SVM & Kernel Trick
SVM (Support Vector Machine)
주어진 데이터가 어느 카테고리에 속하는지 판단하는 이진 선형 분류 모델
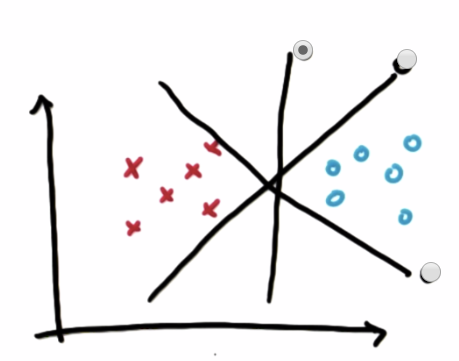 두 데이터 (x/o)를 가장 잘 분류한 것은 가운데 선
두 데이터 (x/o)를 가장 잘 분류한 것은 가운데 선
이유:
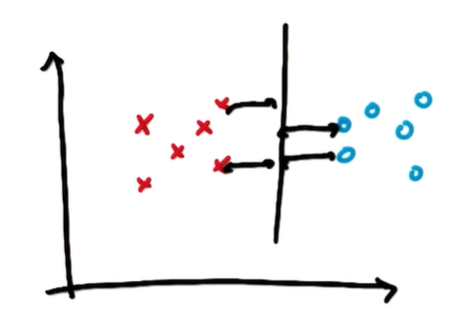 구분선에서 가장 가까운 서로 다른 데이터를 support vector라고 부르고, 구분선에서 support vector까지의 거리를 Margin이라 부르는데,
구분선에서 가장 가까운 서로 다른 데이터를 support vector라고 부르고, 구분선에서 support vector까지의 거리를 Margin이라 부르는데,
Margin이 가장 최대화가 되는 지점이 가운데 선이기 때문
Margin이 가장 최대화가 되는 선을 찾는 이유: 모델의 robust를 위함
Kernel Trick
Linear하게 구분선을 긋지 못하는 경우 저차원의 공간을 고차원의 공간으로 mapping해 linear한 구분선을 그을 수 있게 하는 작업
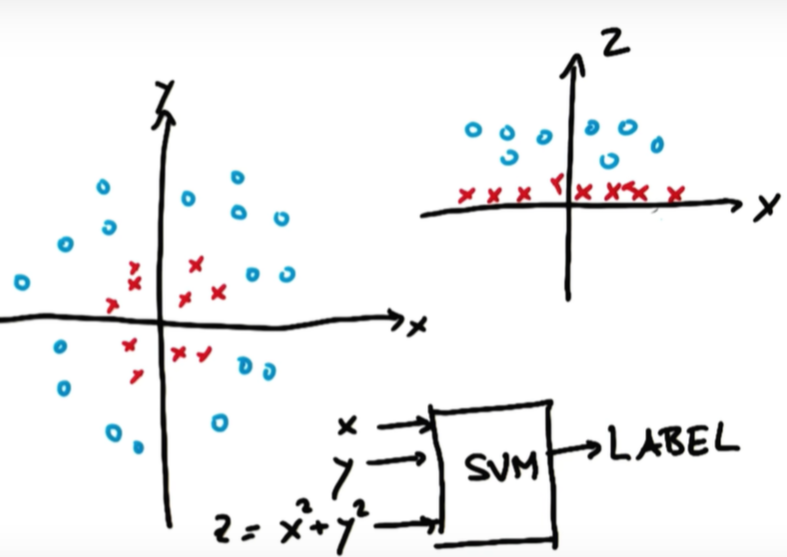
왼쪽 그림에서 o와x를 구분할 수 있는 linear한 구분선을 그을 수 없어서 z=x^2 + y^2를 규정해, x,z로 새로운 좌표평면을 그릴 수 있음
(이때, z는 원점에서 해당 데이터까지의 거리가 된다)
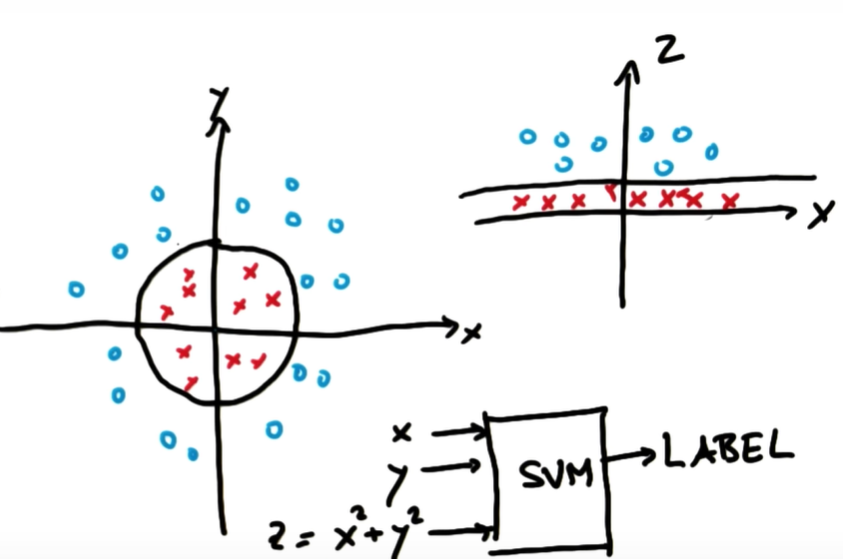
이제 선형으로 구분 가능

사람을 연구하는 공돌이