
Architecture
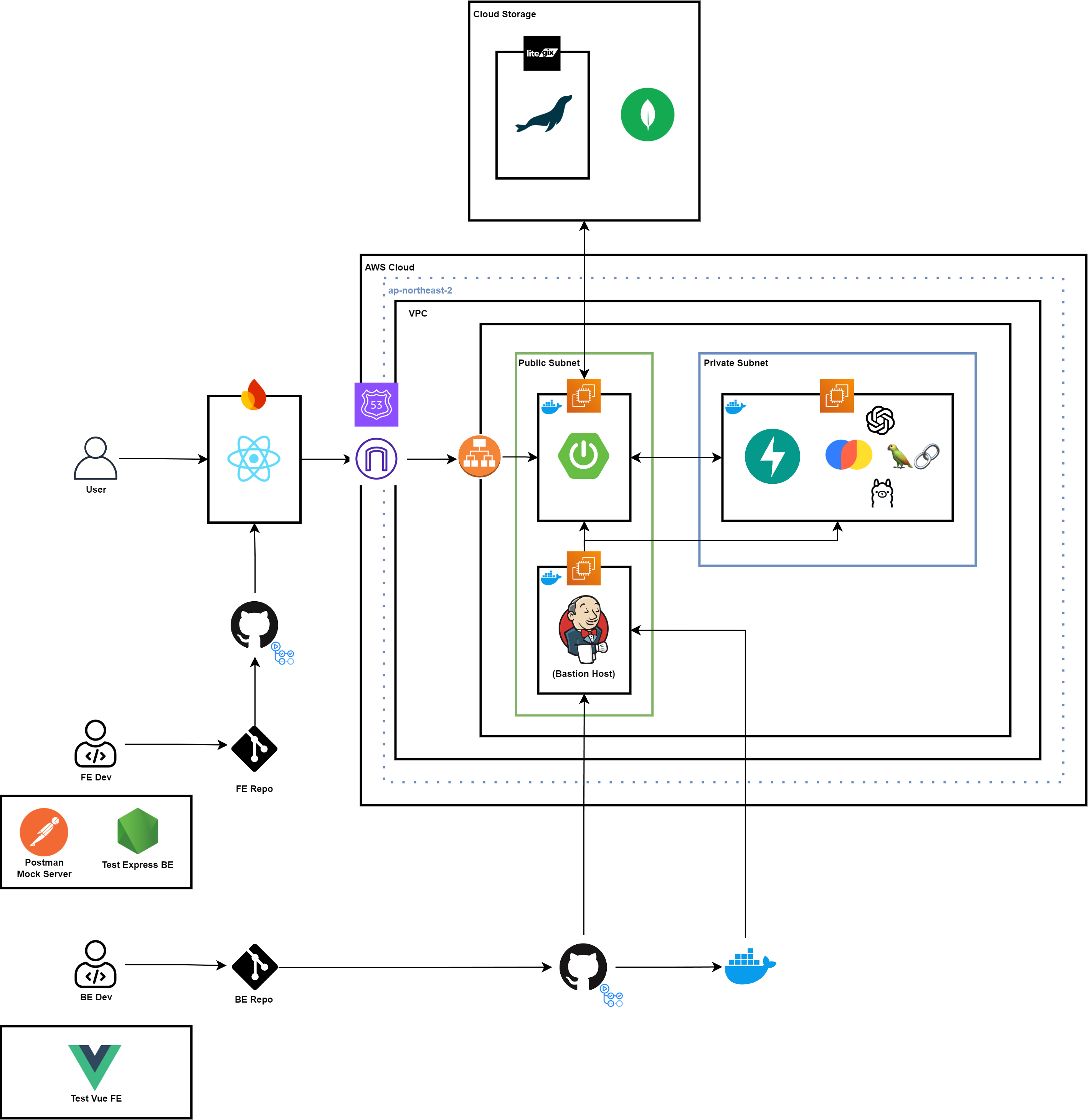
이전에 설계했던 내용과는 차별적이게, 기존 Private Subnet에 있었던 Jenkins 인스턴스를 Bastion Host의 역할을 할 수 있게 하고 Web 환경을 통해 DevOps가 접근할 수 있도록 Public Subnet에 존재하도록 하였다.
SPRINT5 주중 회의
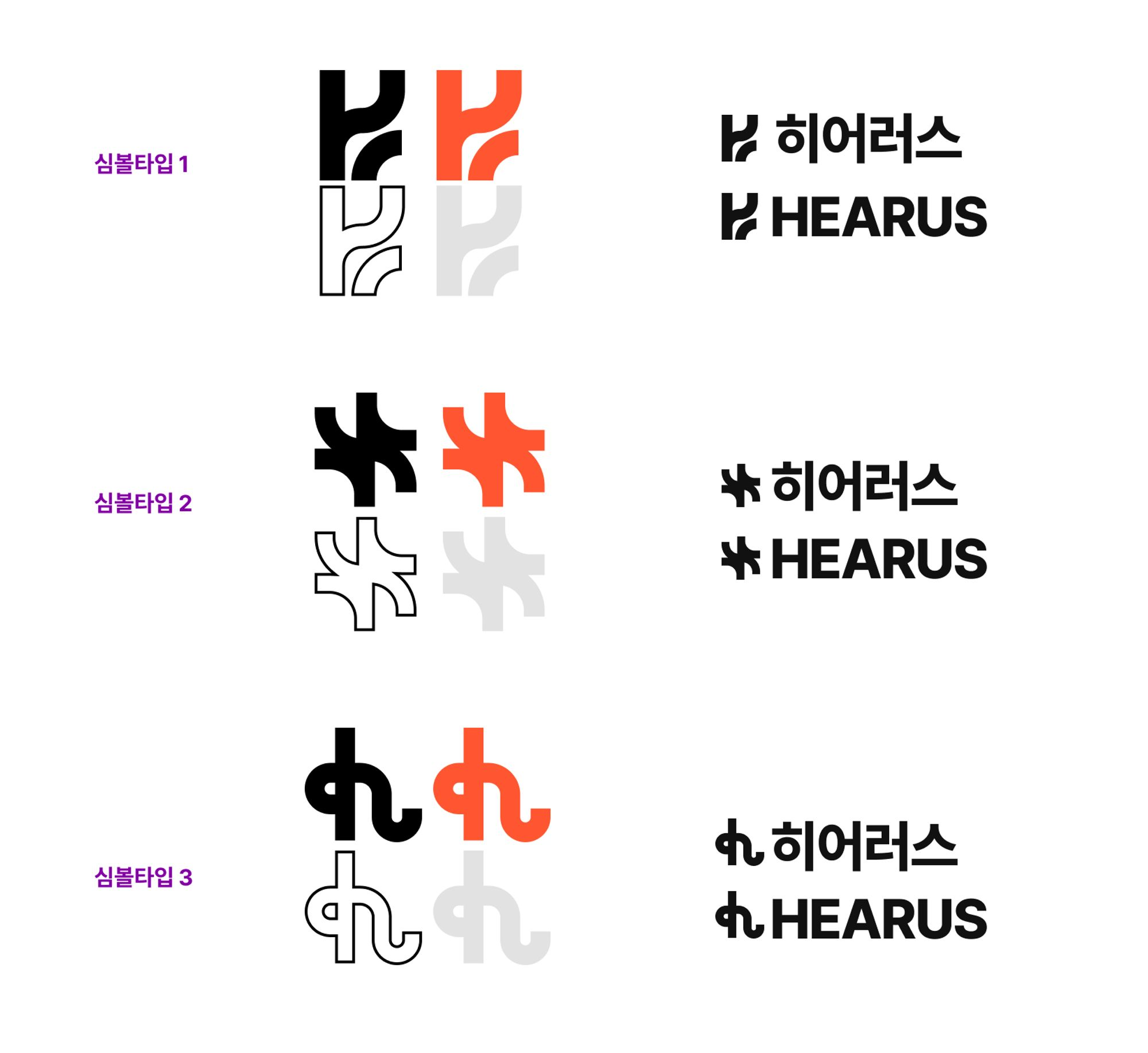 이후 브랜딩을 위하여 같은 팀 디자이너분께 로고 디자인의 요청드렸다.
이후 브랜딩을 위하여 같은 팀 디자이너분께 로고 디자인의 요청드렸다.
총 3개의 로고 디자인 시안이 나오게 되었고 각 로고에 대한 설명은 아래와 같다.
- H와 S의 형태 일부, 곡선과 직선을 살린 디자인, 변형된 부분의 모티브는 날개
(청각장애 학우들을 위한Hero느낌) - 1번과 비슷하지만 좀더 곡선적이고 경쾌한 느낌의 로고
- 이전에 임시로 만들었던 디자인, 이니셜 h와 마이크 아이콘을 모티브로 한 로고
최종적으로 주중 회의에서 각 팀원분들의 의견을 종합한 결과 1번 로고를 최종적으로 선청하였고
 다가오는 8월 KU 창업클럽의 명함 제작 및 네트워킹을 지원하는 KUNNECT 데이에 활용할 명함 디자인 또한 추가적으로 디자인할 계획이다.
다가오는 8월 KU 창업클럽의 명함 제작 및 네트워킹을 지원하는 KUNNECT 데이에 활용할 명함 디자인 또한 추가적으로 디자인할 계획이다.
Spring Public Domain
HomeController.java
package com.hearus.hearusspring.controller;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
@Controller
public class HomeController {
@GetMapping("/")
public String home() {
return "home";
}
}home.html
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<title>HEARUS-SPRING-BE</title>
<style>
body, html {
height: 100%;
margin: 0;
display: flex;
justify-content: center;
align-items: center;
font-family: Arial, sans-serif;
}
.container {
text-align: center;
}
.logo {
width: 200px;
height: 200px;
}
h1 {
margin-top: 20px;
font-size: 24px;
color: #FF5531;
}
h3 {
margin-top: 10px;
font-size: 18px;
font-weight: normal;
}
</style>
</head>
<body>
<div class="container">
<img src="/images/logo.png" alt="Logo" class="logo">
<h1>HEARUS</h1>
<h3>모두의 들을 권리를 위하여</h3>
</div>
</body>
</html>먼저 기존 Spring 서버의 / 라우트에 접근할 경우 API 경로들이 노출되도록 개발되어 있었는데, 배포 상태의 서버의 가시성을 높이고 보안을 강화하기 위하여 위와 같이 별도의 Home 라우트를 관리하는 컨트롤러와 HTML 페이지를 생성하였다.
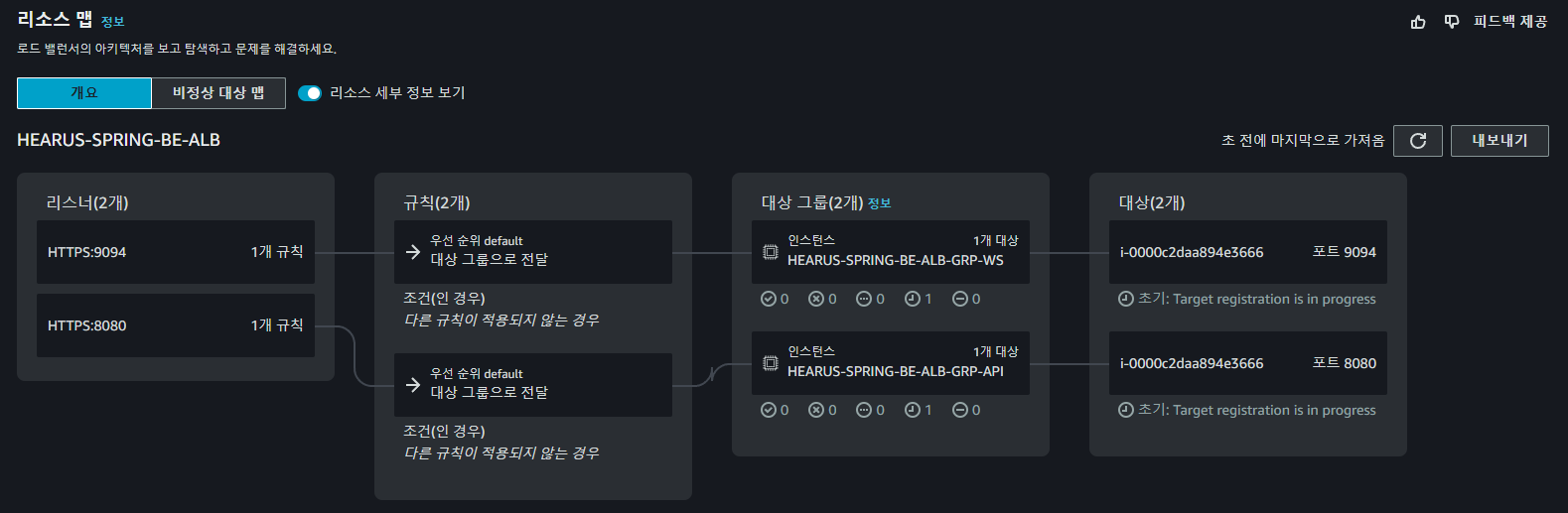 위와 같은 구조의 ALB를 통해 Spring 서버를 배포하였고
위와 같은 구조의 ALB를 통해 Spring 서버를 배포하였고
 퍼블릭 도메인으로 변경된 홈페이지를 가진 서버에 정상적으로 접근하는 것을 볼 수 있었다.
퍼블릭 도메인으로 변경된 홈페이지를 가진 서버에 정상적으로 접근하는 것을 볼 수 있었다.
FastAPI Deployment
AWS EC2 Configuration
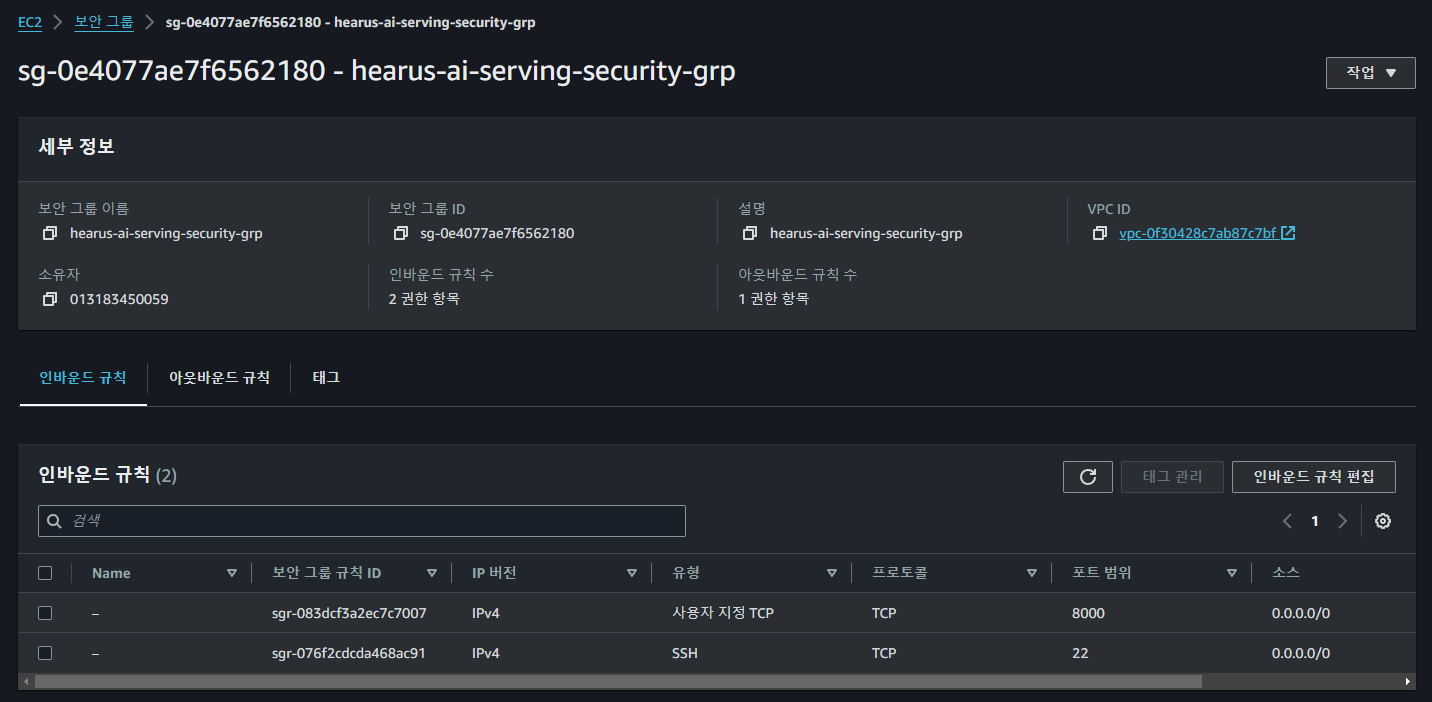 먼저 기존에 설계한 아키텍처에 맞게 인스턴스에 접근할 수 있도록 위와 같이 보안 그룹을 생성하고
먼저 기존에 설계한 아키텍처에 맞게 인스턴스에 접근할 수 있도록 위와 같이 보안 그룹을 생성하고
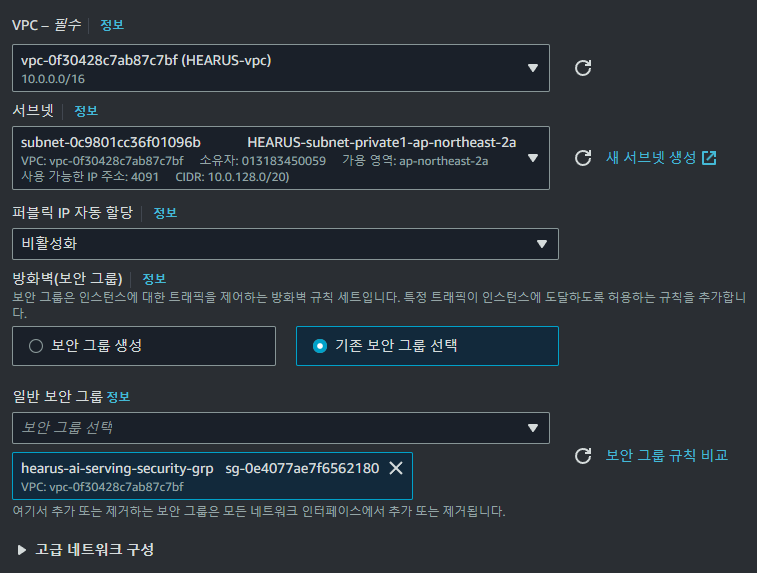 FastAPI AI Serving AWS 인스턴스를 위와 같이 생성해주었다.
FastAPI AI Serving AWS 인스턴스를 위와 같이 생성해주었다.
Jenkins Instance
 이후 Jenkins 인스턴스로 접근하여 인스턴스 생성시 함께 생성되었던 pem 키를 인스턴스에 저장하고
이후 Jenkins 인스턴스로 접근하여 인스턴스 생성시 함께 생성되었던 pem 키를 인스턴스에 저장하고
ssh -i "hearus-ai-serving-key.pem" ***@***Jenkins 인스턴스에서 Private IP를 활용하여 FastAPI 서버에 접근하여준다.
AI-Serving Instance
sudo apt-get update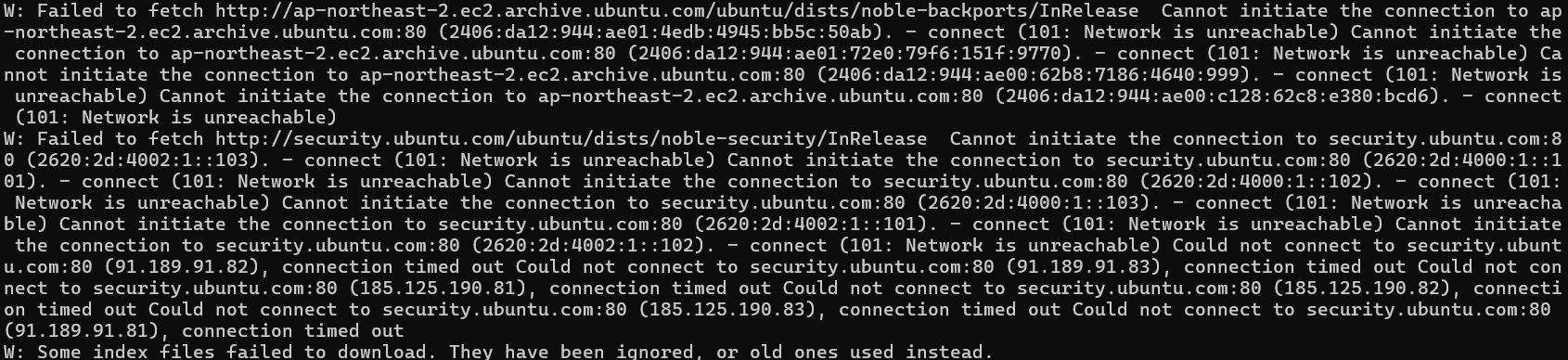 이후
이후 apt-get update를 진행하려 했을때 Private 인스턴스에서 외부로 인터넷 연결이 불가한 문제가 발생하였다.
https://stackoverflow.com/questions/55968995/unable-to-perform-sudo-apt-get-update-from-ec2-instance
Trouble Shooting (101: Network is unreachable)
101: Network is unreachable 오류를 해결하기 위해서는 NAT Gateway를 설정해주어야 한다.
NAT란
-
대부분의 네트워크는 모든 호스트 중 일부만이 인터넷 통신을 수행하는데, 따라서 대부분의 호스트는 PirvateIP를 이용해 통신하고있기에 인터넷 통신을 수행할때만 PublicIP를 사용하게된다면 외부에 노출되는 PublicIP수를 크게 줄일 수 있다.
-
PrivateIP에서 인터넷으로 요청을 보낼때 해당 요청이 Nat을 제공하는 라우터를 통과하게되면 Nat 라우터는 주소 변환 테이블에 가지고있던 PrivateIP를 PublicIP로 IP를 변환하여 요청을 보내고 변환 내용을 Nat변환 테이블에 기록한다.
-
이후 인터넷으로 보낸 응답이 도착하면 기록해두었던 Nat 변환 테이블을 참조하여 요청을 보낸 PrivateIP를 가진 호스트에게 응답을 반환한다.
NAPT란
-
네트워크에서는 여러 호스트가 고유한 PrivateIP를 할당받고, 인터넷으로 요청을 보낼 때 PublicIP로 변환을 위해 Nat를 통과할때 Nat 변환 테이블은 PrivateIP(요청주소)와 NAT을 통해 변환된 PublicIP(변환된 주소)를 기록한다.
-
PrivateIP는 Host마다 고유하지만 변환된 PublicIP는 네트워크의 대표 공인IP이기에 동일 할 수 있다.
-
따라서 인터넷에서 응답이 Nat으로 돌아올때 요청을 보낸 PrivateIP를 구분 하기 위해 변환 테이블의 PublicIP에 PrivateIP마다 각자 다른 port를 할당하고 이를 Network Address Port Translation 즉, NAPT라고 이야기한다
-
이 방법을 통해 여러 PrivateIP가 Nat를 통해 하나의 PublicIP로써 통신이 가능하게 된다.
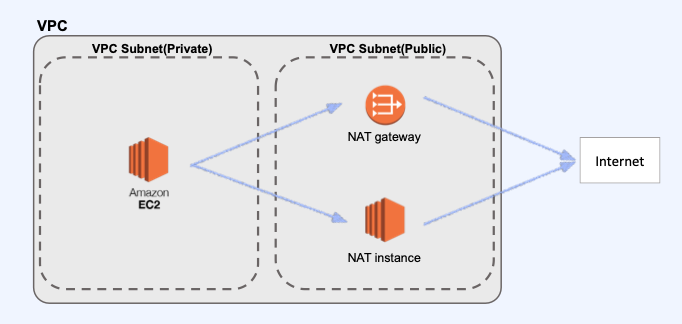
AWS의 NAT Gateway란
- NAT 게이트웨이는 AWS에서 제공하는 NAT(Network Address Translation, 네트워크 주소 변환) 서비스이다.
- NAT의 개념과 동일하게 프라이빗 서브넷의 인스턴스가 VPC 외부의 서비스(인터넷)에 연결할 수 있도록하고
외부 서비스에서는 프라이빗 서브넷 내의 인스턴스와의 연결 할 수 없도록 하기 위해 NAT 게이트웨이를 사용할 수 있다. - 즉 프라이빗 서브넷 내의 EC2를 인터넷, AWS Service에 접근 가능하게 하고 외부에서는 해당 EC2에대한 접근을 막기위해 사용한다.
NAT Gateway 생성
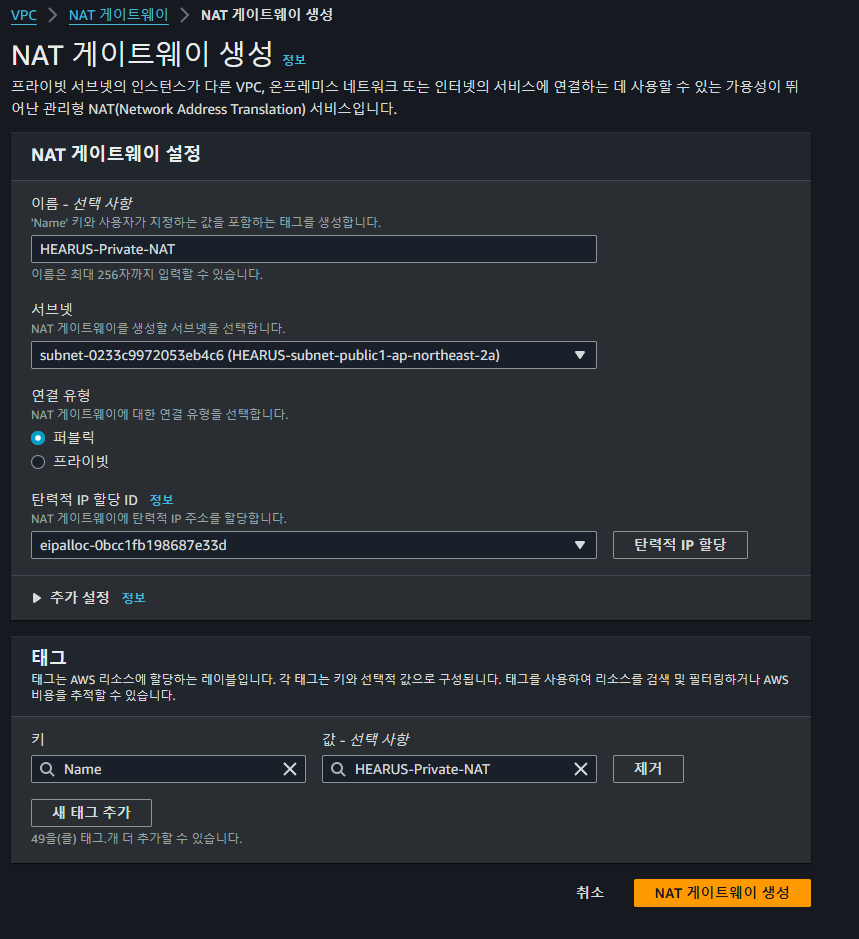 먼저 위와 같이 NAT Gateway를 인스턴스가 위치하고 있는 VPC 내에 생성한다.
먼저 위와 같이 NAT Gateway를 인스턴스가 위치하고 있는 VPC 내에 생성한다.
이때 서브넷은 해당 VPC의 Public 서브넷으로 설정해야 한다.
Private Subnet RTB 수정
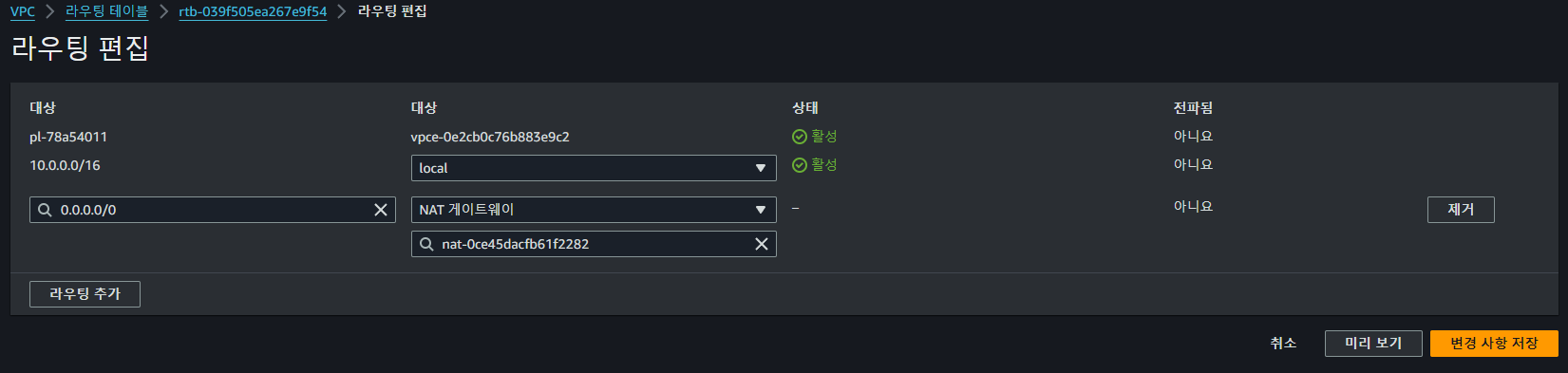
 이후 라우팅 테이에서 모든 IPv4를 NAT Gateway로 향하게 하도록 편집하고
이후 라우팅 테이에서 모든 IPv4를 NAT Gateway로 향하게 하도록 편집하고 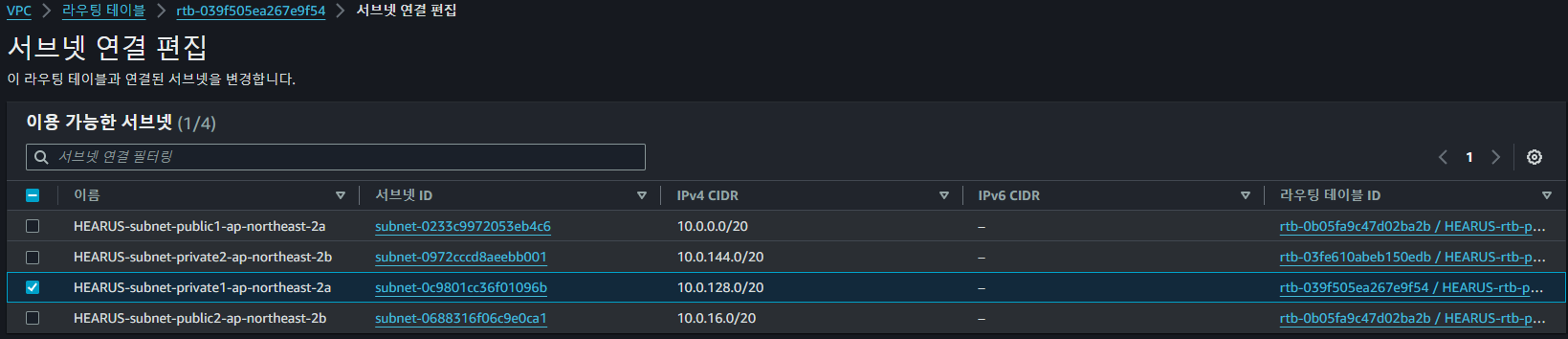
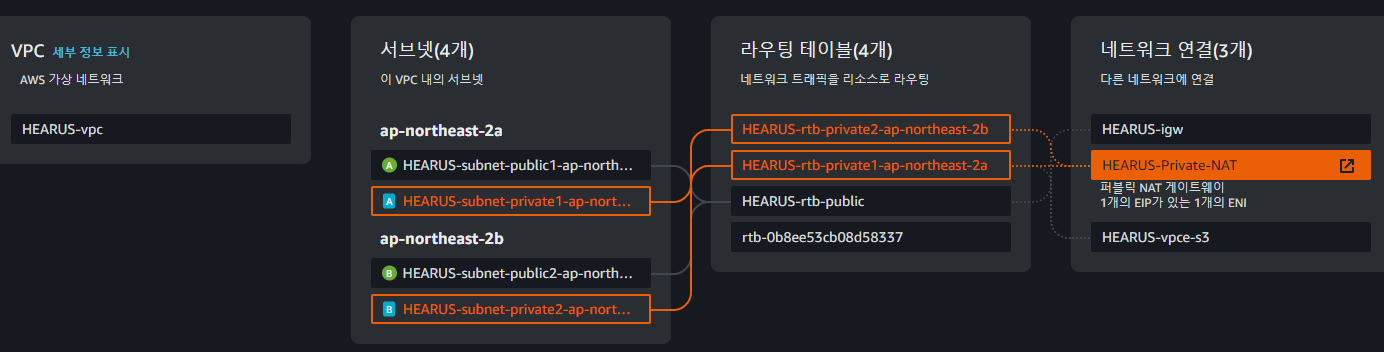 서브넷 연결을 편집하여 Private 인스턴스가 외부로 통신할 수 있도록 네트워크를 구성한다.
서브넷 연결을 편집하여 Private 인스턴스가 외부로 통신할 수 있도록 네트워크를 구성한다.
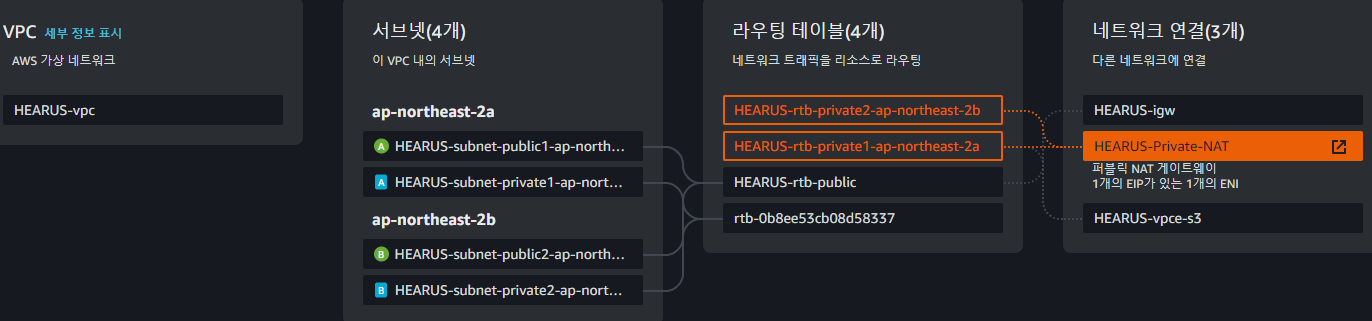
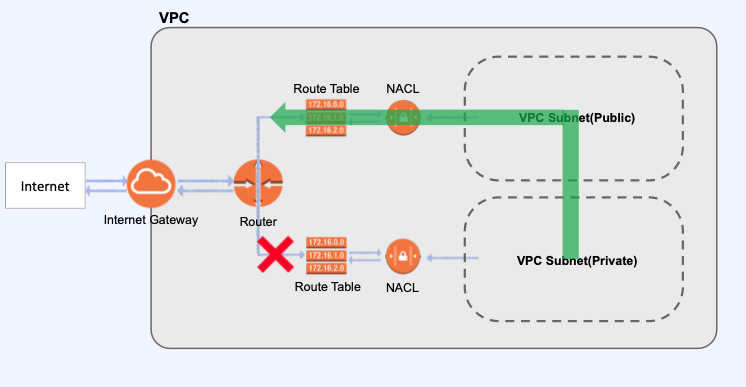 해당 통신 과정을 그림으로 나타내면 다음과 같으며 Private Subnet에서 Public Subnet에 존재하는 NAT를 통해 외부 인터넷으로 연결된 것으로 볼 수 있다.
해당 통신 과정을 그림으로 나타내면 다음과 같으며 Private Subnet에서 Public Subnet에 존재하는 NAT를 통해 외부 인터넷으로 연결된 것으로 볼 수 있다.
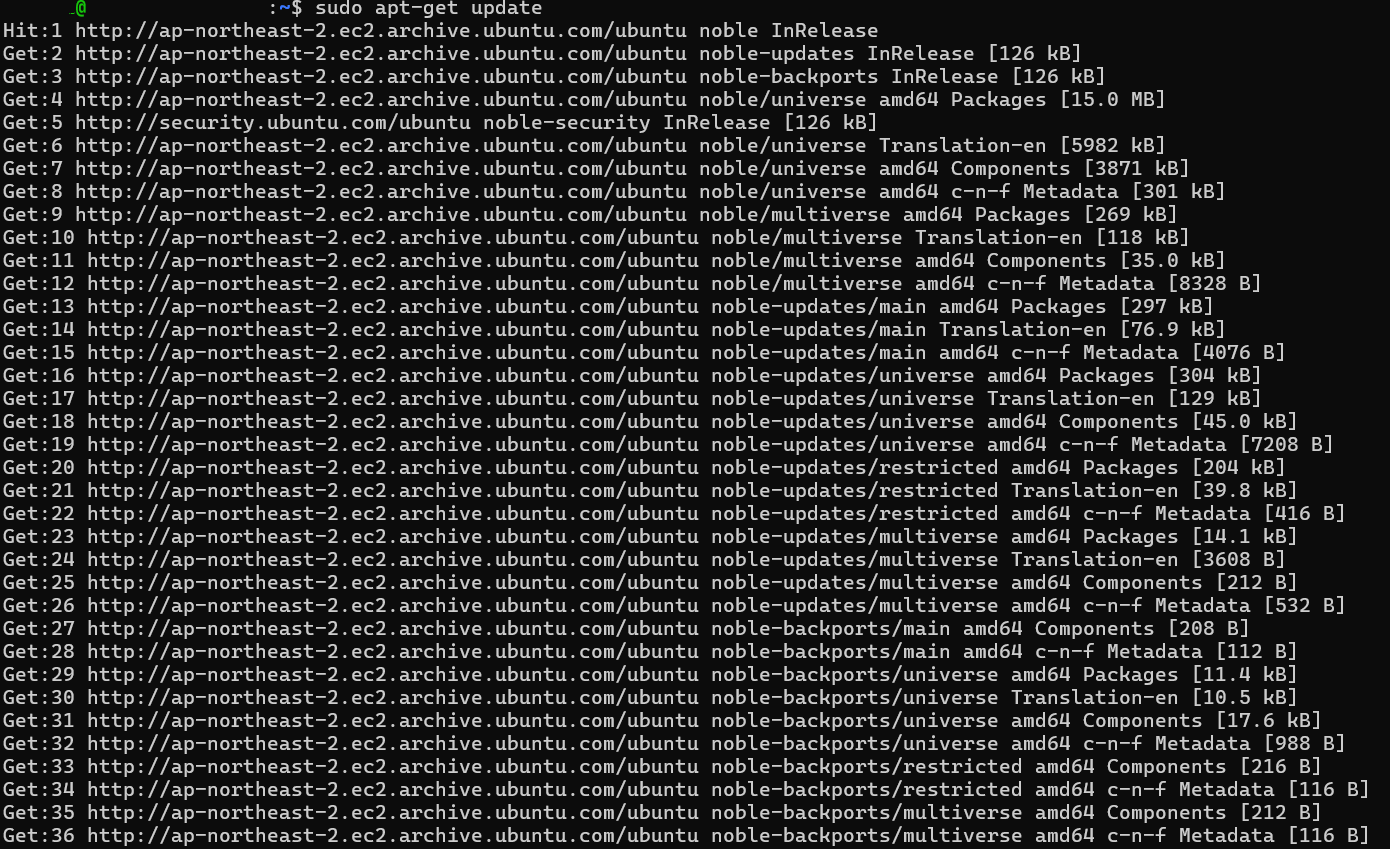 이후 FastAPI 인스턴스에 외부로 정상적으로 통신하는 것을 볼 수 있고
이후 FastAPI 인스턴스에 외부로 정상적으로 통신하는 것을 볼 수 있고
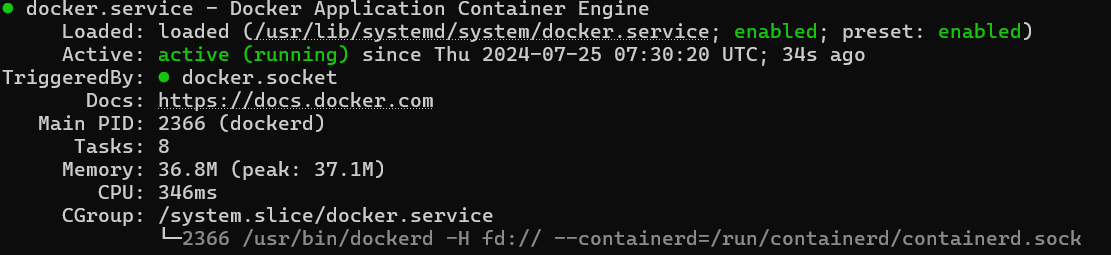 Docker를 설치하여주었다.
Docker를 설치하여주었다.
Dockerize
Dockerfile
FROM python:3.9
WORKDIR /src
RUN mkdir routers
RUN mkdir templates
COPY main.py /src
COPY routers /src/routers
COPY templates /src/templates
COPY requirements.txt /src
COPY start_with_ollama.sh /src
WORKDIR /src
RUN apt-get update
# Install Ollama
RUN curl -fsSL https://ollama.com/install.sh | sh
# Install torch CUDA
RUN pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# Install Whisper
RUN pip install git+https://github.com/openai/whisper.git
# Install Dependencies
RUN pip install -r requirements.txt
RUN chmod +x /src/start_with_ollama.sh
CMD ["/src/start_with_ollama.sh"]기존의 FastAPI 서버를 배포하기 위하여 위와 같이 Dockerfile을 구성하고
start_with_ollama.sh
ollama serve &
while ! nc -z localhost 11434; do
sleep 1
done
ollama pull llama3
exec uvicorn main:app --host 0.0.0.0 --port 8000Ollama가 정상적으로 serve된 이후에 서버가 시작할 수 있도록 스크립트를 작성한다.
 해당 Dockerfile이 정상적으로 빌드되는 것을 확인하였지만 하나의 이미지가 생성되는데 12분 이상이 소요되어 너무 비효율적이라고 판단하였다.
해당 Dockerfile이 정상적으로 빌드되는 것을 확인하였지만 하나의 이미지가 생성되는데 12분 이상이 소요되어 너무 비효율적이라고 판단하였다.
따라서 의존성, Ollama 모델, Whisper 모델 등 서버를 구동하는데 필요한 환경을 인스턴스에 별도로 구성하고 나머지 서버 코드만 배포할 수 있도록 방향을 변경하였다.
apt-get update && apt-get install -y \
curl \
python3 \
python3-pip \
git인스턴스에서 위와 같이 필요한 라이브러리들을 설치하고
$ python3 --version
Python 3.12.3현재 파이썬의 버전을 확인한다.
sudo -i
cd /home/ubuntu이후 위와 같이 /home/ubuntu로 이동하여 주고
apt-get install python3.12-venvpython3.12-venv 라이브러리를 설치하여 인스턴스 내에서 가상환경을 구성할 수 있도록 하였다.
python3 -m venv .venv
source .venv/bin/activatetouch requirements.txt# requirements.txt
# FastAPI
fastapi
uvicorn[standard]
python-dotenv
websockets
pydantic
# Whisper Model Requirement
argparse
numpy
git+https://github.com/openai/whisper.git
# LangChain
langchain
langchain_huggingface
langchain_community
chroma
chromadb
sentence-transformers이후 위와 같이 requirements.txt를 생성하여 주고
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txt
curl -fsSL https://ollama.com/install.sh | shollama serve
ollama pull llama3위 명령어들을 통해 필요한 패키지, 의존성, Ollama 등을 설치하여준다.
Dockerfile
FROM python:3.9
WORKDIR /src
# Install system dependencies
RUN apt-get update && apt-get install -y \
curl \
netcat-openbsd
# Install Ollama
# 빌드 부하 문제로 별도로 인스턴스에 ollama 설치
# RUN curl -fsSL https://ollama.com/install.sh | sh
# Copy application files
COPY main.py requirements.txt start_with_ollama.sh /src/
COPY routers /src/routers
COPY templates /src/templates
# Install application dependencies (excluding torch)
# 빌드 부하 문제로 별도로 인스턴스의 venv에 라이브러리 설치
# 시스템에서 docker-compose volume을 통해 venv내 라이브러리 사용
# RUN grep -v torch requirements.txt > requirements_no_torch.txt && \
# pip3 install -r requirements_no_torch.txt
# Prepare the start script
RUN sed -i 's/\r$//' /src/start_with_ollama.sh && \
chmod +x /src/start_with_ollama.sh
CMD ["/bin/bash", "/src/start_with_ollama.sh"]이러한 상황에 맞추어 위와 같이 시스템에서 volume을 통해 venv내 라이브러리 사용하고 시스템의 Ollama를 사용할 수 있도록 Dockerfile을 변경하여주었다.
docker-compose.yaml
version: '3.8'
services:
app:
build: .
ports:
- "8000:8000"
volumes:
- ./src:/src
- /home/ubuntu/venv:/venv
- /home/ubuntu/.ollama:/root/.ollama
environment:
- VIRTUAL_ENV=/venv
- PATH="/venv/bin:$PATH"
- PYTHONPATH=/venv/lib/python3.8/site-packages
- PYTHONUNBUFFERED=1
network_mode: "host"
command: ["/bin/bash", "/src/start_with_ollama.sh"]또한 추가적으로 편의를 위해 Docker Compose도 위와 같이 작성해주었다.
도커 컴포즈는 컨테이너 여럿을 띄우는 도커 애플리케이션을 정의하고 실행하는 도구(Tool for defining and running multi-container Docker applications) 이다.
컨테이너 실행에 필요한 옵션을 docker-compose.yml이라는 파일에 적어둘 수 있고, 컨테이너 간 의존성도 관리할 수 있어서 좋다.
웹 서비스는 일반적으로 프론트엔드 서버, 벡엔드 서버, 데이터베이스 서버로 구성되기 때문에 각 서버를 docker container로 연결하여 동작시키고 docker compose를 사용하여 해당 컨테이너들을 관리하는 것이다.
Trouble Shooting
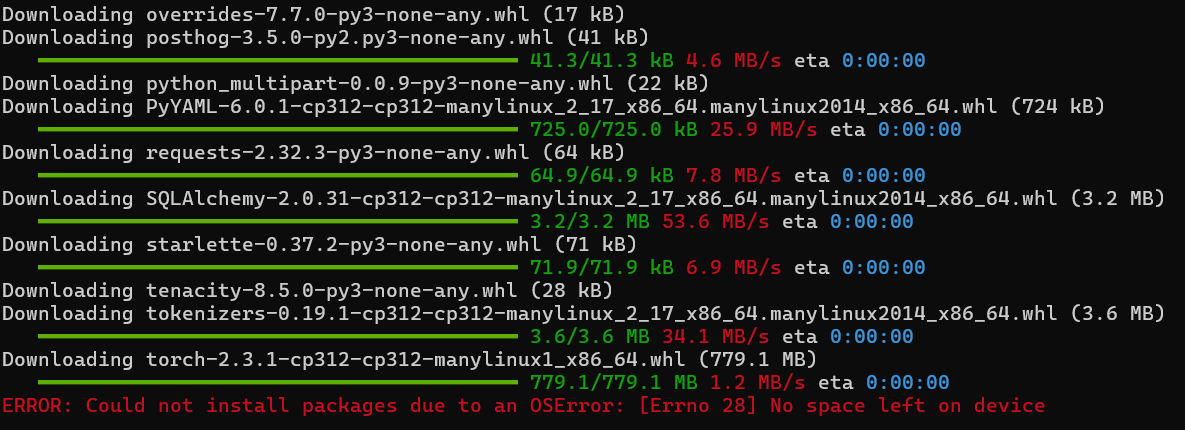 하지만 이러한 과정에서 인스턴스 용량 문제로 먼저 VM을 통해 테스트를 거친 후 새로운 인스턴스 생성을 통해 이를 배포하는 것으로 목표를 변경하였다.
하지만 이러한 과정에서 인스턴스 용량 문제로 먼저 VM을 통해 테스트를 거친 후 새로운 인스턴스 생성을 통해 이를 배포하는 것으로 목표를 변경하였다.
VM Environment Configuration
 먼저 위와 같이 Ubuntu 20.04 LTS 이미지를 다운받고
먼저 위와 같이 Ubuntu 20.04 LTS 이미지를 다운받고
 VirtualBox를 통해 가상 머신을 세팅한다.
VirtualBox를 통해 가상 머신을 세팅한다.

 가상 머신에 Ubuntu가 정상적으로 설치되고 인터넷 연결까지 되어 있는 것을 볼 수 있다.
가상 머신에 Ubuntu가 정상적으로 설치되고 인터넷 연결까지 되어 있는 것을 볼 수 있다.
Trouble Shooting : is not in the sudoers file. This incident will be reported.
위와 같이 현재 ubuntu 유저로 접속해있을 때 terminal에서 sudoer가 아니기 때문에 관리자 권한으로 동작을 수행할 수 없는 오류가 발생한다면
su - root
apt-get install vim
chmod 777 /etc/sudoers
vim /etc/sudoers
chmod 0440 /etc/sudoers
sudo -i위와 같이 /etc/sudoers를 수정하여 ubuntu 유저에게 sudoer 권한을 줄 수 있다.
 이후 Docker를 VM에 설치하고
이후 Docker를 VM에 설치하고
 파이썬 가상환경 또한 생성하여준다.
파이썬 가상환경 또한 생성하여준다.
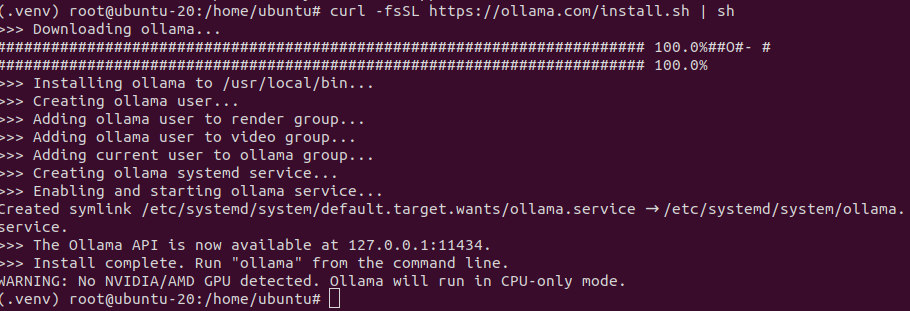 이후 torch와 Ollama를 설치하여주고
이후 torch와 Ollama를 설치하여주고
 최종적으로 원활한 테스트를 위해 Postman까지 설치하여주면 EC2 인스턴스와 유사하게 테스트를 할 수 있는 환경이 생성되었다.
최종적으로 원활한 테스트를 위해 Postman까지 설치하여주면 EC2 인스턴스와 유사하게 테스트를 할 수 있는 환경이 생성되었다.
sudo docker run -dit \
-p 8000:8000 \
--name hearus-ai-serving \
-v /home/ubuntu/venv:/venv \
-v /root/.ollama:/root/.ollama \
-e VIRTUAL_ENV=/venv \
-e PATH="/venv/bin:$PATH" \
-e PYTHONPATH=/venv/lib/python3.8/site-packages \
-e PYTHONUNBUFFERED=1 \
--network host \
judemin/hearus-ai-serving:lastest이후 위와 같이 docker run 명령어를 다시 작성하고
version: '3.8'
services:
hearus-ai-serving:
image: judemin/hearus-ai-serving:lastest
container_name: hearus-ai-serving
ports:
- "8000:8000"
volumes:
- /home/ubuntu/venv:/venv
- /root/.ollama:/root/.ollama
environment:
- VIRTUAL_ENV=/venv
- PATH=/venv/bin:$PATH
- PYTHONPATH=/venv/lib/python3.8/site-packages
- PYTHONUNBUFFERED=1
network_mode: host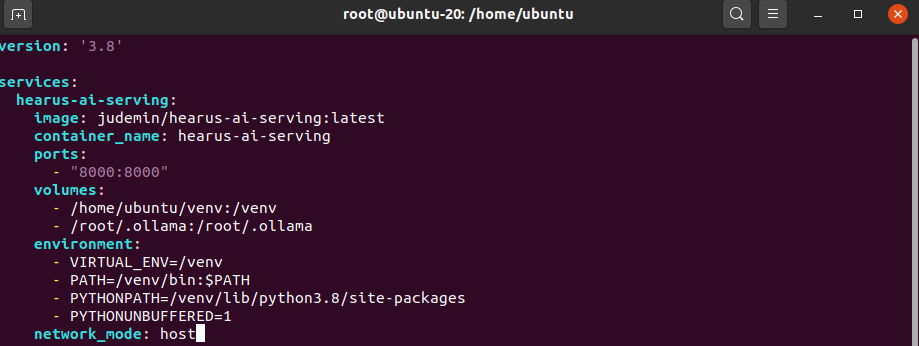 추가적으로 Docker Compose yaml 파일도 작성해주었다.
추가적으로 Docker Compose yaml 파일도 작성해주었다.
apt install docker-compose
docker-compose upapt install docker-compose를 통해 docker-compose를 설정하고 docker-compose up를 통해 컨테이너를 실행시킬 수 있다.
Trouble Shooting
(.venv) root@ubuntu-20:/home/ubuntu# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5e7f823e45f6 judemin/hearus-ai-serving:lastest "/bin/bash /src/star…" About a minute ago Exited (127) About a minute ago hearus-ai-serving
(.venv) root@ubuntu-20:/home/ubuntu# docker logs 5e7
Ollama is ready. Starting the application...
/src/start_with_ollama.sh: line 10: /venv/bin/python: No such file or directory하지만 컨테이너 내부에서 /venv/bin/python: No such file or directory 와 같이 가상환경을 찾지 못한다는 오류가 발생하였다.
FROM python:3.9
WORKDIR /src
# Install system dependencies
RUN apt-get update && apt-get install -y \
curl \
netcat-openbsd
# Copy application files
COPY main.py /src/
COPY routers /src/routers
COPY templates /src/templates
# Create a shell script to activate venv and start the application
RUN echo '#!/bin/bash\n\
source /venvs/bin/activate\n\
python -m uvicorn main:app --host 0.0.0.0 --port 8000 --reload\n\
' > /src/start_app.sh
RUN chmod +x /src/start_app.sh
CMD ["/src/start_app.sh"]이를 해결하기 위해 Dockerfile의 start_app.sh를 생성하는 코드를 변경해주었고
sudo docker run -dit \
--name hearus-ai-serving \
-p 8000:8000 \
-v /home/ubuntu/.venv:/home/ubuntu/.venv \
-v /root/.ollama:/root/.ollama \
-e VIRTUAL_ENV=/home/ubuntu/.venv \
-e PATH="/home/ubuntu/.venv/bin:$PATH" \
-e PYTHONPATH=/home/ubuntu/.venv/lib/python3.8/site-packages \
-e PYTHONUNBUFFERED=1 \
--network host \
judemin/hearus-ai-serving:lastest/home/ubuntu/.venv를 Docker 이미지를 실행시킬 때 환경변수로 지정해주었다.
이때 일반적으로 Docker 컨테이너는 자체적인 네트워크 네임스페이스를 가지며, 호스트 시스템과는 분리된 네트워크 환경에서 실행되는데 Ollama 및 시스템 내 설치된 패키지를 활용하기 위해 --network host 옵션을 사용하면 이 분리를 제거하고, 컨테이너가 호스트의 네트워크 스택을 직접 사용하게 된다.
--network host에 대한 특징들은 아래와 같다
주요 특징:
- 호스트의 네트워크 인터페이스를 직접 사용
- 호스트의 IP 주소와 모든 네트워크 인터페이스를 공유
- 별도의 포트 매핑 없이 호스트의 포트를 그대로 사용 가능
장점:
- 네트워크 성능이 향상 (NAT 오버헤드 제거)
- 호스트의 네트워크 도구와 설정을 그대로 사용 가능
- 호스트에서 실행 중인 다른 서비스(예: Ollama)에 쉽게 접근할 수 있음
단점:
- 컨테이너와 호스트 시스템 간의 네트워크 격리가 없어집니다.
- 보안 위험이 증가할 수 있습니다.
- 포트 충돌이 발생할 수 있습니다.
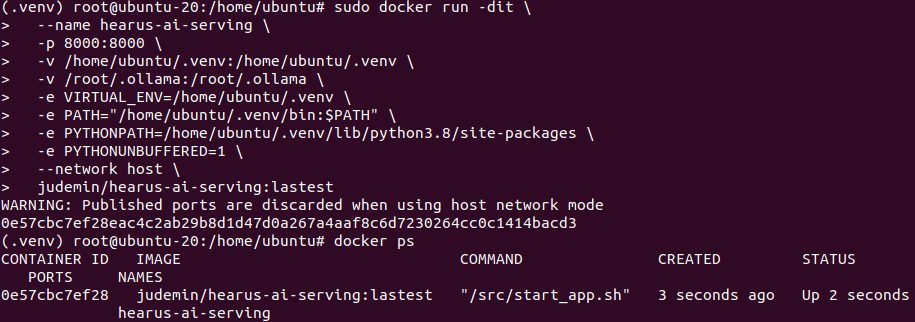
Trouble Shooting
(.venv) root@ubuntu-20:/home/ubuntu$ docker logs be
/src/start_app.sh: line 2: /.venv/bin/activate: No such file or directory
INFO: Will watch for changes in these directories: ['/src']
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
INFO: Started reloader process [7] using StatReload
...
ImportError: Failed to load PyTorch C extensions:
It appears that PyTorch has loaded the `torch/_C` folder
of the PyTorch repository rather than the C extensions which
are expected in the `torch._C` namespace. This can occur when
using the `install` workflow. e.g.
$ python setup.py install && python -c "import torch"이후 위와 같이 torch._C 패키지를 찾지 못하는 문제가 발생하여
docker exec -it be sh실행중인 Docker 컨테이너에 직접 접근하여 어떤 문제가 있는지 확인해보았다.
Dockerfile
FROM python:3.12
...
# Create a shell script to activate venv and start the application
RUN echo '#!/bin/bash\n\
chmod 777 .venv/bin/activate\n\
source .venv/bin/activate\n\
python -m uvicorn main:app --host 0.0.0.0 --port 8000 --reload\n\
' > /src/start_app.sh우선 위와 같이 Dockerfile에서 잘못된 volume 참조 코드를 수정하였다.
python3 3.11 버전 업그레이드
sudo apt-get install --upgrade python3
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt install python3.11 -yroot@ubuntu-20:~$ python3.11 --version
Python 3.11.9apt list | grep python3.11이때 이러한 문제는 Ubuntu에 기본적으로 설치된 Python 3.8 버전을 통해 패키지를 설치할 경우 Docker 컨테이너 내의 Python 3.11 과는 호환되지 않는 버전이 설치되어 발생하는 문제일 수도 있을 것 같아 위와 같이 Python3.11을 설치하여주었고
root@ubuntu-20:~# sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.11 1
update-alternatives: using /usr/bin/python3.11 to provide /usr/bin/python3 (python3) in auto moderoot@ubuntu-20:~# python3 -V
Python 3.11.9update-alternatives를 통해 Python3의 버전을 업그레이드해주었다.
https://vegastack.com/tutorials/how-to-install-python-3-11-on-ubuntu-22-04/
https://www.itsupportwale.com/blog/how-to-upgrade-to-python-3-11-on-ubuntu-20-04-and-22-04-lts/
Pytorch 버전 업그레이드
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu또한 현재 VM에서는 CPU만 활용하고 있기 때문에 CPU를 사용하는 버전의 torch를 재설치해주었고
sudo docker run -dit \
--name hearus-ai-serving \
-p 8000:8000 \
-v /home/ubuntu/.venv:/src/.venv \
-v /root/.ollama:/root/.ollama \
-e VIRTUAL_ENV=/src/.venv \
-e PATH="/src/.venv/bin:$PATH" \
-e PYTHONPATH=/src/.venv/lib/python3.8/site-packages \
-e PYTHONUNBUFFERED=1 \
-e HUGGINGFACEHUB_API_TOKEN=your_token_here \
--network host \
judemin/hearus-ai-serving:lastestChromaDB를 위한 HUGGINGFACEHUB_API_TOKEN를 별도로 Docker 실행시 환경변수로 지정해주어
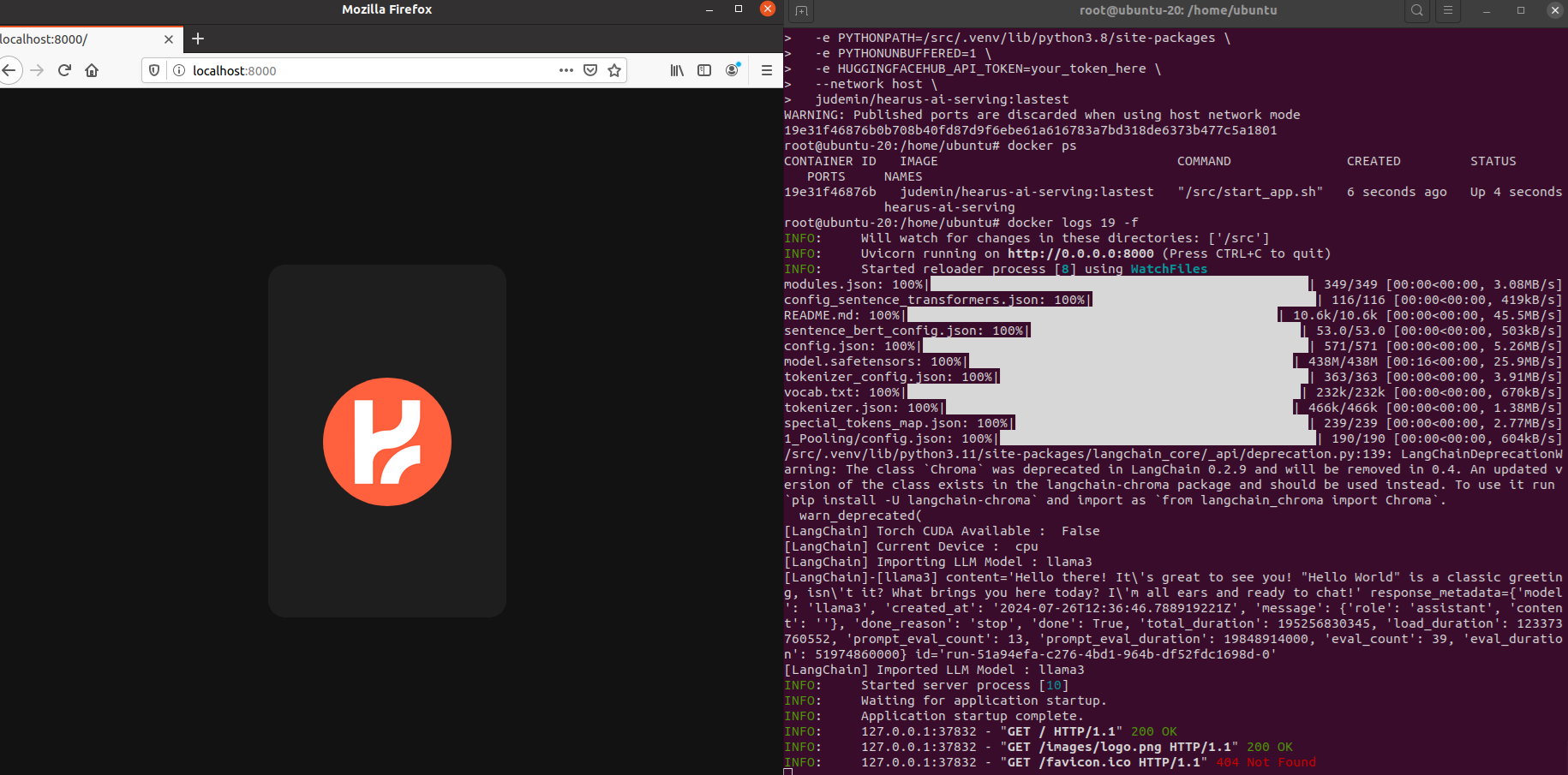 서버가 정상적으로 작동한 것을 확인할 수 있었으며
서버가 정상적으로 작동한 것을 확인할 수 있었으며
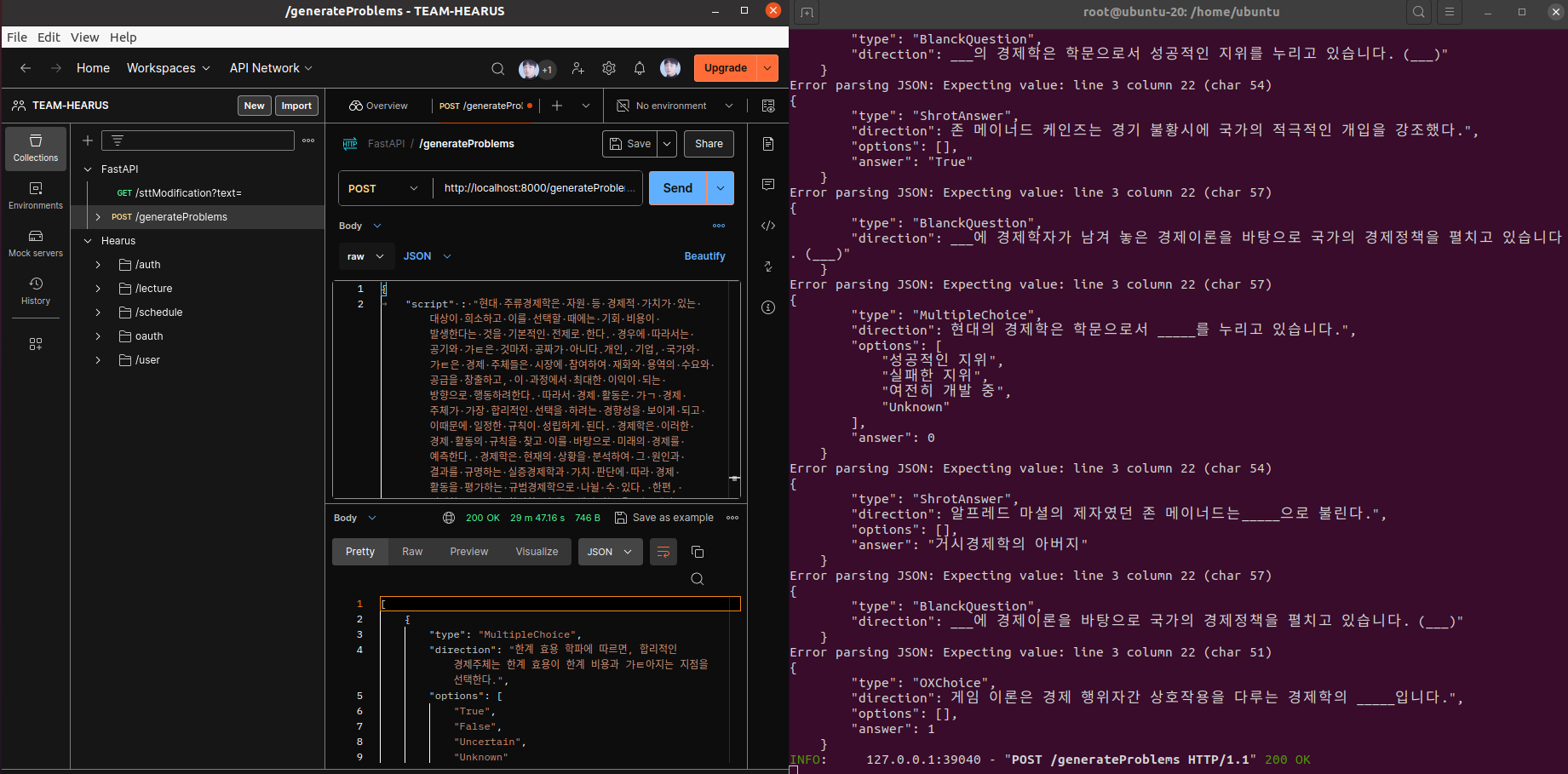 CPU만 사용하고 있어 오래 걸리지만 LangChain도 정상적으로 동작하는 것을 확인하였다.
CPU만 사용하고 있어 오래 걸리지만 LangChain도 정상적으로 동작하는 것을 확인하였다.
AWS Spot Instance Deployment
AWS Pricing

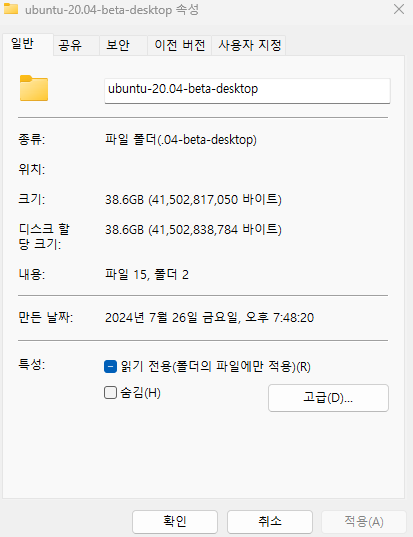 이전 VM 환경을 구축한 저장공간 및 프로세서, 메모리 등을 위와 같이 확인하였다
이전 VM 환경을 구축한 저장공간 및 프로세서, 메모리 등을 위와 같이 확인하였다
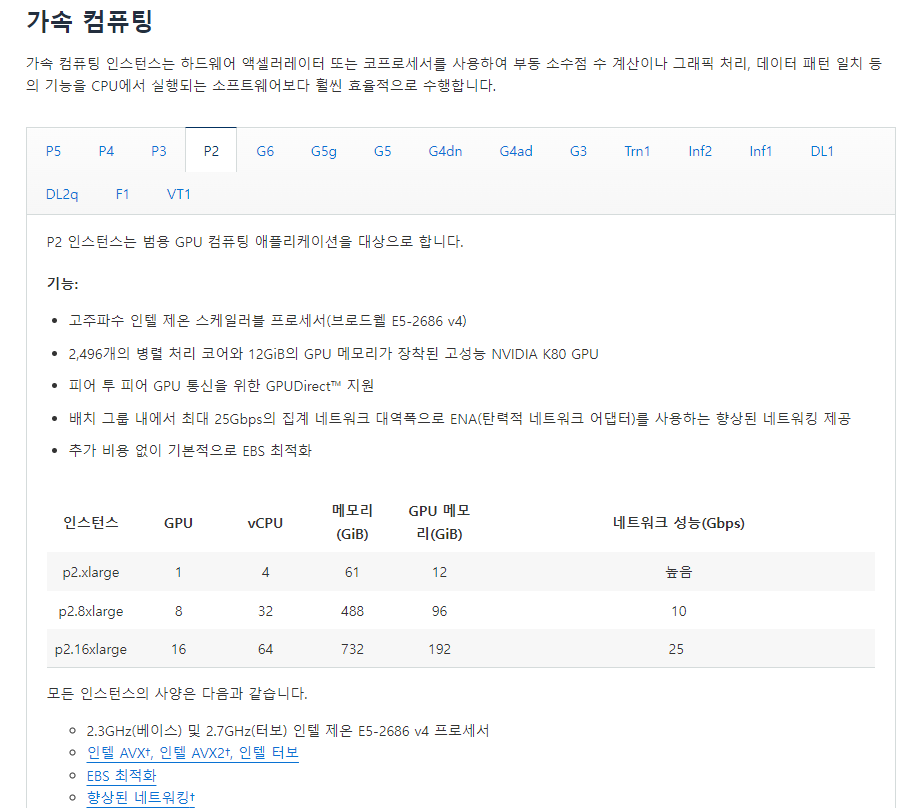 이후 이러한 정보를 바탕으로 GPU 활용이 가능한 인스턴스들 중
이후 이러한 정보를 바탕으로 GPU 활용이 가능한 인스턴스들 중 P2 계열의 인스턴스를 선택하였고
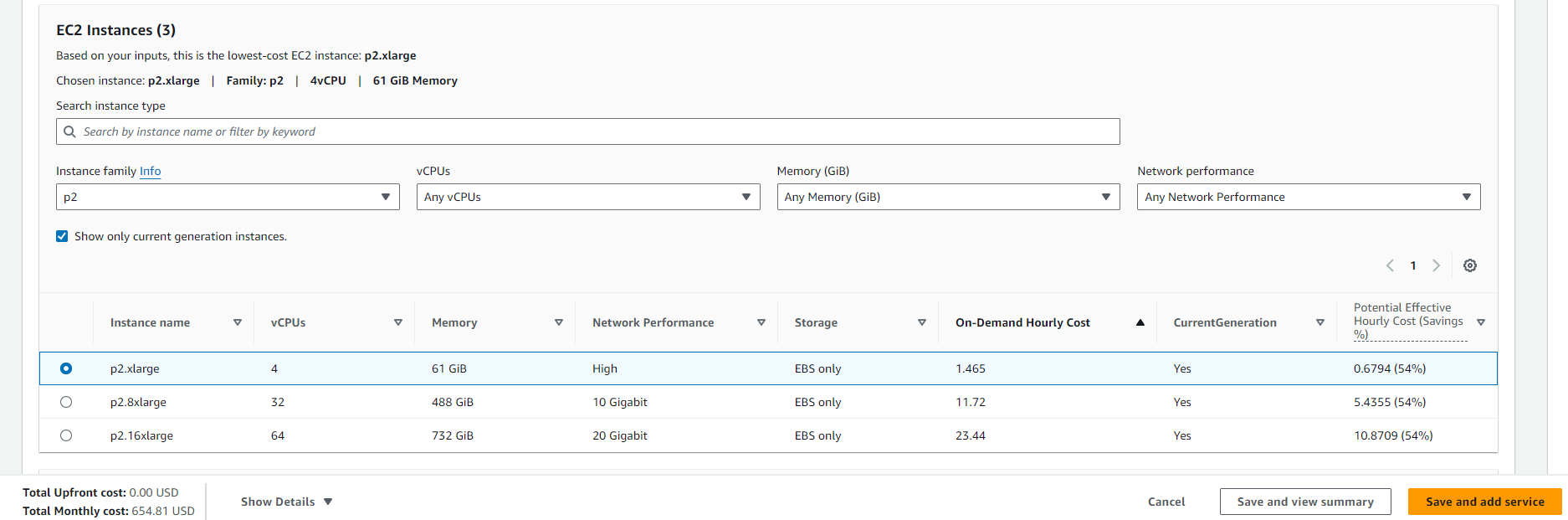 AWS p2.xlarge On Demand EC2의 경우 위와 같이 월 약
AWS p2.xlarge On Demand EC2의 경우 위와 같이 월 약 654.81 USD의 비용이 발생하는 것을 확인하였다.
하지만 이러한 서버 유지 비용에도 불구하고 서버를 구축하려는 이유는
[GPT-4o Mini]
- US$0.150 / 1M input tokens
- US$0.600 / 1M output tokens
바교적 가격이 저렴한 GPT-4o Mini를 사용하더라도 현재 서비스의 기능들을 고려하였을 때
현재 분류 Input 토큰 길이 : 4000
- 250 요청 = 0.150 USD
예상 분류 Output 토큰 길이: 1000 - 1,000 요청 = 0.600 USD
MAU : 10,000명
하루 평균 요청 횟수 : 10
- Input 0.006 USD
- Output : 0.06 USD
GPT-4o Mini 월별 사용 금액 : 660 USD
위와 같이 MAU 10,000명의 하루 10번의 문제 생성 요청만 발생한다고 한다고 해도 이미 약 660 USD로 서버 유지 비용을 넘어서기 때문이다.
또한 실시간 음성인식 및 음성인식 결과 조정을 위한 LangChain의 토큰이 발생한다는 것을 고려해보면 서버를 구축하는 것이 사업화가 가능한 방향이라고 결론을 내리게 되었다.
AWS Spot Instance
위와 같은 서버 비용을 절감하기 위해 Spot Instance를 활용하는 방향으로 프로젝트를 진행하였다.
Spot Instance는 온디맨드에 비해 70~90%정도의 가격으로 EC2 인스턴스를 이용할 수 있게 해주는 기능이다.
대신 가격은 수요와 공급에 따라 항상 변화하고 안정성이 떨어지는데 전체 EC2 인스턴스가 부족해지면 사용하던 Spot Instance를 종료시키게 되어 유연하게 동작해야하는 작업에 주로 활용된다.
해당 Spot Instance와 관련된 개념들은 아래와 같다
Spot Capacity Pool
미사용 EC2 인스턴스 집합을 말한다.
Spot Price
스팟 인스턴스의 현재 시간당 가격이다.
Spot Instance request
스팟 인스턴스를 사용하기 위한 최고 가격을 제시하면 그에 맞는 인스턴스가 있을 때 사용할 수 있게 해준다.
일회성이나 영구적으로 사용하는 방법이 있는데 영구적 사용시 인스턴스가 종료되고 다시 인스턴스 풀에 사용할 수 있는 인스턴스가 발견되면 사용하게 해준다.
Spot Fleet
사용자가 지정한 기준을 바탕으로 시작되는 인스턴스 세트이다. 목표 용량을 정해두면 그 용량에 맞추어 인스턴스를 유지하려고 한다. 이 요청에 온디맨드 요청을 포함시킬 수 있다.
EC2 instance rebalance recommendation
스팟이 종료되려고 할 때 리밸런싱 권고 신호를 2분전에 생성한다.
Spot Instance interruption
최고 가격에 맞는 인스턴스가 더 이상 없을 경우 스팟 인스턴스를 중지하거나 절전모드로 전환한다.
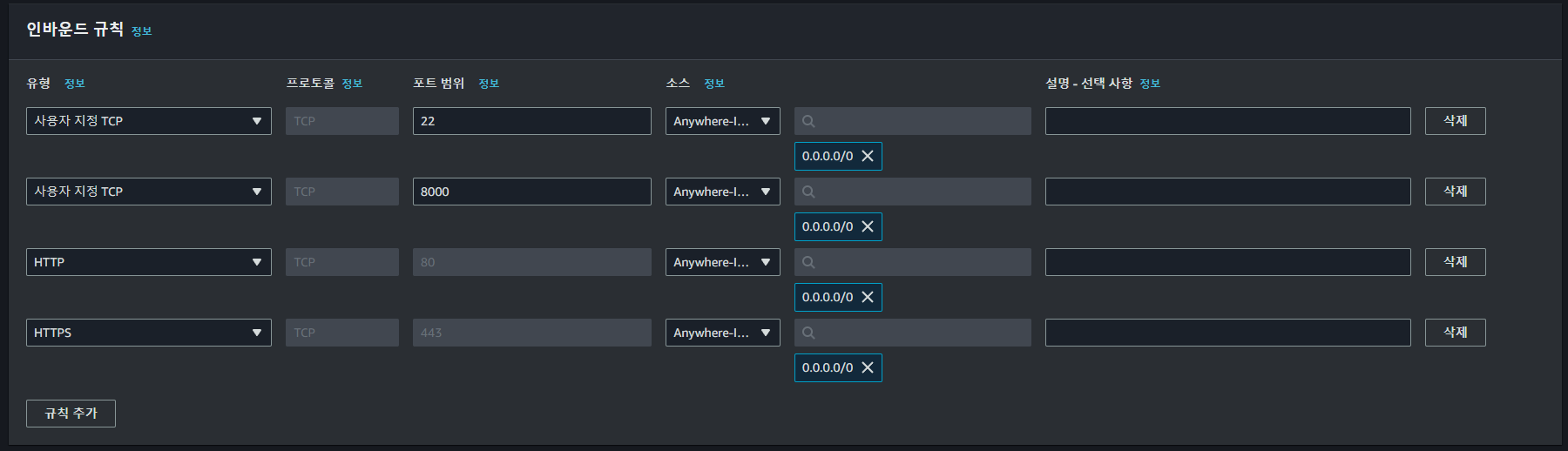 인스턴스를 생성하기 이전 보안그룹을 위와 같이 생성한다.
인스턴스를 생성하기 이전 보안그룹을 위와 같이 생성한다.
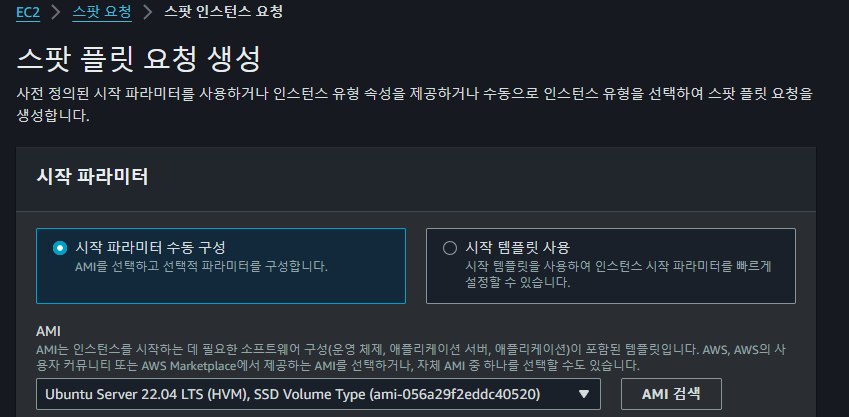
Spot Instance를 생성하기 위하여 위와 같이 Ubuntu Server 22.04 LTS AMI를 선택한다.
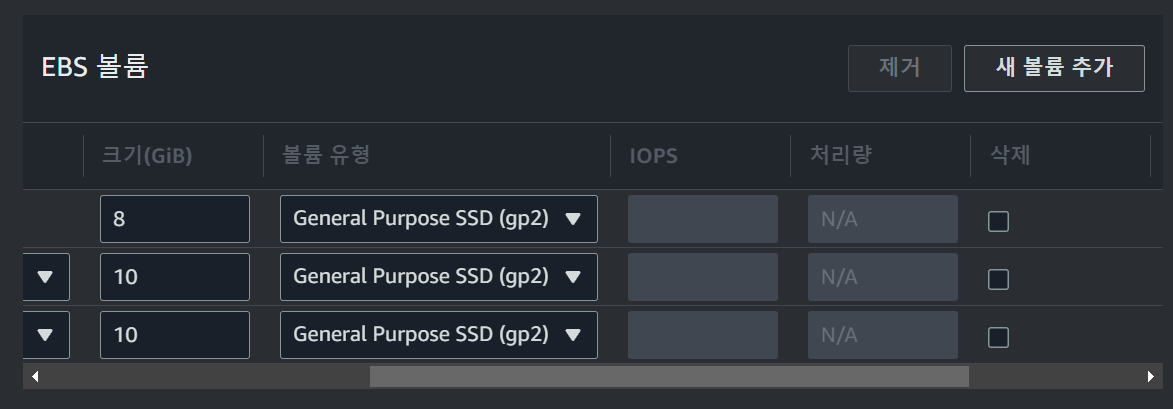
 또한
또한 The snapshot should be of one of the root volumes attached to the instance in the past 오류를 방지하기 위하여 Spot 인스턴스를 요청할 때 위와 같이 인스턴스가 삭제되었을 때 Root Volume이 삭제되는 옵션을 해제해야 한다
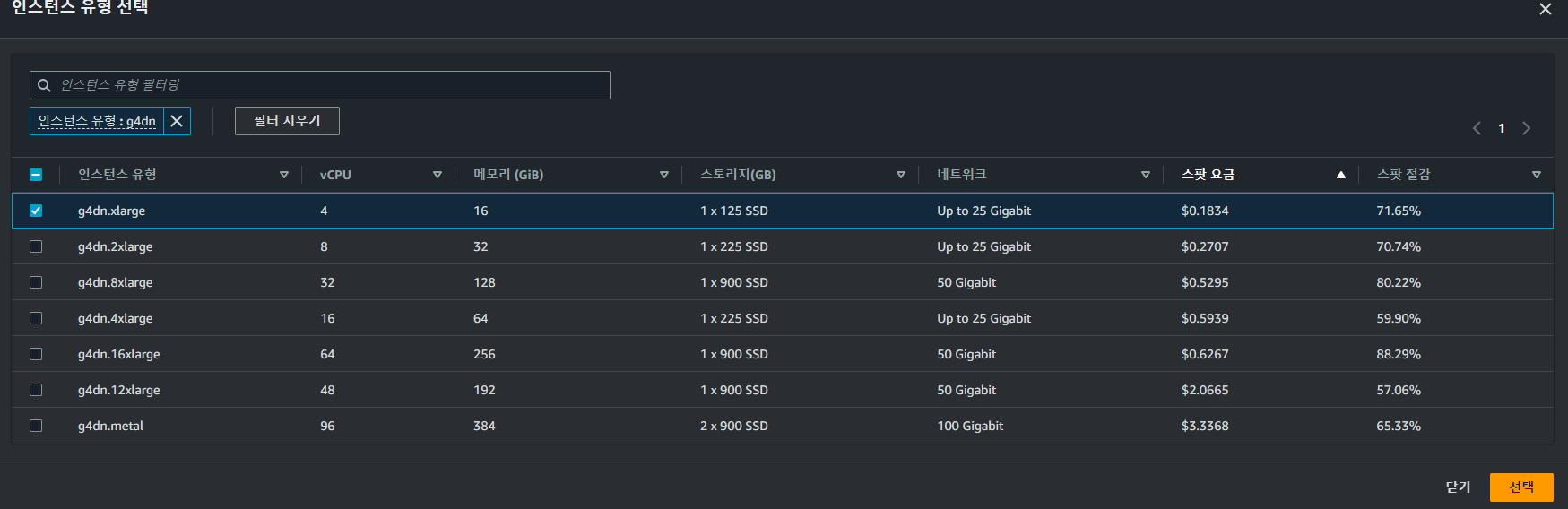 이후
이후 g4dn 또는 p2.xlarge 인스턴스 유형을 선택하여준다
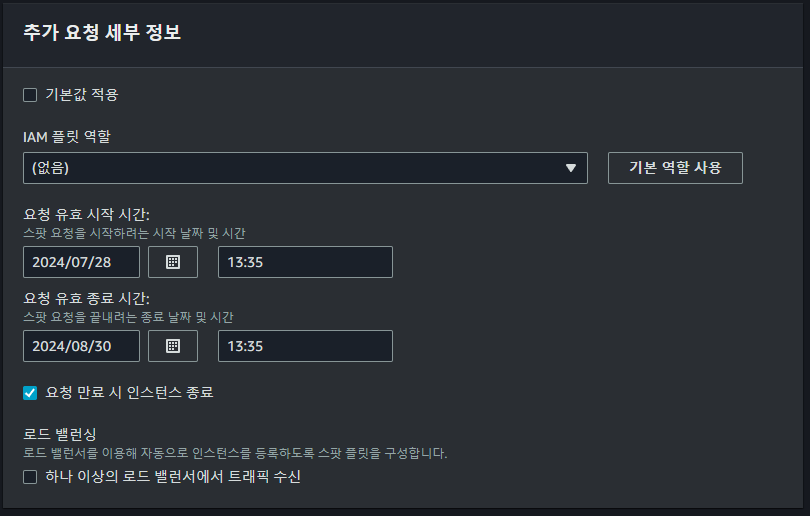 추가요청 세부정보에서는 요청 유효 기간과 요청이 만료되었을 때 인스턴스를 종료하는 등의 작업을 수행할 수 있다.
추가요청 세부정보에서는 요청 유효 기간과 요청이 만료되었을 때 인스턴스를 종료하는 등의 작업을 수행할 수 있다.
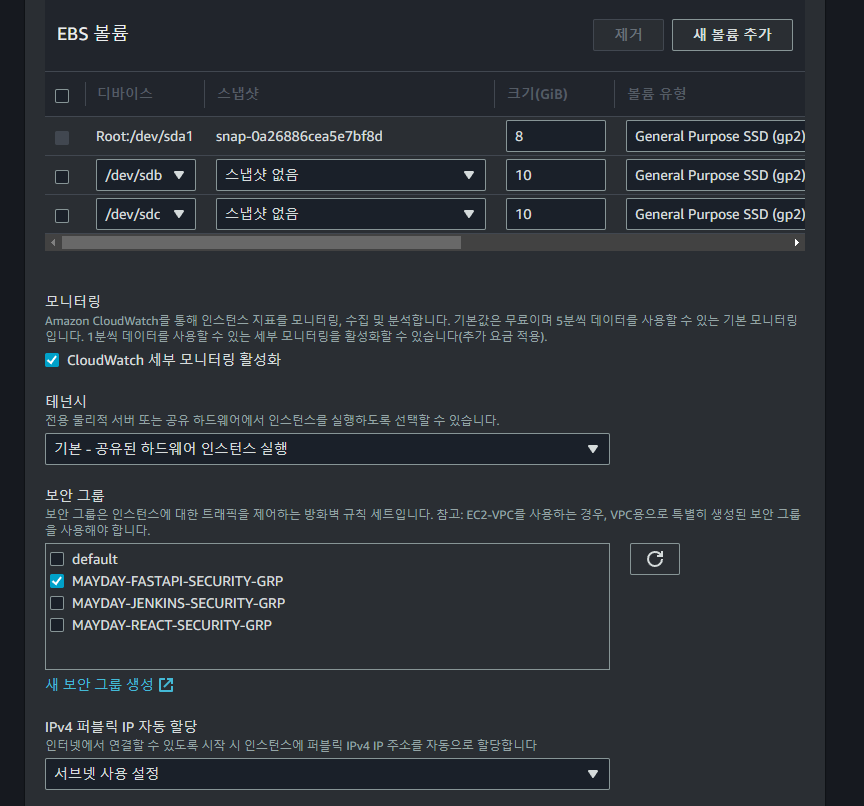 또한 위와 같이 VPC, Subnet 설정 및 보안 그룹을 활성화한다.
또한 위와 같이 VPC, Subnet 설정 및 보안 그룹을 활성화한다.
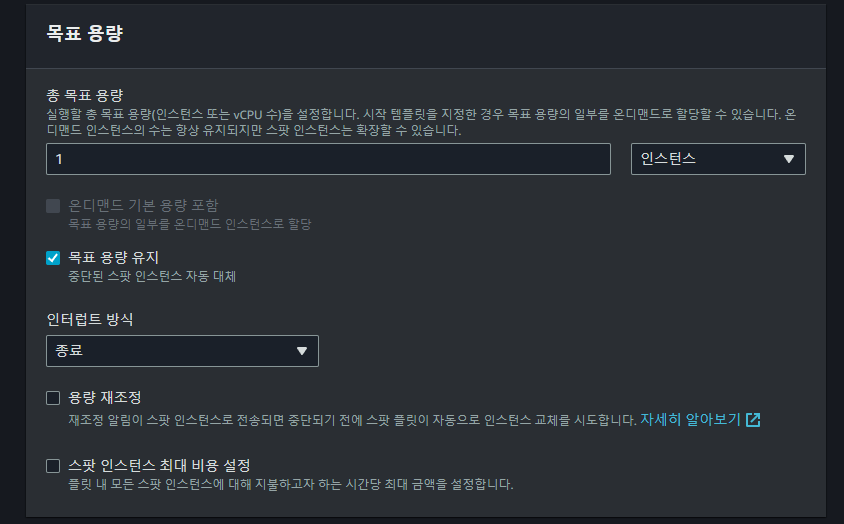 이후 목표 용량과 관련된 설정을 마치고 나면
이후 목표 용량과 관련된 설정을 마치고 나면 Spot Instance 요청을 생성할 수 있다.
 이때 위와 같이
이때 위와 같이 g4dn 유형의 인스턴스를 생성할 수 없다는 에러가 발생하게 되면
Spot Instance Quota Increase Request
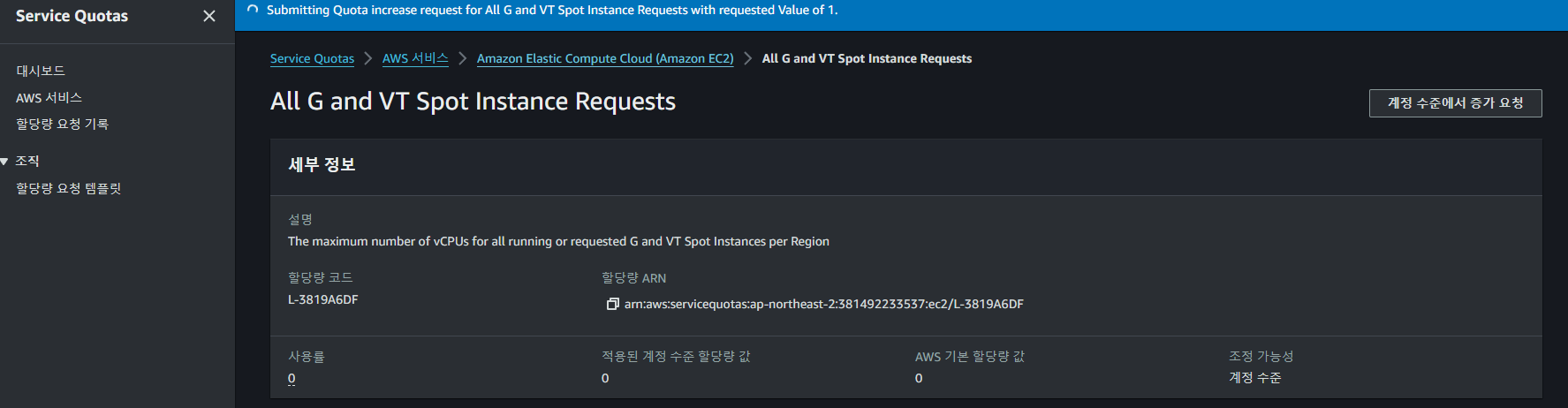
 계정 수준에서 G, VT Spot 인스턴스에 대한 증가 요청을 해주어야 한다.
계정 수준에서 G, VT Spot 인스턴스에 대한 증가 요청을 해주어야 한다.
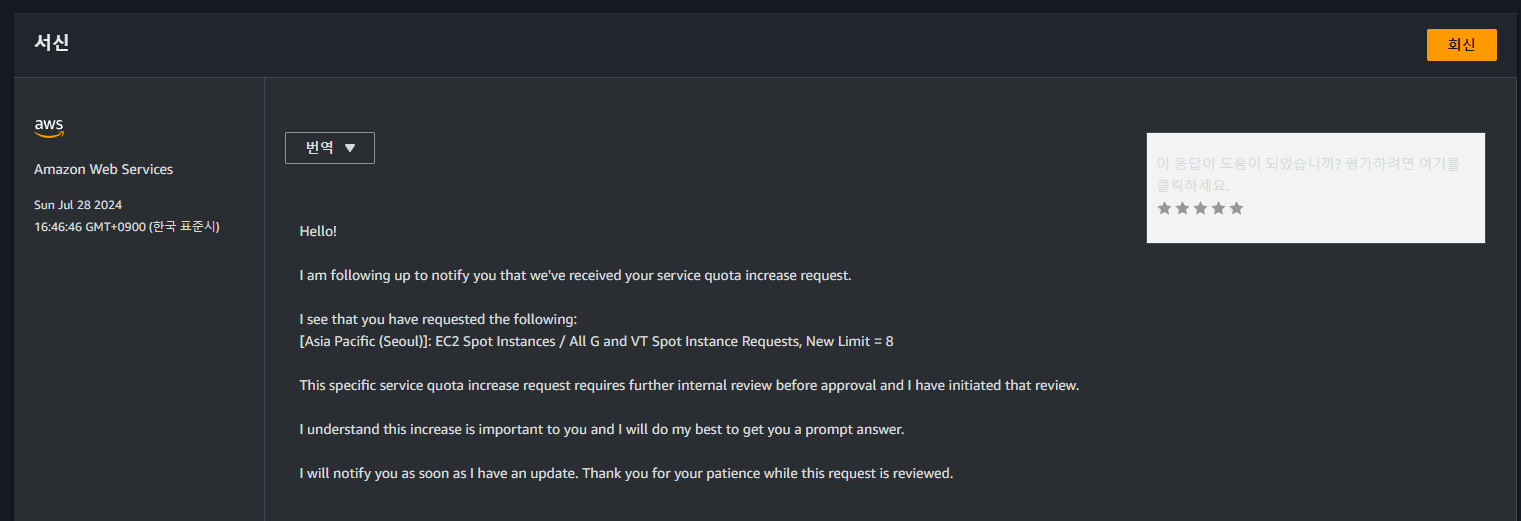 이후 계정 수준에서 인스턴스 Quota 증가 요청이 완료되면
이후 계정 수준에서 인스턴스 Quota 증가 요청이 완료되면
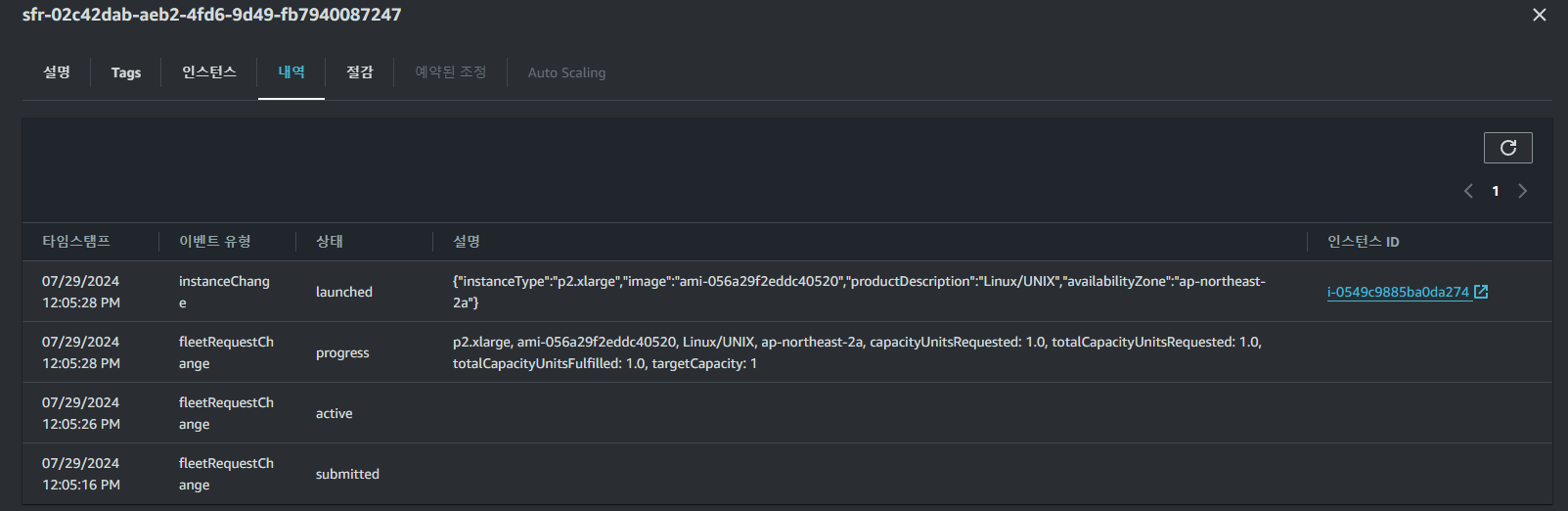 위와 같이
위와 같이 Spot Instance 요청이 정상적으로 생성되는 것을 볼 수 있고

Spot Instance 요청에 맞는 인스턴스가 생성되는 것을 확인할 수 있다.
$ lshw -numeric -C display
*-display:0 UNCLAIMED
description: VGA compatible controller
product: GD 5446 [1013:B8]
vendor: Cirrus Logic [1013]
physical id: 2
bus info: pci@0000:00:02.0
version: 00
width: 32 bits
clock: 33MHz
capabilities: vga_controller
configuration: latency=0
resources: memory:80000000-81ffffff memory:86004000-86004fff memory:c0000-dffff
*-display:1 UNCLAIMED
description: 3D controller
product: GK210GL [Tesla K80] [10DE:102D]
vendor: NVIDIA Corporation [10DE]
physical id: 1e
bus info: pci@0000:00:1e.0
version: a1
width: 64 bits
clock: 33MHz
capabilities: pm msi pciexpress cap_list
configuration: latency=0
resources: iomemory:100-ff memory:84000000-84ffffff memory:1000000000-13ffffffff memory:82000000-83ffffff$ lspci | grep -i nvidia
00:1e.0 3D controller: NVIDIA Corporation GK210GL [Tesla K80] (rev a1)해당 인스턴스에서 lshw, lspci 명령어를 통해 NVIDIA Corporation GK210GL [Tesla K80] GPU가 존재하는 것을 확인할 수 있고
apt install -y nvidia-driver-470해당 GPU에 맞는 nvidia-driver-470를 설치하여
$ nvidia-smi
Mon Jul 29 06:18:37 2024
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.256.02 Driver Version: 470.256.02 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 00000000:00:1E.0 Off | 0 |
| N/A 30C P0 58W / 149W | 0MiB / 11441MiB | 87% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+nvidia-smi를 통해 GPU의 현재 상태를 확인할 수 있다.
EBS Volume Configuaration
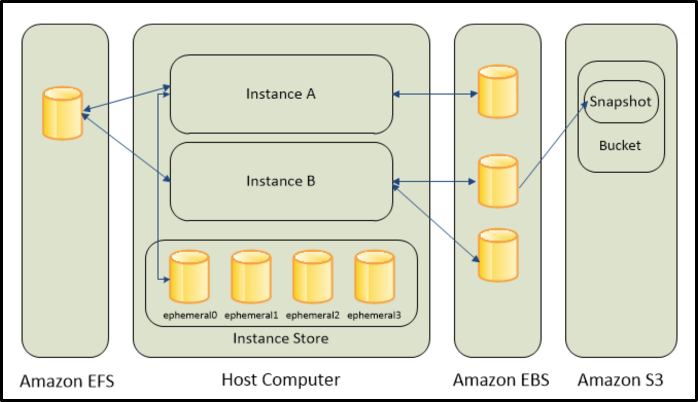
1) Amazon EBS(Elastic Block Storage)
-
EBS는 블록 스토리지이다.
-
Amazon EBS는 EC2 인스턴스의 영구 스토리지로써 인스턴스의 종료나 중지와 상관없이 데이터가 유지된다.
-
세분화된 업데이트를 자주 수행하는 데이터의 경우 적당한 내구성을 갖춘 EBS 사용을 권장한다.
-
특히, EBS는 EC2인스턴스에서 DB를 실행해야 할 경우 권장되는 스토리지 옵션이다.
-
처음 EC2를 생성할 시, root디바이스 유형이 EBS로 설정되어있으며 앞선 그림에서 참조할 수 있듯이, EBS는 인스턴스에 단일로 구성될 수 있으며 여러 EBS로 구성될 수 있다.
-
또한, 인스턴스에서 EBS를 분리하여 다른 인스턴스에 연결하여 사용할 수 있지만 인스턴스 생성시에 구성된 root 디바이스의 경우는 분리하지 못하며 추가적으로, EBS 볼륨의 스냅샷을 생성하여 S3에 저장하면 데이터의 백업 사본을 유지할 수 있다.
-
이러한 SnapShot을 통해 Spot Instance의 가용성을 어느정도 보장할 수 있다.
2) Amazon EC2 Instance Store
- Instance Store는 인스턴스를 종료, 중단 및 최대 절전모드시 Instance Store Volume의 모든 데이터가 손실되는 휘발성 스토리지이며 EC2 생성 혹은 AMI 생성 시에 선택해야 한다.
3) Amazon EFS(Elastic File System)
-
EFS는 Amazon EC2에서 사용할 수 있는 확장 가능한 파일 스토리지를 제공하고 EFS 파일 시스템을 만든 후, 파일 시스템을 마운트 하도록 인스턴스를 구성할 수 있다.
-
또한 EFS는 하나의 파일 시스템으로 여러 인스턴스와 연결 가능하다.
4) Amazon S3(Simple Storage Service)
-- S3 서비스는 오브젝트(객체) 스토리지이며 저렴하고 신뢰성 있는 데이터 스토리지 인프라에 액세스 할 수 있다.
-
또한, EC2 내 혹은 웹의 어디서나 원하는 데이터 양을 저장하고 가져올 수 있어서, 웹 규모의 컴퓨팅 작업을 쉽게 수행할 수 있고 S3를 사용하면, 데이터 및 애플리케이션의 백업 복사본을 저장할 수 있다.
-
더 나아가 S3를 사용하면 EBS 스냅샷과 인스턴스 스토어를 AMI 형태로 백업할 수 있다.
 Spot Instance를 생성할때 자동으로 생성된 볼륨은 위와 같이 구성되어 있으며
Spot Instance를 생성할때 자동으로 생성된 볼륨은 위와 같이 구성되어 있으며
 EBS에 대한 가격 정책은 위와 같다.
EBS에 대한 가격 정책은 위와 같다.
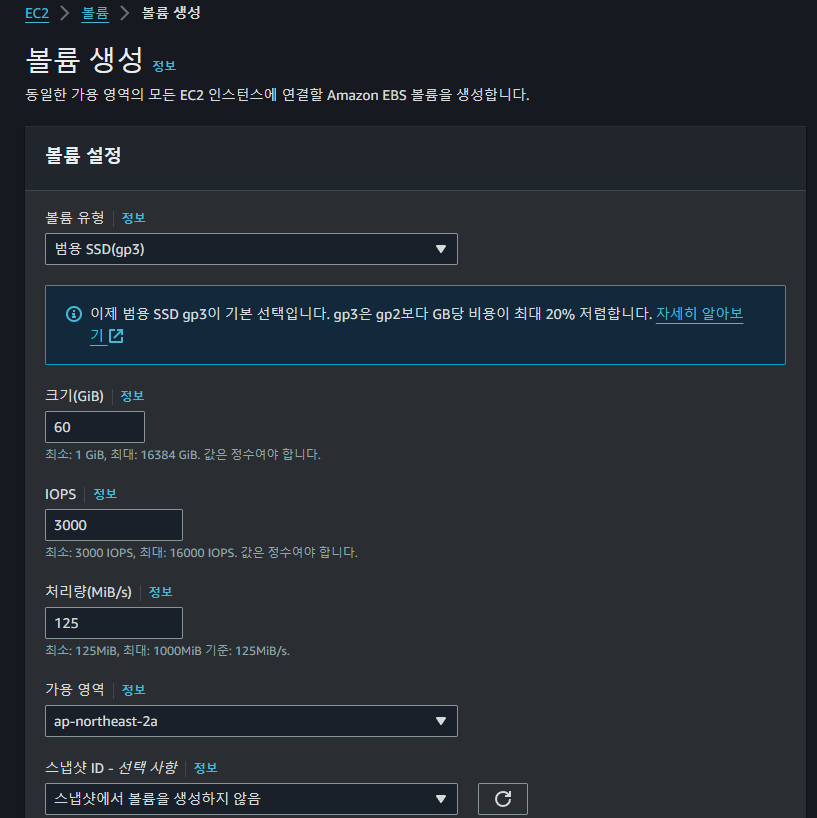 기존의 VM에서의 스펙을 기반으로 위와 같은 볼륨을 새로 생성하고
기존의 VM에서의 스펙을 기반으로 위와 같은 볼륨을 새로 생성하고
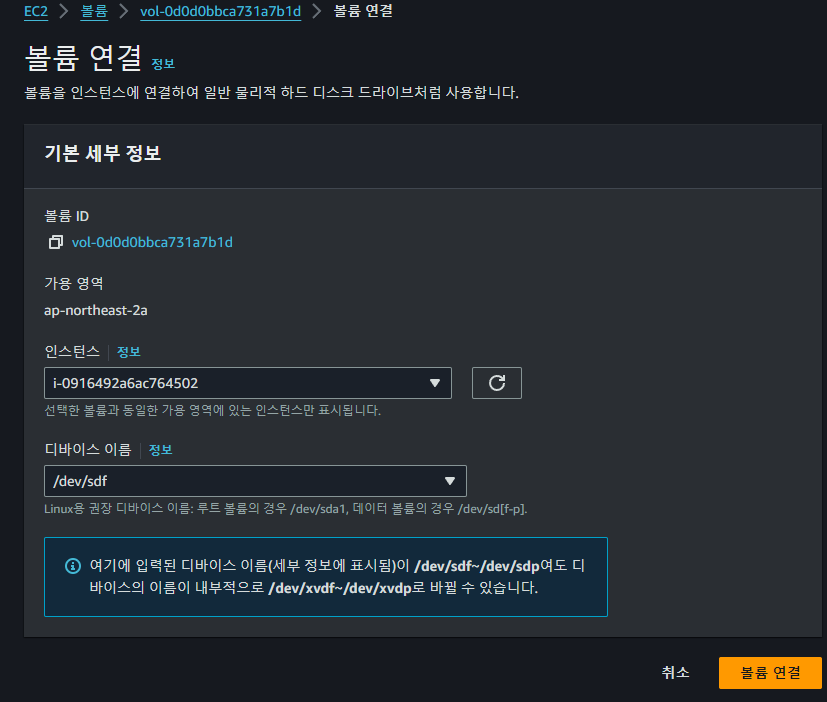 AWS Console에서 Spot Instance와 볼륨을 위와 같이 연결하여준다
AWS Console에서 Spot Instance와 볼륨을 위와 같이 연결하여준다
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
loop0 7:0 0 25.2M 1 loop /snap/amazon-ssm-agent/7993
loop1 7:1 0 55.7M 1 loop /snap/core18/2829
loop2 7:2 0 63.9M 1 loop /snap/core20/2318
loop3 7:3 0 87M 1 loop /snap/lxd/28373
loop4 7:4 0 38.8M 1 loop /snap/snapd/21759
xvda 202:0 0 8G 0 disk
├─xvda1 202:1 0 7.9G 0 part /
├─xvda14 202:14 0 4M 0 part
└─xvda15 202:15 0 106M 0 part /boot/efi
xvdf 202:80 0 60G 0 disklsblk를 통해 현재 Mount된 디스크들을 위와 같이 확인할 수 있다.
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/root 7.6G 1.6G 6.0G 22% /
tmpfs 30G 0 30G 0% /dev/shm
tmpfs 12G 876K 12G 1% /run
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/xvda15 105M 6.1M 99M 6% /boot/efi
tmpfs 6.0G 4.0K 6.0G 1% /run/user/1000이후 df -h를 통해 현재 FileSystem을 확인해주고
$ sudo file -s /dev/xvdf
/dev/xvdf: datafile -s /dev/xvdf 옵션으로 해당 드라이버가 마운트되어 있는지 확인한다.
data로 표시되는 경우 아직 마운트가 되어있지 않다는 의미이다.
$ sudo mkfs -t xfs /dev/xvdf
meta-data=/dev/xvdf isize=512 agcount=4, agsize=3932160 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1 bigtime=0 inobtcount=0
data = bsize=4096 blocks=15728640, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=7680, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0sudo mkfs -t xfs /dev/xvdf를 통해 새로운 파일 시스템을 생성하여주고
sudo mkdir /data드라이버가 마운트될 디렉토리를 생성한 후
sudo mount /dev/xvdf /datamount 명령어를 통해 드라이버를 마운트해준다.
Persistent Volume Mount
sudo cp /etc/fstab /etc/fstab.orig하지만 위와 같은 방법으로 진행할 경우 인스턴스의 상태에 따라 마운트가 해제될 수도 있기 때문에 영구적으로 볼륨을 마운트해주어야 한다.
sudo blkid
/dev/xvda1: LABEL="cloudimg-rootfs" UUID="a7e321c6-fe24-4b08-b922-b296032b6eda" BLOCK_SIZE="4096" TYPE="ext4" PARTUUID="c3c83566-041b-448c-847a-c32f2ae31352"
/dev/xvda15: LABEL_FATBOOT="UEFI" LABEL="UEFI" UUID="E0C7-CA96" BLOCK_SIZE="512" TYPE="vfat" PARTUUID="6e58f1ca-8df9-45da-adfc-ba18e46e38d2"
/dev/loop1: TYPE="squashfs"
/dev/xvda14: PARTUUID="188e4e28-b97c-4882-8242-7b1b2089ae75"
/dev/loop4: TYPE="squashfs"
/dev/xvdf: UUID="805dec26-5662-430b-9834-ab310aac0f59" BLOCK_SIZE="512" TYPE="xfs"
/dev/loop2: TYPE="squashfs"
/dev/loop0: TYPE="squashfs"
/dev/loop3: TYPE="squashfs"sudo blkid명령어를 통해 마운트된 디바이스의 UUID를 복사하여준다.
/dev/xvdf: UUID="805dec26-5662-430b-9834-ab310aac0f59" BLOCK_SIZE="512" TYPE="xfs"
sudo vi /etc/fstab
UUID=xxxx-xxxx-xxxxxxx /data xfs defaults,nofail 0 2
/etc/fstab를 수정하여 위 포맷에 맞게 추가하여주고
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
...
xvdf 202:80 0 60G 0 disk /datadf -h
Filesystem Size Used Avail Use% Mounted on
...
/dev/xvdf 60G 461M 60G 1% /datalsblk 명령어와 df -h 명령어를 통해 영구적으로 마운트된 것을 확인할 수 있다.
xvda Volume Expand
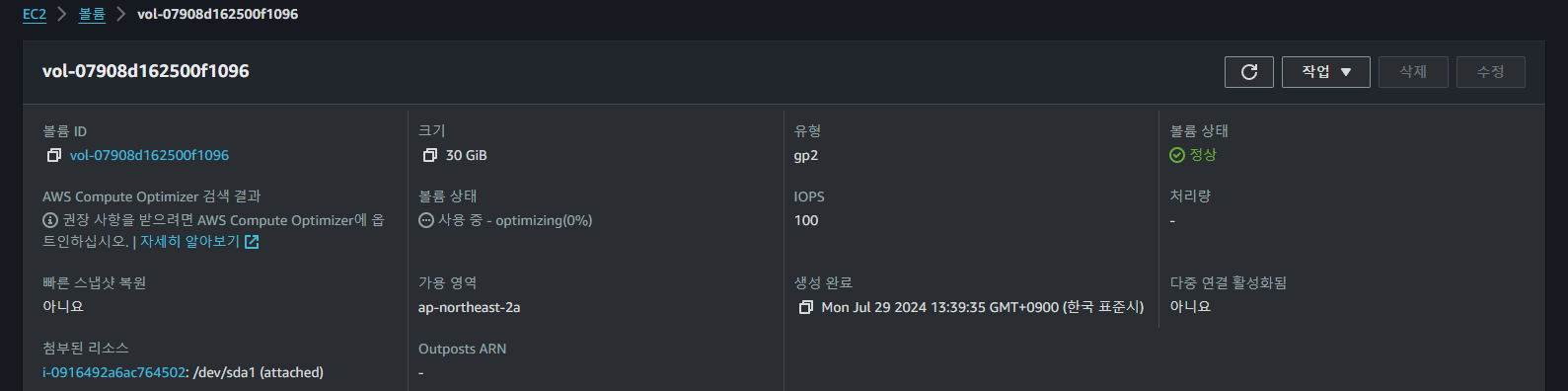 새로운 볼륨을 마운트하는 것 뿐 아니라
새로운 볼륨을 마운트하는 것 뿐 아니라 root 볼륨을 확장하여 용량 문제를 해결하고자 하였다.
$ sudo lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
loop0 7:0 0 25.2M 1 loop /snap/amazon-ssm-agent/7993
loop1 7:1 0 55.7M 1 loop /snap/core18/2829
loop2 7:2 0 63.9M 1 loop /snap/core20/2318
loop3 7:3 0 87M 1 loop /snap/lxd/28373
loop4 7:4 0 38.8M 1 loop /snap/snapd/21759
xvda 202:0 0 30G 0 disk
├─xvda1 202:1 0 7.9G 0 part /
├─xvda14 202:14 0 4M 0 part
└─xvda15 202:15 0 106M 0 part /boot/efi
xvdf 202:80 0 60G 0 disk /datalsblk 명령어를 통해 AWS Console을 통해 확장한 볼륨의 용량이 잘 반영되었는지 확인하고
$ sudo growpart /dev/xvda 1
CHANGED: partition=1 start=227328 old: size=16549855 end=16777183 new: size=62687199 end=62914527growpart 명령어를 통해 /dev/xvda의 1번째 파티션의 용량을 추가적으로 확장하고
$ sudo lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
...
xvda 202:0 0 30G 0 disk
├─xvda1 202:1 0 29.9G 0 part /
├─xvda14 202:14 0 4M 0 part
└─xvda15 202:15 0 106M 0 part /boot/efilsblk를 통해 파티션에 해당 데이터가 잘 반영되었는지 확인한 후
$ sudo resize2fs /dev/root
resize2fs 1.46.5 (30-Dec-2021)
Filesystem at /dev/root is mounted on /; on-line resizing required
old_desc_blocks = 1, new_desc_blocks = 4
The filesystem on /dev/root is now 7835899 (4k) blocks long.ext4 포맷의 파티션의 경우 resize2fs 명령어를 통해 사이즈를 다시 할당한다.
df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/root ext4 29G 5.0G 24G 18% /
...해당 결과를 df -hT 명령어를 통해 확인할 수 있다.
https://jhlee-developer.tistory.com/entry/AWS-EC2-EBS-%EB%B3%BC%EB%A5%A8-%ED%99%95%EC%9E%A5%ED%95%98%EB%8A%94-%EB%B0%A9%EB%B2%95
https://docs.aws.amazon.com/ko_kr/ebs/latest/userguide/recognize-expanded-volume-linux.html
NVIDIA Docker Runtime
또한 GPU를 Docker 컨테이너에서 사용하기 위해서는 몇 가지 추가적인 설정이 필요하다.
1. NVIDIA Docker 런타임 설치
# NVIDIA GPG 키 추가 및 저장소 설정
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
# 패키지 리스트 업데이트 및 nvidia-docker2 설치
sudo apt-get update
sudo apt-get install -y nvidia-docker2
# Docker 데몬 재시작
sudo systemctl restart docker먼저, NVIDIA Docker 런타임을 설치해야 하는데 이는 Docker 컨테이너가 호스트의 NVIDIA GPU를 사용할 수 있게 해준다.
2. Docker 실행 명령어 수정
sudo docker run -dit \
--name mayday-fastapi-be \
--gpus all \
-p 8000:8000 \
-v /home/ubuntu/.venv:/src/.venv \
-v /root/.ollama:/root/.ollama \
-e VIRTUAL_ENV=/src/.venv \
-e PATH="/src/.venv/bin:$PATH" \
-e PYTHONPATH=/src/.venv/lib/python3.8/site-packages \
-e PYTHONUNBUFFERED=1 \
-e HUGGINGFACEHUB_API_TOKEN=your_token_here \
--network host \
judemin/mayday-fastapi-be:lastestGPU를 사용하기 위해 Docker 실행 명령어에 --gpus all 옵션을 추가한다.
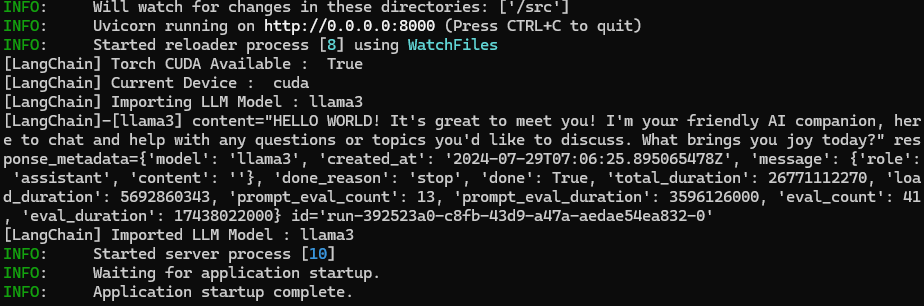 최종적으로 GPU를 사용하며 llama3 모델이 정상적으로 Spot Instance에서 구동되는 것을 볼 수 있다.
최종적으로 GPU를 사용하며 llama3 모델이 정상적으로 Spot Instance에서 구동되는 것을 볼 수 있다.
Volume Snapshot
이후 EBS Snapshot이라고 하는 point-in-time 복사본을 만들어 Amazon EBS 볼륨의 데이터를 백업할 수 있다. 스냅샷은 증분식 백업이므로 가장 최근 스냅샷 이후 변경된 디바이스의 블록만 저장되고 스냅샷을 만드는 데 필요한 시간이 최소화되며 데이터를 복제하지 않으므로 스토리지 비용이 절약된다.
AWS EBS 볼륨에 저장된 데이터를 자동으로 백업하지 않는다. 데이터 복원력과 재해 복구를 위해 정기적으로 EBS 스냅샷을 생성하거나 Amazon Data Lifecycle Manager 또는 AWS Backup을 사용하여 자동 스냅샷 생성을 설정하는 것은 사용자의 책임이며 추후 이러한 아키텍처 구축을 통해 장애 대응 능력을 확보할 계획이다.
EBS 스냅샷은 직접 액세스할 수 없는 Amazon S3의 S3 버킷에 저장된다. Amazon EC2 콘솔 또는 Amazon EC2 API를 사용하여 스냅샷을 생성하고 관리할 수 있다.
각 스냅샷에는 (스냅샷을 만든 시점의) 데이터를 새 EBS 볼륨에 복원하는 데 필요한 모든 정보가 들어 있다. 스냅샷을 기반으로 EBS 볼륨을 생성하는 경우, 새 볼륨은 해당 스냅샷을 생성하는 데 사용된 볼륨과 정확히 일치한다. 복제된 볼륨은 사용자가 즉시 사용할 수 있도록 백그라운드에서 데이터를 로드하고 아직 로드되지 않은 데이터에 액세스하는 경우, 볼륨은 요청한 데이터를 Amazon S3에서 즉시 다운로드한 후 백그라운드에서 볼륨의 나머지 데이터를 계속해서 로드한다.
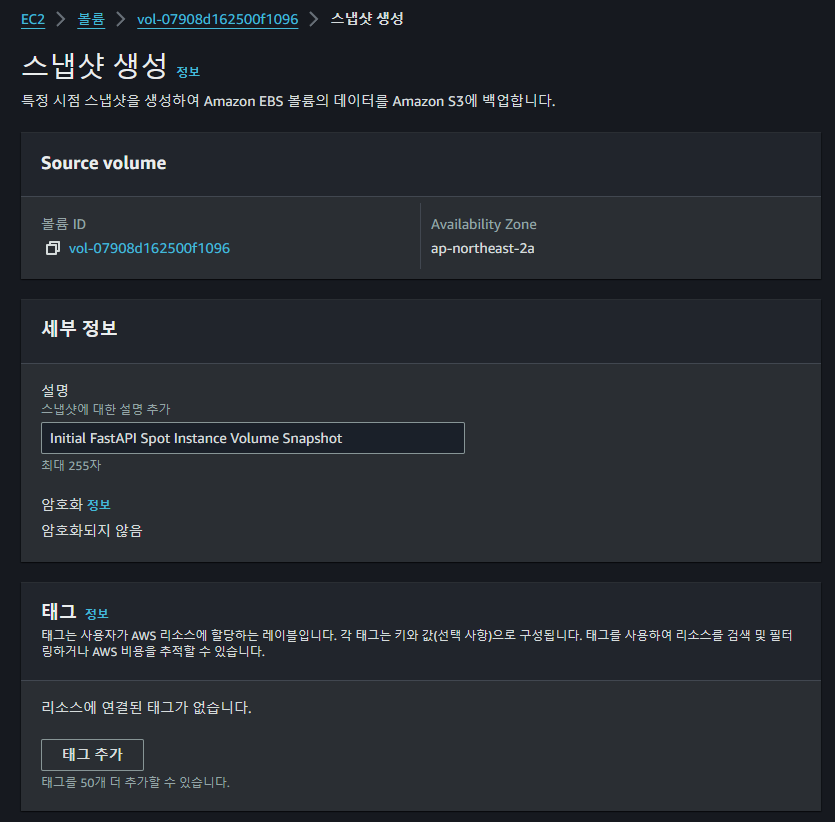 위와 같이 이미 세팅이 완료된 Volume의 SnapShot 생성을 요청하면
위와 같이 이미 세팅이 완료된 Volume의 SnapShot 생성을 요청하면
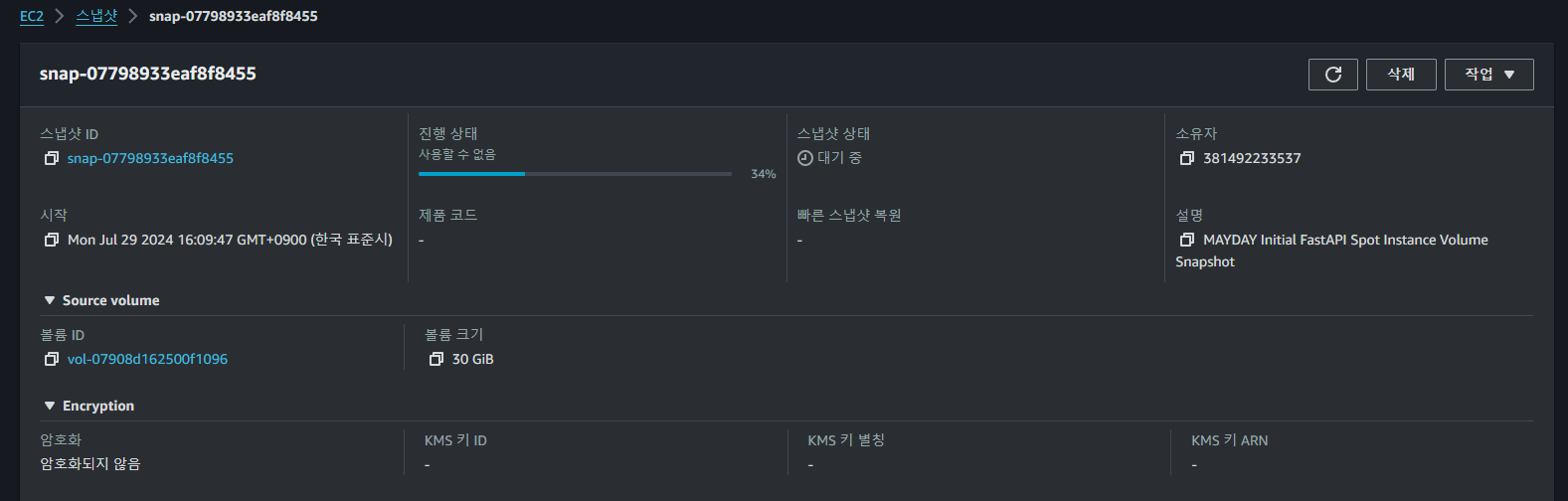 정상적으로 새로운 스냅샷이 생성되는 것을 볼 수 있으며
정상적으로 새로운 스냅샷이 생성되는 것을 볼 수 있으며
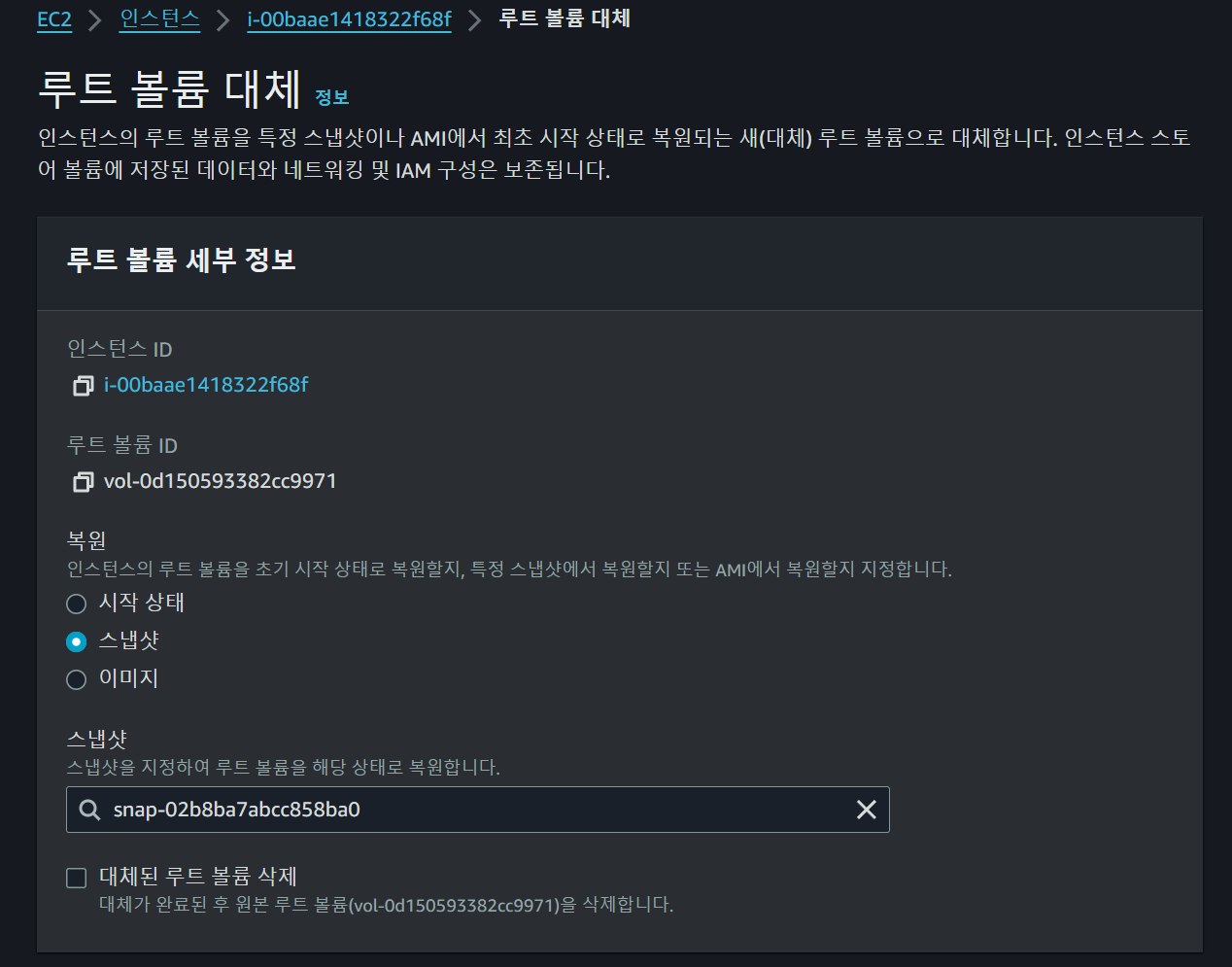 추후 새로운 Spot 요청을 통해 인스턴스를 생성하면 위와 같이 루트 볼륨을 대체하여 이전까지의 진행상황을 복원할 수 있다.
추후 새로운 Spot 요청을 통해 인스턴스를 생성하면 위와 같이 루트 볼륨을 대체하여 이전까지의 진행상황을 복원할 수 있다.
AWS FIS Spot Instance 중지 실험
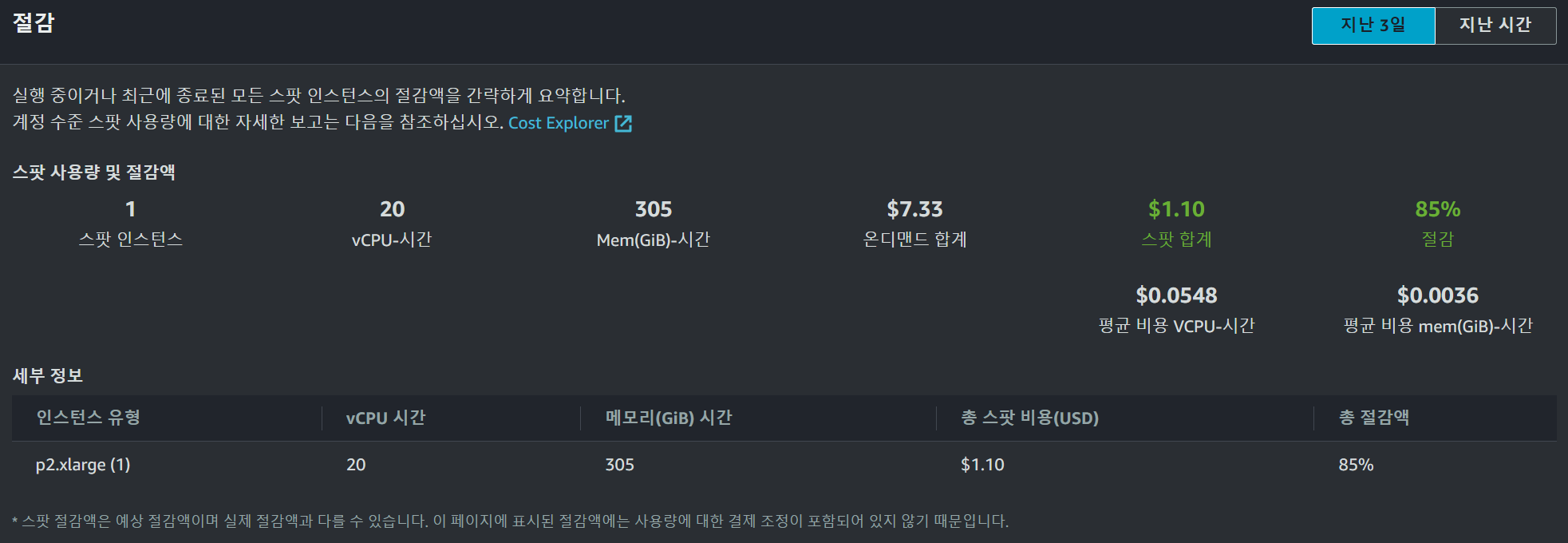 세팅을 진행할 동안의 Spot 비용은 위와 같이 발생하였다.
세팅을 진행할 동안의 Spot 비용은 위와 같이 발생하였다.
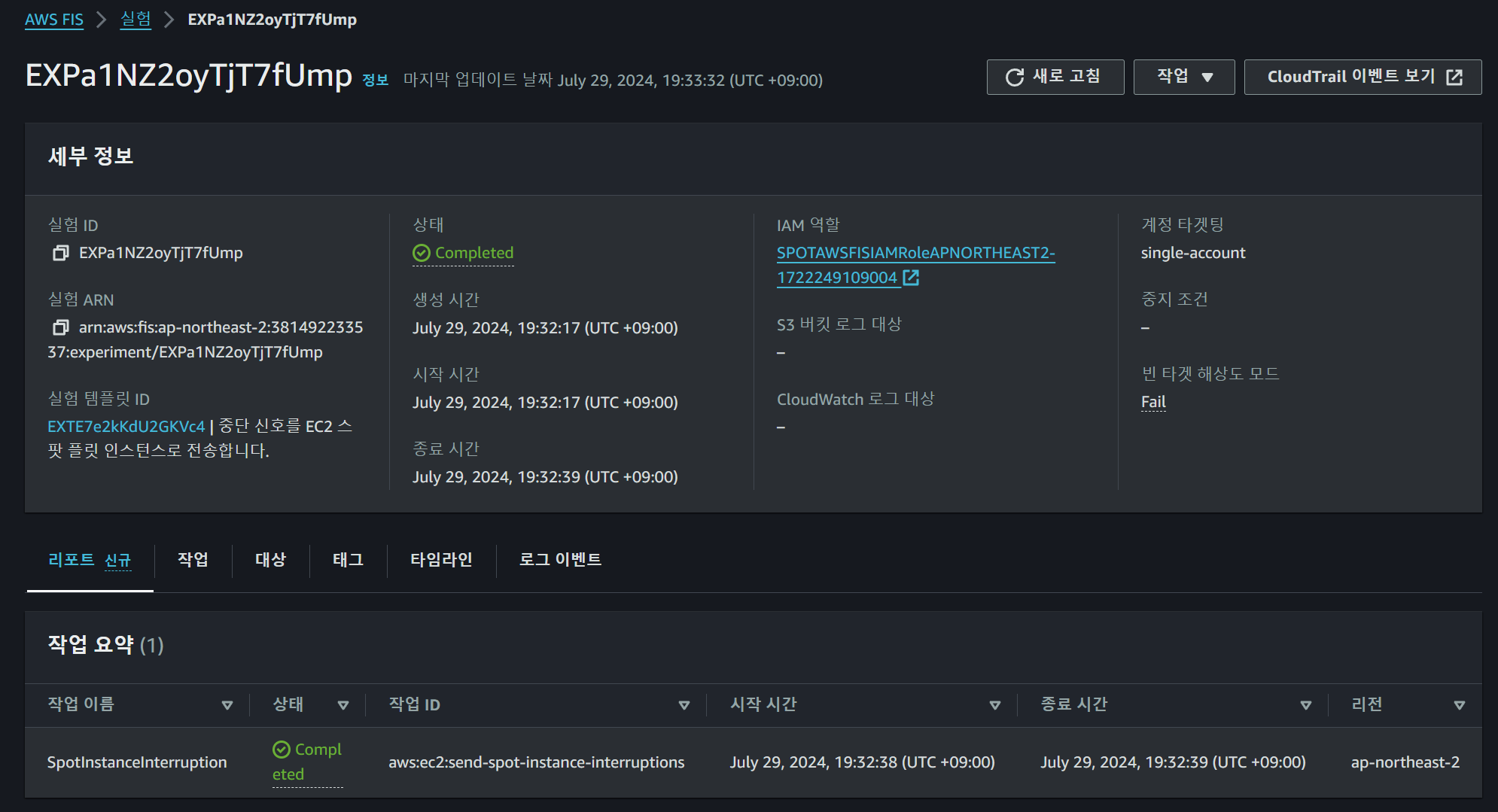 만약 실제로 제한에 도달하거나 기타 상황이 발생하였을 때 어떤 일이 발생하는지를 실험해보기 위하여 위와 같이 Spot의 중지 실험을 요청해보았고
만약 실제로 제한에 도달하거나 기타 상황이 발생하였을 때 어떤 일이 발생하는지를 실험해보기 위하여 위와 같이 Spot의 중지 실험을 요청해보았고
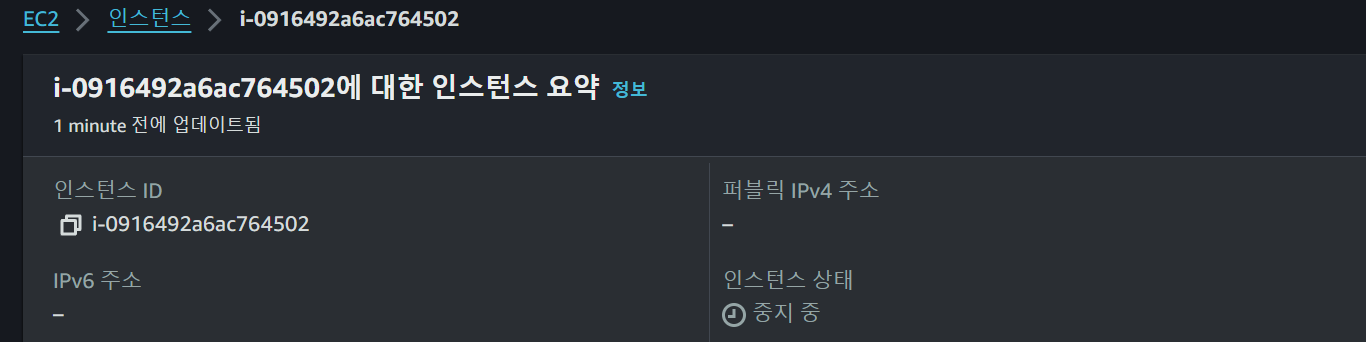 인스턴스가 갑자기 중지되는 상황을 볼 수 있었다.
인스턴스가 갑자기 중지되는 상황을 볼 수 있었다.
추후 이러한 중지 상황에서 새로운 인스턴스를 할당하여 Volume을 대체하거나 중지되기 이전에 이를 모니터링 할 수 있는 아키텍처를 설계하고 실 서비스에서 운용할 계획이다.
Github Action
name: Build and Push Docker Image
on:
push:
branches:
- main
- langchain
jobs:
build-and-push-image:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v2
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v1
- name: Login to DockerHub
uses: docker/login-action@v1
with:
username: ${{ secrets.ORG_JUDEMIN_DOCKERHUB_USERNAME }}
password: ${{ secrets.ORG_JUDEMIN_DOCKERHUB_PASSWORD }}
- name: Build and push
id: docker_build
uses: docker/build-push-action@v2
with:
push: true
tags: judemin/hearus-ai-serving:lastest
# Github Action Cache
cache-from: type=gha
cache-to: type=gha,mode=max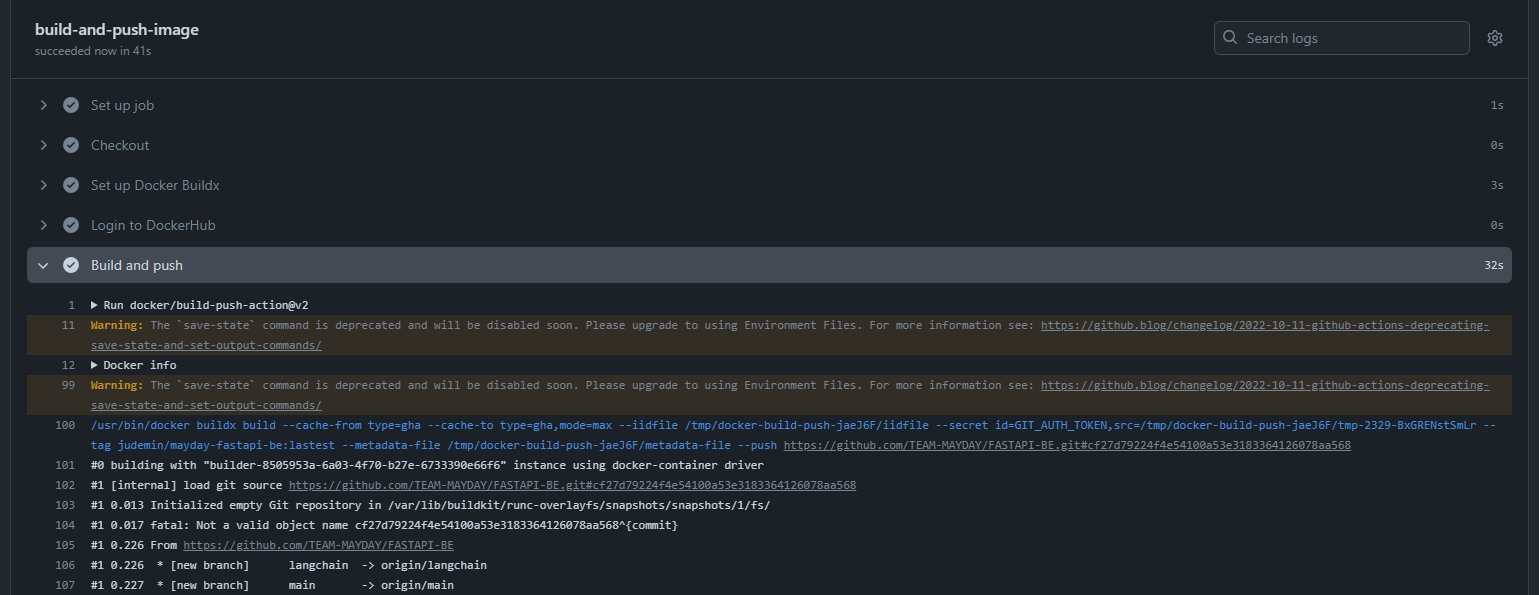 최종적으로 위와 같이 Github Action Workflow를 작성하여 CI Pipeline을 구축하였다.
최종적으로 위와 같이 Github Action Workflow를 작성하여 CI Pipeline을 구축하였다.
g4dn Spot Instance
Trouble Shooting
$ nvidia-smi -L
GPU 0: Tesla K80 (UUID: GPU-6741615b-bebb-d028-0c58-be02692bc9a9)$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2021 NVIDIA Corporation
Built on Wed_Jun__2_19:15:15_PDT_2021
Cuda compilation tools, release 11.4, V11.4.48
Build cuda_11.4.r11.4/compiler.30033411_0이전의 p2.xlarge 인스턴의 경우 Tesla K80 GPU를 가지고 있었는데
$ journalctl -u ollama -n 50
looking for compatible GPUs
[0] CUDA GPU is too old. Compute Capability detected: 3.7
no compatible GPUs were discoveredOllama의 포럼을 확인해본 결과 현 스펙의 CUDA GPU가 지원되지 않는다는 것을 확인하고 g4dn 인스턴스로 변경하였다.
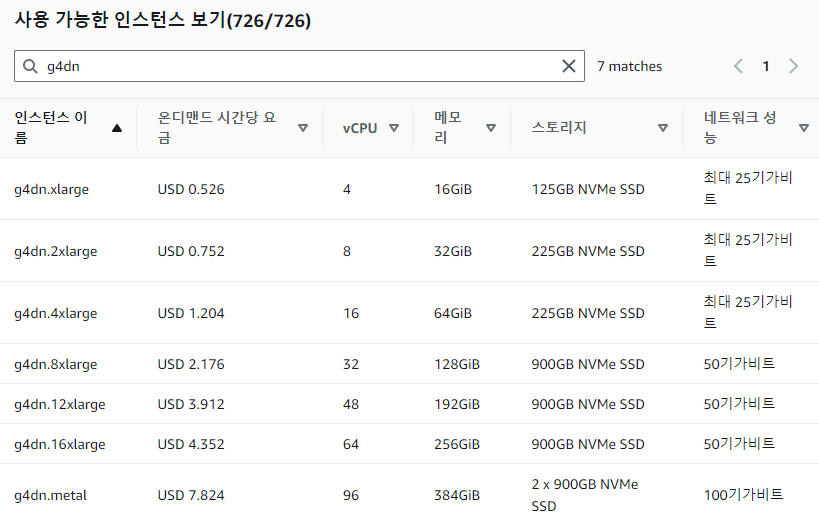
g4dn.xlarge 인스턴스의 경우 기존의 p2.xlarge보다 가격이 더 저렴한 것을 확인하였으며
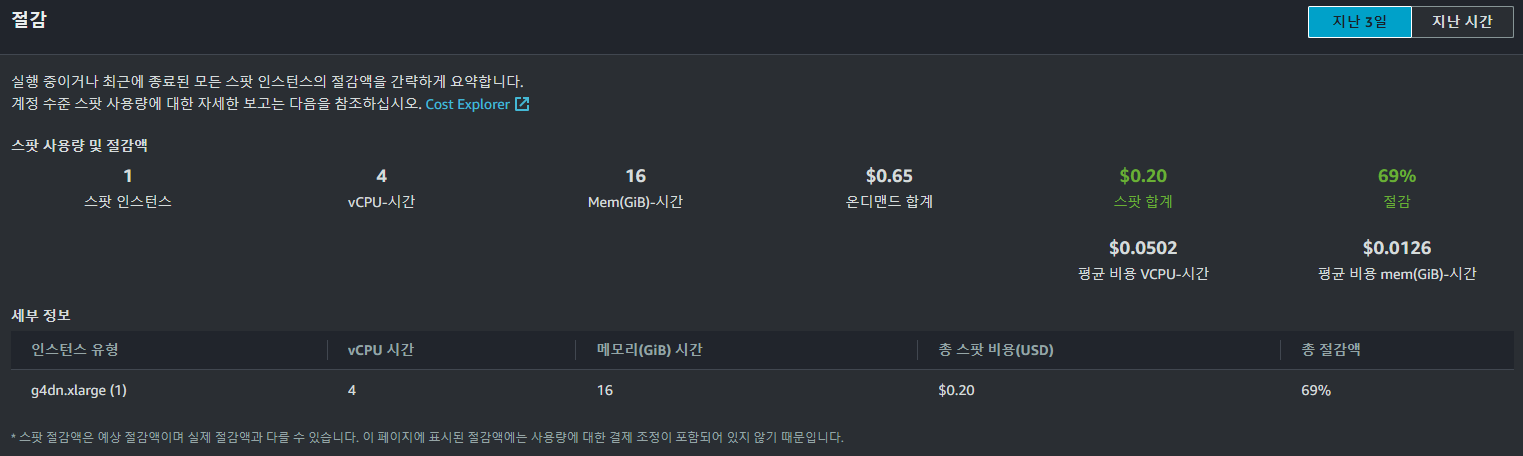 Spot Instance에서는 위와 같이 시간당 약
Spot Instance에서는 위와 같이 시간당 약 0.20 USD인 것을 확인할 수 있었다.
Spot Instance Redeployment
기존 인스턴스 AMI 생성
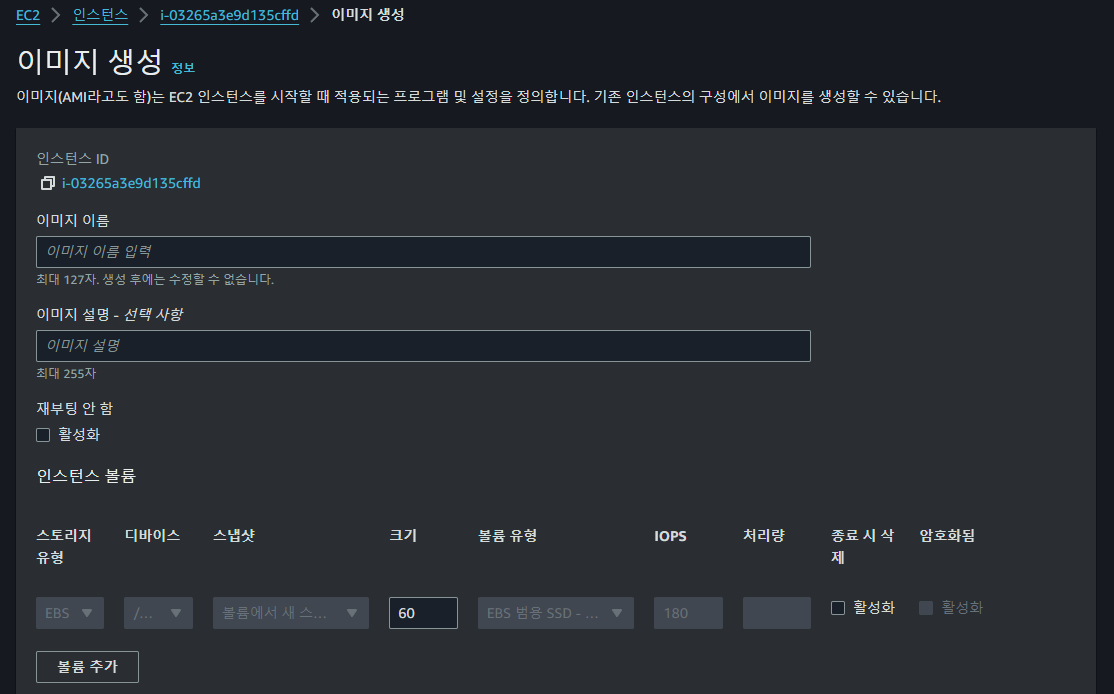 이전에 세팅이 완료된 인스턴스에 대해서 AMI를 생성하고
이전에 세팅이 완료된 인스턴스에 대해서 AMI를 생성하고
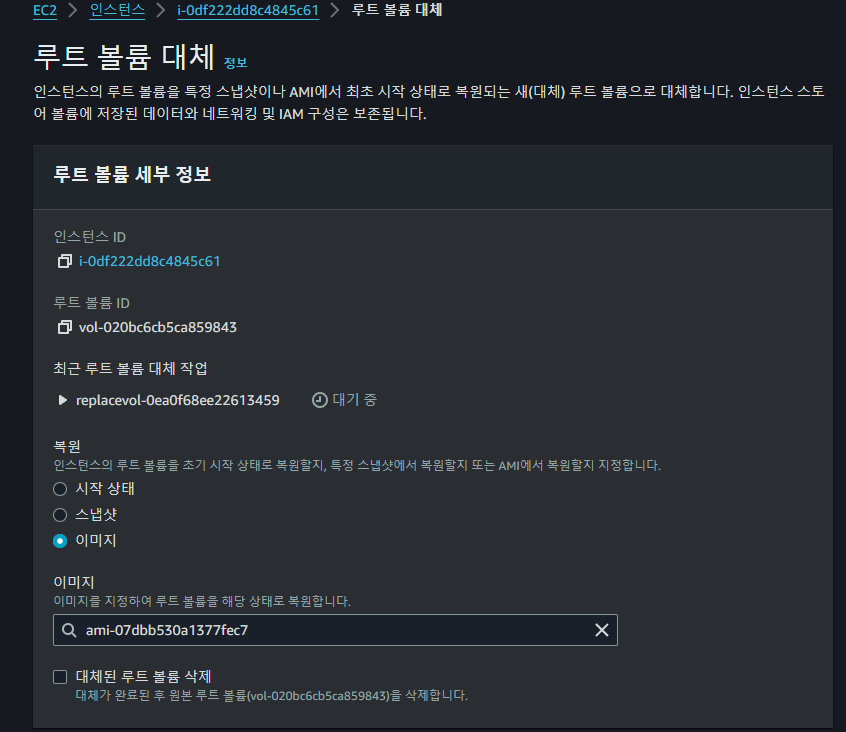 이후 새롭게 생성된
이후 새롭게 생성된 g4dn.xlarge의 루트 볼륨을 대체하여준다
$ nvidia-smi -L
GPU 0: Tesla T4 (UUID: GPU-3526055e-1672-45c9-f400-9a0ca42a5f53)
$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2021 NVIDIA Corporation
Built on Wed_Jun__2_19:15:15_PDT_2021
Cuda compilation tools, release 11.4, V11.4.48
Build cuda_11.4.r11.4/compiler.30033411_0이후 위와 같이 별도의 설정 없이 볼륨에 이미 세팅된 nvidia driver, CUDA 라이브러리를 통해 Tesla T4 GPU의 존재를 확인할 수 있었다.
Trouble Shooting : undefined symbol: cublasLtGetStatusString
import torch
from langchain_community.chat_models import ChatOllama
from langchain.prompts import PromptTemplate
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# Model Import
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if device.type == "cuda":
torch.cuda.empty_cache()
print("[LangChain] Torch CUDA Available : ", torch.cuda.is_available())
print("[LangChain] Current Device : ", device)
model_id = "llama3"
print("[LangChain] Importing LLM Model :", model_id)
llm = ChatOllama(model=model_id, device=device)
print("[LangChain]-[" + model_id + "]", llm.invoke("Hello World!"))
print("[LangChain] Imported LLM Model :", model_id)새로운 환경에서 Ollama의 구동 여부와 torch import 여부를 확인하기 위해 위와 같이 테스트 python 코드를 작성하였지만
OSError: /root/.venv/lib/python3.11/site-packages/torch/lib/../../nvidia/cublas/lib/libcublas.so.11: undefined symbol: cublasLtGetStatusString, version libcublasLt.so.11이를 실행시켰을 때 libcublasLt.so.11 관련 오류가 발생하여
pip uninstall nvidia_cublas_cu11위 명령어로 nvidia_cublas_cu11 패키지를 수동으로 삭제하여 문제를 해결해줄 수 있었다.
$ ollama run llama3
>>> hello world!
Hello there! It's great to see you! "Hello World" is a classic greeting, and I'm happy to
respond in kind. How are you today?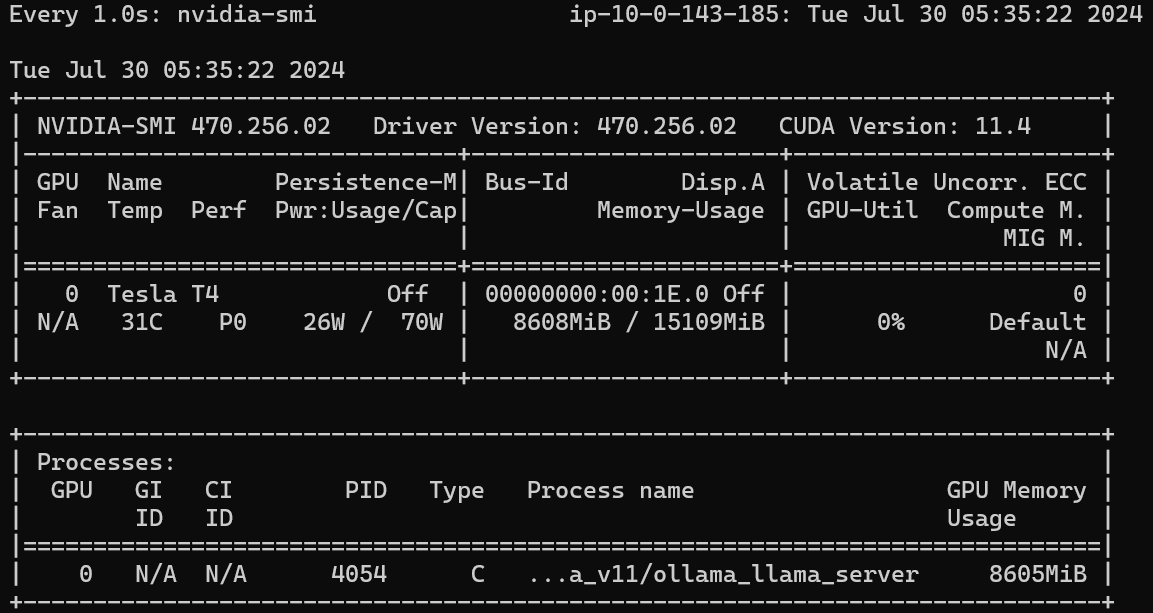 또한 Ollama를 별도로 실행시켜 GPU에 할당되는 것을 확인하였고
또한 Ollama를 별도로 실행시켜 GPU에 할당되는 것을 확인하였고
$ python3 cuda-test.py
[LangChain] Torch CUDA Available : True
[LangChain] Current Device : cuda
[LangChain] Importing LLM Model : llama3
[LangChain]-[llama3] content="Hello there! It's great to meet you. Welcome to the world of AI-powered conversations! I'm here to help answer any questions you may have, provide information on a wide range of topics, or just chat with you about your day. What's on your mind?" response_metadata={'model': 'llama3', 'created_at': '2024-07-30T05:38:02.37062917Z', 'message': {'role': 'assistant', 'content': ''}, 'done_reason': 'stop', 'done': True, 'total_duration': 1491908789, 'load_duration': 22131006, 'prompt_eval_count': 13, 'prompt_eval_duration': 105483000, 'eval_count': 56, 'eval_duration': 1320766000} id='run-c91e3925-5985-4aa7-bbe1-01bcdca70c6c-0'
[LangChain] Imported LLM Model : llama3테스트 코드도 정장적으로 동작하며
 Docker 컨테이너를 구동하여 GPU와 함께 Ollama가 정상적으로 구동되는 것을 확인할 수 있었다.
Docker 컨테이너를 구동하여 GPU와 함께 Ollama가 정상적으로 구동되는 것을 확인할 수 있었다.
Initial Configuration Commands
#### Nvidia Graphic Driver ####
sudo apt install nvidia-driver-470
sudo apt install ubuntu-drivers-common
#### CUDA Toolkit 11.4 ####
# Resolve liburcu6 package error
sudo add-apt-repository ppa:cloudhan/liburcu6
sudo apt update
sudo apt install liburcu6
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/11.4.0/local_installers/cuda-repo-ubuntu2004-11-4-local_11.4.0-470.42.01-1_amd64.deb
sudo dpkg -i cuda-repo-ubuntu2004-11-4-local_11.4.0-470.42.01-1_amd64.deb
sudo apt-key add /var/cuda-repo-ubuntu2004-11-4-local/7fa2af80.pub
sudo apt-get update
sudo apt-get -y install cuda
#### Docker ####
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
sudo systemctl | grep docker
# nvidia-docker runtime
# NVIDIA GPG 키 추가 및 저장소 설정
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
# 패키지 리스트 업데이트 및 nvidia-docker2 설치
sudo apt-get update
sudo apt-get install -y nvidia-docker2
# Docker 데몬 재시작
sudo systemctl restart docker
#### Python ####
sudo apt-get install --upgrade python3
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt install python3.11 -y
sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.11 1
sudo apt-get install python3.11-venv
python3.11 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
# CUDA 11.4 버전에 맞는 torch 설치
pip install torch==1.13.0
pip uninstall nvidia_cublas_cu11
#### Ollama ####
curl -fsSL https://ollama.com/install.sh | sh
ollama pull llama3만약 Volume, AMI 등이 초기화되었을 때 초기 위 명령어들을 통해 초기 세팅을 완료할 수 있다.
References
https://inexperiencedhuman.tistory.com/3
https://velog.io/@hope1213/GPU%EC%84%9C%EB%B2%84%EB%A5%BC-Spot-Instance-%ED%99%9C%EC%9A%A9%ED%95%B4-%EC%A0%80%EB%A0%B4%ED%95%98%EA%B2%8C-%EC%82%AC%EC%9A%A9%ED%95%B4%EB%B3%B4%EC%9E%90-1
https://velog.io/@hope1213/AWS%EC%97%90%EC%84%9C-GPU%EC%84%9C%EB%B2%84%EB%A5%BC-%EC%A0%80%EB%A0%B4%ED%95%98%EA%B2%8C-%EC%82%AC%EC%9A%A9%ED%95%B4%EB%B3%B4%EC%9E%90-2
https://velog.io/@taekkim/AWS-Spot-instances-GPU-%EC%9C%A0%ED%98%95-%EB%B0%8F-%EA%B0%80%EA%B2%A9-%EC%A0%95%EB%A6%AC
https://developnote-blog.tistory.com/163
https://data-engineer-tech.tistory.com/21
