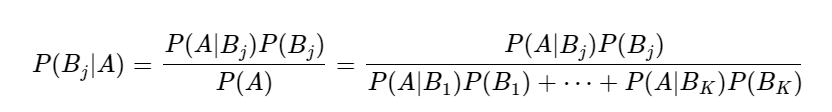표본 분산에서 분모가 N-1인 이유!?
=> 기본적으로 표본은 모집단의 성질을 그대로 나타내ㅜ저야 한다!
그래서 표본분산의 평균이 모분산과 같아져야 하는데
어떤 표본집단의 분산은 모분산보다 클 수도있고 작을수도 있다.
만약 표본분산의 분모 = n-1일 때 E(s2) = σ2이 되면 만족하는데 아래의 식을 거쳐 만족하기 때문에 n-1이 분모가 된다!
2.2 분포
확률 분포를 가정하는 방법 -> histogram
베르누이 분포 데이터가 2개의 값(0,1)만 가지는 경우
카테고리 분포 데이터가 n개의 이산적인 값을 가지는 경우
베타 분포 데이터가 [0,1] 사이에서 값을 가지는 경우
감마, 로그분포 데이터가 0 이상의 값을 가지는 경우
정규분포, 라플라스분포 데이터가 R전체에서 값을 가지는 경우
2.3 조건부 확률과 베이즈 통계학
조건부 확률
P(A∩B)=P(B)P(A∣B)P(A∣B)=P(B)P(A∩B)
베이즈 통계학 (나중에 따로 정리) 베이즈 정리
데이터가 새로 추가되었을 때 정보를 업데이트 하는 방식에 대한 기반이되어 머신러닝에 사용되는 예측 모형의 방법론으로 굉장히 많이 사용되는 개념!!
A 정보가 주어졌을 때 B가 일어날 확률을
B정보가 주어졌을때 A가 일어날 확률식으로 표현할 수 있다
P(B∩A)=P(A)P(A∩B)=P(A)P(B)P(A∣B)
위의 식을 일반적으로 베이즈 정리라고 한다.
위 식에서 핵심은 사건 A 가 일어났을 때의 확률( P(Bj|A) ) 을 계산함에 있어서 이를 거꾸로 뒤집어 B 가 일어났을 때의 확률들( P(A|Bi) 들 )로 표현 할 수 있다는 것!
즉 A 가 조건으로 주어졌을 때 B 의 확률에 대해서 궁금했던 것을 반대로 B 가 조건으로 주어졌을 때 A 의 확률에 대해서 이야기 하는 것으로 바꾸어 쓸 수 있다는 것!!
데이터가 주어졌을 때 구하고자 하는 확률은 보통 다음과 같은 수식으로 설명된다
P(θ∣D)=P(θ)P(D)P(D∣θ)
P(θ∣D) = 사후확률(posterior) : 구하고자 하는 확률 P(θ) = 사전확률(prior) : 이전에 일어난 확률 P(D∣θ) = 가능도(likelihood) : 주어진 모수에서 데이터가 관찰될 확률 P(D) = Evidence : 데이터 전체의 분포 θ : (가설, 가정, 파라미터)
이를 베이즈 정리를 적용해서 다음과 같은 문제를 해결할 수 있다. Example) COVID-99의 발병률이 10%로 알려져 있다. COVID-99에 실제 걸렸을 때 검진될 확률은 99%, 실제로 걸리지 않았을 때 오검진 될 확률이 1%라고 할 때, 어떤 사람이 질병에 걸렸다고 검진결과가 나왔을 때, COVID-99에 감염되었을 확률은?