Strategy for effective training of Korean-English idioms in NMT-
Korean Title : 한-영 관용구 기계번역을 위한 NMT 학습 방법
(HCLT 2020 (Annual Conference on Human and Cognitive Language Technology)) -
Download Paper (Korean)
HCLT2020-한-영 관용구 기계번역을 위한 NMT 학습 방법_최민주.pdf
-
HCLT 2020 Slide PPT (Korean)
(구두발표)HCLT2020-한-영 관용구 기계번역을 위한 NMT 학습 방법_최민주.pdf
1. Abstract
- Training method using special token(tag) and KISS dataset
- After research of 'A Dataset and Evaluating Method for Korean-English Idiom Machine Translation’
2. Related Research
A Dataset and Evaluating Method for Korean-English Idiom Machine Translation
3. Dataset for experiment
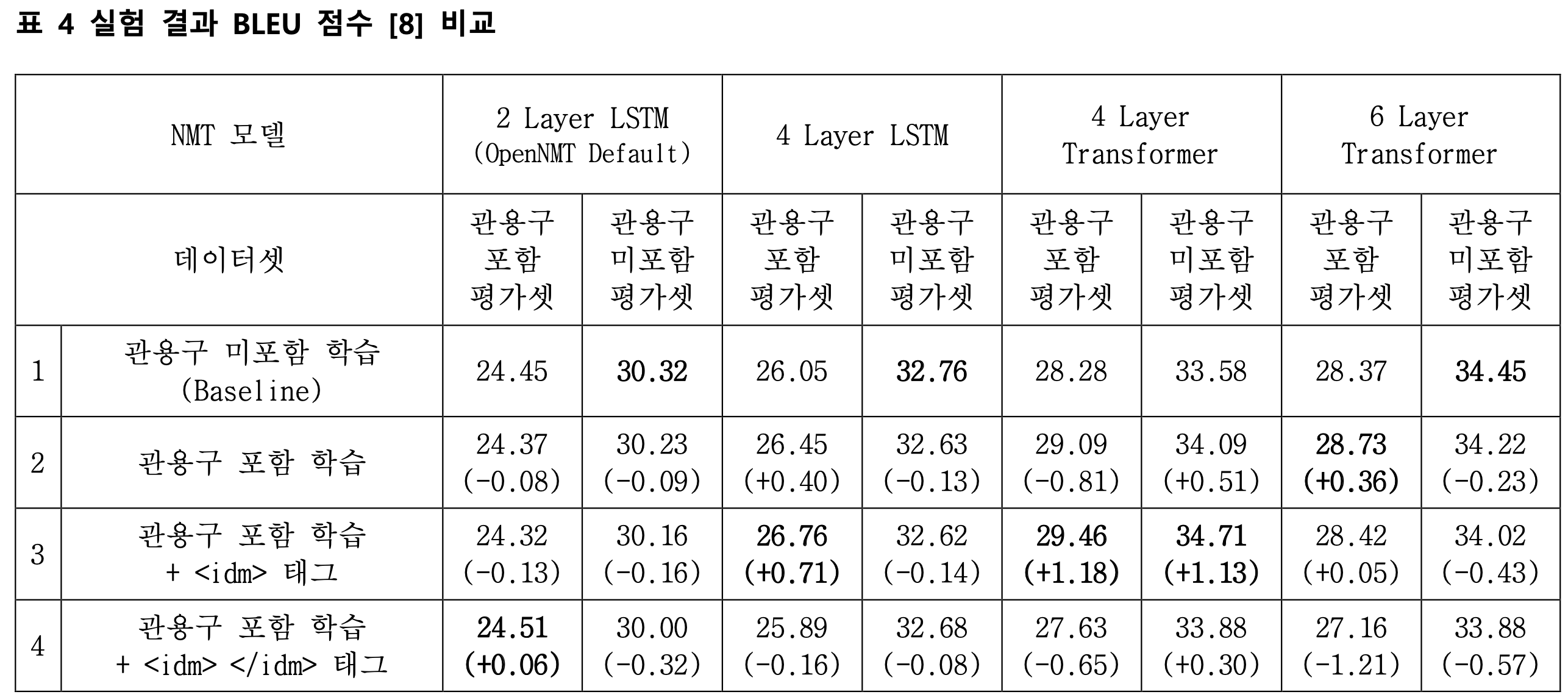
- Special token(tag) to each 4 dataset
- Non-idiom sentence dataset
- Idiom sentence dataset
- idiom sentence dataset
- Attach ‘’ tag in front of idiom word
- idiom sentence dataset
- Attach ‘’ tag in front of idiom word and ‘’ tag back of idiom word
4. Experiment (Training)
OpenNMT-py, model hyper-parameters are:
- 2 Layer LSTM
- 4 Layer LSTM
- Transformer
Best : type 3 (‘’ tag & 4 layer transformer)
5. Conclusion
- In normal, idiom sentence BLEU score is lower than non-idiom sentence
- For efficiently train Korean idiom to NMT, attach special token only in front of idiom.
Reference Project 🌳🦜

AI Researcher