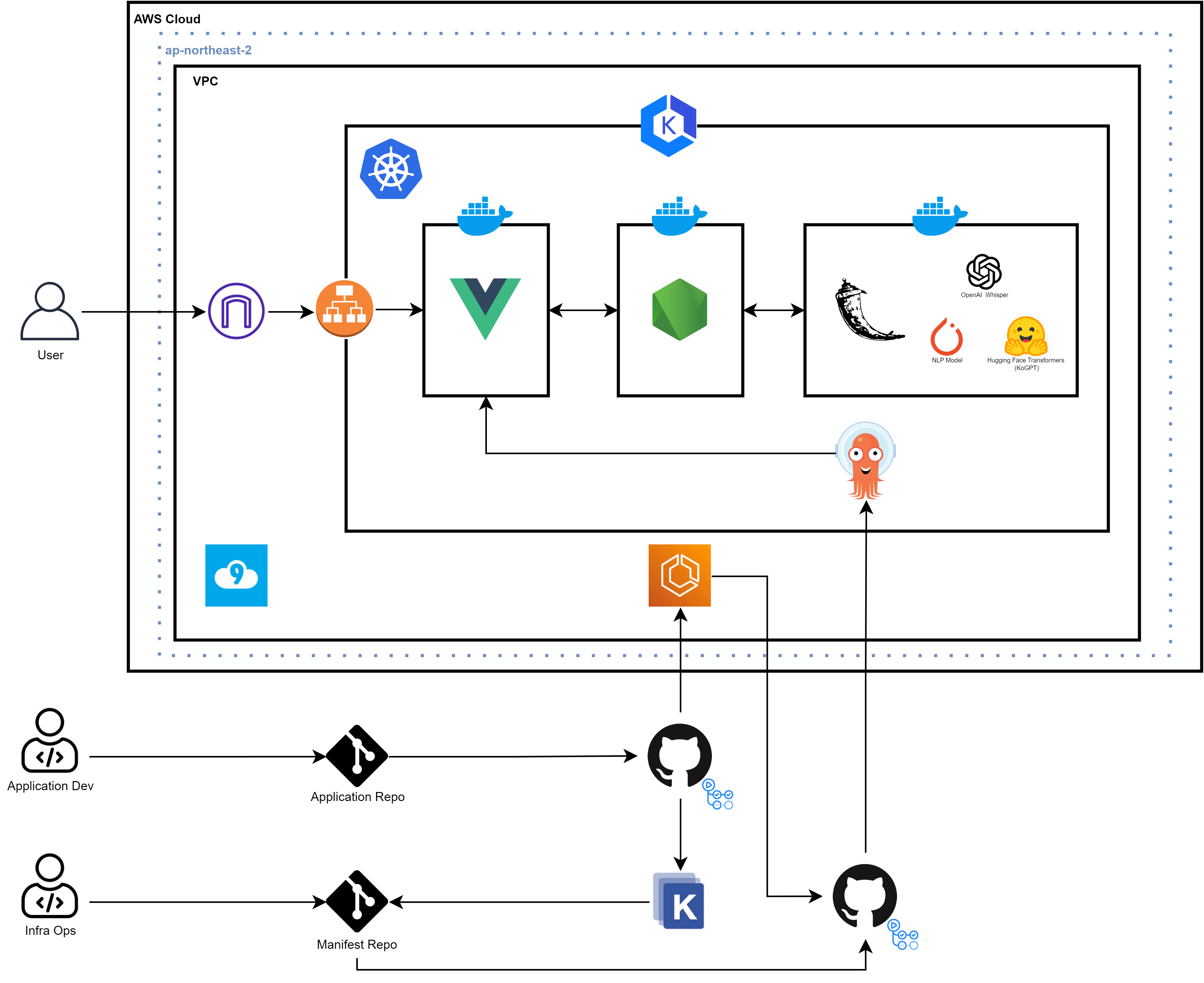
 현 단계까지 구현된 전체 구조도는 위와 같다.
현 단계까지 구현된 전체 구조도는 위와 같다.
Flask 서버의 경우 3개의 built-in 인공지능 모델을 사용하고 있다.
또한 현재 GithubAction, Kustomzie, ECR, ArgoCD를 활용한 파이프라인은 Vue 앱만 배포하고 있다.
Hugging Face Transformers
Flask
pip install transformers
pip install accelerateHugging Face Transformers를 사용하기 위해 먼저 위와 같은 패키지를 설치한다.
Flask==3.0.0
Flask_cors==4.0.0
deepspeech==0.9.3
numpy==1.19.4
pydub
transformers
accelerateTroubleShooting : Could not install packages due to an OSError
ERROR: Could not install packages due to an OSError: [Errno 2] No such file or directory: 'C:\\..\\transformers\\models\\deprecated\\trajectory_transformer\\convert_trajectory_transformer_original_pytorch_checkpoint_to_pytorch.py'
HINT: This error might have occurred since this system does not have Windows Long Path support enabled. You can find information on how to enable this at https://pip.pypa.io/warnings/enable-long-paths이후 accelerate관련 에러는 아래와 같이 LongPathsEnabled으로 해결할 수 있다.
New-ItemProperty -Path "HKLM:\SYSTEM\CurrentControlSet\Control\FileSystem" `
-Name "LongPathsEnabled" -Value 1 -PropertyType DWORD -Forceskt/kogpt2-base-v2
...
from models.hugging_face import add_comment
...
@app.route("/process", methods=["POST"])
def process():
if not request.is_json:
return jsonify({"error": "Missing JSON in request"}), 400
try:
text_data = request.get_json()
processed_text = process_text(text_data)
processed_text = add_comment(processed_text)
return jsonify(processed_text)
except json.JSONDecodeError as e:
return jsonify({"error": "Invalid JSON"}), 400이후 skt/kogpt2-base-v2 사용을 위해 app.py에 위와 같이 hugging_face를 import해주고
from transformers import GPT2LMHeadModel, PreTrainedTokenizerFast
import torch
# KoGPT2 모델과 토크나이저 로드
model_name = "skt/kogpt2-base-v2"
model = GPT2LMHeadModel.from_pretrained(model_name)
tokenizer = PreTrainedTokenizerFast.from_pretrained(
"skt/kogpt2-base-v2",
bos_token="</s>",
eos_token="</s>",
unk_token="<unk>",
pad_token="<pad>",
mask_token="<mask>",
)
def create_prompt(keyword, subject):
return f"대학교 '{subject}' 과목에서 다루는 '{keyword}'의 의미는, "
def generate_text(prompt, max_length):
# Tokenize Prompt
input_ids = tokenizer.encode(prompt, return_tensors="pt")
# Generate Text
with torch.no_grad():
output = model.generate(
input_ids, max_length=max_length, num_return_sequences=1
)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
return generated_text
def add_comment(app, text_data):
for item in text_data.get("unProcessedText", []):
if "comment" in item[1]:
# 전공을 판별하는 것은 추후 개발될 기능
prompt = create_prompt(item[0], "전공")
# 현재 Default Prompt는 아래와 같이 설정
prompt = item[0] + "라는 단어의 사전적 의미는, "
try:
input_ids = tokenizer.encode(prompt, return_tensors="pt")
gen_ids = model.generate(
input_ids,
max_length=64,
repetition_penalty=2.0,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
use_cache=True,
)
generated = tokenizer.decode(gen_ids[0])
# Strip text from Prompt
processed_text = generated[len(prompt) :].strip()
end_idx = processed_text.find("\n")
if end_idx != -1:
processed_text = processed_text[:end_idx].strip()
app.logger.info(generated)
item[2] = processed_text
except Exception as e:
print(f"Error in generating text: {e}")
return text_data위 코드를 통해 모델을 불러와 기능을 구현할 수 있다.
kakaobrain/kogpt
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained(
"kakaobrain/kogpt",
revision="KoGPT6B-ryan1.5b-float16", # or float32 version: revision=KoGPT6B-ryan1.5b
bos_token="[BOS]",
eos_token="[EOS]",
unk_token="[UNK]",
pad_token="[PAD]",
mask_token="[MASK]",
)
model = AutoModelForCausalLM.from_pretrained(
"kakaobrain/kogpt",
revision="KoGPT6B-ryan1.5b-float16", # or float32 version: revision=KoGPT6B-ryan1.5b
pad_token_id=tokenizer.eos_token_id,
torch_dtype="auto",
low_cpu_mem_usage=True,
).to(device="cuda", non_blocking=True)
_ = model.eval()
def create_prompt(keyword, subject):
return (
f"대한민국의 대학교 '{subject}' 과목에서 다루는 '{keyword}'에 대한 자세한 설명을 제공해줘.\n"
"아래의 조건을 만족하는 답변이어야 해.\n"
"이 설명은 대학생들이 해당 내용을 이해하는 데 도움이 되어야 해.\n"
"설명은 요약식으로 100단어 이내로 제공해.\n"
"꼭 설명이 길 필요는 없어 필요한 내용만 간략하게 제공해줘.\n"
"설명 이후에 공식이나 코드 등 예시가 필요한 설명의 경우 간략한 예시도 포함해줘.\n"
)
def add_comment(text_data):
for item in text_data.get("unProcessedText", []):
if "comment" in item[1]:
# subject의 경우 추후 NLP 모델에서 별도로 처리
prompt = create_prompt(item[0], "전공")
with torch.no_grad():
tokens = tokenizer.encode(prompt, return_tensors="pt").to(
device="cuda", non_blocking=True
)
gen_tokens = model.generate(
tokens, do_sample=True, temperature=0.8, max_length=150
)
generated = tokenizer.batch_decode(gen_tokens)[0]
item[2] = generated
return text_data
하지만 skt/kogpt2-base-v2는 정확도가 부족하여 kakaobrain/kogpt를 사용하는 방법도 고려하였지만 패키지 충돌 문제와 메모리 문제로 이는 다른 팀원이 담당하여 정확도를 높일 계획이다.
find . | grep -E "(__pycache__|\.pyc|\.pyo$)" | xargs rm -rf
python3 -m pip install -U "huggingface_hub[cli]"
huggingface-cli delete-cache또한 추가적으로 huggingface-cli을 통해 기존 모델의 캐시를 삭제할 수 있다.
키워드 요청 테스트
def process_text(text_data):
for item in text_data.get("unProcessedText", []):
if "라이트" in item[0]:
item[1] = "highlight"
elif "설명" in item[0]:
item[1] = "comment"
item[2] = "설명이 포함된 단어는 설명이 추가됩니다"
elif "프로그래밍" in item[0]:
item[1] = "comment"
item[2] = ""
elif "테스트" in item[0]:
item[1] = "comment"
item[2] = ""
elif "인공지능" in item[0]:
item[1] = "comment"
item[2] = ""
elif "강의" in item[0]:
item[1] = "comment"
item[2] = ""
elif "데이터" in item[0]:
item[1] = "comment"
item[2] = ""
elif "파이썬" in item[0]:
item[1] = "comment"
item[2] = ""
elif "대학" in item[0]:
item[1] = "comment"
item[2] = ""
return text_data현재 구현된 모델의 로직을 테스트하기 위해 위와 같이 NLP 키워드 로직을 수정하였다.
UI 개선
<template>
<div class="logo-container" @click="isRecording ? stopRecording() : startRecording()">
<img :src="isRecording ? recordingLogoImageSrc : logoImageSrc" alt="Logo" class="card-item logo-img mb-3"
:class="{ 'animated-logo': isRecording }" />
</div>
<div class="background d-flex justify-content-center align-items-center vh-100">
<div class="script-container text-center">
<div class="scrollable-text">
<div ref="scrollableText" class="scrollable-content">
....scrollable-text {
font-family: 'Gothic A1', sans-serif;
width: 100%;
height: 100%;
padding: 20px;
box-sizing: border-box;
font-size: 15px;
background-color: #1e1e1e;
overflow: hidden;
}
.scrollable-content {
height: calc(100% - 40px);
overflow-y: scroll;
scrollbar-width: thin;
scrollbar-color: #337ea9 #1e1e1e;
}
.scrollable-content::-webkit-scrollbar {
width: 12px;
}
.scrollable-content::-webkit-scrollbar-track {
background-color: #1e1e1e;
border-radius: 20px;
}
.scrollable-content::-webkit-scrollbar-thumb {
background-color: #337ea9;
border-radius: 10px;
}
...
.logo-container {
position: absolute;
top: 5%;
left: 50%;
transform: translate(-50%, -5%);
cursor: pointer;
}
.logo-img {
border-radius: 100px;
width: 100px;
}
@keyframes scaleUp {
0% {
transform: scale(1);
opacity: 1;
}
50% {
transform: scale(1.05);
opacity: 0.8;
}
100% {
transform: scale(1);
opacity: 1;
}
}
.animated-logo {
animation: scaleUp 1s infinite;
}또한 최종적으로 UI를 개선하여 사용자 편의성을 증대하였다.
현재는 마이크 품질, Whisper 모델 레벨 등으로 낮은 음성인식 인식률을 추후 개선할 게획이다.