
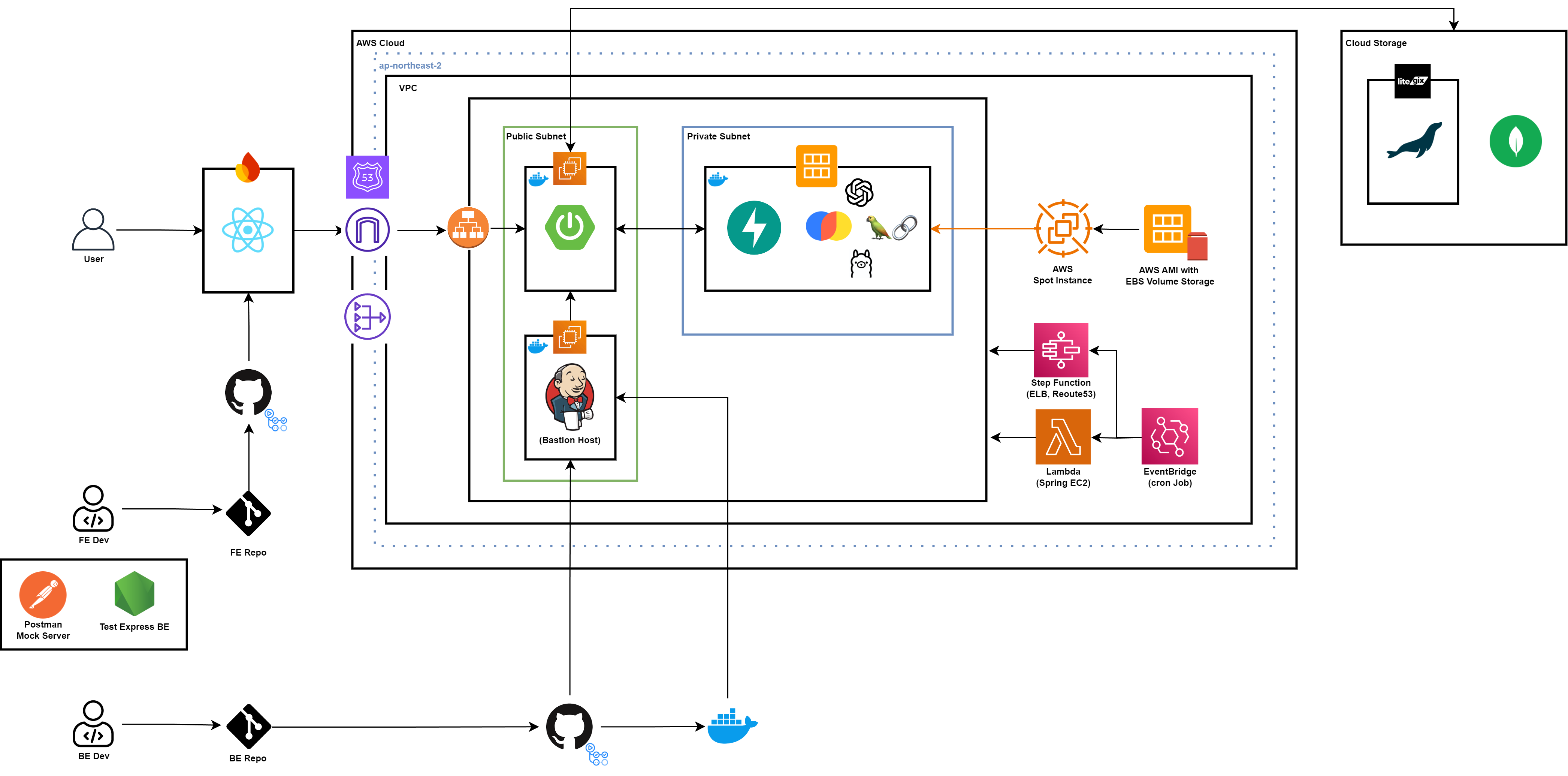
 개발 도중 과도한 AWS 과금이 발생하여 청구서를 분석하여 봤을 때, 개발이 진행되지 않는 시간대에도 EC2, EBS 및 ELB에 대한 요금이 지속적으로 발생하는 것을 확인하였다.
개발 도중 과도한 AWS 과금이 발생하여 청구서를 분석하여 봤을 때, 개발이 진행되지 않는 시간대에도 EC2, EBS 및 ELB에 대한 요금이 지속적으로 발생하는 것을 확인하였다.
따라서 개발 비용을 아끼고 추후 서비스 운영시 가용성을 확보하기 위해 위와 같은 구조로 아키텍처를 설계하였다.
EC2 Auto Restart
우선 현재 구동되고 있는 Spring BE 및 Jenkins 인스턴스를 시간에 맞추어 자동으로 재시작해주는 기능을 개발하는 것을 목표로 삼았다.
IAM Role
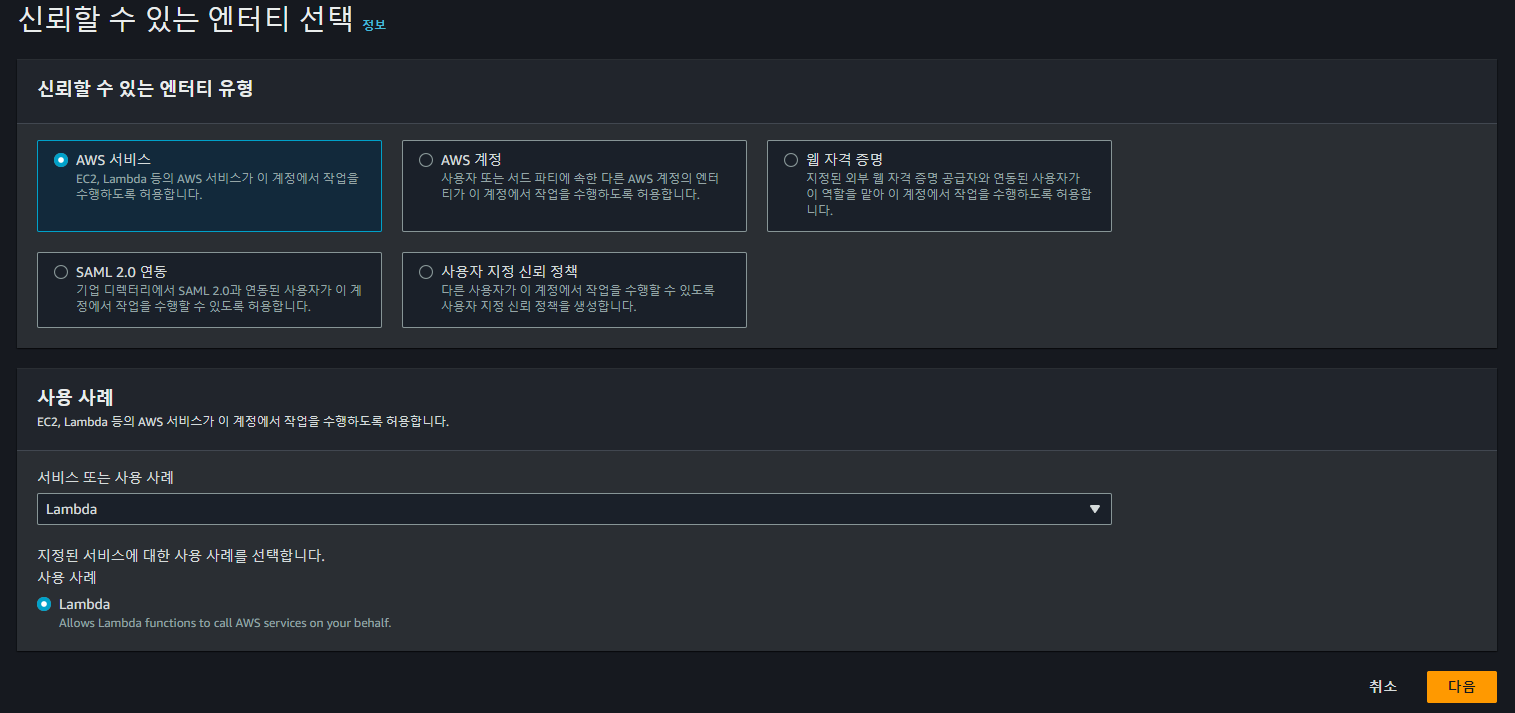
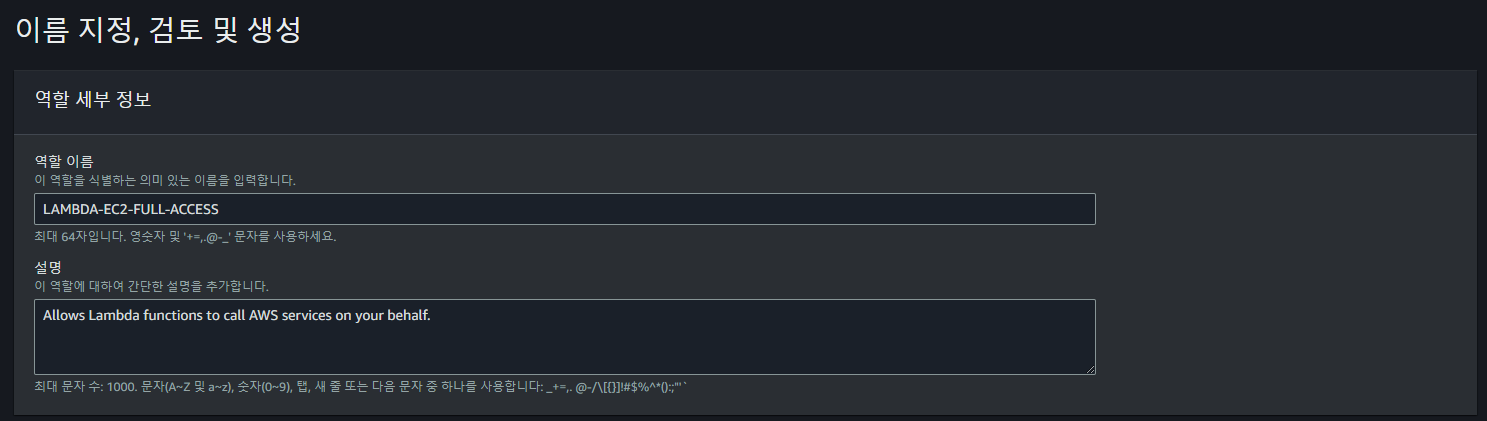 우선 위와 같이 Lambda에서 사용할 수 있는 IAM Role을 생성한다.
우선 위와 같이 Lambda에서 사용할 수 있는 IAM Role을 생성한다.
Lambda Function
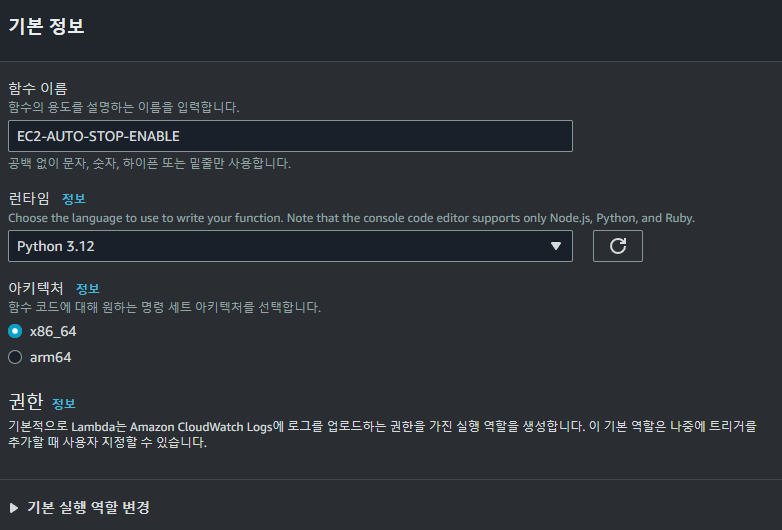 이후 위와 같이 새로운 Lambda Function을 생성해주었다.
이후 위와 같이 새로운 Lambda Function을 생성해주었다.
이때 Node.js 런타임을 선택할 경우 별도로 라이브러리를 설치해줘야 하기 때문에 Python을 통해 Lambda Function을 개발하였다.
import boto3
from datetime import datetime, timedelta
# Seoul region
REGION = 'ap-northeast-2'
# Days of the week in Korean
WEEKDAYS = ["월", "화", "수", "목", "금", "토", "일"]
def lambda_handler(event, context):
print("Start [EC2-AUTO-STOP-ENABLE]")
# Get current time in KST (UTC+9)
now = datetime.utcnow() + timedelta(hours=9)
current_day = WEEKDAYS[now.weekday()]
current_hour = now.hour
print(f"Current time: {current_day}, {current_hour:02d}:00")
ec2 = boto3.client('ec2', region_name=REGION)
# Get all EC2 instances with required tags
instances = ec2.describe_instances(
Filters=[
{'Name': 'tag:AUTOSTOP_ENABLE', 'Values': ['true', 'True']},
{'Name': 'tag-key', 'Values': ['DAY', 'TIME']}
]
)
print("Current Instances in",REGION,":",len(instances))
for reservation in instances['Reservations']:
for instance in reservation['Instances']:
instance_id = instance['InstanceId']
tags = {tag['Key']: tag['Value'] for tag in instance.get('Tags', [])}
print(instance_id, ":", tags)
days = tags.get('DAY', '').split(',')
times = tags.get('TIME', '').split('~')
if current_day not in days:
continue
try:
start_time, end_time = map(int, times)
except ValueError:
print(f"Invalid time format for instance {instance_id}")
continue
if start_time <= current_hour and current_hour <= end_time:
print(f"Starting instance {instance_id}")
ec2.start_instances(InstanceIds=[instance_id])
else:
print(f"Stopping instance {instance_id}")
ec2.stop_instances(InstanceIds=[instance_id])
print("End [EC2-AUTO-STOP-ENABLE]")Lambda Function에서는 ap-northeast-2 리전의 모든 인스턴스에 대한 정보를 받아온 후 AUTOSTOP_ENABLE 태그가 true 또는 True인 모든 인스턴스에 대해 요일 및 가동 시간을 바아와 이에 맞추어 start 또는 stop 명령을 전송한다.
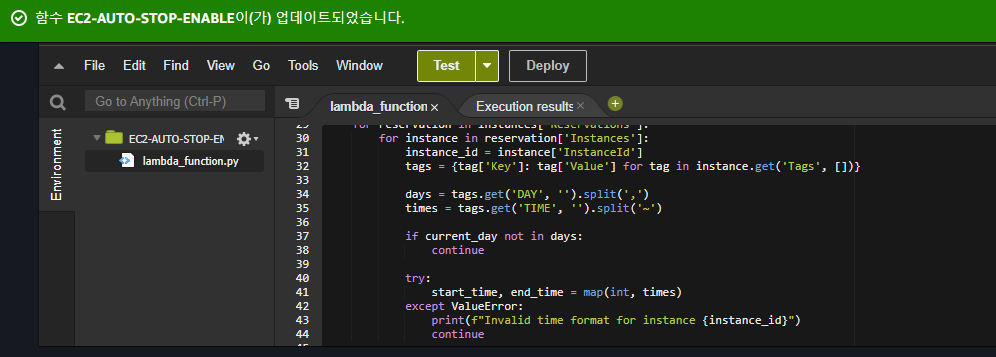 이후 해당 Lambda Function을 성공적으로 업데이트 하고
이후 해당 Lambda Function을 성공적으로 업데이트 하고
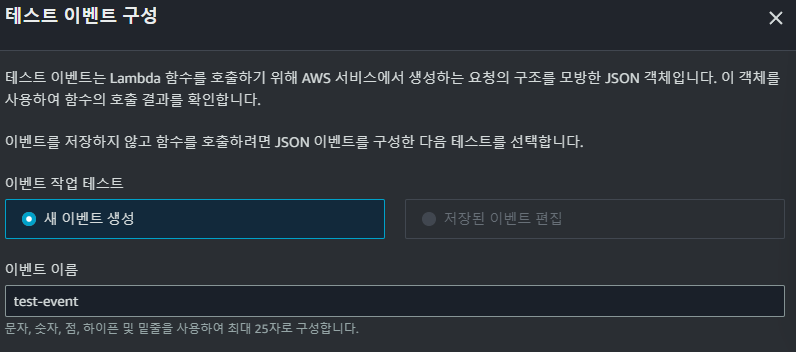 테스트를 위해새로운 이벤트를 생성해주었다.
테스트를 위해새로운 이벤트를 생성해주었다.
https://danawalab.github.io/aws/2021/05/03/aws-autostop.html
TroubleShooting : Task timed out
RequestId: e83cda25-a05d-4bf5-abdd-b036eac5ed78 Error: Task timed out after 3.00 seconds이러한 상황에서 Lambda Function을 실행시켰을 경우 위와 같은 timeout 오류가 발생하여
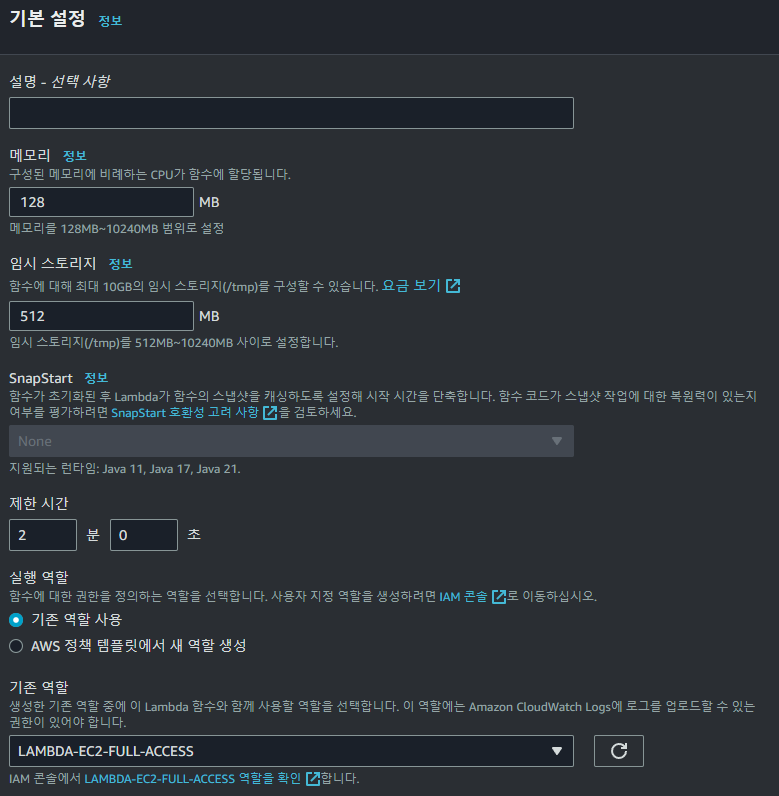 Lambda Function의 기본 설정 내에서 제한 시간을 2분으로 변경해주었다.
Lambda Function의 기본 설정 내에서 제한 시간을 2분으로 변경해주었다.
이때 Lambda는 경우 실행 횟수뿐 아닌 실행 시간을 기준으로 과금되기 때문에 재한 시간을 주의하여 설정해주어야 한다.
 먼저 테스트를 위하여 인스턴스를 중지하였다.
먼저 테스트를 위하여 인스턴스를 중지하였다.
 이후 인스턴의 태그에 위와 같이 3개의 항목을 모두 추가해주고
이후 인스턴의 태그에 위와 같이 3개의 항목을 모두 추가해주고
 Lambda Function 테스트를 실행하면
Lambda Function 테스트를 실행하면
 로그에서도 아무 오류 없이 구동되며 인스턴스가 실행 중인 것을 볼 수 있다.
로그에서도 아무 오류 없이 구동되며 인스턴스가 실행 중인 것을 볼 수 있다.
Cloudwatch EventBridge
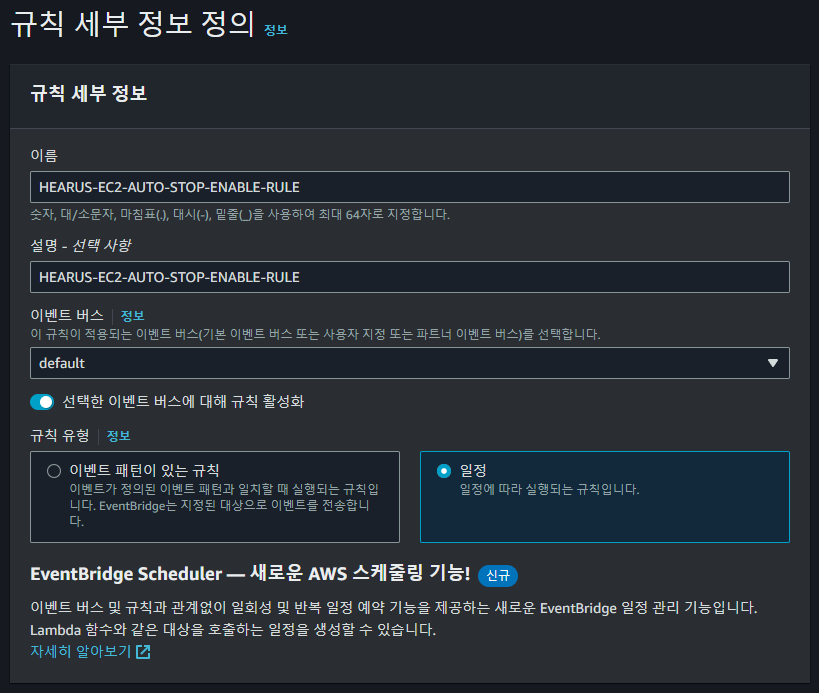 이러한 작업을 자동화해주기 위하여
이러한 작업을 자동화해주기 위하여 Cloudwatch EventBridge의 새로운 규칙을 정의해주었다.
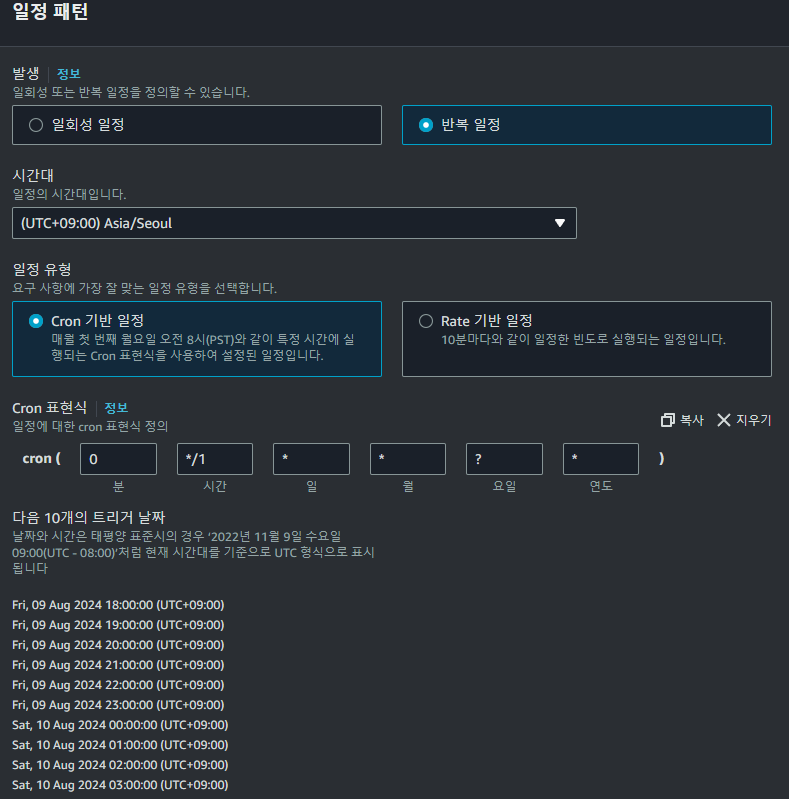
0 */1 * * ? *반복 일정에 대한 cron 패턴을 위와 같이 매일 1시간에 한번씩 실행할 수 있도록 설정하고
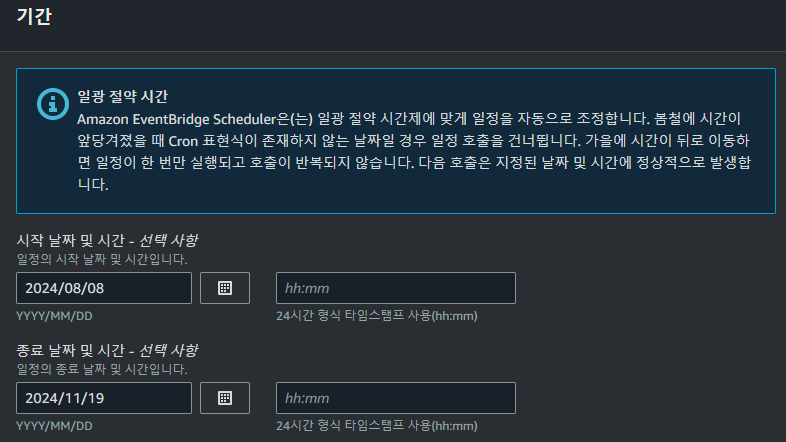 임의로 11월 19일까지 기간을 설정한 후
임의로 11월 19일까지 기간을 설정한 후
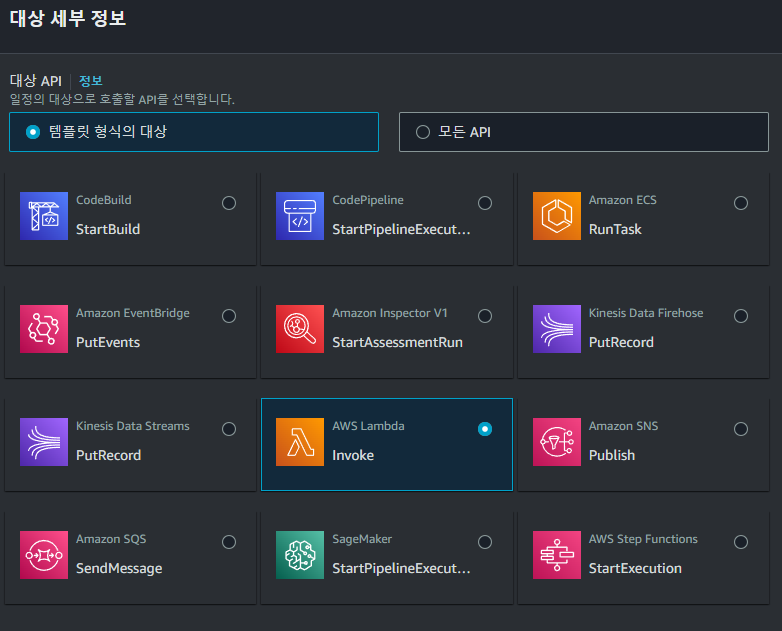 템플릿 형식의 대상을 Lambda Invoke로 선택한다.
템플릿 형식의 대상을 Lambda Invoke로 선택한다.
 이후 위와 같이 일정을 활성화하고 나머지 설정을 완료한 후
이후 위와 같이 일정을 활성화하고 나머지 설정을 완료한 후
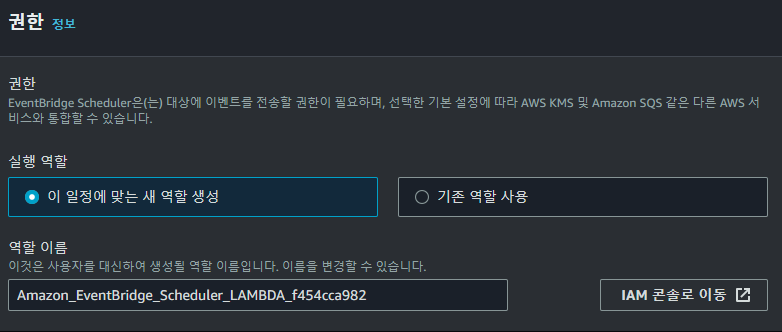 해당 일정에 맞는 새로운 역할을 생성해주면
해당 일정에 맞는 새로운 역할을 생성해주면
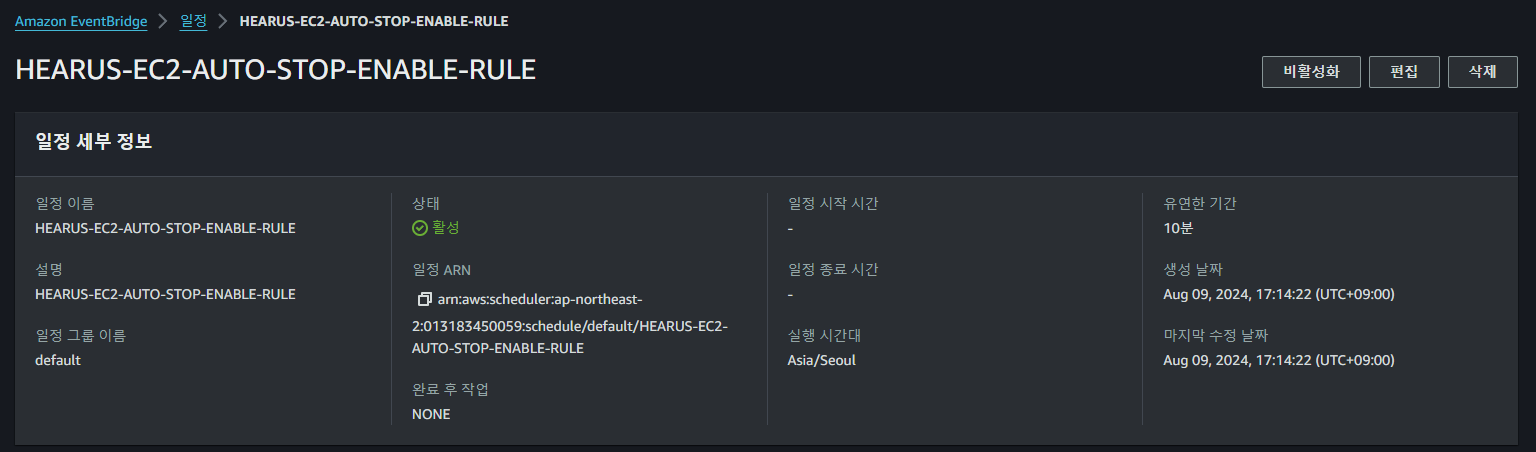 정상적으로 일정이 생성되고 매 1시간에 1번씩 EC2 인스턴스의 태그를 검사하여 자동적으로 해당 인스턴스를 stop시키거나 start 시키는 것을 볼 수 있다.
정상적으로 일정이 생성되고 매 1시간에 1번씩 EC2 인스턴스의 태그를 검사하여 자동적으로 해당 인스턴스를 stop시키거나 start 시키는 것을 볼 수 있다.
Auto docker-compose
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES하지만 Spring-BE 인스턴스의 경우 현재 Docker를 통해 서버를 구동시키고 있었기에, 인스턴스가 재시작되면 위와 같이 Docker의 컨테이너가 중지되는 문제가 있었다.
sudo curl -L https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m) -o /usr/bin/docker-compose
sudo chmod +x /usr/bin/docker-compose
mkdir hearus-spring
cd hearus-spring
vi docker-compose.yaml따라서 인스턴스가 재시작되었을 때 자동적으로 컨테이너를 구동시킬 수 있도록 docker-compose를 설치하고
docker-compose.yaml
version: '3'
services:
hearus-spring:
image: ...
container_name: ...
ports:
- "8080:8080"
- "9094:9094"
deploy:
mode: replicated
replicas: 1
restart: always위와 같이 docker-compose.yaml을 정의하였다.
services: 실행할 서비스(컨테이너)를 정의image: 사용할 Docker 이미지를 지정container_name: 컨테이너 이름을 지정ports: 포트 매핑을 설정
호스트의 8080 포트를 컨테이너의 8080 포트로, 9094 포트를 9094 포트로 매핑deploy: 배포 관련 설정을 지정mode: replicated: 복제 모드를 사용replicas: 1: 1개의 복제본을 실행
이는 -d 옵션, detached 모드와 유사한 효과restart: always: 컨테이너가 종료되면 항상 재시작하도록 설정
docker_boot.service
[Unit]
Description=docker boot
After=docker.service
[Service]
Type=oneshot
RemainAfterExit=yes
WorkingDirectory=/root/hearus-spring
ExecStart=/usr/bin/docker-compose -f /root/hearus-spring/docker-compose.yaml up -d --remove-orphans
[Install]
WantedBy=multi-user.target이후 docker_boot.service 파일을 생성한다,
이때 절대경로, docker를 실행하기 위한 permission에 주의해야 한다.
sudo cp -v docker_boot.service /etc/systemd/system이후 해당 파일을 /etc/systemd/system에 복사하고
sudo systemctl enable docker_boot.service
sudo systemctl start docker_boot.servicedocker_boot.service 서비스를 enable한 이후 시작한다.
$ sudo systemctl status docker_boot.service
● docker_boot.service - docker boot
Loaded: loaded (/etc/systemd/system/docker_boot.service; enabled; preset: enabled)
Active: active (exited) since Fri 2024-08-09 04:48:08 UTC; 10s ago
Process: 1617 ExecStart=/usr/bin/docker-compose -f /root/hearus-spring/docker-compose.yaml up -d >
Main PID: 1617 (code=exited, status=0/SUCCESS)
CPU: 41ms최종적으로 systemctl을 통해 해당 서비스의 작동 여부를 확인한 이후
$ curl -L localhost:8080
...
</head>
<body>
<div class="container">
<img src="/images/logo.png" alt="Logo" class="logo">
<h1>HEARUS</h1>
<h3>모두의 들을 권리를 위하여</h3>
</div>
</body>localhost에 요청을 보내 서버가 정상적으로 실행되는 것을 확인할 수 있다.
 Docker 컨테이너 실행 여부를 확인하기 위해 재부팅 처리하고
Docker 컨테이너 실행 여부를 확인하기 위해 재부팅 처리하고
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e2c60dde4d33 judemin/hearus-spring:latest "java -jar app.jar" 2 minutes ago Up 13 seconds 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp, 0.0.0.0:9094->9094/tcp, :::9094->9094/tcp hearus-springdocker ps 명령어로 재부팅된 이후에도 서버가 정상적으로 실행되는 것을 볼 수 있다.
https://stackoverflow.com/questions/63317771/launch-docker-automatically-when-starting-ec2-server
ELB Auto Restart
 또한 서버 Custom Domain 연결을 위한 ELB를 EC2 인스턴스와 같은 방법으로 재시작하기 위하여 AWS Step Function 서비스를 활용하였다.
또한 서버 Custom Domain 연결을 위한 ELB를 EC2 인스턴스와 같은 방법으로 재시작하기 위하여 AWS Step Function 서비스를 활용하였다.
Step Function
Step Functions은 AWS에서 제공하는 서버리스 워크플로우 서비스
복잡한 프로세스를 여러 단계로 나누어 관리하고 실행할 수 있게 해주는 도구
Step Functions를 사용하면 긴 실행 시간이 필요한 작업을 보다 안정적이고 확장 가능한 방식으로 처리 가능
Step Functions의 주요 특징:
- 시각적 워크플로우: 복잡한 프로세스를 그래픽 인터페이스로 설계
- 오류 처리: 자동 재시도, 대체 경로 등의 오류 처리 메커니즘을 제공
- 병렬 처리: 여러 작업을 동시에 실행 가능
- 상태 관리: 워크플로우의 각 단계의 상태를 자동으로 추적
Step Functions 사용시 이점
- 긴 실행 시간 처리: Lambda의 15분 제한을 우회 가능
- 오류 처리: 각 단계에서 발생할 수 있는 오류를 더 세밀하게 처리
- 시각화: AWS 콘솔에서 워크플로우를 시각적으로 확인하고 디버그
- 재시도 로직: 실패한 단계를 자동으로 재시도 가능
 먼저 위와 같이 새로운 Step Function을 생성한다
먼저 위와 같이 새로운 Step Function을 생성한다
{
"Comment": "A state machine that manages ALB and Route 53 based on time",
"StartAt": "Check Existing ALB",
"States": {
"Check Existing ALB": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:function:CheckExistingALB",
"Next": "Determine Action"
},
"Determine Action": {
"Type": "Choice",
"Choices": [
{
"And": [
{
"Variable": "$.albExists",
"BooleanEquals": true
},
{
"Variable": "$.shouldExist",
"BooleanEquals": false
}
],
"Next": "Delete Route 53 Record"
},
{
"And": [
{
"Variable": "$.albExists",
"BooleanEquals": false
},
{
"Variable": "$.shouldExist",
"BooleanEquals": true
}
],
"Next": "Create ALB"
}
],
"Default": "No Action Required"
},
"Delete Route 53 Record": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:function:DeleteRoute53Record",
"Next": "Delete ALB"
},
"Delete ALB": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:function:DeleteALB",
"End": true
},
"Create ALB": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:function:CreateALB",
"Next": "Create Route 53 Record"
},
"Create Route 53 Record": {
"Type": "Task",
"Resource": "arn:aws:lambda:REGION:ACCOUNT_ID:function:CreateRoute53Record",
"End": true
},
"No Action Required": {
"Type": "Pass",
"End": true
}
}
}이후 위와 같이 Step Function 설정을 구성한다.
이는 Step Function의 Workflow를 정의한 것으로 직접 기능하는 Lambda Function을 새롭게 생성하여 arn을 통해 연결해주어야 한다.
Lambda Function
CheckExistingALB Lambda
import boto3
from datetime import datetime, time, timedelta
def lambda_handler(event, context):
elbv2 = boto3.client('elbv2')
alb_name = event['albName']
start_time = event['startTime']
end_time = event['endTime']
current_time = datetime.utcnow() + timedelta(hours=9)
current_hour = current_time.hour
print(f"Current time:",current_time)
alb_exists = False
alb_arn = None
alb_dns_name = None
alb_hosted_zone_id = None
try:
response = elbv2.describe_load_balancers(Names=[alb_name])
alb = response['LoadBalancers'][0]
alb_exists = True
alb_arn = alb['LoadBalancerArn']
alb_dns_name = alb['DNSName']
alb_hosted_zone_id = alb['CanonicalHostedZoneId']
except elbv2.exceptions.LoadBalancerNotFoundException:
pass
should_exist = is_time_between(current_hour, start_time, end_time)
event.update({
'albExists': alb_exists,
'albArn': alb_arn,
'albDNSName': alb_dns_name,
'albHostedZoneId': alb_hosted_zone_id,
'shouldExist': should_exist
})
return event
def is_time_between(current_hour, start_time, end_time):
if start_time < end_time:
return start_time <= current_hour <= end_time
else: # 자정을 넘어가는 경우 (예: 23:00 ~ 02:00)
return current_hour >= start_time or current_hour <= end_timeCheckExistingALB는 존재하는 ALB를 검사하고 만약 ALB가 존재하고 시간 정보가 일치한다면 ALB의 arn과 hostedzone 등을 업데이트하여 다음 Lambda Function의 Input Event로 전달한다.
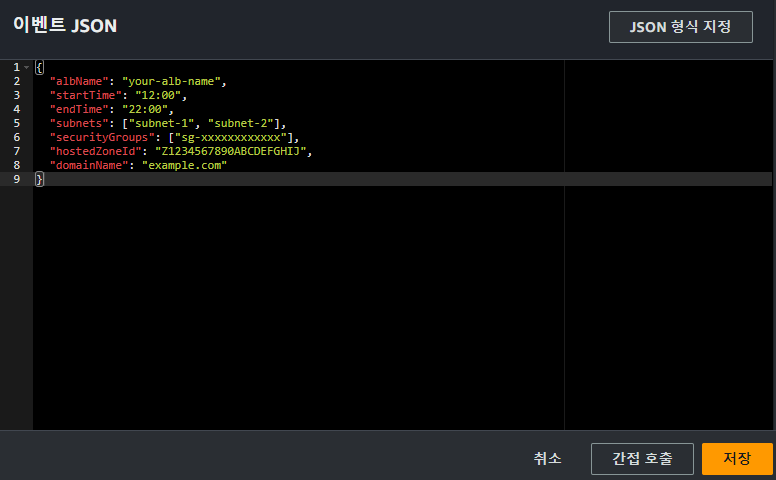 위와 같이 테스트 이벤트를 구성하고 Lambda Function을 실행시키면
위와 같이 테스트 이벤트를 구성하고 Lambda Function을 실행시키면
Test Event Name
test-2
Response
{
"albExists": false,
"albArn": null,
"albDNSName": null,
"albHostedZoneId": null,
"shouldExist": true
}
Function Logs
START RequestId: 1fd0a568-1cbd-49e6-8890-5d540d8d377a Version: $LATEST
Current time: 2024-08-09 19:27:19.055093
END RequestId: 1fd0a568-1cbd-49e6-8890-5d540d8d377a현재 시간대에 ALB가 존재해야 한다는 정보를 리턴하는 것을 볼 수 있다.
CreateALB
import boto3
def lambda_handler(event, context):
elbv2 = boto3.client('elbv2')
alb_name = event['albName']
subnets = event['subnets']
security_groups = event['securityGroups']
target_groups = event['targetGroups']
# ALB 생성
response = elbv2.create_load_balancer(
Name=alb_name,
Subnets=subnets,
SecurityGroups=security_groups,
Scheme='internet-facing',
Type='application'
)
new_alb = response['LoadBalancers'][0]
alb_arn = new_alb['LoadBalancerArn']
processed_target_groups = []
# 기존 대상 그룹 처리 및 리스너 추가
for tg in target_groups:
target_group_arn = tg['targetGroupArn']
# 기존 대상 그룹 정보 가져오기
tg_info = elbv2.describe_target_groups(TargetGroupArns=[target_group_arn])['TargetGroups'][0]
tg_name = tg_info['TargetGroupName']
# 리스너 생성 및 대상 그룹 연결
listener_response = elbv2.create_listener(
LoadBalancerArn=alb_arn,
Protocol=tg['listenerProtocol'],
Port=tg['listenerPort'],
DefaultActions=[
{
'Type': 'forward',
'TargetGroupArn': target_group_arn
}
]
)
processed_target_groups.append({
'name': tg_name,
'arn': target_group_arn,
'listenerArn': listener_response['Listeners'][0]['ListenerArn']
})
event.update({
'albArn': alb_arn,
'albDNSName': new_alb['DNSName'],
'albHostedZoneId': new_alb['CanonicalHostedZoneId']
})
return event또한 이후 새로운 alb를 생성하는 Lambda Function을 위와 같이 구성한다.
{
"albName": "my-alb",
"subnets": ["subnet-1234", "subnet-5678"],
"securityGroups": ["sg-1234"],
"targetGroups": [
{
"targetGroupArn": "arn:aws:elasticloadbalancing:region:account-id:targetgroup/existing-tg-1/...",
"listenerProtocol": "HTTP",
"listenerPort": 80
},
{
"targetGroupArn": "arn:aws:elasticloadbalancing:region:account-id:targetgroup/existing-tg-2/...",
"listenerProtocol": "HTTPS",
"listenerPort": 443
}
]
"certificateArn": "arn:aws:acm:ap-northeast-2:013183450059:certificate/your-certificate-id"
}위와 같은 테스트 이벤트 Input을 구성하고 요청하면
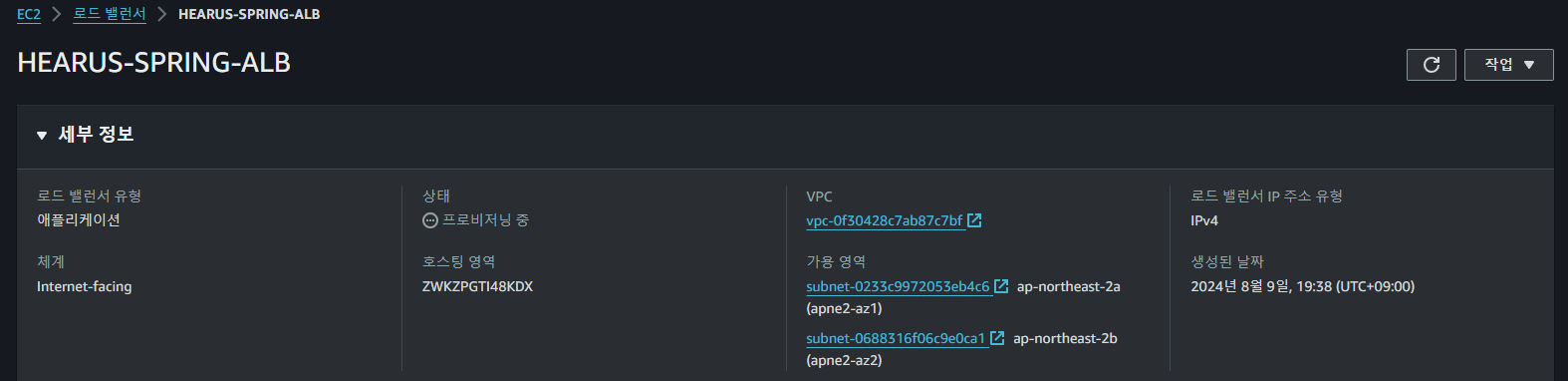 위와 같이 새롭게 ALB가 생성되는 것을 볼 수 있으며
위와 같이 새롭게 ALB가 생성되는 것을 볼 수 있으며
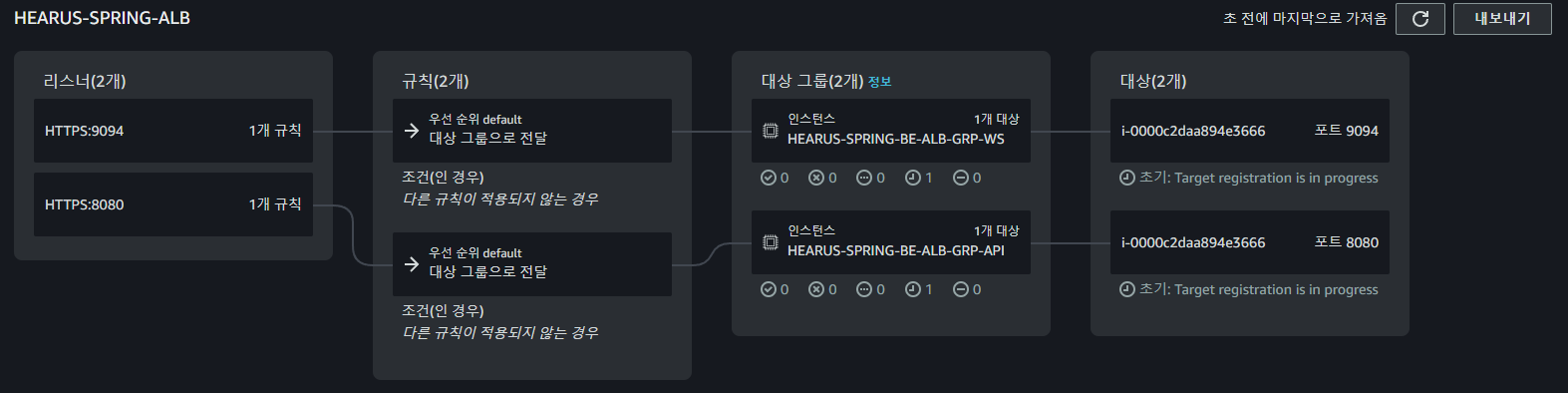 함수의 내용에 따라 Target Group이 연결된 ALB의 네트워크 맵이 구성되는 것을 볼 수 있다.
함수의 내용에 따라 Target Group이 연결된 ALB의 네트워크 맵이 구성되는 것을 볼 수 있다.
DeleteExistingALB
import boto3
def lambda_handler(event, context):
elbv2 = boto3.client('elbv2')
alb_arn = event['albArn']
elbv2.delete_load_balancer(LoadBalancerArn=alb_arn)
event['albStatus'] = 'Deletion initiated'
return event{
"albArn": "my-alb"
}또한 만약 ALB가 삭제되어야 할 때의 Lambda Function을 위와 같이 구성하고 테스트를 요청하면
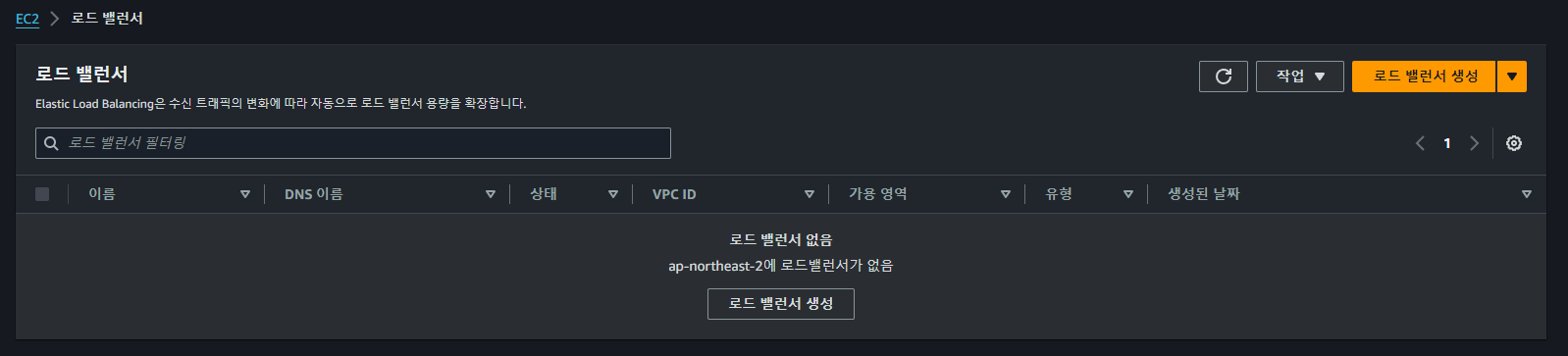 바로 이전에 생성된 ALB가 정상적으로 삭제되는 것을 볼 수 있다.
바로 이전에 생성된 ALB가 정상적으로 삭제되는 것을 볼 수 있다.
CreateRoute53Record
import boto3
def lambda_handler(event, context):
route53 = boto3.client('route53')
hosted_zone_id = event['hostedZoneId']
domain_name = event['domainName']
alb_dns_name = event['albDNSName']
alb_hosted_zone_id = event['albHostedZoneId']
response = route53.change_resource_record_sets(
HostedZoneId=hosted_zone_id,
ChangeBatch={
'Changes': [{
'Action': 'UPSERT',
'ResourceRecordSet': {
'Name': domain_name,
'Type': 'A',
'AliasTarget': {
'HostedZoneId': alb_hosted_zone_id,
'DNSName': alb_dns_name,
'EvaluateTargetHealth': True
}
}
}]
}
)
event['route53Status'] = 'Record created/updated'
return eventCustom Domain을 연결하기 위해 기존의 ACM을 통해 인증된 인증서를 가진 Route53 호스팅 영역에 ALB를 alias로 가지는 A 레코드를 생성할 수 있는 Lambda 함수를 위와 같이 정의한다.
{
"hostedZoneId": "Z1ABCD...",
"domainName": "www.example.com",
"albDNSName": "my-alb-1234567890.us-west-2.elb.amazonaws.com",
"albHostedZoneId": "Z3AADJ..."
}해당 함수에 필요한 정보들을 테스트 이벤트의 Input JSON에 담아 요청하면
esponse
{
"status": "Route 53 record created/updated"
}
Function Logs
START RequestId: c5deb0f7-89b4-4faa-901f-ce1b22b4f041 Version: $LATEST
END RequestId: c5deb0f7-89b4-4faa-901f-ce1b22b4f041
REPORT RequestId: c5deb0f7-89b4-4faa-901f-ce1b22b4f041 Duration: 1248.97 ms Billed Duration: 1249 ms Memory Size: 128 MB Max Memory Used: 76 MB ALB에 대한 A 레코드가 정상적으로 생성되는 것을 볼 수 있다.
ALB에 대한 A 레코드가 정상적으로 생성되는 것을 볼 수 있다.
DeleteRoute53Record
import boto3
def lambda_handler(event, context):
route53 = boto3.client('route53')
hosted_zone_id = event['hostedZoneId']
domain_name = event['domainName']
alb_dns_name = event['albDNSName']
alb_hosted_zone_id = event['albHostedZoneId']
try:
route53.change_resource_record_sets(
HostedZoneId=hosted_zone_id,
ChangeBatch={
'Changes': [{
'Action': 'DELETE',
'ResourceRecordSet': {
'Name': domain_name,
'Type': 'A',
'AliasTarget': {
'HostedZoneId': alb_hosted_zone_id,
'DNSName': alb_dns_name,
'EvaluateTargetHealth': True
}
}
}]
}
)
return {'status': 'Route 53 record deleted'}
except route53.exceptions.InvalidChangeBatch:
return {'status': 'Route 53 record not found'}또한 위와 같이 A 레코드를 삭제하는 Lambda Function을 구성하고
{
"hostedZoneId": "Z1ABCD...",
"domainName": "www.example.com",
"albDNSName": "my-alb-1234567890.us-west-2.elb.amazonaws.com",
"albHostedZoneId": "Z3AADJ..."
}Response
{
"status": "Route 53 record deleted"
}
Function Logs
START RequestId: 6fa1a88a-1860-4b65-ae30-1b3d4d0373d6 Version: $LATEST
END RequestId: 6fa1a88a-1860-4b65-ae30-1b3d4d0373d6
REPORT RequestId: 6fa1a88a-1860-4b65-ae30-1b3d4d0373d6 Duration: 1276.30 ms Billed Duration: 1277 ms Memory Size: 128 MB Max Memory Used: 76 MBLambda Function이 정상적으로 동작하며, A 레코드가 삭제되는 것을 볼 수 있다.
Step Function Test
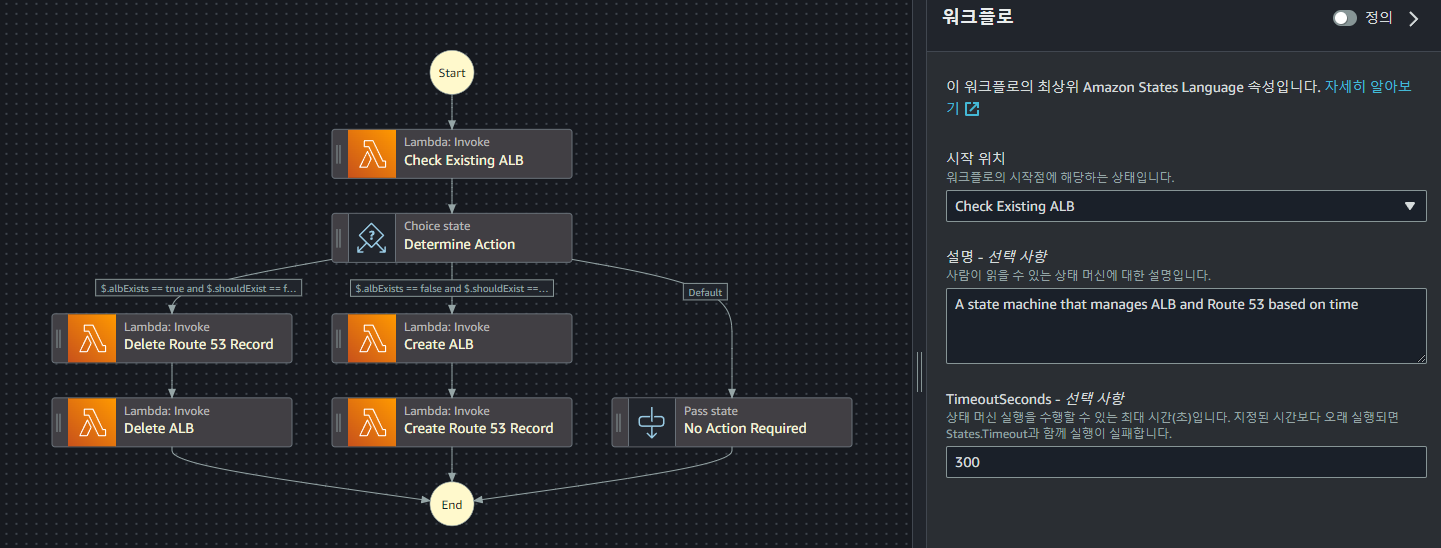 이후 각각의 Lambda Function들을 Step Function에 연결시켜주고 Step Function을 생성한다.
이후 각각의 Lambda Function들을 Step Function에 연결시켜주고 Step Function을 생성한다.
{
"albName": "...",
"startTime": 12,
"endTime": 22,
"subnets": ["subnet-...", "subnet-..."],
"securityGroups": ["sg-..."],
"hostedZoneId": "",
"domainName": "www....",
"targetGroups": [
{
"targetGroupArn": "arn:aws:elasticloadbalancing:ap-northeast-2:013183450059:targetgroup/...",
"listenerProtocol": "HTTP",
"listenerPort": 8080
},
{
"targetGroupArn": "arn:aws:elasticloadbalancing:ap-northeast-2:013183450059:targetgroup/...",
"listenerProtocol": "HTTP",
"listenerPort": 9094
}
],
"certificateArn": "arn:aws:acm:ap-northeast-2:013183450059:certificate/...",
"albArn": "",
"albDNSName": "",
"albHostedZoneId": ""
}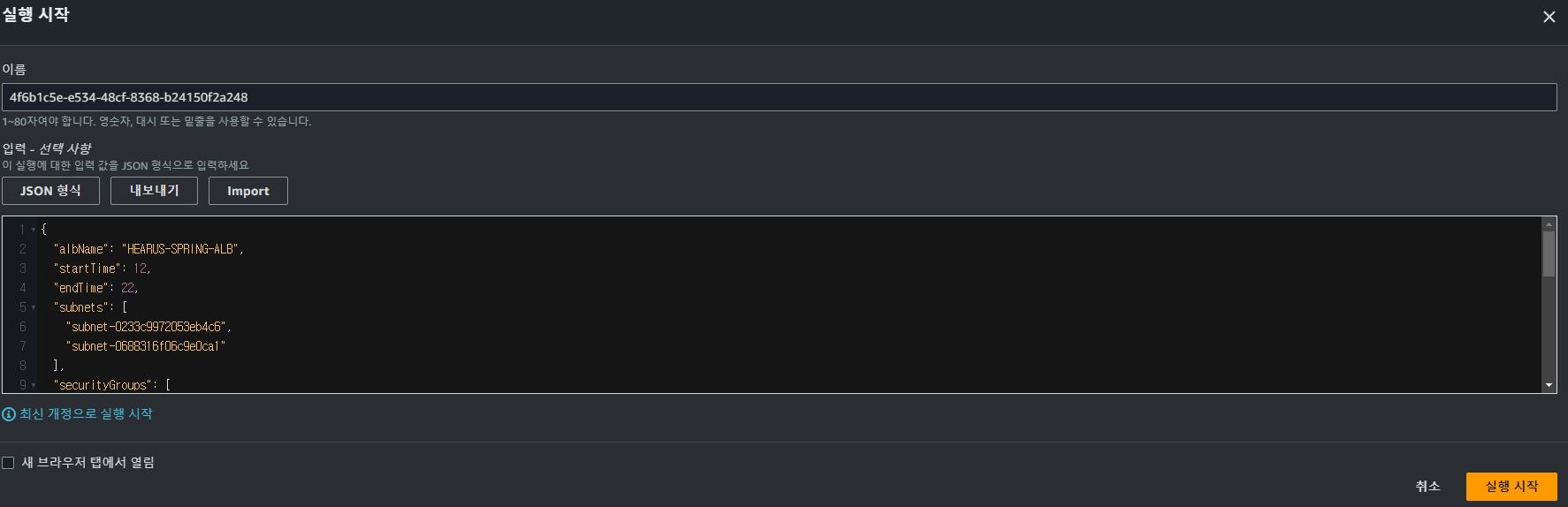 이후 위와 같이 필요한 모든 정보들을 담은 JSON을 Step Function 실행의 Input으로 하여 Step Function을 실행시키면
이후 위와 같이 필요한 모든 정보들을 담은 JSON을 Step Function 실행의 Input으로 하여 Step Function을 실행시키면
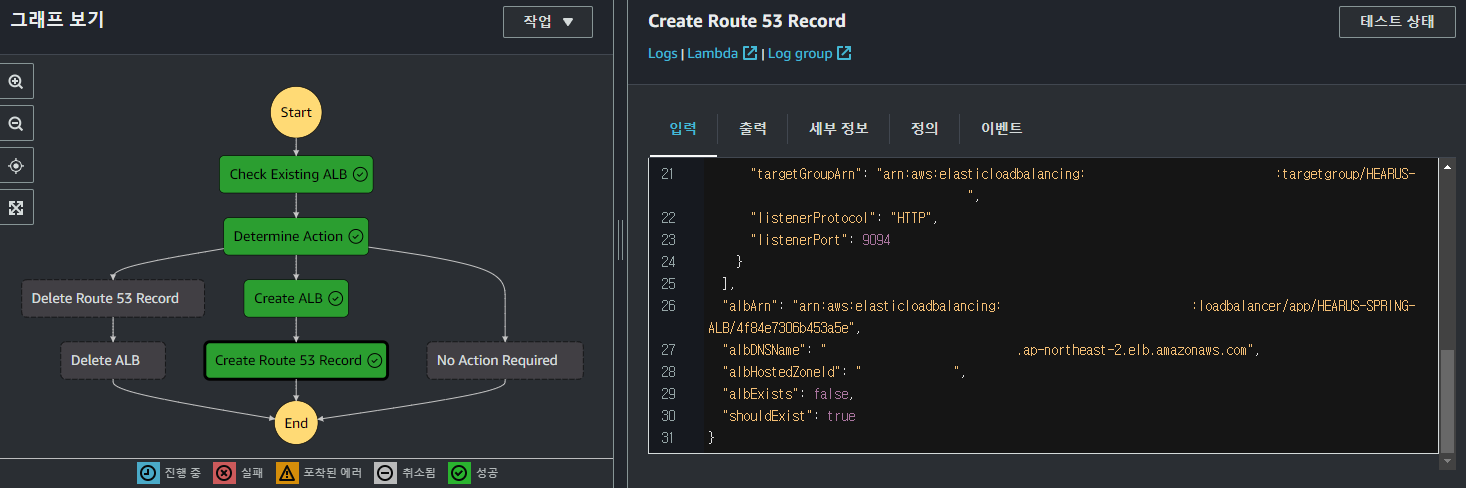 위와 같이 정상적으로 Step Function이 실행되는 것을 볼 수 있으며
위와 같이 정상적으로 Step Function이 실행되는 것을 볼 수 있으며
 Custom Domain을 통해 Spring BE 서버에 접근이 가능한 것을 볼 수 있다.
Custom Domain을 통해 Spring BE 서버에 접근이 가능한 것을 볼 수 있다.
CloudWatch EventBridge
 이러한 작업을 자동적으로 수행하기 위해
이러한 작업을 자동적으로 수행하기 위해 EventBridge의 일정을 생성해준다
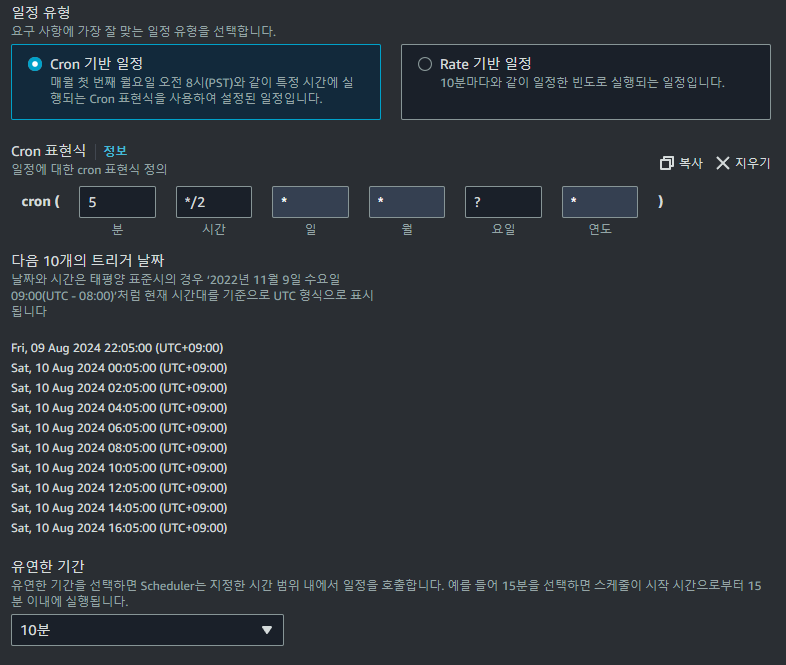 이후 위와 같이 Cron 기반 일정으로 설정하여주고
이후 위와 같이 Cron 기반 일정으로 설정하여주고
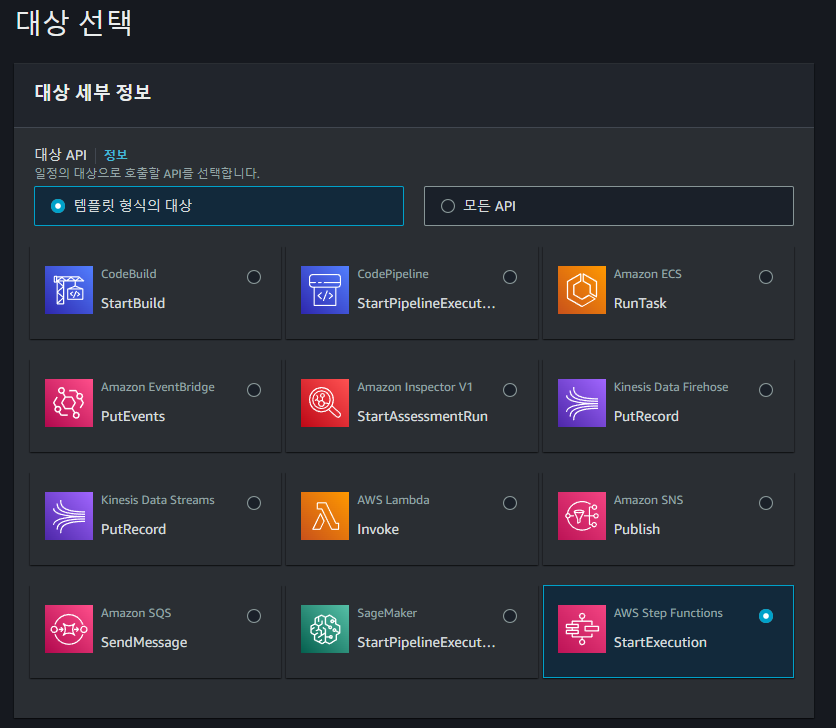 Step Function을 대상으로 선택하면
Step Function을 대상으로 선택하면
 2시간에 한번씩 ALB에 대한 Step Function을 실행시킬 수 있다.
2시간에 한번씩 ALB에 대한 Step Function을 실행시킬 수 있다.
TroubleShooting
{
"albName": "...",
"startTime": 12,
"endTime": 13,
...삭제를 테스트해보기 위하여 위와 같이 시간을 설정하고 Step Function을 실행시켰을 때
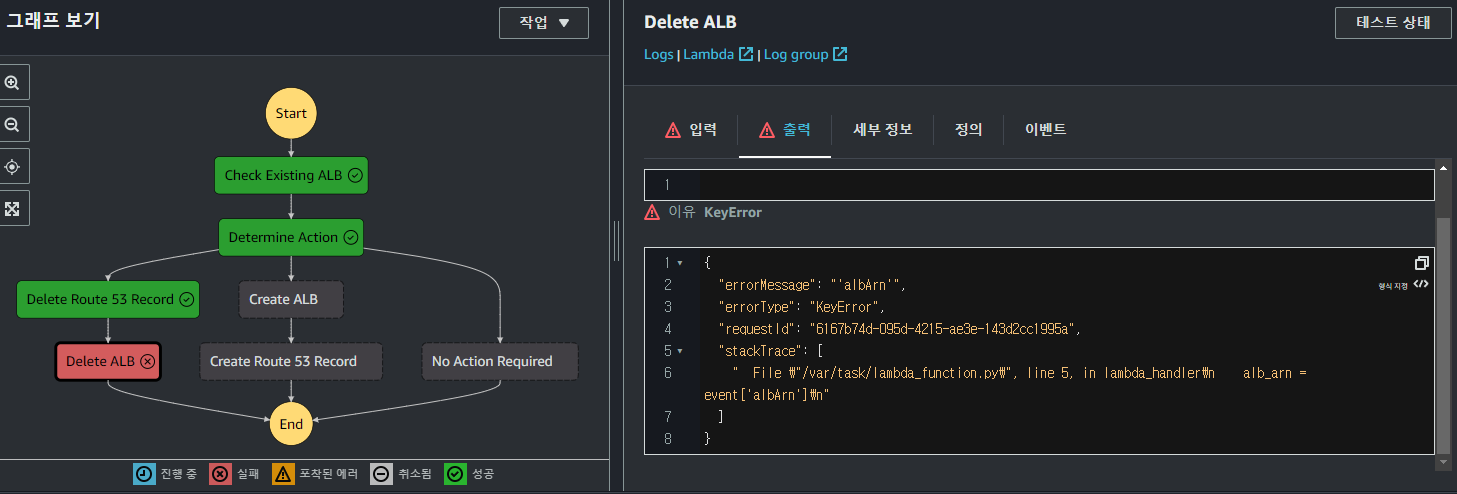 ALB를 삭제하는 과정에서 오류가 발생하였다.
ALB를 삭제하는 과정에서 오류가 발생하였다.
import boto3
def lambda_handler(event, context):
route53 = boto3.client('route53')
hosted_zone_id = event['hostedZoneId']
domain_name = event['domainName']
alb_dns_name = event['albDNSName']
alb_hosted_zone_id = event['albHostedZoneId']
try:
route53.change_resource_record_sets(
HostedZoneId=hosted_zone_id,
ChangeBatch={
'Changes': [{
'Action': 'DELETE',
'ResourceRecordSet': {
'Name': domain_name,
'Type': 'A',
'AliasTarget': {
'HostedZoneId': alb_hosted_zone_id,
'DNSName': alb_dns_name,
'EvaluateTargetHealth': True
}
}
}]
}
)
# event를 update한 이후 return
event['route53Status'] = 'Deletion initiated'
return event
except route53.exceptions.InvalidChangeBatch:
event['route53Status'] = 'Route 53 record not found'
return event이는 이전 Step의 Lambda Function에서 event를 갱신하지 않아 발생한 문제로, event를 update한 이후 return해줄 수 있도록 Lambda Function을 변경하였다.
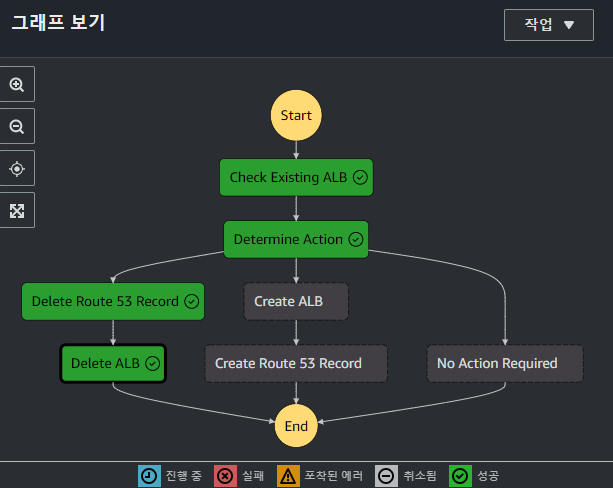 삭제 기능까지 정상적으로 동작하는 것을 확인하였고
삭제 기능까지 정상적으로 동작하는 것을 확인하였고
 자동화를 굉장히 좋아하기에 팀 Slack 채널에 이를 전달하였다.
자동화를 굉장히 좋아하기에 팀 Slack 채널에 이를 전달하였다.
STT Result Restructure
 Whisper의 한국어 STT에 대한 낮은 신뢰성과 하이라이팅 기능 추가를 위해 위와 같이 저장된 STT 결과에 기반하여 변환된 강의 스크립트를 문단 형태로 나누고, 중요한 단어를 하이라이팅해줄 수 있도록 Workflow를 작성하였다.
Whisper의 한국어 STT에 대한 낮은 신뢰성과 하이라이팅 기능 추가를 위해 위와 같이 저장된 STT 결과에 기반하여 변환된 강의 스크립트를 문단 형태로 나누고, 중요한 단어를 하이라이팅해줄 수 있도록 Workflow를 작성하였다.
parse_JSON()
def parse_JSON(text, is_array=False):
def extract_json_objects(text):
json_objects = []
brace_count = 0
start_index = None
for i, char in enumerate(text):
if char == '{':
if brace_count == 0:
start_index = i
brace_count += 1
elif char == '}':
brace_count -= 1
if brace_count == 0 and start_index is not None:
json_objects.append(text[start_index:i+1])
start_index = None
return json_objects
result = []
json_objects = extract_json_objects(text)
for json_str in json_objects:
try:
# 줄바꿈과 공백 처리
json_str = re.sub(r'\s+', ' ', json_str)
parsed_json = json.loads(json_str)
print(parsed_json)
if is_array is False:
return parsed_json
result.append(parsed_json)
except json.JSONDecodeError as e:
print(f"[LangChain]-[parse_JSON] Error parsing JSON: {str(e)}")
print(f"[LangChain]-[parse_JSON] Problematic JSON string: {json_str}")
if not result:
print("[LangChain]-[parse_JSON] No valid JSON data found in the input text")
return None
return resultLLM 결과에서 JSON을 성공적으로 parsing하지 못했을 경우를 대비하여 parse_JSON 매소드를 위와 같이 수정하였다.
STT Result Restructure, Highlight
FastAPI
main.py
class scriptReq(BaseModel):
processedScript: List[str]
@app.post("/restructure_script")
async def restructure_script(script_Req : scriptReq):
print("[main]-[restructure_script] API Call")
restructure_result = await asyncio.create_task(langchain.restructure_script(
script_Req.processedScript
))
return restructure_result이후 /restructure_script라는 새로운 POST API를 생성하고
langchain.py
######## Restructure LangChain ########
async def restructure_script(script):
print("\n[LangChain]-[restructure_script] script :", script, "\n")
prompt = ChatPromptTemplate.from_template("""
당신은 대한민국 대학교 교수입니다.
{script}
위 스크립트는 대한민국의 대학교 수준의 강의 내용인데
해당 스크립트를 문단별로 묶고, 중요한 핵심 단어나 문장을 표시하고자 합니다.
[
"문장1",
"문장2",
...
]
현재 주어지는 스크립트는 위와 같은 구조로 구성되어 있을 것입니다.
{{
processedScript : [
"문단1",
"문단2",
...
"마지막 문단"
]
}}
관련있는 문장들을 하나의 문단으로 묶어서 processedScript List의 하나의 String 내에 넣어주세요
배역의 각 문단이 끝나고 시작하는 " 사이에는 반드시 ,를 넣어주세요
결과는 위 형태에 반드시 맞추어 processedScript를 Key로 가지는 JSON 데이터를 제공해주세요
이때 아래의 조건을 지키면서 새로운 processedScript를 생성해주세요
1. 문법적으로 올바르지 않은 내용이 있다면 그것만 수정해주세요
2. 중요한 단어 양 옆에 **단어** 과 같이 "**"를 붙여주세요
3. 이상한 단어들이 들어가지 않게 꼼꼼하고 정확하게 생성해주세요
한국어로 답변해주세요
""")
chain = (
prompt
| llm
| StrOutputParser()
)
problem_result = await asyncio.to_thread(
chain.invoke, {
"script" : script
})
print("[LangChain]-[restructure_script] Model Result \n", problem_result)
json_result = parse_JSON(problem_result, True)
if not json_result:
return None
return json_result[0]restructure_script LangChain 메소드를 생성해주었다.
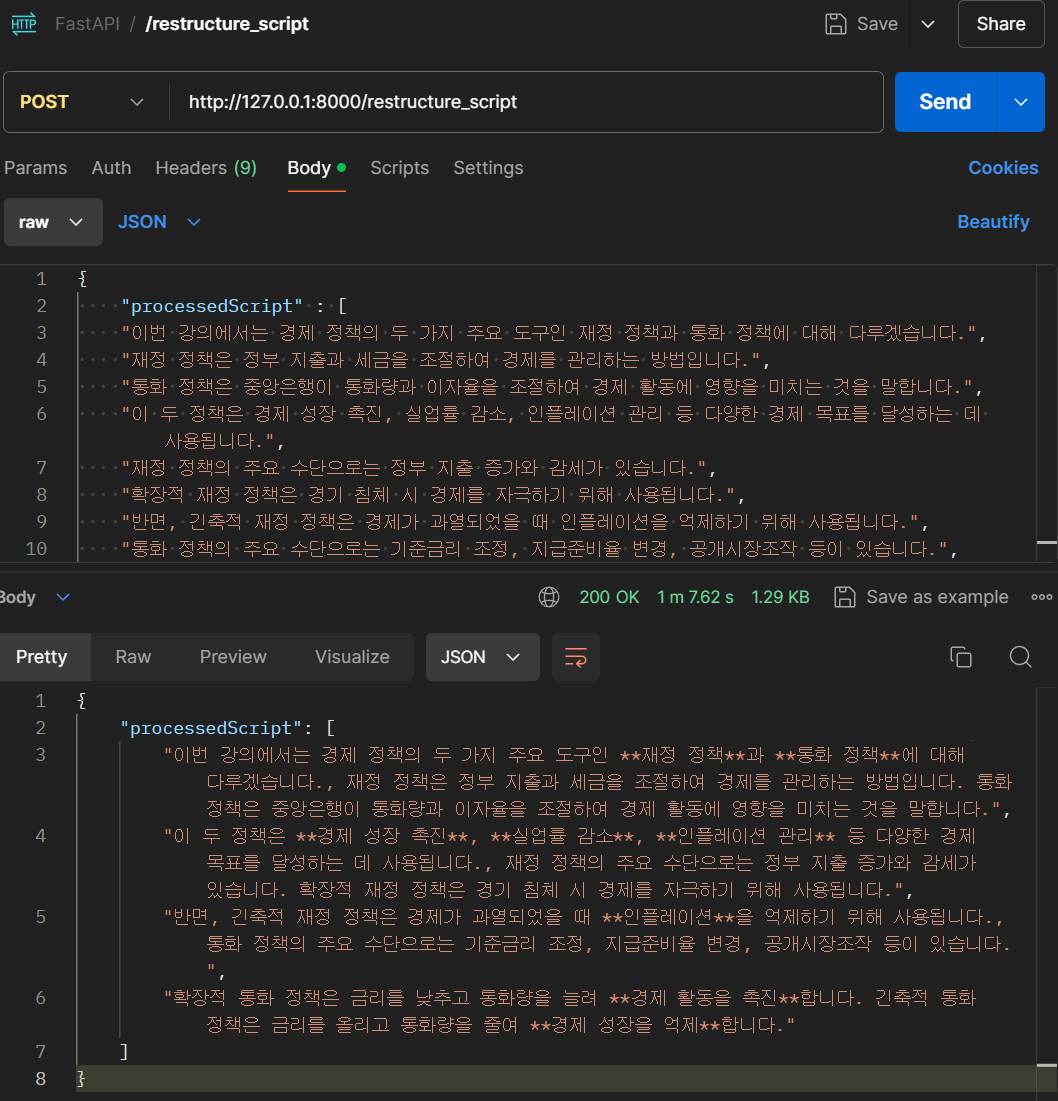 위와 같은 processedScript에 대한 요청을 하면 문단이 나뉘어지고 중요한 단어를
위와 같은 processedScript에 대한 요청을 하면 문단이 나뉘어지고 중요한 단어를 **단어** 형태로 묶어서 반환해주는 것을 볼 수 있다.
 또한 해당 내용을 FE, 디자인 팀원분들께 전달하여 FE에서도 기능이 개발될 수 있게 하였다.
또한 해당 내용을 FE, 디자인 팀원분들께 전달하여 FE에서도 기능이 개발될 수 있게 하였다.
Spring Boot
LectureController.java
public class LectureController {
// Request를 Slice하여 Restructure요청할 때의 SIZE
private final int SLICE_SIZE = 6;
...
@GetMapping("/restructureScript")
public DeferredResult<ResponseEntity<CommonResponse>> restructureScript(@RequestParam("lectureId") String lectureId) {
log.info("[LectureController]-[restructureScript] API Call");
String fastAPIEndpoint = configUtil.getProperty("FAST_API_ENDPOINT");
// Timeout 시간을 5분으로 설정
long timeoutInMillis = 5 * 60 * 1000;
DeferredResult<ResponseEntity<CommonResponse>> deferredResult = new DeferredResult<>(timeoutInMillis);
CompletableFuture.runAsync(() -> {
try{
// LectureId로 Model을 가져와 processedScript에 저장
LectureModel lectureModel = (LectureModel) lectureService.getLecture(lectureId, false).getObject();
List<String> processedScript = lectureModel.getProcessedScript();
List<String> newProcessedScript = new ArrayList<>();
int start = 0, end;
int requestLen = processedScript.size() / SLICE_SIZE;
if(processedScript.size() % SLICE_SIZE != 0)
requestLen++;
for(int i = 0;i < requestLen;i++) {
end = start + SLICE_SIZE;
if(end > processedScript.size())
end = processedScript.size();
log.info("[LectureController]-[restructureScript] restructuring script {} ~ {}", start, end);
Map<String, List<String>> requestMap = new HashMap<>();
requestMap.put("processedScript", new ArrayList<>(processedScript.subList(start, end)));
String jsonBody = new ObjectMapper().writeValueAsString(requestMap);
// FastAPI 비동기 요청 보내기
RestTemplate restTemplate = new RestTemplate();
// UTF-8 인코딩을 사용하는 StringHttpMessageConverter 설정
StringHttpMessageConverter converter = new StringHttpMessageConverter(StandardCharsets.UTF_8);
converter.setWriteAcceptCharset(false);
restTemplate.getMessageConverters().add(0, converter);
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
HttpEntity<String> entity = new HttpEntity<>(jsonBody, headers);
ResponseEntity<String> result = restTemplate.postForEntity(
fastAPIEndpoint + "/restructure_script",
entity,
String.class
);
if (result.getStatusCode() == HttpStatus.OK) {
// JSON 문자열을 Map으로 파싱
ObjectMapper objectMapper = new ObjectMapper();
Map<String, List<String>> responseMap = objectMapper.readValue(result.getBody(), new TypeReference<Map<String, List<String>>>() {});
if (responseMap != null && responseMap.containsKey("processedScript")) {
// processedScript 키에 해당하는 리스트 추출
newProcessedScript.addAll(responseMap.get("processedScript"));
log.info("[LectureController]-[restructureScript] processedScript updated successfully");
start = end;
} else {
log.error("[LectureController]-[restructureScript] 'processedScript' key not found in the response");
i--;
}
} else
log.error("[LectureController]-[restructureScript] restructure script failed {} ~ {}", start, end);
}
lectureModel.setProcessedScript(newProcessedScript);
response = lectureService.updateLecture(lectureModel);
} catch (Exception e) {
log.error("[LectureController]-[restructureScript] {}", e.getStackTrace());
response = new CommonResponse(false, HttpStatus.INTERNAL_SERVER_ERROR, "Restructure Script Failed with Internal Server Error");
} finally {
log.info("[LectureController]-[restructureScript] {}", response.getMsg());
deferredResult.setResult(ResponseEntity.status(response.getStatus()).body(response));
}
});
return deferredResult;
}
...Spring에서도 /restructureScript API를 새롭게 생성하고
LLM 정확도를 높이기 위하여 SLICE_SIZE만큼 processedScript 데이터를 잘라서 요청을 보내고 FastAPI parseJSON의 오류에 대응하기 위해 자동으로 같은 단위의 스크립트에 대해 재요청을 시도할 수 있도록 메소드를 구성하였다.
 위와 같이 MongoDB에 저장되어 있는 데이터에 대해 API를 호출하면
위와 같이 MongoDB에 저장되어 있는 데이터에 대해 API를 호출하면
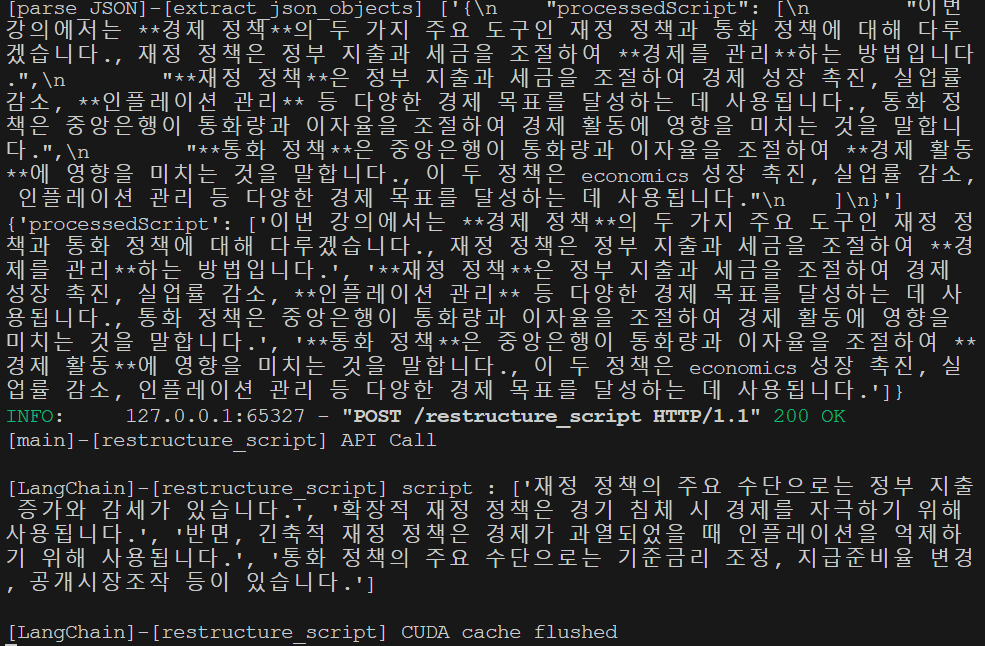
 FastAPI, Spring에서도 로그를 잘 띄우는 것을 볼 수 있으며
FastAPI, Spring에서도 로그를 잘 띄우는 것을 볼 수 있으며 ERROR 상황에서 자동으로 재시도 하는 것을 볼 수 있다.
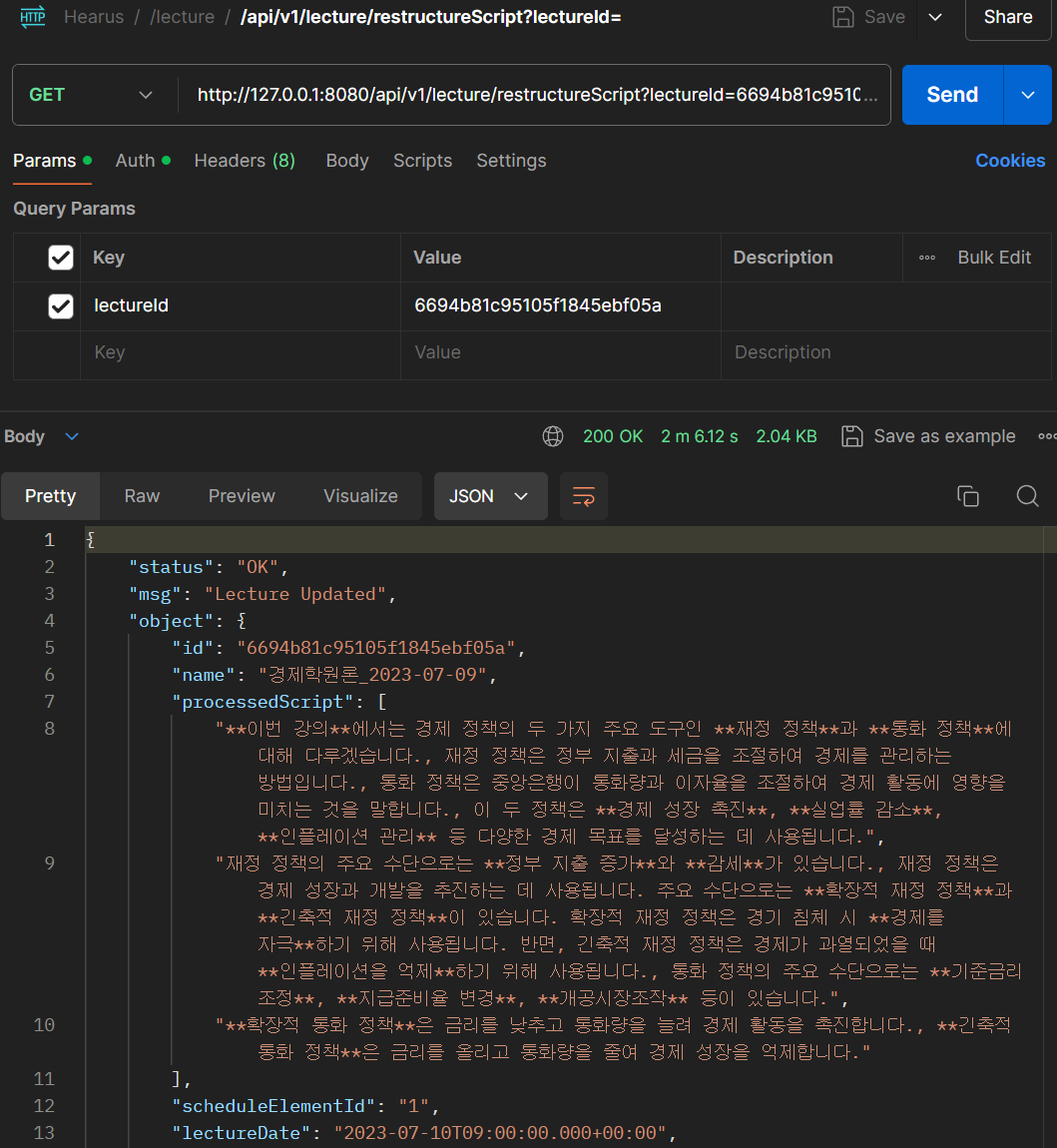
 또한 성공적으로 반환된 데이터가 MongoDB에 잘 반영되는 것을 볼 수 있다.
또한 성공적으로 반환된 데이터가 MongoDB에 잘 반영되는 것을 볼 수 있다.
TroubleShooting : '.,' pattern
 하지만 LLM에서 문장을 요약할 떄
하지만 LLM에서 문장을 요약할 떄 .,와 같이 하나의 문장이 종료되고도 ,를 함께 출력하는 것을 볼 수 있었다
if (responseMap != null && responseMap.containsKey("processedScript")) {
// ., 패턴을 .로 replace
List<String> responseScript = responseMap.get("processedScript");
responseScript.replaceAll(s -> s.replaceAll("\\.,", "."));
// processedScript 키에 해당하는 리스트 추출
newProcessedScript.addAll(responseScript);
log.info("[LectureController]-[restructureScript] processedScript updated successfully");
start = end;
} else {
log.error("[LectureController]-[restructureScript] 'processedScript' key not found in the response");
i--;
}이를 replaceAll를 통해 간단하게 패턴을 대체하는 방식으로 해결하였고
 추후 정상적으로 API 요청 이후 데이터가 저장되는 모습을 볼 수 있었다.
추후 정상적으로 API 요청 이후 데이터가 저장되는 모습을 볼 수 있었다.
Real-Time STT Test
 서비스 MVP 개발이 거의 완료됨에 따라 현재까지 개발된 내용들을 모두 합쳐보고, 예기치 못한 버그를 해결하기 위해 모각코 일정을 확정하였다.
서비스 MVP 개발이 거의 완료됨에 따라 현재까지 개발된 내용들을 모두 합쳐보고, 예기치 못한 버그를 해결하기 위해 모각코 일정을 확정하였다.
Spring <> FastAPI
Trouble Shooting
 모각코 일정 당일 위와 같이 Custom Domain을 통해 WebSocker이 연결되지 않는 문제가 발생하였다.
모각코 일정 당일 위와 같이 Custom Domain을 통해 WebSocker이 연결되지 않는 문제가 발생하였다.
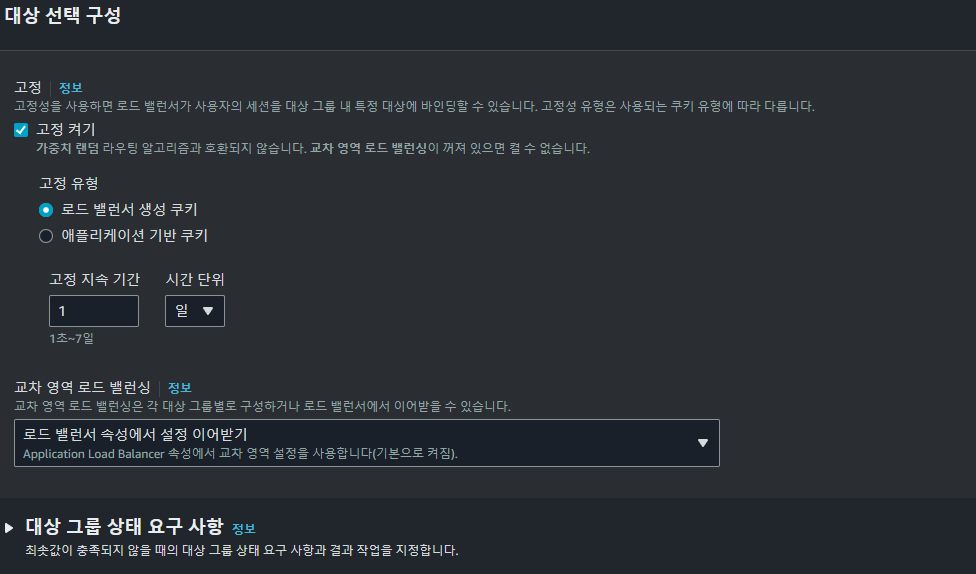
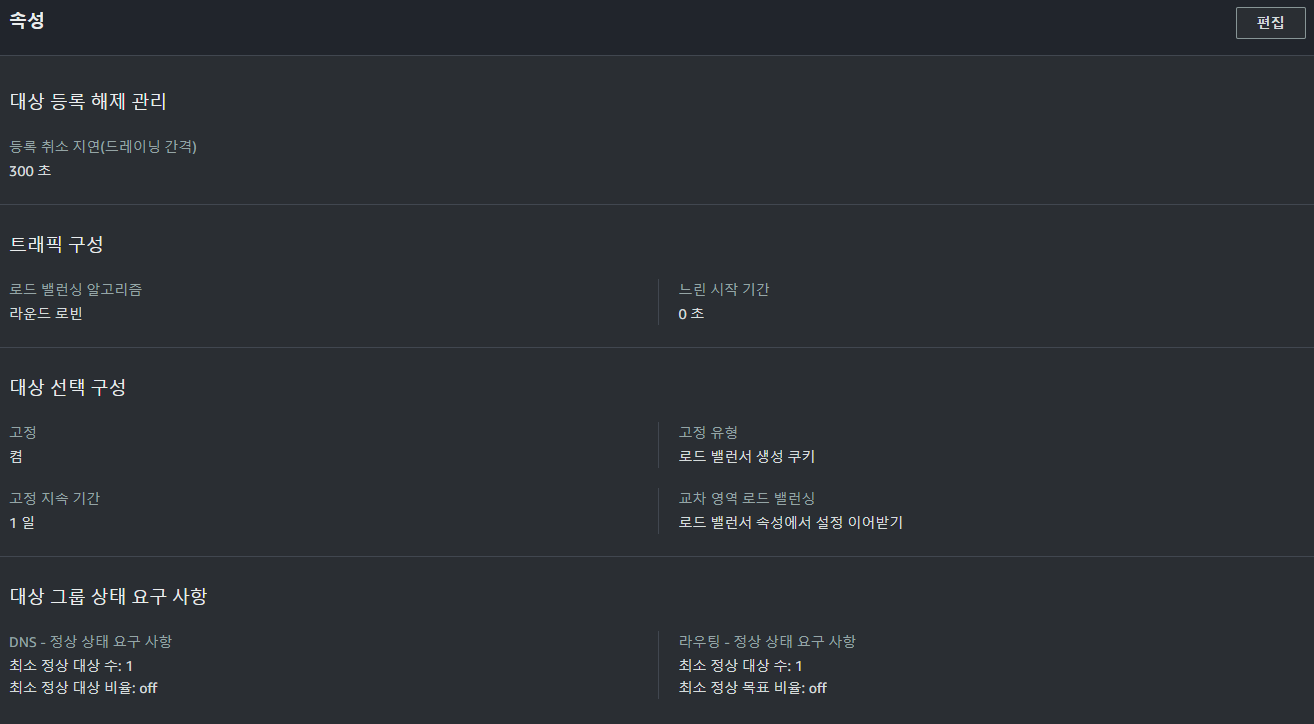 이를 해결하기 대상 그룹의 대상 선택 구성에서 로드 밸런서 생성 쿠키를 통해 연결을 고정하는 설정을 활성화하고
이를 해결하기 대상 그룹의 대상 선택 구성에서 로드 밸런서 생성 쿠키를 통해 연결을 고정하는 설정을 활성화하고
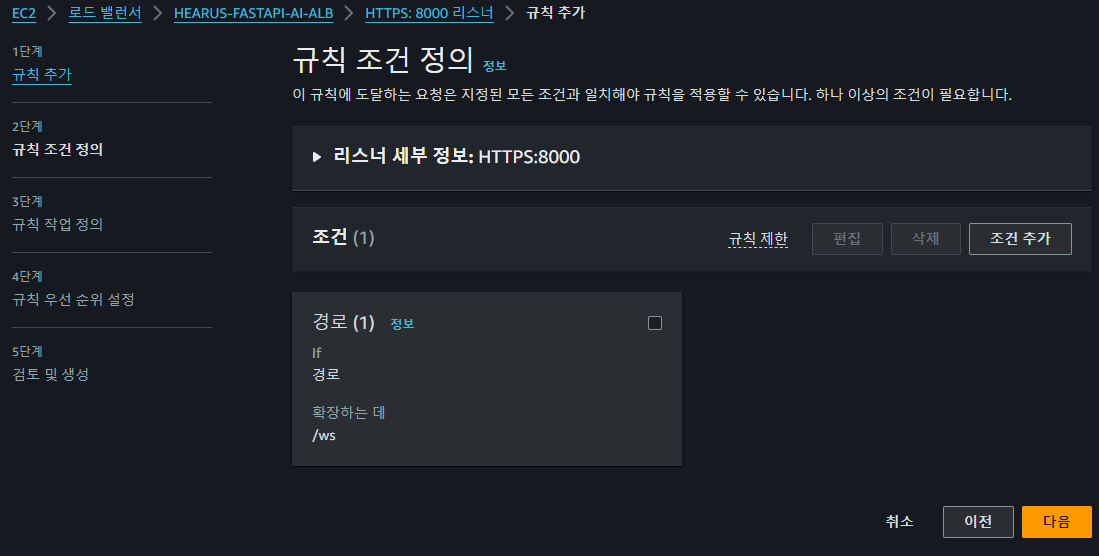 FastAPI의 로드 밸런서에 대한
FastAPI의 로드 밸런서에 대한 /ws path에 대한 새로운 규칙 조건을 정의하였다.
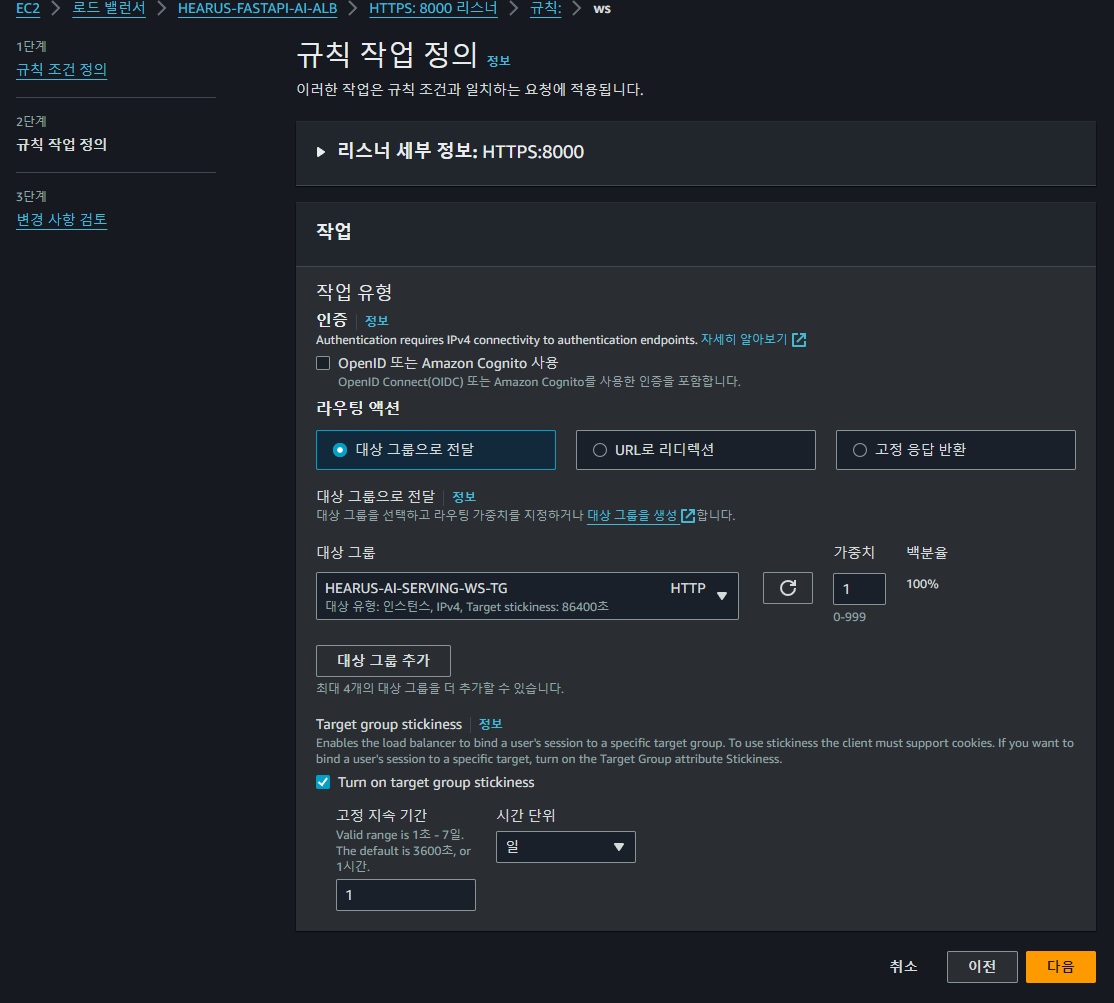 이후
이후 /ws path로의 요청을 대상 그룹으로 전달하도록 설정하고 Target Group Stickness 옵션을 활성화해주었다.
 이에 대해 위와 같이 ALB의 네트워크 맵의 연결이 정상적으로 구성되는 것을 볼 수 있었고
이에 대해 위와 같이 ALB의 네트워크 맵의 연결이 정상적으로 구성되는 것을 볼 수 있었고
# FastAPI
FAST_API_ENDPOINT=https://www.mayday-spring.store:8000
FAST_API_WS_ENDPOINT=wss://www.mayday-spring.store:8000Spring BE에서 FAST_API_WS_ENDPOINT를 새롭게 정의해준 다음
...
private void connectFastAPI(Timer timer, SocketIOClient client){
timer.scheduleAtFixedRate(new TimerTask() {
@Override
public void run() {
URI fastAPIWSURI = null;
try {
fastAPIWSURI = new URI(FastAPIEndpoint + "/ws");
if(fastAPIWebSocket == null || fastAPIWebSocket.isClosed()) {
fastAPIWebSocket = new WebSocketUtil(
lectureDAO,
fastAPIWSURI,
new Draft_6455(),
client,
lectureId
);
fastAPIWebSocket.connectBlocking();
fastAPIWebSocket.send(String.valueOf(UUID.randomUUID()));
}
} catch (InterruptedException e) {
log.error("[WebRTCProxy]-[connectFastAPI] WebSocket connection interrupted: ", e);
}
catch (Exception e) {
log.error("[WebRTCProxy]-[connectFastAPI] WebSocket connection failed: ", e);
log.info("[WebRTCProxy]-[connectFastAPI] {}", fastAPIWSURI);
}
}
}, 0, 60);
}기존의 WebSocket 연결 코드를 통해 연결을 수행하면
 Spring과 FastAPI 사이의 WebSocker 연결이 정상적으로 이루어지는 것을 볼 수 있었다.
Spring과 FastAPI 사이의 WebSocker 연결이 정상적으로 이루어지는 것을 볼 수 있었다.
React <> Spring
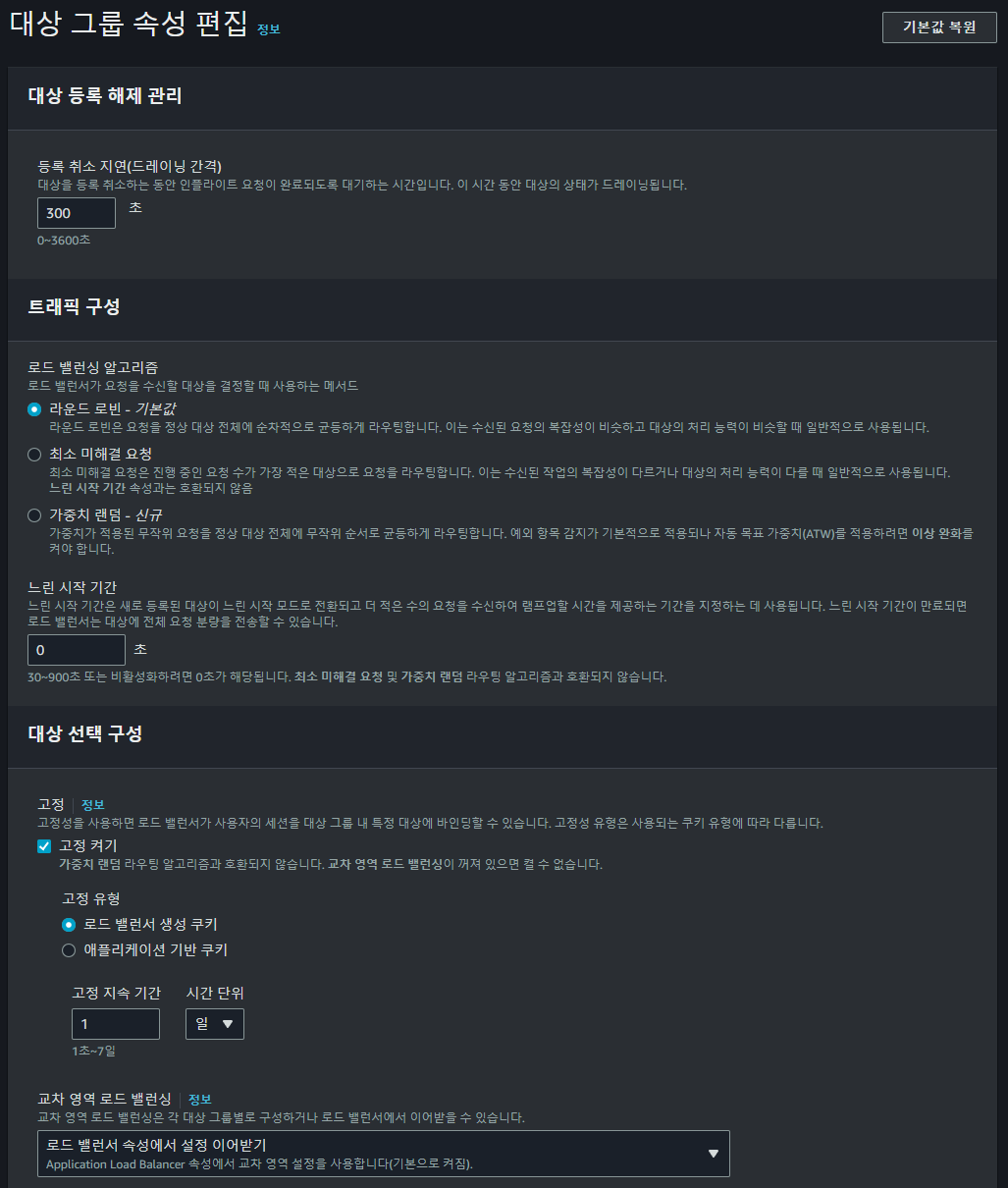 또한 Spring ALB의 대상 그룹을 새롭게 생성하여 고정 옵션을 추가하고
또한 Spring ALB의 대상 그룹을 새롭게 생성하여 고정 옵션을 추가하고
 9094 포트로 socketio 연결을 수행하기 때문에
9094 포트로 socketio 연결을 수행하기 때문에 /socketio path에 대한 규칙을 설정한다
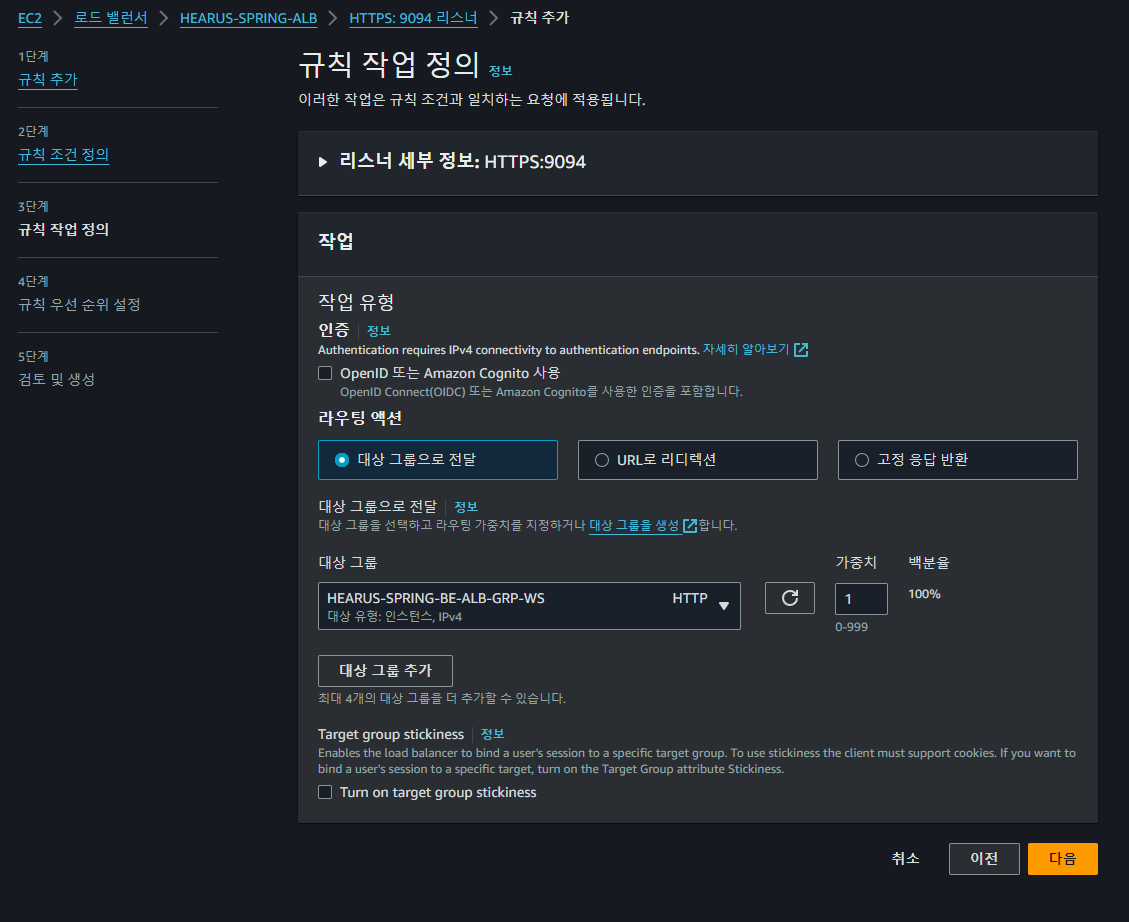
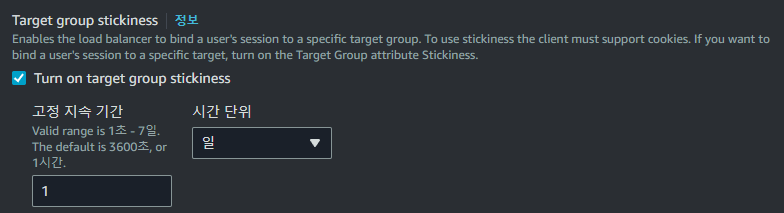 또한 이전과 동일하게 Stickness 옵션을 켜주게 되면 React와 Spring 사이의 Socketio 연결 또한 정상적으로 이루어지는 것을 볼 수 있었다.
또한 이전과 동일하게 Stickness 옵션을 켜주게 되면 React와 Spring 사이의 Socketio 연결 또한 정상적으로 이루어지는 것을 볼 수 있었다.
TroubleShooting : "this.ffmpegConfig" is null
[WebRTCProxy]-[Socketio] Exception
java.lang.NullPointerException: Cannot invoke "com.hearus.hearusspring.common.ffmpeg.FFmpegConfig.getFFmpegPath()" because "this.ffmpegConfig" is null실제 음성인식 테스트를 수행했을 때 Spring BE에서 위와 같은 오류가 발생하여
# Private Profile Include
spring.profiles.include=private
spring.profiles.active=productionapplication.properties에 spring.profiles.active=production값을 추가하고
@Slf4j
@Component
public class FFmpegConfig {
@Value("${spring.profiles.active:}")
private String activeProfile;
public String getFFmpegPath() {
log.info("[FFmpegConfig]-[getFFmpegPath] {}", activeProfile);
if ("production".equals(activeProfile)) {
// Docker 환경에서는 시스템 경로의 FFmpeg 사용
return "ffmpeg";
} else {
// 로컬 개발 환경에서는 프로젝트에 포함된 FFmpeg 사용
return "src/main/resources/ffmpeg/bin/ffmpeg";
}
}
}FFmpegConfig 를 위와 같이 정의하여
 모각코 당일 음성인식이 정상적으로 수행되고 LangChain 또한 작동하는 것을 확인하였다.
모각코 당일 음성인식이 정상적으로 수행되고 LangChain 또한 작동하는 것을 확인하였다.
TroubleShooting : ffmpeg returned non-zero exit status
java.lang.RuntimeException: java.io.IOException: ffmpeg returned non-zero exit status. Check stdout.하지만 테스트를 진행하며 위와 같은 오류가 발생하여
$ free -h
total used free shared buff/cache available
Mem: 957Mi 664Mi 89Mi 984Ki 356Mi 293Mi
$ nproc
1Spring BE 서버가 구동되고 있는 EC2 인스턴스의 CPU와 메모리 정보를 확인하고
sudo docker run -p 8080:8080 -p 9094:9094 --user 1000:1000 --cpus=0.9 --memory=900m --name hearus-spring -d judemin/...위와 같이 컨테이너를 구동할 때 --user, --cpus, --memory root 권한과 CPU, 메모리를 지정해주었다.
...
// Create a temporary file to store the converted audio data
File tempOutputFile = File.createTempFile("temp_audio_output", ".raw");
tempOutputFile.deleteOnExit();
// Set read and write permissions for owner, group, and others
Files.setPosixFilePermissions(tempOutputFile.toPath(),
PosixFilePermissions.fromString("rw-rw-rw-"));
// Use FFmpeg to convert the audio data
FFmpeg ffmpeg = new FFmpeg("ffmpeg");
FFmpegBuilder builder = new FFmpegBuilder()
.setInput(tempInputFile.getAbsolutePath())
.overrideOutputFiles(true)
.addOutput(tempOutputFile.getAbsolutePath())
.setAudioCodec("pcm_s16le")
.setAudioChannels(1)
.setAudioSampleRate(16000)
.setFormat("s16le")
.addExtraArgs("-loglevel", "quiet")
.done();또한 혹시나 모를 Ffmpeg 임시 파일의 권한 오류를 방지하기 위해 PosixFilePermissions를 통해 생성된 임시 파일에 대한 읽기/쓰기 권한을 모두 허용해주었다.
