Building Dataset and Evaluating Method for Korean-English Idiom in NMThttps://github.com/Judy-Choi/KISS
-
Korean Title : 관용구 기계번역을 위한 한-영 데이터셋 구축 및 평가 방법
(KCC 2020 (Korean Information Science Society Conference)) -
Download Paper (Korean)
KCC_관용구 기계번역을 위한 한-영 데이터셋 구축 및 평가 방법.pdf
-
Download LangCon2020 Slide PPT (Korean)
1. Abstract
- Translating idiom sometimes have some problems
- example
- example
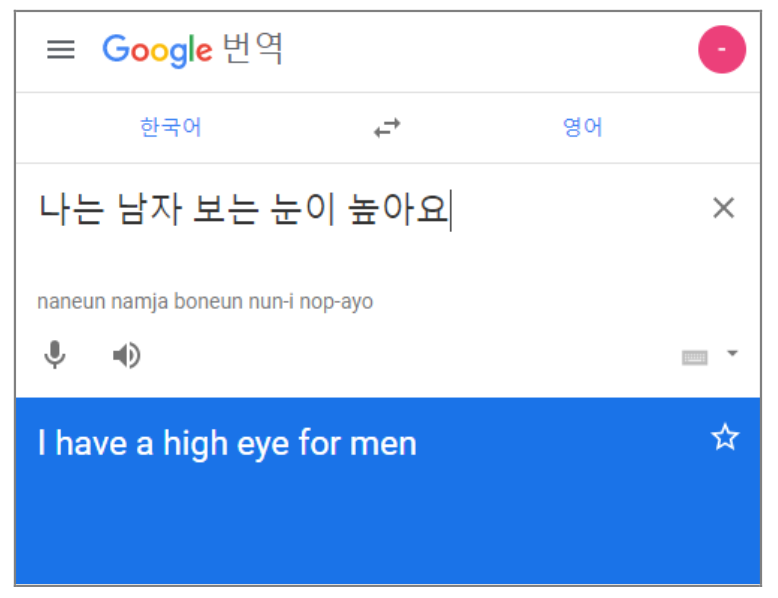
- (Korean) ‘나는 남자 보는 눈이 높아요’ = I have high standard for men
- But Google Translate : I have a high eye for men 👀- So I Built ‘Korean-english Idioms in Sentences dataset (KISS)’
- And I also introduce evaluating method (black-list method) for Korean-English Idiom in NMT
3. KISS : KO-EN parallel dataset including korean idioms
- Download Korean idioms list from Korean language dictionary website
- Extract sentence pair including Korean idioms from large KO-EN parallel corpus (1600K)
- KO-EN parallel corpus from http://www.aihub.or.kr/
- Tokenize each idioms and Korean sentences
- If there are same idiom token series in sentences, extract it
- Get 18,808 sentence pairs, including 430 kinds of idioms
- To tuning the idiom balance in dataset, limit the number of sentences containing the same idiom from 4 to 40
- Finally I got a ‘KISS’ dataset 7,500 sentence pairs
4. Black list evaluating method
- To avoid directly translate problem.
- example
- ‘눈 높다’ directly’ translated to ‘high eye’
- Create black list pair ‘눈 높다’ - ‘eye’
- If there are black list word in sentence, categorize into mistranslated sentences
5. Evaluation
- Quality evaluation about NMT service
- Google Translate, Naver Papago, Kakao i Translate
- (Papago is the most popular NMT service in korea.)
- (Kakao is the most big IT service company in korea, as Naver)
- Compare BLEU & Black-list method
- Google Translate, Naver Papago, Kakao i Translate
6. Conclusion
- I proposed ‘Korean-english Idioms in Sentences dataset (KISS)’
- 420 Korean idioms, 7,500 sentence pairs
- And I also introduce evaluating method (black-list method) for Korean-English Idiom in NMT
- Finally, a dataset consisting of 3,461 translation pairs containing 275 idioms is extracted by excluding mistranslations using the blacklist
- In addition, as a result of calculating the translation accuracy of the machine translation service using the built-up blacklist, it was possible to evaluate the translation quality more accurately than the BLEU score.
- In the future, this study can be applied to the study of constructing a dataset to learn not only idioms but also idioms and proverbs with connotative meanings in NMT, and it can be applied to research evaluating the quality of NMT translation.
- In particular, the method proposed in this study can be widely applied because it can be applied not only to Korean-English translation pairs, but also to other types of language pairs such as Korean-Japanese and Korean-French.
Main reference
- Fadaee Marzieh, et al. Examining the tip of the iceberg:A data set for idiom translation. arXiv preprint arXiv:1802.04681. 2018.
- Shao Yutong, et al. Evaluating machine translation performance on Chinese idioms with a blacklist method. arXiv preprint arXiv:1711.07646. 2017.

NLP Researcher