협업 필터링(Collaborativve Filtering, CF)
목적
유저 u가 아이템 i에 부여할 평점을 예측하는 것
방법
- 주어진 데이터를 활용해 유저-아이템 행렬을 생성한다..
- 유사도 기준을 정하고, 유저 혹은 아이템간의 유사도를 구한다.
- 주어진 평점과 유사도를 활용하여 행렬의 비어 있는 값(평점)을 예측한다.
원리
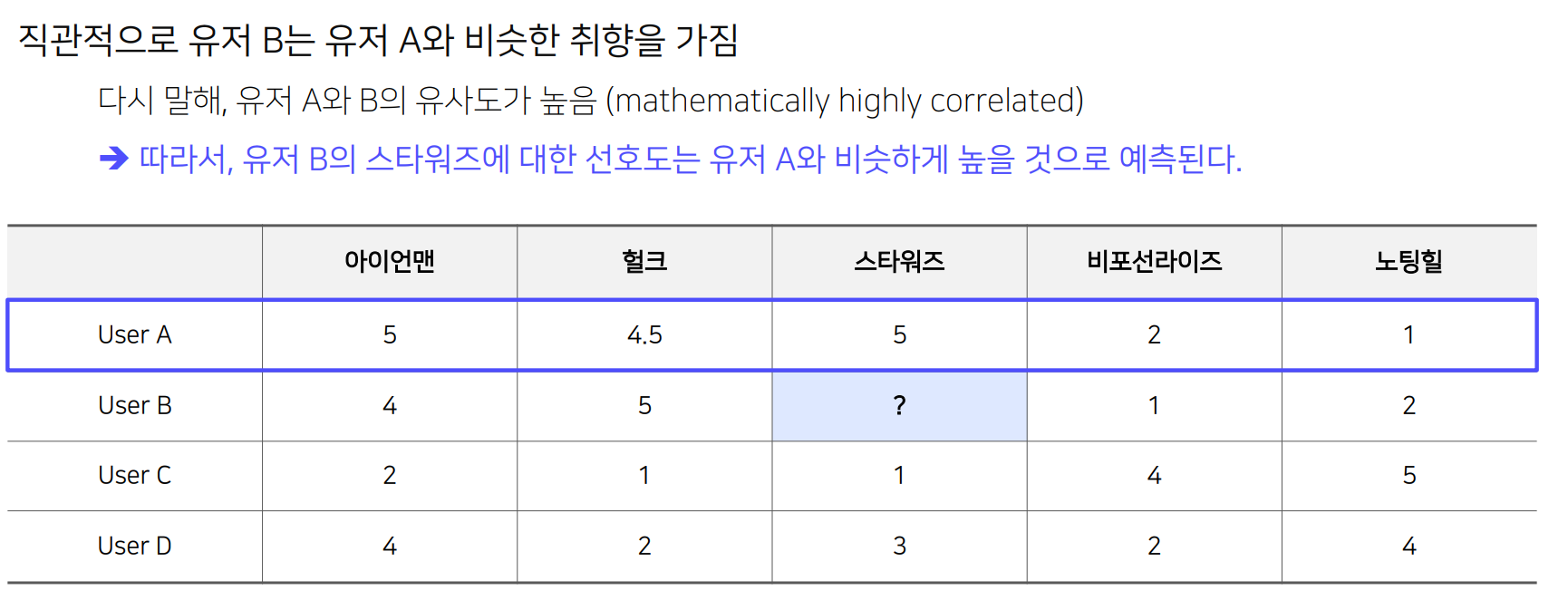
유저 A와 비슷한 취향을 가진 유저들이 선호하는 아이템을 추천
-> 아이템이 가진 속성을 사용하지 않으면서도 높은 추천 성능을 보임
CF 분류
Neighborhood-based CF(Memory based CF)
- User-based
- Item-based
Model based CF
- SVD
- Matrix Factorization (SGD, ALS, BPR)
- DeepLearning
Hybrid CF
- Content based Recommendation과의 결합
NBCF (Neighborhood-based CF)
User based
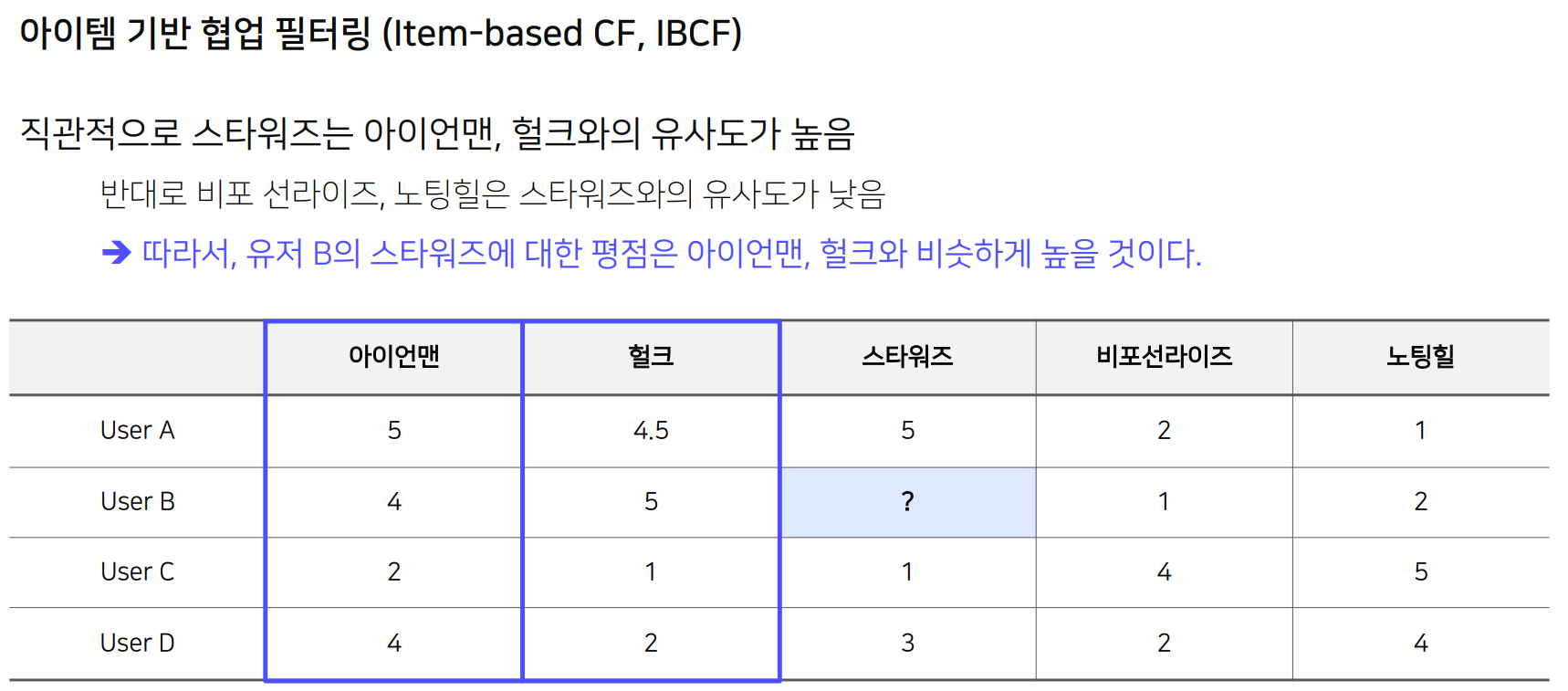
Item based
NBCF 한계
- 아이템이나 유저가 계속 늘어날 경우 확장성이 떨어진다 (Scalability)
- 주어진 평점/선호도 데이터가 적을 경우, 성능이 저하된다 (Sparsity)
KNN CF
model based에 들어가기 전 유사도 측정법
-
Cosine Similarity

-
Jacccard Similarity

MBCF (Model based CF)
항목 간 유사성을 단순 비교하는 것에서 벗어나 데이터에 내재한 패턴을 이용해 추천하는 CF 기법
- Parametric Machine Learning을 사용
- 주어진 데이터를 사용하여 모델을 학습
- 데이터 정보가 파라미터의 형태로 모델에 압축
- 모델의 파라미터는 데이터의 패턴을 나타내고, 최적화를 통해 업데이트
특징
데이터에 숨겨진 유저 아이템 관계의 잠재적 특성/패턴을 찾음
현업에서는 Matrix Factorization 기법이 가장 많이 사용된다고 함 (+ DL)
장점
1. 모델 학습 서빙
- 유저 아이템 데이터는 학습에만 사용되고 학습된 모델은 압축된 형태로 저장됨
- 이미 학습된 모델을 통해 추천하기 때문에 서빙속도가 빠르다!
- Sparsity / Scalability 문제 개선
- sparse한 데이터에서도 좋은 성능을 보임 (Sparsity Ratio가 99.5%가 넘을 경우에도 사용 가능)
- 사용자 아이템 개수가 많이 늘어나도 좋은 추천 성능을 보임
- Overfitting 방지
- NBCF와 비교했을 때 전체 데이터의 패턴을 학습하도록 모델이 작동함
- NBCF의 ㄱㅇ우 특정 주변 이웃에 의해 크게 영향을 받을 수 있음
- Limited Coverage 극복
- NBCF의 경우 공통의 유저 / 아이템을 많이 공유해야만 유사도 값이 정확해짐
- NBCF의 유사도 값이 정확하지 않은 경우 이웃의 효과를 보기 어려움
Latent Facotr Model
의미
유저와 아이템 관계를 잠재적 요인으로 표현할 수 있다고 보는 모델
- 다양하고 복잡한 유저와 아이템의 특성을 몇 개의 벡터로 compact하게 표현
유저 아이템 행렬을 저차원의 행렬로 분해하는 방식으로 작동
- 각 차원의 의미는 모델 학습을 통해 생성되며 표면적으로는 알 수 없음
같은 벡터 공간에서 유저와 아이템 벡터가 놓ㅇ힐 경우 유저와 아이템의 유사한 정도를 확인할 수 있음
- 유저 벡터와 아이템 벡터가 유사하게 놓인다면 해당 유저에게 해당 아이템이 추천될 확률이 높음
SVD (Singular Value Decomposition)
Rating Matrix R에 대해 유저와 아이템의 잠재 요인을 포함할 수 잇는 행렬로 분해
- 유저 잠재 요인 행렬
- 잠재 요인 대각행렬
- 아이템 잠재 요인 행렬
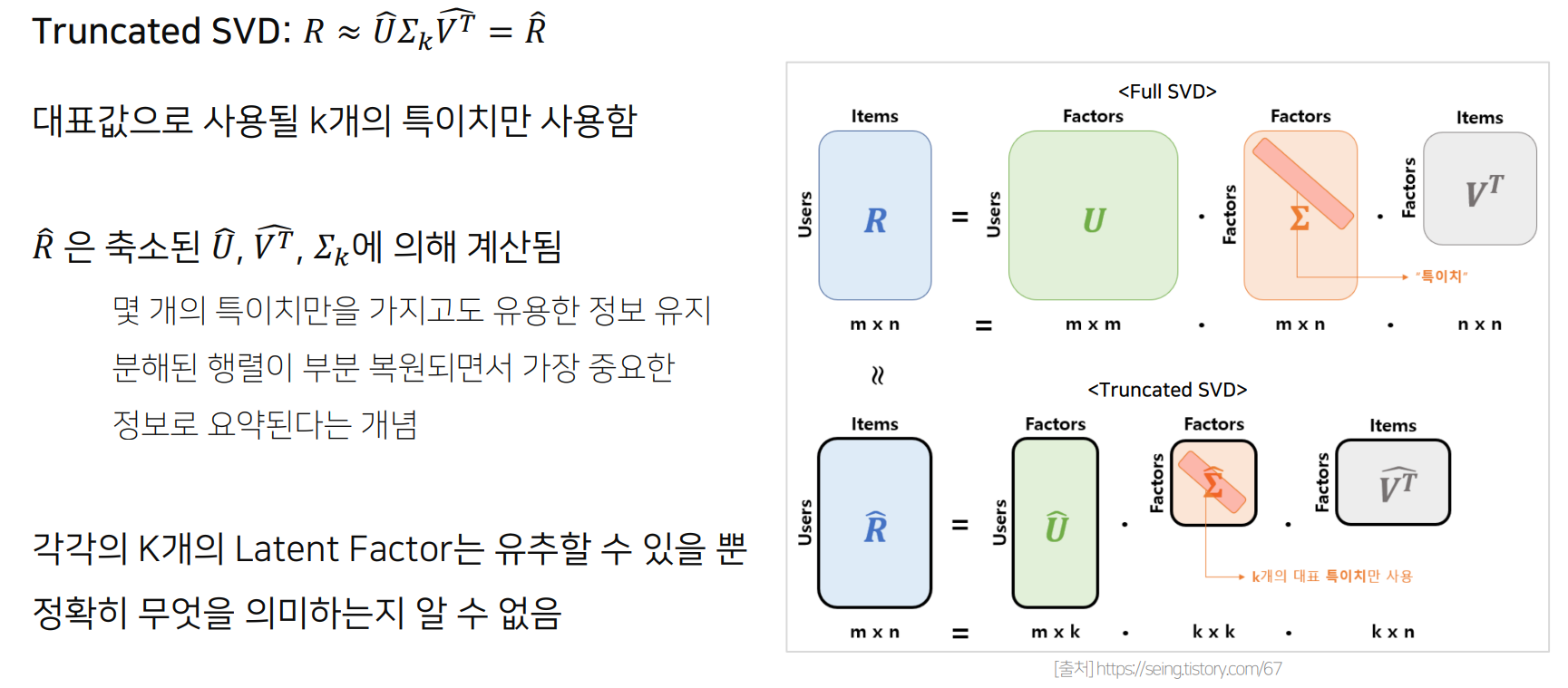
한계
1. Sparse한 데이터에 대해서 결측된 entry를 모두 채우는 inputation을 통해 dense matrix를 만들어주게 되는데 데이터의 양이 상당히 많아져 computation비용이 높아지고 부정확한 imputation은 데이터를 왜곡시켜 예측 정확도를 떨어뜨린다.
2. 행렬의 entry가 적을 때 SVD를 적용하면 과적합 되기 쉽다
SVD의 원리를 차용하되 다른 접근 방법 -> MF의 등장
MF (Matrix Factorization)
User-Item 행렬을 저차원의 User와 Item의 latent factor 행렬의 곱으로 분해하는 방법
SVD의 개념과 유사하나, 관측된 선호도(평점)만 모델링에 활용하여, 관측되지 않은 선호도를 예측하는 일반적인 모델을 만드는 것이 목표
Rating Matrix를 P와 Q로 분해하여 R 과 최대한 유사하게 을 추론(최적화)
Objective Function

Regularization이란?
weight를 loss function에 넣어주면 weight가 너무 커지지 않도록 제한이 거렬 overfitting 방지
추가적으로..
MF에서 이미지적으로 이해하기는 쉽지 않은 것 같다.
또 다양한 MF + 가 많아 각각에 맞는 Objective Function을 구현하는 것을 목표로 해야할 듯 하다.
참고
모든 자료는 부스트캠프 AI Tech교육 자료를 참고
