이번 포스팅은 DB 이중화에 대한 내용을 다루고 있습니다.
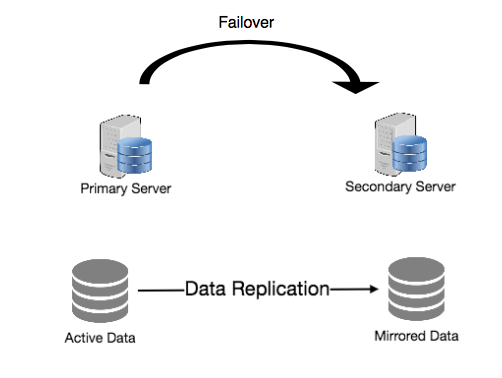
DB를 이중화하는 방법을 설명하기에 앞서 먼저 왜 DB를 이중화 해야하는지 그 필요성부터
이야기 해보겠습니다. 😲
[DB 이중화 필요성]

[DB가 Single로 구성되어 있다면?]
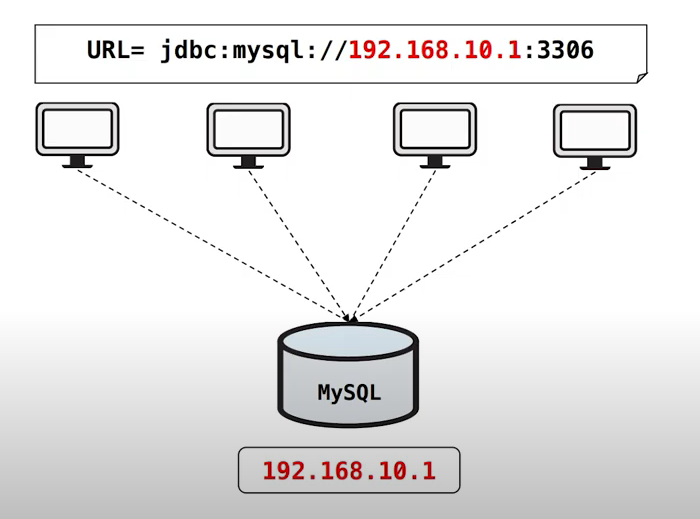
먼저 다음과 같이 물리 IP 192.168.10.1 를 갖고 있는 MySQL DB 한대가 있습니다.
그리고 각각의 서버에서는 DB의 물리 IP를 바라보고 있습니다.
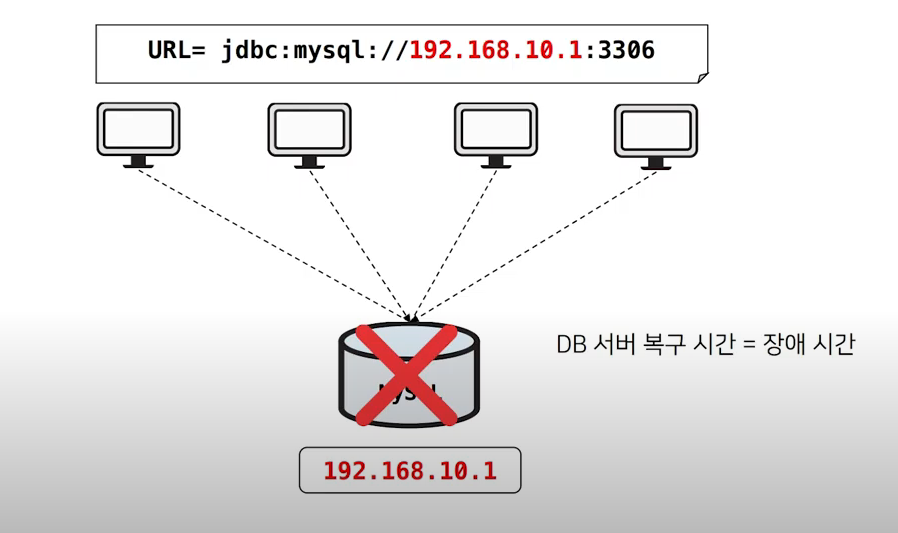
만약에 이 DB 서버가 하드웨어 장애나 MYSQL DB의 문제로 접속이 되지않는다면,
서비스에 들어오는 데이터를 저장하고 이미 저장된 데이터를 조회할 수 없기 때문에
서비스 장애시간 = DB 서버를 복구하는데 걸리는시간 이 됩니다.
[DB가 복제되어 있다면?]
그렇다면 대체할 장비를 하나더 추가하고 복제를 구성한 상황의 경우를 가정해 보겠습니다.
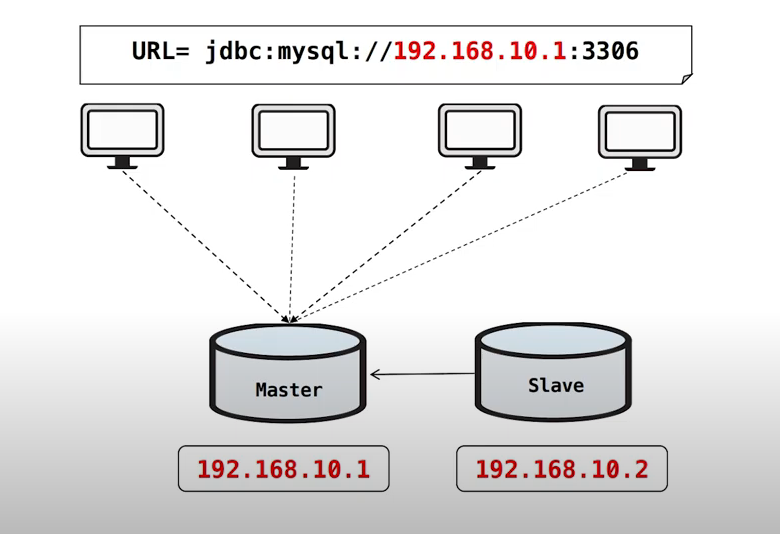
다음과 같이 물리IP 192.168.10.2를 가지는 DB를 한대 추가하여 복제를 구성한다고 해보겠습니다.
각 서버에서는 기존과 동일하게 Master DB의 물리 IP를 바라보고 있습니다.
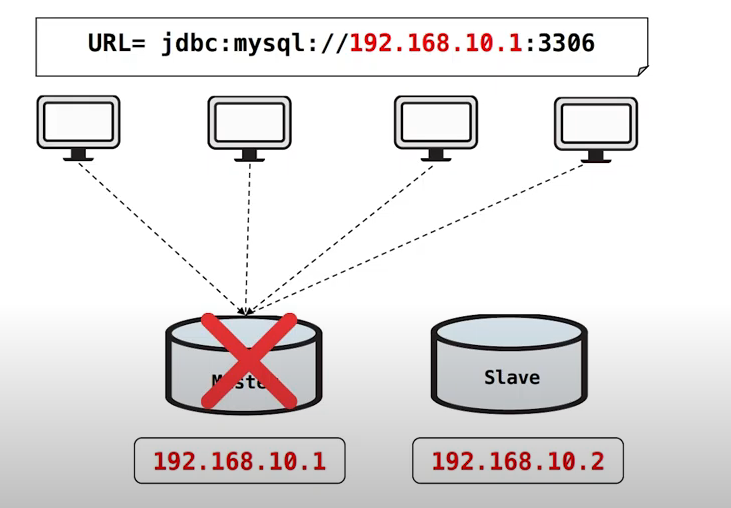
만일 이러한 상황에서 물리 IP 192.168.10.1의 DB가 장애가 발생한다면,
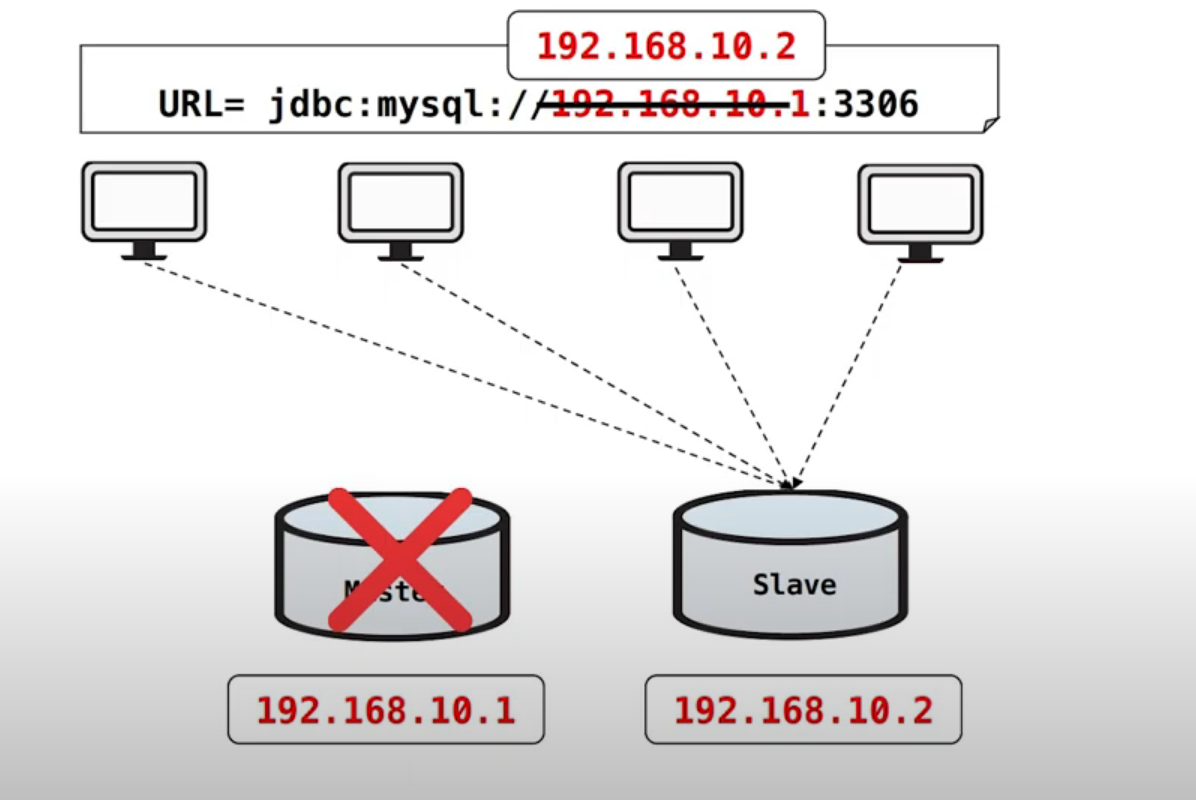
위와 같이 복제해둔 Slave 물리 IP 192.168.10.2 DB로 변경하여 배포해주면
Slave DB로 서비스를 운영할 수 있습니다.
따라서 기존과 달리 서비스 장애시간을
서비스 장애시간 = 커넥션 변경 후 배포하는데 걸리는시간으로 줄일 수 있습니다.
[잠깐! 이런일은 누가 하나요?]
0. 조직이 시스템 엔지니어와 DBA, 서비스개발자로 나뉘어 구성되어있는 상황이라면,
1. 시스템엔지니어와 DBA가 장애를 인지하고 현상을 파악합니다.
2. 개발팀에 이를 공유합니다.
3. 개발팀은 DB 커넥션을 변경하는 방식으로 장애를 처리합니다.하지만... 이렇게 DB를 복제한 경우에도 여전히 DB의 장애시간은
DB 커넥션을 변경하고 배포하는 시간만큼은 발생하고 있습니다 ㅠ.ㅠ
그렇다면!! 여기서 배포 시간 마저도 줄일 수 있도록 VIP(가상 IP)를 추가하는 방법이 있습니다.
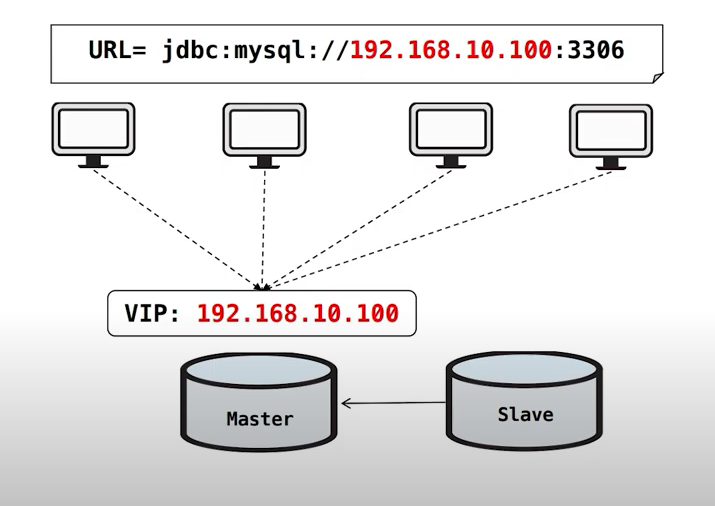
기존의 방식과 다르게 VIP를 통해 Master를 각각의 서버가 바라보고 있는 상황이라면
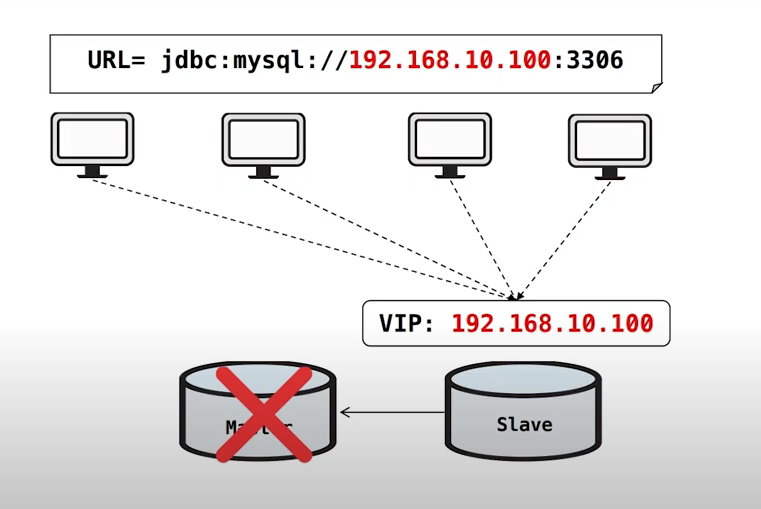
위와 같이 Master DB가 장애가 났을 때,
Master의 VIP를 제거하고 Slave에 VIP를 할당하여 각 서버의 커넥션이 Slave DB로 변경되어
즉시 리커넥트 해주는 방식으로 서버 장애시간을 줄일 수 있습니다.
[이중화 방안]
그렇다면 이렇게 서비스 장애시간을 줄일 수 있는 DB 이중화를 하는 방법에는 어떤것들이 있는지
알아보도록하겠습니다!
[HW 이중화]
[1. Shared Disk]
우선 shared disk 방식은 아래 그림과 같이 Master(Active)와 Master(Standby), 이렇게 두대의
서버로 구성되어 있습니다. ex: OS Cluster(RHCS)
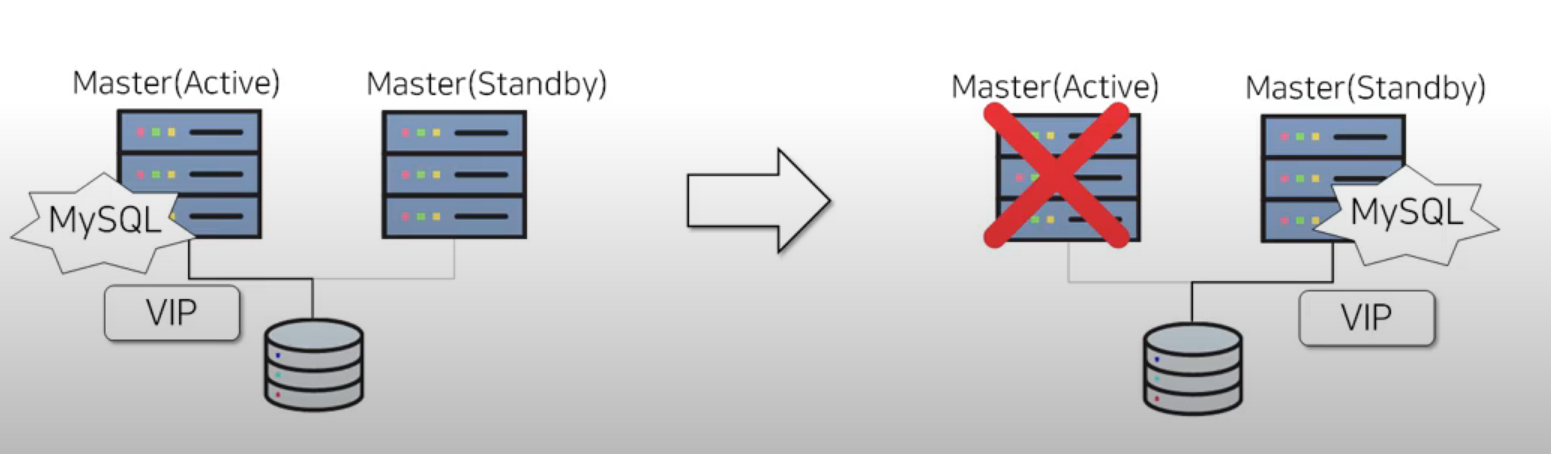
-
하나의 디스크를 공유하는 방식입니다.
-
Master Standby는 Master Acitve가 장애가 발생할경우 Failover 용도로만 사용되며
앞서 설명드린 방식으로 VIP를 Standby에 할당하여 주는 방식입니다.
Failover란?
장애 극복 기능(failover,페일오버)은 컴퓨터 서버, 시스템, 네트워크 등에서 이상이 생겼을 때
예비 시스템으로 자동 전환 되는 기능을 의미합니다.
[Shared Disk 방식의 문제점]
-
RHCS 솔루션을 구매하는 비용이 필요
-
고비용의 SHARED DISK 필요
[2. DISK 복제]
앞서 설명해드린 Shared DISK방식의 경우 고비용으로 인해 사용하기 부담스러운 경우가 많습니다.
따라서 실제로 하드웨어레벨에서 많이 사용하는 방식은 DISK 복제 방식이 있습니다.
DISK 복제 방식은 별도의 Shared DISK 방식과 달리 별도의 라이센스나 고성능 DISK가
없어도 사용이 가능하며, 오픈소스로 구성이 가능합니다.
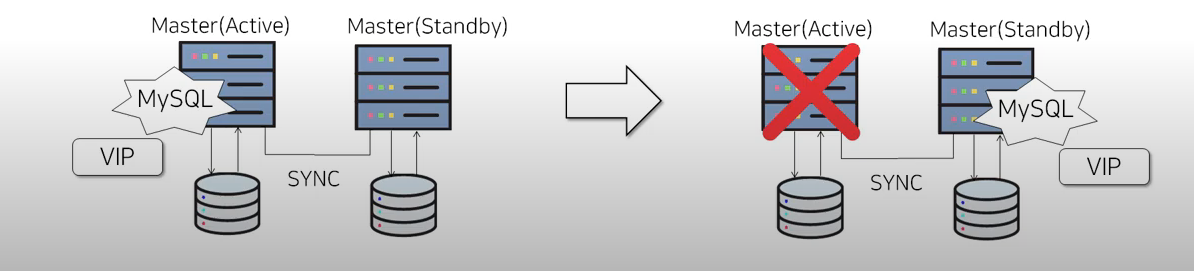
위 그림과 같이 Active와 Standby는 하나의 디스크를 공유하지않고 각각의 디스크를 바라보며,
평상시에 Active에 서버를 띄워 서비스를 하며, 이를 네트워크 통신을 통해 동기화하여
Standby가 같은 DB를 가지게끔 해줍니다.
[Disk 복제 방식의 문제점]
DISK 복제 방식을 선택하여 Shared DISK에 비해 비용을 줄였다고 할지라도,
DISK 복제 방식은 네트워크를 이용하여 DB를 복제하는 방식이 핵심이기 때문에
Network Latency에 의해 성능 영향을 받게됩니다.
latency(지연 속도) 란?
네트워크에서 하나의 데이터 패킷이 한 지점에서 다른 지점으로 보내지는 데 소요되는 시간.
또한 하드웨어 이중화 방식의 경우 아래와 같은 한계점 또한 존재합니다.
[두 방식의 공통적인 한계점]
-
Stand by 서버의 경우 FAILOVER시에만 사용 가능
-
백업을 위한 추가 서버가 필요
-
유지보수 및 장애 대응 어려움( OS 및 하드웨어에 대한 지식이 필요)
[MySQL Replication 이중화]
이러한 하드웨어 이중화 방식의 한계때문에 MySQL Replication 이중화를 이용하게 됩니다.
우선 MySQL Replication(복제) 또한 2대 이상의 DBMS를 나눠서 데이터를 저장하는,
비동기 방식의 복제 방식입니다.
[MySQL Replication의 동작원리]
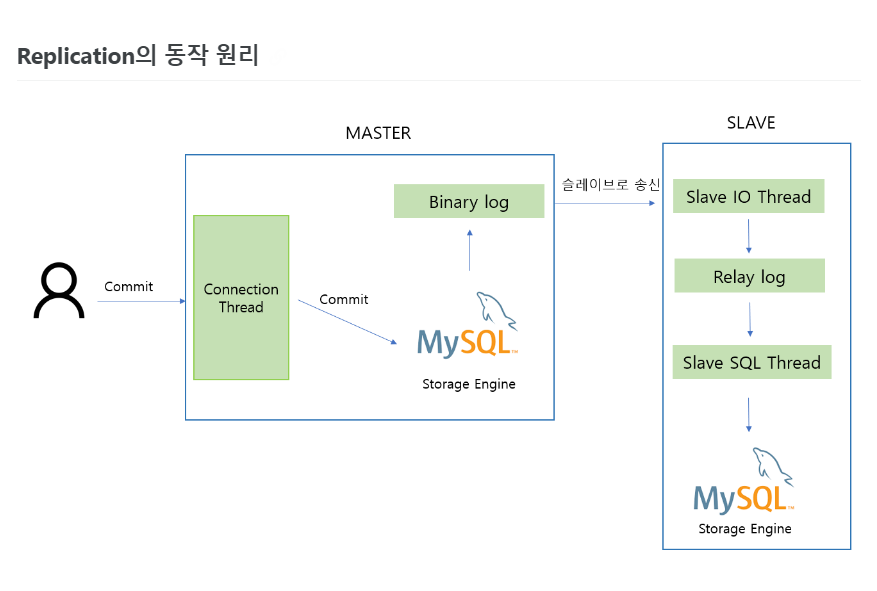
- 클라이언트가 Commit 을 누르면 먼저 Master 서버에 존재하는
Binary log 에 변경사항을 모두 기록합니다.
- Master Thread 는 비동기적으로 (복사되는 시간을 기다려주지 않습니다)
Binary log를 읽어 Slave 서버로 전송합니다.
- Slave 의 I/O Thread 는 Master로 부터 받은 변경 데이터들을
Relay log 에 기록을 합니다.
- Slave의 SQL Thread 는 Replay log의 기록들을 읽어 자신의 스토리지 엔진에 최종
적용합니다.
[MySQL Replication의 사용목적]
기존의 서비스 장애시간 단축 이외에도 다음과 같은 목적들이 있습니다.
[Scale-out Solution]
부하를 분산시켜줄 수 있습니다. 모든 프로젝트가 그렇겠지만 CRUD 연산이 하나의
DB에서 일어난다면, 트래픽이 늘어남에 따라 자연스럽게 병목현상이 생길 수 밖에 없습니다.
쓰기는 원본 서버에서만 수행하게 하고 읽기는 원본의 복제 서버에서 읽어오게 한다면 쓰기의 기능과
읽기의 기능을 병목 없이 모두 향상시킬 수 있게됩니다.
[데이터의 보안]
Replication 을 구성하게 되면 항상 복제를 진행하는게 아닌, 일시중지가 가능합니다.
이는 원천 데이터를 손상시키지 않고 복제본에서 백업 서비스를 작동시키는게 가능하게 해줍니다.

4개의 댓글



I kept getting confused by the terminology, but thanks to this I learned it again. Thank you!
https://solaraexecutor.dev/
이중화에 대해서는 처음 들어봤네요! 좋은 글 감사합니다