학습: GPT-4를 이용해 기존 데이터에 비판 토큰을 달아주는 라벨링 작업을 수행하고, 가벼운 별도의 'Critic 모델'을 먼저 학습시킵니다.
- 데이터셋 구축: 이 Critic 모델을 활용해 15만 개의 학습 데이터 코퍼스 전체에 오프라인으로 비판 토큰을 삽입합니다.
- 표현 및 생성 모델(Generator) 학습: 최종 타겟 모델은 이 특수 토큰들이 포함된 데이터를 단순히 '다음 단어 예측(Next token prediction)' 방식으로 학습합니다.
결과적으로 무거운 강화학습 인프라 없이도, 표준적인 지도 학습만으로 System-2의 자가 검증 능력을 모델에 성공적으로 이식한 사례입니다.
🚀 다음 파트 예고: 만약 검색해 온 지식 자체가 '오답'이라면?
Self-RAG는 모델 스스로 자신의 답변을 비판하고 교정하는 능력을 부여함으로써 내부적인 환각을 효과적으로 억제했습니다. 하지만 여기에는 한 가지 전제가 필요합니다. "적어도 검색 엔진이 가져온 문서 중에는 정답이 섞여 있어야 한다"는 점입니다.
만약 내부 지식 베이스가 오염되어 있거나, 검색기가 질문과 전혀 상관없는 '쓰레기 정보'만 가득 물어온다면 모델이 아무리 성찰해도 올바른 답을 낼 수 없습니다.
이러한 '검색 결과의 불확실성'을 정면으로 돌파하는 기술이 바로 CRAG(Corrective RAG)입니다. 다음 [Part 3. 검색된 지식이 쓰레기라면? 스스로 교정하는 검색 (CRAG)] 편에서는 검색된 문서의 품질을 냉정하게 평가하고 지식의 결함을 보완하는 메커니즘을 파헤쳐 보겠습니다.
