
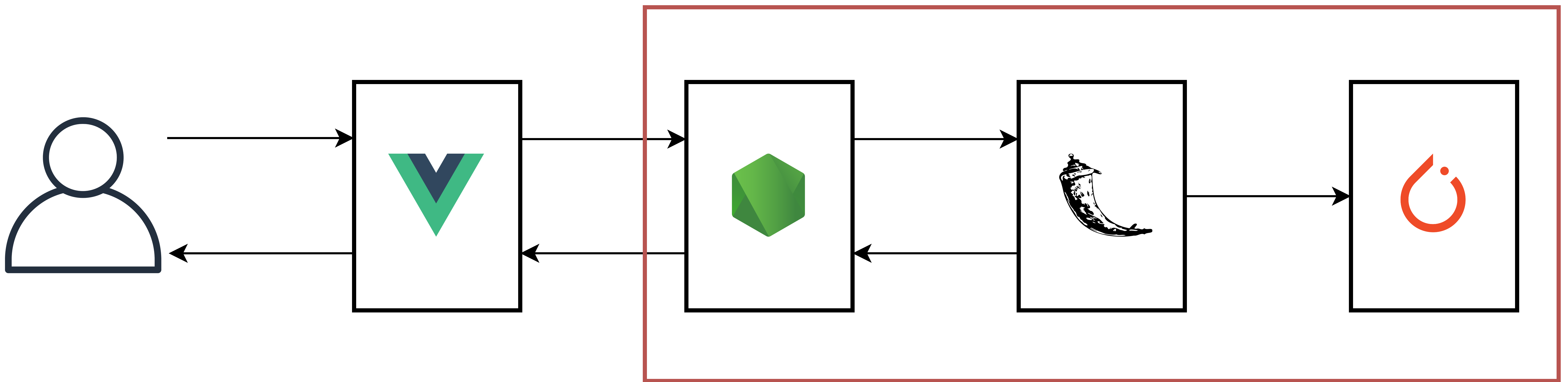
인공지능 서빙 로직 구현
Flask Server
/HEARUS-AI-SERVING
/models
__init__.py
stt_model.py
nlp_module.py
app.py위 구조와 같이 추후 개발될 인공지능 모델을 서빙할 수 있는 flask 서버를 구축한다
pip install Flask
pip install torch
pip install flask_corsFlask, torch, flask_cors 파이썬 모듈을 설치한다.
from flask import Flask, request
from flask_cors import CORS
from models.stt_model import STTModel
from models.nlp_module import process_text
app = Flask(__name__)
CORS(app)
stt_model = STTModel(
"./deepspeech/deepspeech-0.9.3-models.pbmm",
"./deepspeech/deepspeech-0.9.3-models.scorer",
)
@app.route("/transcribe", methods=["POST"])
def transcribe():
audio_file = request.files["audio"]
transcription = stt_model.transcribe(audio_file)
processed_text = process_text(transcription)
return processed_text
if __name__ == "__main__":
app.run(port=5001)
이후 5001번 포트에서 /transcribe 라우터로 요청받을 서버를 생성한다
pip install deepspeech
curl -LO https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/deepspeech-0.9.3-models.pbmm
curl -LO https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/deepspeech-0.9.3-models.scorer인공지능 모델이 개발되기 이전이기 떄문에 DeepSpeeck 릴리즈 버전을 설치한다.
https://github.com/mozilla/DeepSpeech/releases/tag/v0.9.3
이때 curl 명령어로 접근할 수 없으면 위 주소에서 수동으로 다운로드한다.
import deepspeech
import numpy as np
import wave
class STTModel:
def __init__(self, model_path, scorer_path):
self.model = deepspeech.Model(model_path)
self.model.enableExternalScorer(scorer_path)
def transcribe(self, audio_file):
with wave.open(audio_file, "rb") as w:
frames = w.getnframes()
buffer = w.readframes(frames)
data16 = np.frombuffer(buffer, dtype=np.int16)
return self.model.stt(data16)
DeepSpeech를 통해 audioFile을 처리하는 모듈을 생성하고
import re
def process_text(text):
# 텍스트에서 특정 패턴이나 키워드를 찾고 처리하는 로직
# 예: 숫자를 찾아서 '[숫자]'로 대체
processed_text = re.sub(r"\d+", "[숫자]", text)
return processed_text
자연어 처리를 테스트 해볼 수 있게 위와 같은 모듈을 생성한다.
Express Server
npm install axiosflask 서버와 통신할 수 있도록 axios 패키지를 설치한다.
const socketIO = require('socket.io');
const fs = require('fs');
const FormData = require('form-data');
const axios = require('axios');
const { v4: uuidv4 } = require('uuid');
function initSocket(server, app) {
...
clientSocket.on('audioData', async (audioBlob) => {
const isDeleted = false;
const tempFilePath = `./temp/${uuidv4()}.wav`;
try {
fs.writeFileSync(tempFilePath, audioBlob);
const form = new FormData();
form.append('audio', fs.createReadStream(tempFilePath));
const response = await axios.post('http://127.0.0.1:5001/transcribe', form, { headers: form.getHeaders() });
console.log(response.data);
socket.emit('recognitionResult', response.data);
isDeleted = true;
fs.unlinkSync(tempFilePath);
} catch (error) {
if (!isDeleted)
fs.unlinkSync(tempFilePath);
console.error('Error in transcription:', error);
}
});
...이후 socket 내에 위와 같이 Vue로부터 넘겨받은 데이터를 temp audio 파일로 생성해 API 요청으로 넘겨서 처리한 후 처리된 텍스트 데이터를 받아서 다시 socket에 emit해주는 로직을 작성한다.
이떄 isDeleted을 통해 try-catch문에서 에러가 발생하더라도 temp audio 파일을 삭제하여 메모리 낭비를 방지한다.
Error in transcription: AxiosError: connect ECONNREFUSED ::1:5001
at Function.AxiosError.from (C:...\node_modules\axios\dist\node\axios.cjs:837:14)만약 localhost:5001로 axios를 통해 API 요청을 했을 때 위와 같은 오류가 발생한다면 아래와 같이 127.0.0.1:5001로 요청을 보내 해결할 수 있다.
await axios.post('http://127.0.0.1:5001/transcribe', form, { headers: form.getHeaders() });Trouble Shooting
webm to wav
File "C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.8_3.8.2800.0_x64__qbz5n2kfra8p0\lib\wave.py", line 131, in initfp
raise Error('file does not start with RIFF id')
wave.Error: file does not start with RIFF id이전 코드와 같이 전체 서비스를 실행시키면 위와 같이 유효하지 않은 파일이라는 에러가 발생한다. 이는 format과 codec 문제이다.
npm install fluent-ffmpeg
npm i @ffmpeg-installer/ffmpeg이를 해결하기 위해서 epress에서 사용할 ffmpeg 관련 패키지를 설치한다.
const ffmpegPath = require('@ffmpeg-installer/ffmpeg').path;
const ffmpeg = require('fluent-ffmpeg');
ffmpeg.setFfmpegPath(ffmpegPath);
async function convertToWav(inputFilePath, outputFilePath) {
return new Promise((resolve, reject) => {
ffmpeg(inputFilePath)
.toFormat('wav')
.on('end', () => {
console.log('Conversion Finished');
resolve(outputFilePath);
})
.on('error', (err) => {
console.error(err);
reject(err);
})
.save(outputFilePath);
});
}이후 위와 같이 기본적으로 frontend에서 mediaRecorder로 넘겨주는 음성 데이터는 webm 포맷과 opus 코덱을 사용하므로 위와 같은 변환코드를 작성한다.
...
io.on('connection', (clientSocket) => {
console.log('Socket Client connected');
clientSocket.on('clientData', (data) => {
console.log('Data from client ' + data);
});
clientSocket.on('audioData', async (audioBlob) => {
const tempInputPath = `./temp/${uuidv4()}.webm`;
const tempOutputPath = `./temp/${uuidv4()}.wav`;
try {
fs.writeFileSync(tempInputPath, audioBlob);
await convertToWav(tempInputPath, tempOutputPath);
const form = new FormData();
form.append('audio', fs.createReadStream(tempOutputPath));
const response = await axios.post('http://127.0.0.1:5001/transcribe', form, { headers: form.getHeaders() });
console.log(response.data);
socket.emit('recognitionResult', response.data);
await fs.unlinkSync(tempInputPath);
await fs.unlinkSync(tempOutputPath);
} catch (error) {
if (fs.existsSync(tempInputPath))
fs.unlinkSync(tempInputPath);
if (fs.existsSync(tempOutputPath))
fs.unlinkSync(tempOutputPath);
console.error('Error in transcription:', error);
}
});이후 변환을 uuid4를 통해 임의로 filePath을 설정하고 변환을 진행한다.
Invalid data found when processing input
Error: ffmpeg exited with code 1: ./temp/107a691e-7bc8-4996-96a2-6de2c958a155.webm: Invalid data found when processing input
at ChildProcess.<anonymous> (C:\Users\judem\Git\HEARUS\HEARUS-BACKEND\node_modules\fluent-ffmpeg\lib\processor.js:182:22)
at ChildProcess.emit (node:events:520:28)
at Process.ChildProcess._handle.onexit (node:internal/child_process:291:12)하지만 첫번째 음성 변환 요청 이후 위와 같은 에러가 발생한다.
이는 express의 fs의 동시성 접근 문제거나 ffmpeg문제일 수도 있기 때문에 현재 socke으로 전달받은 blob 데이터를 Queue를 통해 처리한다.
npm install better-queueconst socketIO = require('socket.io');
const fs = require('fs');
const FormData = require('form-data');
const axios = require('axios');
const { v4: uuidv4 } = require('uuid');
const ffmpegPath = require('@ffmpeg-installer/ffmpeg').path;
const ffmpeg = require('fluent-ffmpeg');
ffmpeg.setFfmpegPath(ffmpegPath);
function delay(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
function convertToWav(inputFilePath, outputFilePath) {
console.log("convertToWav : " + inputFilePath);
return new Promise((resolve, reject) => {
ffmpeg(inputFilePath)
.toFormat('wav')
.on('end', () => {
console.log('Conversion Finished');
resolve(outputFilePath);
})
.on('error', (err) => {
reject(err);
})
.save(outputFilePath);
});
}
function processAudioData(clientSocket, audioBlob) {
return new Promise(async (resolve, reject) => {
const uuidString = uuidv4();
const tempInputPath = `./temp/${uuidString}.webm`;
const tempOutputPath = `./temp/${uuidString}.wav`;
try {
// Force fs.writefile to Sync
const buffer = Buffer.from(audioBlob);
await fs.promises.writeFile(tempInputPath, buffer);
console.log(tempInputPath);
await convertToWav(tempInputPath, tempOutputPath);
const form = new FormData();
form.append('audio', fs.createReadStream(tempOutputPath));
const response = await axios.post('http://127.0.0.1:5001/transcribe', form, { headers: form.getHeaders() });
console.log("Transcription result : " + response.data);
clientSocket.emit('recognitionResult', response.data);
fs.unlinkSync(tempInputPath);
fs.unlinkSync(tempOutputPath);
resolve();
} catch (error) {
if (fs.existsSync(tempInputPath)) fs.unlinkSync(tempInputPath);
if (fs.existsSync(tempOutputPath)) fs.unlinkSync(tempOutputPath);
console.error('Error in transcription ', error);
reject(error);
}
});
}
module.exports = processAudioData;Queue로 데이터 변환과 인공지능 서빙 서버 요청을 위해 processAudioData 모듈을 별도로 생성하고 위와 같이 주요 로직을 내부적으로 구현한다.
const socketIO = require('socket.io');
const Queue = require('better-queue');
const processAudioData = require("./processAudioData");
function initSocket(server, app) {
console.log('Configuring Socket');
const io = socketIO(server, {
cors: {
credentials: true,
},
allowEIO3: true,
});
app.set('io', io);
io.on('connection', (clientSocket) => {
console.log('Socket Client connected');
clientSocket.on('clientData', (data) => {
// console.log('Data from client ' + data);
});
const audioQueue = new Queue((task, done) => {
processAudioData(task.clientSocket, task.audioBlob)
.then(() => done())
.catch(err => done(err));
}, { concurrent: 1 });
clientSocket.on('audioData', async (audioBlob) => {
audioQueue.push({ clientSocket, audioBlob });
});
clientSocket.on('disconnect', () => {
console.log('Socket Client disconnected');
});
});
}
module.exports = initSocket;또한 위와 같이 audioQueue를 구현하여 각 socket의 emit 요청을 처리한다.
이때 concurrent를 1로 설정하여 fs나 ffmpeg의 충돌을 방지한다.
ffmpeg -i ./temp/d7e5814d-855a-4f59-afb2-f510fa4e2f4d.webm ./temp/output.wav하지만 Queue를 통한 처리 이후에도 동일한 에러가 지속적으로 발생하였다.
이때 직접 파일을 실행하고 ffmpeg를 통해 직접적으로 변환을 시도한 결과 frontend로부터의 데이터에 대한 무결성이 만족되지 않음을 알 수 있었다.
data() {
return {
clientToken: '',
socket: null,
recognitionResult: '',
scriptData: ["음성 인식을 시작해보세요"],
stream: null,
mediaRecorder: null,
isRecording: false,
resCnt: 0,
logoImageSrc: require('@/assets/logo.png'),
};
},
computed: {
scriptDataText() {
return this.scriptData.join(' ');
},
},
methods: {
initMediaRecorder() {
const options = { mimeType: 'audio/webm;codecs=opus' };
this.mediaRecorder = new MediaRecorder(this.stream, options);
this.mediaRecorder.ondataavailable = (event) => {
if (event.data.size > 0) {
this.socket.emit('clientData', this.clientToken);
this.socket.emit('audioData', event.data);
}
};
this.mediaRecorder.start();
},
async startRecording() {
this.stream = await navigator.mediaDevices.getUserMedia({ audio: true });
this.initMediaRecorder();
this.scriptData = [' '];
this.resCnt = 0;
this.isRecording = true;
this.sendAudioDataInterval = setInterval(async () => {
await this.mediaRecorder.requestData();
await this.mediaRecorder.stop();
this.initMediaRecorder();
}, 2000);
},이는 기존의 코드에서 mediaRecorder가 데이터를 쌓고 있는 도중에 requestData()를 통해 데이터를 요청하면 blob 형태의 데이터가 두번째 부터는 손상되어 첫번째 시도는 항상 성공하지만 두번째 시도는 실패한다는 것을 확인하였다.
따라서 위와 같이 stream울 전역에서 관리하며 특정 조건 (현재는 2000ms)마다 mediaRecorder를 재시작하며 데이터를 emit 해줄 수 있도록 로직을 변경하였다.
dockerize
pip list위 명령어를 통해 설치된 파이썬 모듈의 버전과 정보를 확인한다.
Flask==3.0.0
Flask_cors==4.0.0
deepspeech==0.9.3
numpy==1.19.4requirements.txt를 위와 같이 별도로 작성하여 모듈 관리를 용이하게 한다.
FROM python:3.9
COPY requirements.txt requirements.txt
RUN pip install -r requirements.txt
COPY . /app
WORKDIR /app
CMD ["python3", "-m", "flask", "run", "--host=0.0.0.0"]Dockerfile을 위와 같이 작성하고 아래 명령어들을 통해 이를 빌드하고 Docker Hub에 Push까지 해주면 flask 서버가 일차적으로 기능과 함께 구현이 완료되었다.
docker build -t judemin/hearus-flask-serving .
docker run -it --rm -p 5001:5001 --name hearus-flask-serving judemin/hearus-flask-serving
docker push judemin/hearus-flask-serving