
최근 인공지능 학계와 산업계의 화두는 단연 '추론 연산(Test-Time Compute)의 확장'입니다. 모델의 파라미터 크기를 키우고 방대한 데이터를 학습시키는 사전 학습(Pre-training) 중심의 스케일링 법칙(Scaling Law)이 점차 효율성 한계에 도달하면서, 모델이 정답을 도출하는 '추론(Inference) 단계'에 연산량을 집중하여 성능을 극대화하는 새로운 패러다임이 부상하고 있습니다.
이번 Thinking Model 시리즈의 첫 번째 파트에서는 기존 거대 언어 모델(LLM)이 지닌 구조적 한계를 짚어보고, 모델 스스로 '생각할 시간'을 확보하는 System-2 아키텍처로의 전환 배경을 소개합니다.
1. 철학 및 배경: 인간의 인지 과정을 모방하다
새로운 Thinking Model 패러다임의 기저에는 행동경제학자 대니얼 카너먼(Daniel Kahneman)이 제안한 인간의 '이중 처리 이론(Dual Process Theory)'[1]이 자리 잡고 있습니다. 이 이론은 인간의 인지 및 의사결정 과정을 다음과 같은 두 가지 시스템으로 분류합니다.
- System-1 (빠른 사고): 직관적이고 자동적이며 무의식적인 사고방식입니다. 친숙한 대상을 인식하거나 일상적인 대화를 나눌 때 작동하며, 처리 속도가 빠르지만 인지적 편향과 오류에 취약합니다.
- System-2 (느린 사고): 의식적이고 분석적이며, 신중한 계획과 논리적 추론이 요구되는 사고방식입니다. 복잡한 수학 문제를 풀거나 전략적인 의사결정을 내릴 때 활성화됩니다.
기존 LLM의 현주소: System-1에 머물러 있던 AI
지금까지의 거대 언어 모델들은 본질적으로 System-1 사고방식에 머물러 있었습니다. 프롬프트가 입력되면 왼쪽에서 오른쪽으로(Left-to-Right), 이전 토큰들의 확률 분포를 바탕으로 다음 단어를 즉각적으로 예측해 나가는 자가회귀(Autoregressive) 생성 메커니즘은 인간의 직관적이고 즉각적인 반응과 매우 유사합니다.
이러한 메커니즘은 일상 대화나 번역, 단순 정보 검색 등 제한적인 인지 작업(Perceptual tasks)에는 높은 효율을 보입니다. 그러나 다단계 탐색(Search)과 전략적 사전 예측(Lookahead)이 필수적인 복잡한 문제 앞에서는 논리적 정합성을 잃고 환각(Hallucination)을 일으키는 치명적인 약점을 드러냅니다.
약한 System-2의 한계와 강한 System-2로의 진화
인간은 어려운 문제에 직면했을 때 즉답을 피하고, 여러 대안을 브레인스토밍하며 자신의 추론을 평가 및 수정하는 '시간'을 확보합니다.
기존에도 프롬프트 엔지니어링을 통해 모델이 중간 추론 과정을 명시적으로 출력하도록 유도하는 생각의 사슬(Chain-of-Thought, CoT) 기법이 존재했습니다. 이는 일종의 '약한 System-2(Weak System-2)' 단계라 할 수 있습니다. 그러나 단순한 CoT는 생성 도중 논리적 오류가 발생하더라도 이를 스스로 인지하거나 궤도를 수정하지 못하고 오답을 향해 직진해버리는 근본적인 한계를 지닙니다.
이를 극복하기 위해 최근의 AI 연구는 1950년대 인공지능의 선구자인 뉴얼(Newell)과 사이먼(Simon)이 제안했던 고전적 AI의 '문제 공간(Problem space) 탐색' 철학을 현대의 LLM과 결합했습니다[2]. 오답의 늪에 빠지지 않도록 추론 단계에서 다음 세 가지 핵심 인지적 전략을 수행하게 만든 것입니다.[3]
- 다양한 대안의 생성 (Repeated Sampling): 단일한 직관에 의존하지 않고, 여러 개의 다양한 추론 경로를 병렬로 생성하여 최적의 답을 고를 수 있는 강력한 후보군(Pool)을 형성합니다.
- 의도적 계획 및 탐색 (Tree Search): 문제 해결 과정을 상태(State) 노드들의 트리(Tree)로 구조화하고, 체스 알고리즘처럼 유망한 방향을 체계적으로 탐색합니다.
- 자가 평가 및 교정 (Self-Correction): 생성된 중간 사고 과정을 스스로 평가(Self-critique)합니다. 논리적 비약이나 오류가 발생할 경우 이를 인식하고, 이전 단계로 되돌아가는 백트래킹(Backtracking)을 수행합니다.
결과적으로 Thinking Model은 단순한 패턴 매칭을 넘어, 기계가 스스로 대안을 탐색하고 검증할 '시간(Test-Time Compute)'을 부여하는 철학적, 구조적 전환을 의미합니다.
2. 기존 LLM의 한계와 새로운 패러다임의 필요성
최근 몇 년간 LLM은 파라미터 규모의 확장과 방대한 데이터 학습을 통해 비약적으로 발전했습니다. 하지만 근본적인 'Left-to-Right' 자가회귀 생성 방식은 현실의 복잡한 문제를 해결할 때 다음과 같은 세 가지 구조적 한계가 있습니다.
한계 1. 지우개 없이 볼펜으로 십자말풀이를 하는 LLM (탐색과 백트래킹 불가)
기존 LLM은 자신이 방금 생성한 토큰에 논리적으로 갇히게 됩니다. 앞으로 나아갈 길을 내다보고(Lookahead) 전략을 세우거나, 막다른 길에 다다랐을 때 이전 단계로 되돌아가는(Backtracking) 탐색 능력이 구조적으로 부재합니다.
💡 현실 시나리오: 제약 조건이 얽힌 일정 짜기
5x5 미니 십자말풀이나, "2일 차에는 반드시 실내 활동을 해야 한다"는 후행 조건이 붙은 워크숍 일정 수립 과제를 가정해 봅니다.
기존 LLM은 1일 차 일정부터 직관적으로 그럴싸하게 텍스트를 써 내려갑니다. 그러나 생성하다가 2일 차의 제약 조건과 충돌하는 상황을 뒤늦게 마주하게 됩니다. 이미 생각한건 돌이킬 수 없기에 그대로 밀고 나갑니다. 인간이라면 "생각해보니 1일 차 일정을 다른 것으로 교체해야겠네"며 앞선 결정을 수정하겠지만, 기존 모델은 이미 출력한 텍스트를 지우고 되돌아갈 수 없습니다. 결국 꼬여버린 논리를 억지로 이어가며 결함이 있는 답변을 도출하게 됩니다.[2]
한계 2. 작은 실수 하나가 낳는 '오답의 눈덩이 효과' (오류 누적)
다단계 추론(Multi-step reasoning) 환경에서는 단 한 번의 논리적 비약만으로도 전체 솔루션이 붕괴할 수 있습니다. 기존 모델은 중간 사고 과정을 자체적으로 검증(Verify)하는 메커니즘이 없어, 발생한 오류가 텍스트 생성과 함께 눈덩이처럼 불어나는 도미노 현상을 겪습니다.
💡 현실 시나리오: 데이터 분석용 코드 작성
방대한 엑셀 데이터를 분석하는 파이썬(Python) 코드 작성을 지시할 때, 모델이 극초반부에서 날짜 형식을 'MM/DD'가 아닌 'DD/MM'으로 착각하는 사소한 오류를 범했다고 가정합니다. 기존 모델은 이 잘못된 전제가 참이라는 가정하에 100줄이 넘는 코드를 논리적으로 전개해 버립니다. 텍스트 자체는 완벽해 보이지만 실행 결과는 완전히 실패하는 전형적인 오류 누적 현상입니다.[4]
한계 3. 인간 데이터 의존성으로 인한 '성장의 한계(Ceiling)'
과거에는 모델의 추론 한계를 극복하기 위해 사람이 직접 작성한 고품질의 풀이 과정(CoT)을 지도 학습(Supervised Fine-Tuning, SFT) 시켰습니다. 그러나 최근 연구들은 이러한 인간 데이터 의존성이 오히려 모델의 잠재력을 제한한다고 지적합니다.
💡 현실 시나리오: 대규모 물류 경로 최적화
수백 대의 택배 차량 경로를 짤 때, SFT로 훈련된 모델은 인간 배차 담당자들이 과거에 풀었던 방식(예: "가장 가까운 목적지부터 간다"는 휴리스틱)만을 모방하도록 제약받습니다.
인간이 작성한 데이터는 명시적인 성찰(Reflection)이나 수많은 실패-검증 단계를 종종 생략한 채 최종 정답만을 담고 있습니다. 결과적으로 모델은 인간의 직관적이고 편향된 패턴에 갇히게 되며, 스스로 깊이 탐색하여 인간조차 생각하지 못했던 '기발하고 압도적인 추론 경로(non-human-like reasoning pathways)'를 발견할 기회를 원천적으로 박탈당하게 됩니다.[5]
🚀 새로운 패러다임: "말하기 전에 먼저 생각하라"
결론적으로, 언어 모델의 덩치를 무작정 키우거나 사람이 만든 정답 데이터만을 주입하는 방식은 한계에 도달했습니다.
이제 AI 연구의 최전선은 모델에게 어려운 질문이 주어졌을 때 즉각적으로 텍스트를 내뱉는(System-1) 대신, 출력 전 스스로 충분히 생각하고 검토할 연산 시간(System-2)을 갖도록 아키텍처를 재설계하는 것으로 이동했습니다. 강화학습에 노출된 최신 모델들은 오답을 전개하다가도 스스로 "잠깐만(Wait), 다시 생각해보자"라며 논리를 교정하는 창발적 능력(Emergent behavior)을 보여주고 있습니다.
3. 기술 이해를 위한 배경지식: Test-Time Computing (TTC)의 진화
새로운 패러다임인 Thinking Model을 구조적으로 이해하기 위해서는 이 변화의 근간인 '테스트 타임 연산(Test-Time Computing, TTC)'의 진화 과정을 짚어보아야 합니다.
전통적으로 인공지능의 성능 향상은 '훈련 시간(Train-Time)'에 막대한 연산량과 데이터를 투입하는 방식으로 이루어졌습니다. 반면, TTC는 모델이 훈련을 마친 후 실제 텍스트를 생성하는 추론(Inference) 단계에서 추가적인 연산을 투입하여 결과물의 품질을 높이는 방법론을 통칭합니다. AI 모델이 직관적 사고(System-1)에서 숙고하는 사고(System-2)로 발전함에 따라, TTC의 역할과 형태 역시 크게 세 단계로 진화해 왔습니다.
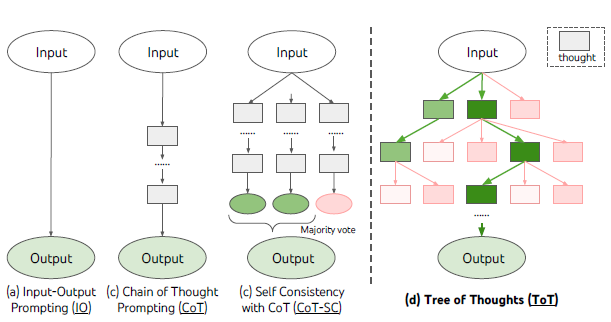
1 단계. System-1 모델에서의 TTC: 테스트 타임 적응 (TTA)
초기 딥러닝 모델들은 훈련 데이터의 분포에 과적합(Overfitting)되는 경향이 있어, 실제 테스트 환경의 데이터 분포가 다를 때(Distribution Shift) 성능이 저하되는 현상이 빈번했습니다. 이를 완화하기 위해 추론 시점에 모델을 미세하게 조정하는 TTA(Test-Time Adaptation) 기술이 연구되었습니다.[3]
- 매개변수 업데이트 (Parameter Updating): 추론 시 입력된 테스트 데이터를 활용해 모델의 정규화 층(Normalization layer)이나 소프트 프롬프트 등을 역전파(Backpropagation)로 일시 재학습시키는 방식입니다.
- 입력 수정 (Input Modification): 매개변수 업데이트 비용이 커지자, 테스트 샘플과 가장 유사하거나 유용한 예시를 검색기(Retriever)로 찾아 프롬프트에 동적으로 배치하는 인컨텍스트 러닝(ICL) 최적화 기법이 도입되었습니다.
- 표현 편집 (Representation Editing): 가중치를 직접 수정하지 않고, 모델 내부의 활성화 값(Activation)에 대비되는 프롬프트로 계산된 '조향 벡터(Steering vector)'를 더해 출력의 논리나 스타일을 교정합니다.
- 출력 보정 (Output Calibration): 추론된 텍스트 확률 분포를 외부의 방대한 데이터스토어(kNN-MT 등)에서 검색된 정보와 결합하여 최종 출력을 교정하는 방식입니다.
2 단계. 약한 System-2 (Weak System-2)로의 전환: 생각의 사슬 (CoT)
모델의 파라미터가 수백억 개 이상으로 커지면서 추론 단계마다 파라미터를 업데이트하는 것은 연산 비용과 안정성 측면에서 비효율적이 되었습니다. 이에 따라 파라미터를 완전히 고정(Frozen)한 상태에서 텍스트(토큰)의 생성량을 늘려 연산량을 확보하는 패러다임이 등장했습니다.
그 핵심이 바로 생각의 사슬(Chain-of-Thought, CoT)입니다. 모델이 최종 답을 도출하기 전 중간 추론 과정(Rationale)을 명시적으로 생성하도록 유도하여 문제를 논리적으로 분해하도록 돕습니다. 파라미터를 수정하는 대신 토큰을 길게 생성하며 모델 스스로 '생각할 연산량'을 벌어들이는 효과를 가져왔습니다.[6]
그러나 단순 CoT는 여전히 단방향(Left-to-Right) 생성 구조에 머물러 있어, 중간에 논리적 오류가 발생할 경우 앞을 내다보거나 되돌아가지 못하고 오답으로 직진해 버리는 근본적인 맹점을 지니고 있었습니다.
3 단계. 강한 System-2 (Strong System-2): 테스트 타임 추론 (Test-Time Reasoning)
단순 CoT의 한계를 극복하기 위해 등장한 최신 추론 모델(OpenAI o1, DeepSeek-R1 등)은 텍스트 생성 과정 내부에 복잡한 '피드백 모델링(검증)'과 '탐색 전략'을 결합한 테스트 타임 추론을 수행합니다.
- 피드백 모델링 (Feedback Modeling): 방대한 탐색 공간에서 생성된 여러 경로 중 어느 것이 정답을 향하고 있는지 채점하는 검증기(Verifier) 역할을 수행합니다. 결과만 평가하는 결과 기반 보상 모델(ORM)의 한계를 극복하기 위해, 추론의 각 중간 단계마다 점수를 매기는 과정 기반 보상 모델(PRM)이 주로 활용됩니다. (최근에는 PRM 점수를 집계할 때 단순 곱셈을 넘어, 마지막 단계의 점수만을 활용하여 평가의 정밀도를 높이는 등 최적화 연구가 활발합니다.)
- 탐색 전략 (Search Strategies): 피드백을 바탕으로 정답을 찾아가는 알고리즘입니다. 여러 추론 경로를 병렬로 생성해 최적을 선택하는 반복 샘플링(Repeated Sampling), 모델 스스로 오류를 인식하고 순차적으로 수정하는 자가 교정(Self-correction), 그리고 유망한 경로를 뻗어가되 막힌 길은 되돌아가는 트리 탐색(Tree Search) 기법이 유기적으로 통합됩니다.[3]

과거의 TTC가 환경에 맞춰 뇌 구조의 일부를 고치는 작업이었다면, 현재의 강한 System-2 TTC는 뇌 구조를 그대로 유지한 채 머릿속으로 수많은 시나리오를 시뮬레이션하고 검증할 시간을 극대화하는 방향으로 진화했습니다.
4. System-2 Thinking 구현 방법론 및 작동 원리: 기술적 딥다이브
최신 연구들이 깊은 사고력(Test-Time Reasoning)을 모델 내부에 구현하기 위해 어떠한 알고리즘과 수학적, 구조적 처리를 거치는지 5가지 핵심 방법론으로 분석해 보겠습니다.
4.1. 탐색 공간의 구조화: 생각의 트리 (Tree of Thoughts, ToT)
선형적인 생성 방식을 벗어나기 위해 제안된 생각의 트리(ToT)는 문제 해결 과정을 방대한 검색 트리(Search Tree)로 재구성합니다.
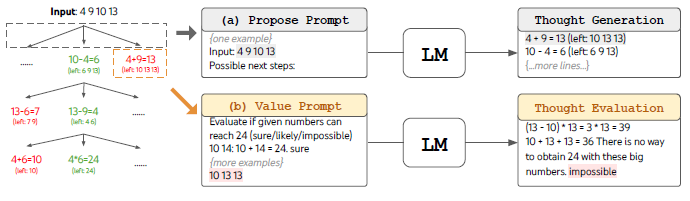
[그림 3] 생각의 트리(ToT)의 너비 우선 탐색(BFS) 과정 (Game of 24 태스크) 수학 퍼즐인 '24 게임'에서 언어 모델이 너비 우선 탐색(BFS) 알고리즘을 수행하는 예시입니다
. 모델은 각 단계에서 가능한 여러 중간 수식을 생성(Thought Generation)하고, 정답에 도달할 가능성이 있는지 스스로 평가(Thought Evaluation)합니다
. 이를 통해 가장 유망한 후보들만을 남겨두고 여러 경로를 넓게 뻗어나가며 정답을 탐색합니다
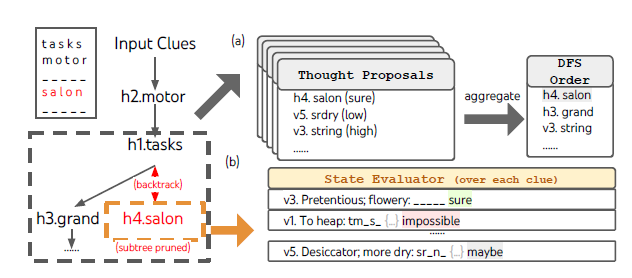
- 생각의 분해 (Thought Decomposition): 문제 해결의 중간 단계를 정의합니다.
- 생각 생성기 (Thought Generator): 특정 상태(State)에서 나아갈 여러 경로 후보를 독립적으로 샘플링하거나 순차적으로 제안합니다.
- 상태 평가기 (State Evaluator): 별도로 훈련된 무거운 가치 예측 신경망(Value Network)을 추가로 사용하는 기존 탐색 알고리즘과 달리, 언어 모델 본연의 프롬프팅 능력을 활용하여 스스로 현재 상태가 정답에 도달할 수 있을지 '확실함(sure) / 아마도(maybe) / 불가능(impossible)'으로 이성적인 채점(Self-evaluation)을 수행합니다. 가능성이 없는 경로는 즉시 가지치기(Pruning)를 수행합니다.[4]
- 탐색 알고리즘 (Search Algorithm): 너비 우선 탐색(BFS)이나 깊이 우선 탐색(DFS) 알고리즘을 적용해 트리를 순회하며, 평가 결과에 따라 막힌 길을 되돌아가는 백트래킹(Backtracking)을 수행합니다.
4.2. 사고 과정의 세밀한 검증: ORM과 PRM
생성된 여러 경로 중 올바른 것을 선택하기 위해서는 정교한 채점 기준이 필요합니다.
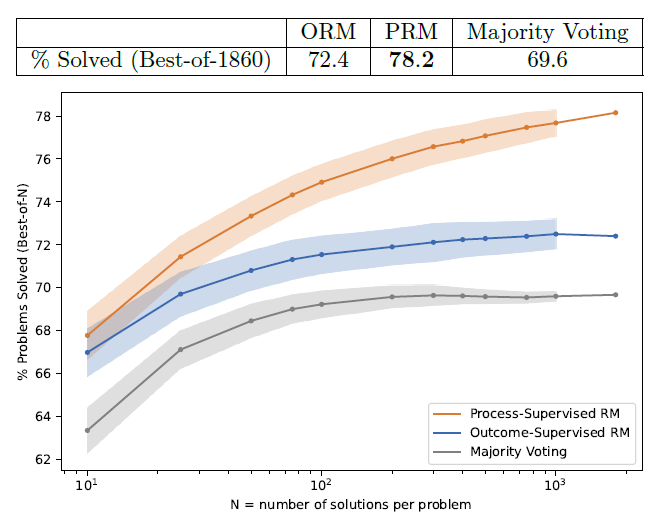
- 결과 기반 보상 모델 (ORM, Outcome-supervised Reward Models): 추론이 끝난 후 최종 결과의 정답 여부만을 평가합니다. 구현이 비교적 단순하지만, 긴 풀이 과정 중 정확히 어느 지점에서 논리가 어긋났는지 파악하기 어려운 신용 할당(Credit-assignment) 문제에 직면합니다.
- 과정 기반 보상 모델 (PRM, Process-supervised Reward Models): 추론의 '각 중간 단계(Step)'마다 세밀하게 점깁니다. 논리적 오류 지점을 조기에 식별하여 오답의 눈덩이 효과를 차단합니다.
전체 풀이의 최종 점수를 산출할 때는 전통적으로 각 단계 점수의 최솟값(Min)이나 곱(Product)을 사용해 왔습니다. 그러나 최근 구글 딥마인드(Google DeepMind)의 연구에 따르면, 복잡한 소프트 라벨(Soft values) 환경에서는 단순히 '마지막 단계의 점수(Last step score)'만을 사용하는 것이 기존 방식들보다 오히려 가장 우수한 성능을 기록하는 등, 최적의 점수 집계 방식에 대한 연구도 끊임없이 진화하고 있습니다.[7]
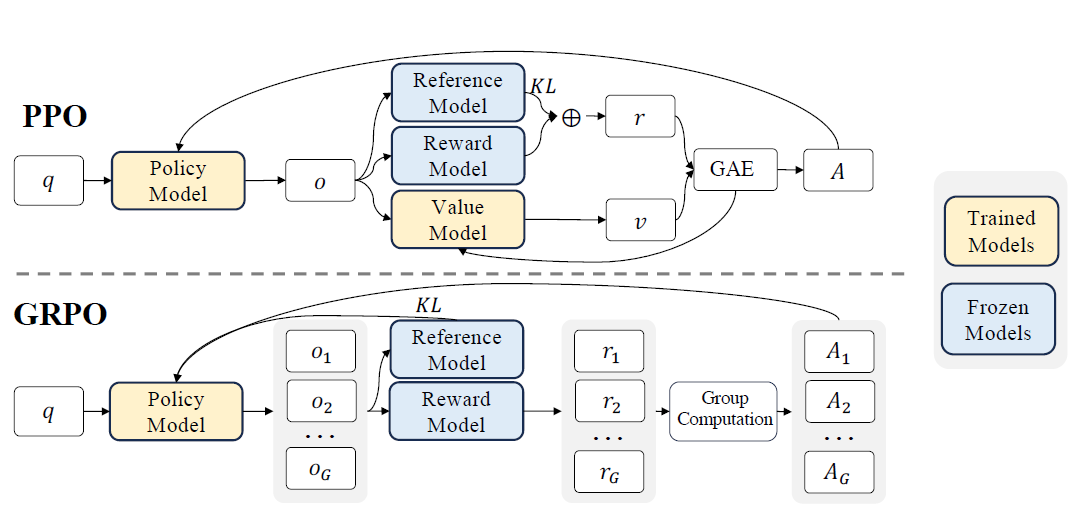
4.3. 강화학습 아키텍처의 혁신: PPO의 한계와 GRPO의 도입
인간의 지도 학습(SFT) 없이 순수 강화학습(RL)만으로 추론 능력을 발현시킨 DeepSeek-R1-Zero의 성과는 모델 학습 효율화에 큰 시사점을 줍니다.
기존 표준 강화학습 알고리즘인 PPO(Proximal Policy Optimization)는 텍스트를 생성하는 정책 모델(Policy Model) 외에도, 현재 상태의 기대 보상을 예측하는 가치 모델(Value Model)을 동시에 구동해야 하여 극심한 메모리 및 연산 오버헤드를 발생시켰습니다.
DeepSeek 연구진이 채택한 GRPO(Group Relative Policy Optimization)는 이 무거운 가치 모델을 제거했습니다. 특정 프롬프트에 대해 여러 개의 답변 그룹을 한 번에 샘플링하고, 그룹 내 답변들의 보상 점수를 상호 비교하여 상대적인 이점(Advantage)을 계산합니다. 또한 보상 해킹(Reward hacking)을 방지하기 위해 형식을 지켰는지와 정답이 맞는지 확인하는 단순한 규칙 기반 보상(Rule-based rewards)만을 적용해 연산 효율을 극대화했습니다.[5]
4.4. "Wait" 기반 자기 교정과 추론 능력의 증류 (Distillation)
오답을 전개하다 스스로 멈추고 궤도를 수정하는 현상과 이를 활용한 최신 기술적 성과는 다음과 같이 요약할 수 있습니다.
- 순수 강화학습을 통한 자생적 발현 (DeepSeek-R1): 모델에게 명시적으로 지시하지 않았음에도, 보상을 최대화하는 과정에서 모델 스스로 "Wait, wait" 등의 단어를 생성해 논리 전개를 멈추고 반성(Reflection)하는 능력이 창발(Emergent behavior)했습니다. 단, 언어가 섞이는 혼종(Language mixing) 현상을 해결하기 위해 콜드 스타트(Cold-start) SFT 데이터와 다단계 RL을 결합하는 파이프라인이 도입되었습니다.
- 예산 강제 할당 (s1 모델의 Budget Forcing): 모델의 추론 시간을 외부에서 강제로 제어하는 양방향성(Bidirectional) 기술입니다. 모델이 추론을 조기 종료하려 할 때(EOS 토큰 출력 시), 이를 억제하고 "Wait(기다려)"라는 문자열을 인위적으로 주입합니다. 이 개입으로 인해 모델은 멈추려던 논리를 강제로 연장하여 스스로 이중 점검(Double-check)을 수행하게 됩니다. 반대로 지정된 연산 예산을 초과하여 무한 루프에 빠질 위험이 있을 때는 종료 토큰을 강제로 주입해 사고를 조기 종료(Truncation)시키기도 합니다.[8]
- 거대 모델 추론 능력의 증류 (Distillation): DeepSeek-R1 연구가 AI 커뮤니티에 남긴 가장 중요한 기술적 기여 중 하나는, 강화학습으로 빚어낸 거대 모델의 깊은 사고 궤적(약 80만 개)을 Qwen, Llama와 같은 1.5B ~ 32B 규모의 작은 모델에 지도 학습(SFT)시키는 것만으로도 System-2 추론 능력이 성공적으로 이식(Distillation)되었다는 점입니다.[5] 이는 막대한 연산량이 필요한 추론 모델의 대중화를 이끈 결정적 성과입니다.
4.5. 매 토큰마다 숨겨진 추론을 수행: 조용한 추론 (Quiet-STaR)
복잡한 수학 문제가 아닌 일반 텍스트 문맥에서도 눈에 보이지 않는 내면의 사고(Inner Rationale)를 수행하게 만드는 기술입니다.
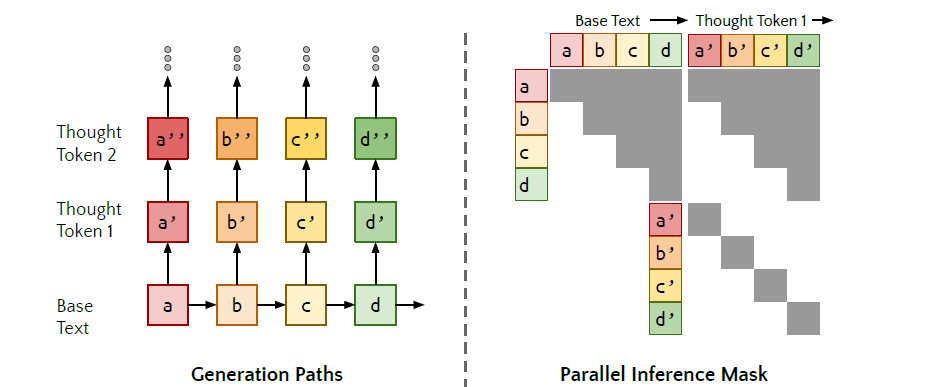
- 대각선 어텐션 마스크 (Diagonal Attention Mask): 시퀀스의 모든 토큰 위치에서 동시에 생각을 생성하기 위해 사용됩니다. 각 토큰이 파생시킨 생각 토큰들에만 주의를 기울이게 하여, 병렬적이고 간섭 없는 생각 생성을 지원합니다.
- 혼합 헤드와 티처 포싱: 생각 생성이 완료되면, '생각을 거친 다음 단어 예측 확률'과 '생각을 거치지 않은 원래의 예측 확률'을 얕은 신경망(Mixing Head)으로 적절히 혼합합니다. 이를 바탕으로 실제 정답 텍스트에 대한 티처 포싱(Teacher-forcing) 방식으로 모델을 학습시켜 일상적인 언어 처리에서도 문맥 이해의 깊이를 더합니다.[9]
5. 무조건 오래 생각하면 좋을까? TTC의 한계와 최적화
OpenAI o1과 DeepSeek-R1의 성과는 "추론 시간(Test-Time)에 연산을 투자할수록 성능이 향상된다"는 스케일링 법칙(Scaling Law)을 입증했습니다. 그러나 최신 연구들은 생각할 시간을 무한정 길게 부여하는 것이 필연적인 성능 향상으로 이어지지는 않음을 시사합니다. 주어진 추론 연산량(Test-Time Compute, TTC)을 문제의 특성에 맞춰 얼마나 효율적으로 할당할 것인가(Compute-Optimal)가 향후 System-2 모델 경쟁력의 핵심 과제로 대두되고 있습니다.
5.1. 과유불급: 오버띵킹(Overthinking)의 역효과
단순히 생각의 사슬(CoT)을 길게 늘린다고 해서 항상 정답에 수렴하는 것은 아닙니다. 런민대와 마이크로소프트 연구진이 발표한 ‘TOPS (Towards Thinking-Optimal Scaling)’ 연구에 따르면, 문제의 난이도에 맞지 않는 과도한 추론 시간은 오히려 모델의 성능을 저하시키는 '오버띵킹(Overthinking)' 현상을 유발합니다.[10]
- 쉬운 문제에서의 역효과: 간단한 사칙연산이나 직관적인 논리 문제(예: GSM8K 데이터셋)를 풀 때 모델에게 억지로 긴 추론을 강제하면, 불필요한 가정을 끌어들이거나 엉뚱한 탐색 경로를 파고들게 됩니다. 이 과정에서 중간에 오류가 포함된 추론 단계(Erroneous steps)가 생성될 확률이 급격히 높아집니다.
- 사고 최적화 (Thinking-Optimal): 반면 난도가 높은 문제에서는 깊은 탐색이 필수적입니다. 따라서 연구진은 모델이 문제의 난이도에 맞춰 스스로 생각의 길이를 조절할 수 있도록, 다양한 길이의 풀이 궤적 중 '가장 짧고 정확한 경로(Shortest correct response)'만을 선별하여 학습(Self-Improvement)시키는 최적화 전략이 효과적임을 증명했습니다.
5.2. 문제 난이도에 따른 연산 할당 전략
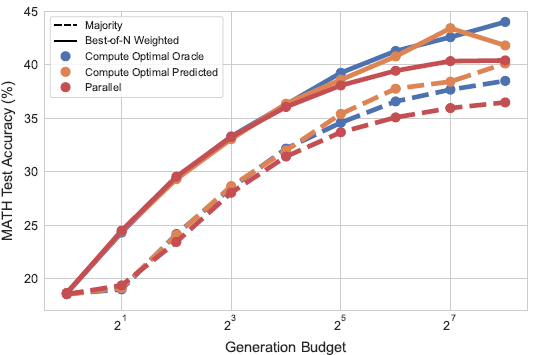
구글 딥마인드(Google DeepMind)의 연구는 한정된 연산 예산을 '순차적 탐색(Sequential revisions)'에 사용할 것인지, '병렬적 탐색(Parallel sampling)'에 사용할 것인지에 대한 명확한 기준을 제시했습니다.
- 쉬운 문제 (순차적 탐색 유리): 난도가 낮을 때는 모델이 스스로 자신의 답을 지속해서 고쳐나가는 순차적인 자가 교정에 연산량을 할당하는 것이 효율적입니다.
- 어려운 문제 (병렬적 탐색 유리): 한 가지 풀이 방식에만 갇히면 오답의 늪에 빠질 위험이 큽니다. 따라서 다양한 대안을 동시에 생성하고, 과정 기반 보상 모델(PRM)과 같은 검증기를 통해 최적의 답을 선택하는 병렬 탐색에 연산을 분배하는 것이 성능을 극대화합니다.[7]
이 연구에서 주목할 만한 부분은 연산-파라미터 교환(FLOPs-Matched Evaluation) 실험 결과입니다. 작은 베이스 모델에 위와 같이 최적화된 테스트 타임 연산을 부여했을 때, 추론 연산 없이 즉답을 도출하는 14배 더 거대한 사전 학습(Pre-training) 모델의 성능을 능가했습니다. 이는 중간 난이도 이하의 현실 문제에서 '작은 파라미터 + 최적화된 System-2 추론' 조합이 압도적인 연산 효율성을 지님을 보여줍니다.
5.3. 데이터 효율성의 극대화: 1K 데이터로 충분한 System-2 (s1 모델)
System-2 모델이 깊은 사고 능력을 갖추기 위해서는 수백만 번의 강화학습(RL) 스텝이 필수적이라고 여겨졌으나, 스탠포드 대학교 연구진이 발표한 's1' 모델은 이러한 고정관념을 뒤집었습니다.
- 표면적 정렬 (Superficial Alignment) 가설: 연구진은 방대한 데이터를 사전 학습한 모델 내부에는 이미 심층적인 추론 능력이 내재되어 있다고 판단했습니다.
- 1,000개의 고품질 데이터의 비밀: 그들은 5만여 개의 데이터 중 엄격한 필터링을 거쳐 단 1,000개의 초고품질 추론 데이터만을 선별했습니다. 논문의 절제 연구(Ablation study)에 따르면, 데이터를 무작위로 1,000개 뽑거나 단순히 길이가 가장 긴(가장 어려운) 1,000개만 뽑았을 때는 모델의 성능이 최대 30% 가까이 폭락했습니다. 즉, 이 1K 데이터의 위력은 단순한 양이나 극단적인 난이도가 아니라 '품질-난이도-다양성의 완벽한 균형'에서 비롯됨을 증명한 것입니다.[8]
이 소량의 정제된 데이터로 지도 학습(SFT)을 진행하고 추론 시점에 'Wait'을 주입하는 강제 예산 할당(Budget Forcing) 기법을 적용한 결과, s1 모델은 기존 거대 추론 모델들과 견줄 만한 성능을 확보했습니다.
6. 현재의 한계와 미래 전망: 진정한 인지 지능을 향하여
테스트 타임 연산의 확장과 System-2 Thinking의 도입은 인공지능 발전에 새로운 지평을 열었으나, 범용 인공지능(AGI)으로 나아가기 위해서는 여전히 해결해야 할 구조적 과제들이 존재합니다.
6.1. 직면한 기술적 한계점
- 도메인 편중 (Domain Dependency): 현재 최고 수준의 System-2 모델들이 강점을 보이는 분야는 수학이나 코딩처럼 '정답이 명확하고 규칙 기반 검증(Rule-based Verification)이 가능한' 영역입니다. 반면, 창의적 글쓰기나 주관적 가치가 개입되는 일반 언어 작업에서는 성능 향상 폭이 미미하거나 오히려 가독성이 떨어지는 현상을 보입니다. 이는 객관적인 '채점자(Verifier)'를 알고리즘으로 설계하기 어려운 영역의 본질적 숙제입니다.
- 보상 해킹과 정렬의 어려움: 강화학습 과정에서 모델은 오직 보상을 극대화하기 위해 평가 시스템의 허점을 찌르는 보상 해킹(Reward Hacking)을 시도할 수 있습니다. 또한, 수만 토큰에 달하는 긴 사고 과정 속에서 제어를 잃고 여러 언어가 섞이는 혼종(Language Mixing) 현상을 겪는 등 출력의 안정성 확보가 필요합니다.
- 막대한 추론 비용과 응답 지연: 수많은 경로를 탐색하고 검증하는 과정은 필연적으로 높은 연산 비용과 응답 지연(Latency)을 초래합니다. 단순한 일상 대화에 수십 초의 연산이 소요된다면 실서비스 환경에서의 효용성이 떨어지므로, 과제의 난이도에 맞춰 System-1(빠른 직관)과 System-2(깊은 숙고)를 동적으로 조절하는 라우팅(Routing) 기술이 요구됩니다.
6.2. 미래 연구 방향 (Future Directions)
이러한 한계를 극복하기 위해 학계와 산업계는 다음과 같은 융합 연구로 시선을 넓히고 있습니다.
- 다중 모달리티 추론 (Multimodal System-2 Reasoning): 텍스트를 넘어 시각, 청각 등 다양한 감각 정보를 종합하여 공간적 트리를 탐색하고 논리적으로 분석하는 방향으로의 확장입니다.
- 도구 사용과의 결합 (Tool-Augmented Reasoning): 모델이 내면의 사고에만 의존하지 않고, 코드 컴파일러, 웹 검색 엔진, 물리 시뮬레이터 등의 외부 도구를 능동적으로 호출하여 자신의 가설을 교차 검증(Cross-validation)하는 연구가 활발히 진행 중입니다.[5]
- 약한 감독에서 강한 지능으로 (Weak-to-Strong Generalization): 인간이 정답을 아는 문제를 넘어, 인간의 '약한 피드백'만으로도 AI가 스스로 검증 루프를 돌며 미지의 과학적 난제를 해결하는 자체 진화 메커니즘을 구축하는 것입니다.
6.3. 결론: "생성(Generation)"에서 "해결(Problem-Solving)"의 시대로
지금까지의 대형 언어 모델은 이전의 맥락을 바탕으로 다음에 올 단어를 예측하는 '텍스트 생성기'에 가까웠습니다. 그러나 테스트 타임 연산의 확장과 자기 검증 프로세스의 내재화를 통해, 인공지능은 직관적 대답을 멈추고 신중하게 숙고하는 단계로 진입했습니다.
이는 AI의 본질이 단순한 확률적 패턴 매칭을 넘어, 현실의 제약을 분석하고 최적의 해답을 찾아내는 '문제 해결사(Problem-Solver)'로 진화하고 있음을 의미합니다. 파라미터의 규모만을 경쟁하던 시대를 지나, 제한된 자원을 활용해 가장 효율적이고 깊게 생각하는 '추론의 최적화'가 향후 인공지능 발전의 가장 중요한 이정표가 될 것입니다.
📚 References (참고문헌)
- [1] Kahneman, D. (2011). Thinking, fast and slow. Macmillan. (인간의 인지 과정인 이중 처리 이론의 근간)
- [2] Yao, S., et al. (2023). "Tree of Thoughts: Deliberate Problem Solving with Large Language Models." NeurIPS. (언어 모델의 의도적 탐색과 백트래킹을 구현한 ToT 논문)
- [3] Test-time Computing Survey (2024). "Test-time Computing: from System-1 Thinking to System-2 Thinking." (LLM의 Test-Time Computing 진화 과정을 총망라한 리뷰 논문)
- [4] Lightman, H., et al. (2023). "Let's Verify Step by Step." ICLR. (오류 누적을 방지하는 과정 기반 보상 모델, PRM의 효과를 입증한 OpenAI 논문)
- [5] DeepSeek-AI. (2025). "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning." (인간 데이터 없이 강화학습만으로 'Aha Moment'를 발현시키고 소형 모델로의 증류를 증명한 논문)
- [6] Wei, J., et al. (2022). "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models." NeurIPS. (약한 System-2의 시작을 알린 CoT 프롬프팅 논문)
- [7] Snell, C., Lee, J., Xu, K., & Kumar, A. (2024). "Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters." Google DeepMind. (문제 난이도에 따른 Test-Time 연산의 최적 할당 법칙 및 병렬/순차 탐색 혼합 비율을 분석한 논문)
- [8] Muennighoff, N., et al. (2025). "s1: Simple test-time scaling." (단 1,000개의 고품질 데이터와 Budget Forcing을 통한 'Wait' 주입 기법으로 o1급 성능을 구현한 스탠포드 연구)
- [9] Zelikman, E., et al. (2024). "Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking." (일반 텍스트 예측 과정에서도 병렬로 내면의 사고를 수행하게 만드는 방법론)
- [10] Yang, W., et al. (2025). "Towards Thinking-Optimal Scaling of Test-Time Compute for LLM Reasoning." Renmin University & Microsoft Research. (과도한 Test-Time 연산이 가져오는 '오버띵킹' 부작용을 지적하고 최단 정답 경로를 통한 최적화 학습을 제안한 TOPS 논문)
